机器学习中调参调优思想以随机森林乳腺癌数据集为例子
Posted iostreamzl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习中调参调优思想以随机森林乳腺癌数据集为例子相关的知识,希望对你有一定的参考价值。
文章目录
通过画学习曲线,网格搜索,我们可以探索到调参边缘(代价可能是训练一次模型可能要跑很久很久)。现实中,高手调参往往依赖于长久积累的经验,这些经验主要来源:1.非常正确的调参思路;2.对模型评估指标非常深入的理解;3.对数据的感觉和经验;4.用洪荒之力不断去尝试。
虽然我们没有高手多年积累的经验,但是我们可以学习他们对模型评估指标的理解和调参思路。
正确的调参思路
第一步是要找准目标:我们要做什么? 一般来说这个目标是提升某个模型的评估指标。比如对随机森林来说,我们要提升模型在未知数据上的准确率(由score,或oob_score来衡量)。找准了这个目标我们就要思考,模型在未知数据上的准确率受什么影响,。在机器学习中,我们用来衡量模型在未知数据上准确率的指标叫做泛化误差
泛化误差
当模型在未知数据(测试集或者袋外数据)上表现糟糕时,我们说模型的泛化程度不够,泛化误差大,模型的效果不好。泛化误差受到模型的结构(复杂度)影响。看下面这张图,它准确地描绘了泛化误差与模型复杂度的关系,当模型太复杂,模型就会过拟合,泛化能力就不够,所以泛化误差大。当模型太简单,模型就会欠拟合,拟合能力就不够,所以误差也会大。只有当模型的复杂度刚刚好的才能够达到泛化误差最小的目标。
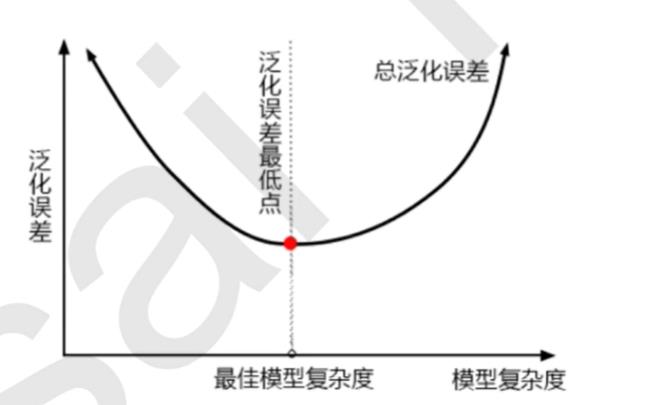
那模型的复杂度与我们的参数有什么关系呢?对树模型来说,树越茂盛,深度越深,枝叶越多,模型就越复杂。所以树模型是天生位于图的右上角的模型,随机森林是以树模型为基础,所以随机森林也是天生复杂度高的模型。随机森林的参数,都是向着一个目标去:减少模型的复杂度,把模型往图像的左边移动,防止过拟合。当然了,调参没有绝对,也有天生处于图像左边的随机森林,所以调参之前,我们要先判断,模型现在究竟处于图像的哪一边(过拟合还是欠拟合)。
四个关键点:
1)模型太复杂或者太简单,都会让泛化误差高,我们追求的是位于中间的平衡点
2)模型太复杂就会过拟合,模型太简单就会欠拟合
3)对树模型和树的集成模型来说,树的深度越深,枝叶越多,模型越复杂
4)树模型和树的集成模型的目标,都是减少模型复杂度,把模型往图像的左边移动
随机森林各个参数对模型在未知数据上评估性能的影响
| 参数 | 对模型评估性能的影响 | 影响程度 |
|---|---|---|
| n_estimators | 越大越稳定 | **** |
| max_depth | 对模型的影响有增有减,max_depth默认最大深度,即此时模型复杂度最高,往往降低模型的泛化能力 | *** |
| min_samples_leaf | 影响有增有减,默认值1,即最高复杂度。min_samples_leaf越大,模型越简单 | ** |
| min_samples_split | 影响有增有减,默认值2,也是最高复杂度,min_samples_split越大模型越简单 | ** |
| max_features | 影响有增有减,max_features越大,模型越复杂;max_features越小模型越简单.max_features默认值为特征数的平方根,是处使模型复杂度处在中间的一个参数。 | * |
| criterion | 影响有增有减,一般默认gini | 视情况而定 |
示例—随机森林在sklearn乳腺癌数据集上的调参
调参思路:先调对模型影响最大的参数,再逐步调后面的参数,最终找到最优的参数
从sklearn中导入相关的包
from sklearn.datasets import load_breast_cancer # 乳腺癌数据集接口
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV # 网格搜索
from sklearn.model_selection import cross_val_score # 交叉验证
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
导入数据,不经过调参直接看模型准确度
# 导入数据
data = load_breast_cancer()
X = data['data']
y = data['target']
# 看一下不经过调参直接交叉验证模型得分
rfc = RandomForestClassifier()
