机器学习sklearn----用随机森林来填充缺失值
Posted iostreamzl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习sklearn----用随机森林来填充缺失值相关的知识,希望对你有一定的参考价值。
概述
我们在现实中收集的数据,几乎不可能是完美无缺的,往往会有一些缺失值,面对缺失值,很多人先择的方法是直接将包含缺失值的样本删除,,这是一种有效的方法,但是有时候填补缺失值比之际丢弃样本有更好的效果。即使我们其实并不知道缺失值的真实样貌。在sklearn中,我们可以使用sklearn.impute.SimpleImputer来轻松的将均值、中值或者其他常用的数值填补到缺失值中,具体用法戳这里。在这个案例中我们将用随机森林来填补缺失值。
填充思路
对于一个有n个特征的数据来说,其中特征T有缺失,我们就将特征T当作标签,其他n-1个特征和原来的标签组成新的特征矩阵。对于特征T来说,他没有缺失的部分就是我们的y_train,这部分对应的标签就是X_train,缺失部分就是我们需要预测的部分,也即是y_predict,这部分对应的标签就是X_test,对于数据中有多个特征缺失的情况,需要从缺失值最少的特征开始填补(填补缺失值越少的特征需要的准确信息越少)
当填补一个特征时,将其他特征的缺失值用0代替,依次填补直到所有特征填补完全
原始数据
本次使用的数据为kaggle上泰坦尼克幸存者数据集,原始数据下载地址,也可以在我的数据集下载地址获得同样的数据
实现代码
到相关库
from sklearn.ensemble import RandomForestClassifier # 随机森林分类器,处理分类问题
from sklearn.ensemble import RandomForestRegressor # 随机森林回归器,处理连续值问题
from sklearn.impute import SimpleImputer # sklearn填充缺失值的类
from sklearn.model_selection import cross_val_score # 交叉检验
from sklearn.model_selection import train_test_split # 分割训练测试集
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
加载原始数据
# 导入原始数据
file_name = "../../data/titanic/train.csv"
df = pd.read_csv(file_name)
# 删除不必要特征
df.drop(['Name', 'Ticket'], inplace=True, axis=1)
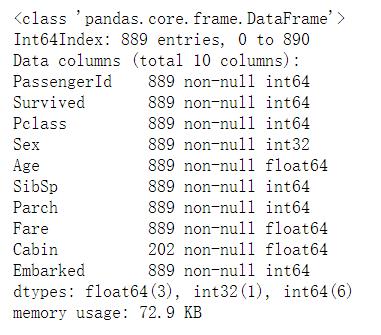
df.info()

原始数据中,Age缺失200左右,Cabin缺失700左右,Embarked缺失2个,Age,Cabin缺失很多,不能直接的删除,这样会造成样本数据大量减少,对模型的训练带来很大的影响,Embarked缺失2条,可用放心的删除缺失的部分,不会对模型造成什么影响。对于Age和Cabin要考虑进行缺失值的填充,有简单的使用sklearn.impute.SimpleImputer来轻松的将均值、中值或者其他常用的数值填补到缺失值中,具体用法戳这里。这里考虑随机森林填充的方式。
删除Embarked中的缺失数据
# Embarked 缺失值很少,这里将缺失的那两行数据删除
# 获得缺失值所在的行索引
na_index = df.loc[df['Embarked'].isnull(), 'Embarked'].index
# 删除缺失值所在的行
df.drop(na_index, inplace=True)
df.info()

查看数据具体信息
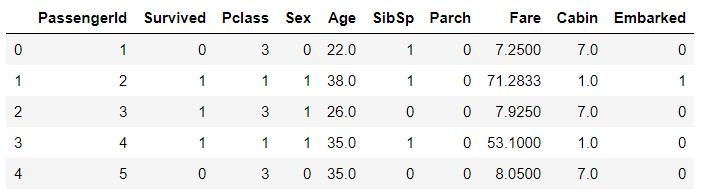
df.head()
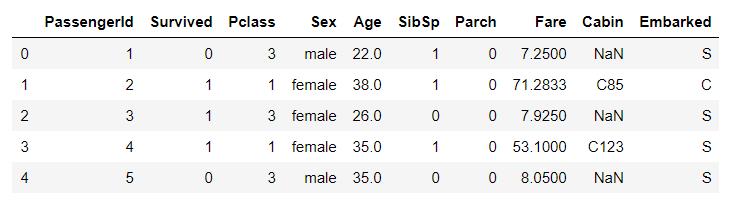
Sex,Cabin,Embarked特征为字符类型,不能直接运算,需要进行数值化。这里Sex,Embarked是简单的数值Cabin中的数据比较混乱,需要经过一些处理才能进行数值化。
将Sex,Embarked进行数值化
# 将Sex,Embarked特征数值化
# 数值化Sex,只能进行一次的操作,必须确保正确,多次执行下面语句会覆盖内容(Sex全为0)
df['Sex'] = (df['Sex'] == 'female').astype('int')
# 这种数值化方式会将nan变为0
categories = df['Embarked'].unique().tolist()
df['Embarked'] = df['Embarked'].apply(lambda x : categories.index(x))
df.head()
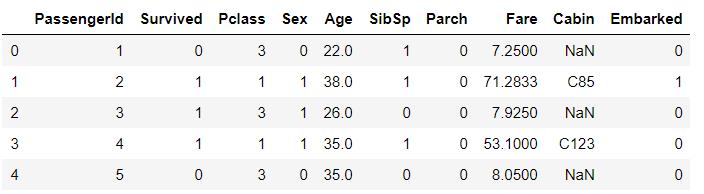
对Cabin数值化
这里的处理思路是:保留空值,将有值的部分取第一个字符作为Cabin的值
# 对Cabin客舱号的处理
# 取客舱号的首字母表示旅客的客舱号
df.loc[df['Cabin'].notnull(), 'Cabin'] = df.loc[df['Cabin'].notnull(), 'Cabin'].apply(lambda x : x[0])
df.head()
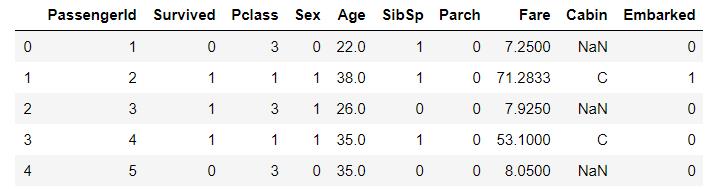
# 客舱属性数值化, 注意保留空值
categories = df['Cabin'].unique().tolist()[1:]
# 这里从列表的第二给元素开始取值,是应为unique默认将空值放在第一位
# 我们需要保留空值,所以不能将空值数值化为0
# 将每一个类别对应的下标作为他的数值
new_val = [categories.index(i)+1 for i in categories]
