利用聚类算法进行啤酒分类
Posted Python数据分析之旅
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了利用聚类算法进行啤酒分类相关的知识,希望对你有一定的参考价值。
一.聚类简介
原理:将数据集划分为不相交的子集,每个子集称为一个簇,每个簇对应一个类别目标:簇内相似度高,簇间相似度低性能度量:轮廓系数,表达式如下:

二.聚类基本步骤
1.设置要分组的组数K2.随机指定每组中心3.将离中心近的点归到相应族群4.重新计算组内中心点5.用新的中心点重新对个体分类
三.案例实战
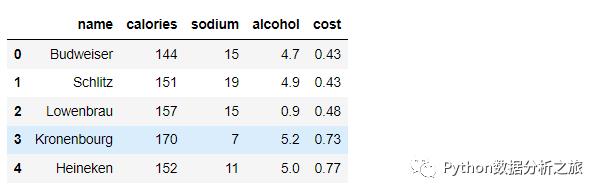
import pandas as pdimport matplotlib.pyplot as plt%matplotlib inline#读取文件beer = pd.read_csv('data.txt', sep=' ')beer.head()
#K-means clusteringfrom sklearn import metricsfrom sklearn.cluster import KMeans#筛选最好的聚类数目#获取属性X = beer[["calories","sodium","alcohol","cost"]]#存储结果dic={}for k in range(2,20):#获取标签labels = KMeans(n_clusters=k).fit(X).labels_#计算轮廓轮廓系数score = metrics.silhouette_score(X, labels)#记录分数dic[k]=score#按照值进行排序print(sorted(dic.items(),key = lambda k : k[1],reverse = True))#分类2类是最好的类别

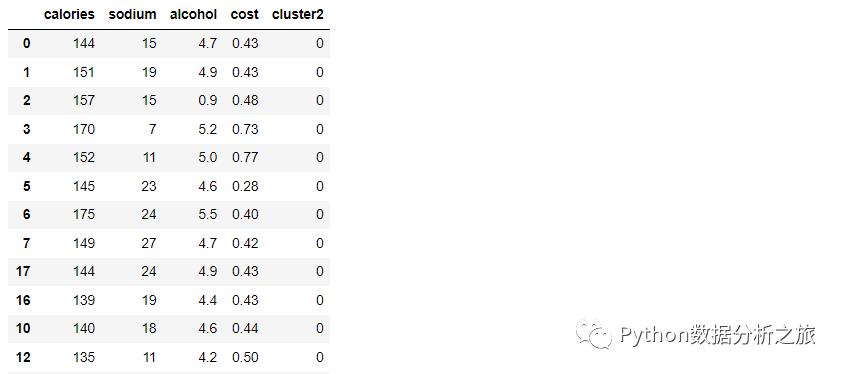
#进行聚类km2 = KMeans(n_clusters=2).fit(X)#添加标签X['cluster2'] = km2.labels_#按照标签排序X.sort_values('cluster2')
%matplotlib inlineimport matplotlib.pyplot as plt#设置颜色plt.rcParams['font.size'] = 14#获取聚类中心centers = X.groupby("cluster2").mean().reset_index()centers
import numpy as np#设置颜色colors = np.array(['red', 'green'])#聚为2类的中心cluster_centers_2 = km2.cluster_centers_#画样本点plt.scatter(X["calories"], X["alcohol"],c=colors[X["cluster2"]])#画中心点plt.scatter(centers.calories, centers.alcohol, linewidths=3, marker='+', s=300, c='black')#x轴标签plt.xlabel("Calories")#y轴标签plt.ylabel("Alcohol")#我们发现效果还不错,但是有些点效果还是不是很好
以上是关于利用聚类算法进行啤酒分类的主要内容,如果未能解决你的问题,请参考以下文章