Spark SQL练习
Posted 皓洲
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark SQL练习相关的知识,希望对你有一定的参考价值。
Spark SQL
实验目的
1.理解Spark SQL工作原理;
2.掌握Spark SQL使用方法。
实验内容
现有一份汽车销售记录(文件名:Cars.csv),销售记录包括时间、地点、邮政编码、车辆类型等信息,每条记录信息包含39项数据项。按步骤完成如下操作(建议在Spark-shell中完成):
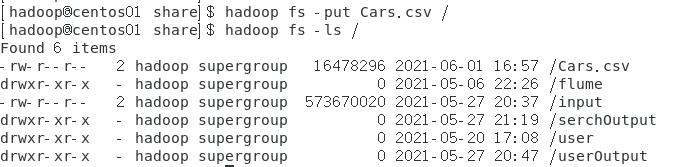
(1)将汽车销售记录上传至HDFS;
(2)使用编程方式定义RDD模式,提取月、市、区县、品牌、车辆类型、使用性质和数量7列,并定义相应Schema;
(3)将(2)的结果以json格式保存至HDFS;
(4)读取该json文件,构建DataFrame;
(5)在DataFrame中使用SQL语句实现如下查询:
① 统计各汽车品牌的销量,并按销量从高到低排序;
② 统计各月各汽车品牌的销量;
③ 统计各市的汽车销量,并按销量从低到高排序;
④ 统计不同城市不同车辆类型的销量;
⑤ 统计各城市汽车销量最大的区县;
⑥ 统计1~6月非营运车辆销量最大的前3大品牌。
实验步骤
将汽车销售记录上传至HDFS
使用编程方式定义RDD模式,提取月、市、区县、品牌、车辆类型、使用性质和数量7列,并定义相应Schema;
-
加载数据为Dataset
scala> val d1=spark.read.csv("hdfs:/Cars.csv") -
用编程方式定义RDD,提取关键字段,定义相应的Schema
scala> import org.apache.spark.sql.types._ scala> import org.apache.spark.sql.Row scala> val files = Array(StructField("month",IntegerType,true), StructField("city",StringType,true), StructField("county",StringType,true), StructField("brand",StringType,true), StructField("carType",StringType,true), StructField("nature",StringType,true), StructField("quantity",IntegerType,true))- 定制Schema
scala> val mySchema = StructType(files)- 读入数据产生RDD
scala> val carsRDD = spark.sparkContext.textFile("/Cars.csv")- 分割数据
scala> val rowRDD = carsRDD.map(_.split(",")).map(line => Row(line(0).trim.toInt,line(1),line(2),line(3),line(4),line(5),line(6).trim.toInt))- 表头和数据拼接
scala> val carsDF = spark.createDataFrame(rowRDD,mySchema)- 查看数据
scala> carsDF.show()

- json格式保存结果到hdfs
scala> carsDF.write.format("json").save("/car.json")
- 读取json文件,构建DataFrame
scala> val cdf = spark.read.json("/car.json")
- 在DataFrame上船舰一个临时视图“cars”
scala> cdf.createTempView("cars")
-
在DataFrame中使用SQL语句实现如下查询:
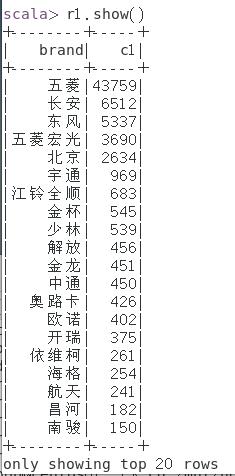
① 统计各汽车品牌的销量,并按销量从高到低排序;
scala> val r1 = spark.sql("select brand,sum(quantity) as c1 from cars group by brand order by c1 desc")
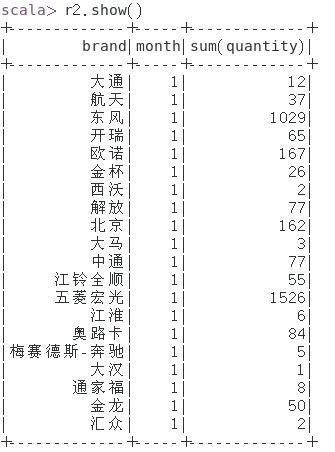
② 统计各月各汽车品牌的销量;
scala> val r2 = spark.sql("select brand,month,sum(quantity) from cars group by brand,month order by month")
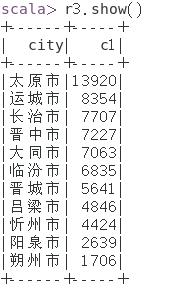
③ 统计各市的汽车销量,并按销量从低到高排序;
scala> val r3 = spark.sql("select city,sum(quantity) as c1 from cars group by city order by c1 desc")
④ 统计不同城市不同车辆类型的销量;
scala> val r4 = spark.sql("select city,carType,sum(quantity) from cars group by city,carType order by city")

⑤ 统计各城市汽车销量最大的区县;
scala> val r5 = spark.sql("select a.city,a.county,max(a.c1) from (select city,county,sum(quantity) as c1 from cars group by city,county)a group by a.city,a.county ")

⑥ 统计1~6月非营运车辆销量最大的前3大品牌。
scala> val r6 = spark.sql("select a.brand from (select brand,nature,sum(quantity) as c1 from cars where month between 1 and 6 and nature like '___' group by brand,nature order by c1 desc)a limit 3")

踩过的坑
1、本次实验数据不知道哪里有问题,直接使用的话,在存储或者查询的时候,总会报错,说是有一个“客车”String被填入到一个Int类型里了。所以最后是直接处理原数据,把所有用不到的列直接删掉了。然后就没问题了。
2、spark sql中的查询不能使用中文,就很奇怪。用了echo $LANG查看语言发现也是UTF-8,实在找不到问题我就直接用like '___'解决了
以上是关于Spark SQL练习的主要内容,如果未能解决你的问题,请参考以下文章