# 通过replqce方法一次替换多个值
df['Cabin'].replace(categories, new_val, inplace=True)
df.head()
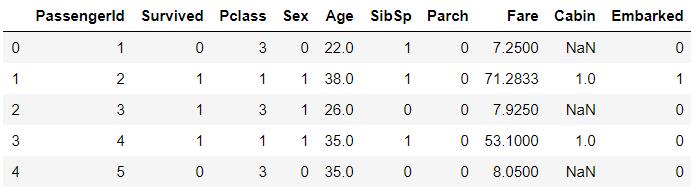
创建数值化后未填充缺失值的数据的副本,方便后面比较随机森林填充缺失值,和0填充缺失值模型的准确度
raw_df = df.copy()
填充Age的缺失值
# 数据初步预处理已经完成,下面开始进入填充
# Age属性缺失最少,所以先填充Age属性,
# 将Cabin缺失的部分用0填充
# 创建副本,避免填充0时修改原始数据,造成后面对Embarked属性填充时不清楚哪些是缺失值
# 所有的填充操作都是对df_copy操作,最后填充完成在将对应特征项的数据更新就可以了
df_copy = df.copy()
filled_Embarked = SimpleImputer(strategy='constant', fill_value=0).fit_transform(df_copy['Cabin'].values.reshape(-1, 1))
df_copy['Cabin'] = filled_Embarked
# 处理Age以外其他特征的缺失值基金用0填充完毕了
# 下面开始对Age填充,Age是一个连续属性,
# 所以选择随机森林回归器做数据填充
# 新的特征矩阵
new_df = df_copy.loc[:, df_copy.columns != 'Age']
# 新的标签
label = df_copy['Age']
# 获得训练集测试集
# 获得所有非空值作为训练姐的标签
y_train = label[label.notnull()]
# 获得训练集X_train的特征,X_train的index与y_train的index一一对应
X_train = new_df.loc[y_train.index]
y_test = label[label.isnull()]
X_test = new_df.loc[y_test.index]
# 建模并预测
rfr = RandomForestRegressor(n_estimators=101)
rfr.fit(X_train, y_train)
y_predict = rfr.predict(X_test)
# 将原数据中的Age特征的缺失值换为预测值
# X_test的索引与原数据Age特征缺失值的index是一一对应的
# y_predict的值与X_test一一对应
# 继而y_predict与原数据缺失值也是一一对应的
df.loc[df['Age'].isnull(), 'Age'] = y_predict
填充Cabin的缺失值
# Age属性填补完成,接下来填补Cabin
# Cabin是一个类目特征,所以用随机森林分类器来实现填补
# 这次之际在df上操作不创建副本了
# 是因为只有Cabin还存在缺失值,不存在补0操作修改原始数据的情况
label = df['Cabin']
y_train = label.loc[label.notnull()]
y_test = label.loc[label.isnull()]
new_features = df.loc[:, df.columns != 'Cabin']
X_train = new_features.loc[y_train.index]
X_test = new_features.loc[y_test.index]
rfc = RandomForestClassifier(n_estimators=101)
rfc.fit(X_train, y_train)
y_predict = rfc.predict(X_test)
df.loc[df['Cabin'].isnull(), 'Cabin'] = y_predict
df.head()
训练模型比较
用随机森林填充缺失值的模型表现
X, y = df.loc[:, df.columns != 'Survived'], df.loc[:, df.columns == 'Survived']
y = y.values.ravel()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
rfc = RandomForestClassifier(n_estimators=101)
rfc.fit(X_train, y_train)
score1 = rfc.score(X_test, y_test)
print(score1) # 0.8651685393258427
用0填充缺失值的模型表现
# 用0填充缺失值
raw_df.fillna(0, inplace=True)
# 与用0填充缺失值相比,随机森林准确度高很多
X, y = raw_df.loc[:, raw_df.columns != 'Survived'], raw_df.loc[:, raw_df.columns == 'Survived']
y = y.values.ravel()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
rfc = RandomForestClassifier(n_estimators=101)
rfc.fit(X_train, y_train)
score1 = rfc.score(X_test, y_test)
print(score1) # 0.7602996254681648
总结
并不是随机森林比普通的填充缺失值效果一定要好,需要具体情况具体分析,一般首先考虑普通填充方式,普通方式效果不好再考虑随机森林。
欢迎评论交流
以上是关于机器学习sklearn----用随机森林来填充缺失值的主要内容,如果未能解决你的问题,请参考以下文章