init_score = cross_val_score(rfc, X, y, cv=10).mean()
init_score
# 0.9544097312246131
# 已经是很不错了,可以预感接下来的调参不会由巨大的提高
初步画学习曲线
这里的调参思路:找到这个参数的大概范围再进一步找出最优解
# 初步画出n_estimators学习曲线,n_estimators从1-200步长为10
# 看一下学习曲线在哪个位置取得最大值,然后再再这个最大值范围内进行精细调参
# 设置random_state参数,确保模型中生成的树模式是一样的
# 真是一个耗时的操作
scores = []
for i in range(1, 201, 10) :
rfc = RandomForestClassifier(n_estimators=i, random_state=1)
scores.append(cross_val_score(rfc, X, y, cv=10).mean())
print(max(scores), scores.index(max(scores))*10+1)
# 0.9650905280442486 151
# 有了一点点提高接着努力
plt.plot(range(1, 201, 10), scores)
plt.show()
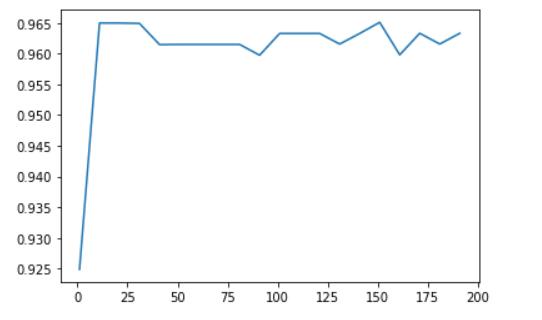
这里可以明显的看到,再0-15这一段模型的准确度飞速提高,然后再0.96左右开始波动。通过代码找到n_estimators再151的时候模型表现最好,但是这里的步长是10,所以并不知道再151周围模型的表现,可以假设再151周围模型有一些波动,所以需要进一步的画出学习曲线来研究。
进一步画出学习曲线
# 上面的初步u调参中可以看出再n_estimators=151附近
# 模型的精确度应该还有一个变化
# 可以选择进一步调参,让n_estimators在141-161之间变化
# 找出得分最高的参数值
scores = []
for i in range(141, 162, 1) :
rfc = RandomForestClassifier(n_estimators=i, random_state=1)
scores.append(cross_val_score(rfc, X, y, cv=10).mean())
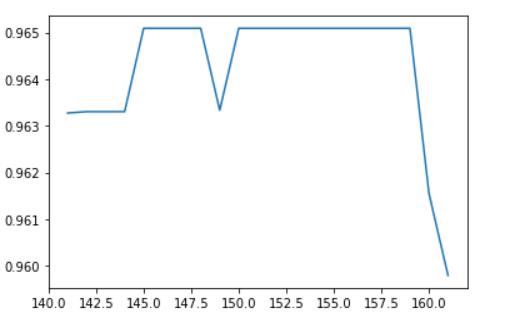
print(max(scores), scores.index(max(scores))+141)
plt.plot(range(141, 162, 1), scores)
# 0.9651905280442486 145
# 升高了一点点可以接受
plt.show()
调影响第二大的参数—max_depth
从最后的结果来看,这一步是白忙活了
# 最优的n_estimators已经找到>>>>145
# 接下来按照影响程度调节max_depth参数
# 想要看max_depth对模型的影响变化可以选择画学习曲线
# 但是学习曲线运行比较慢,这里选择网格搜索
params_grid = {
'max_depth' : range(1, 30)
}
# 这里的n_estimators参数已经最优了不需要再调了,直接使用前面的结果即可
rfc = RandomForestClassifier(n_estimators=145, random_state=1)
GS = GridSearchCV(rfc, param_grid=params_grid, cv=10)
GS = GS.fit(X, y)
print(GS.best_params_)
print(GS.best_score_)
# {'max_depth': 8}
# 0.9648506151142355
# 这里精确度比原来降低了。
# 说明我的复杂度降低了但是精确度下降了,我们模型居然欠拟合了
# 那就表明复杂度越高模型越好
# 那么降低复杂度的参数都可以不用调了
通过分析可以知道要增加复杂度,有针对性的调参—max_features
# 调增加复杂度的参数max_features
# max_features默认特征数的平方跟
# 这里需要增加复杂度,则要经该参数调大
# 选择从默认值开始,知道数值等于特征数
params_grid = {
'max_features' : range(5, 30)
}
rfc = RandomForestClassifier(n_estimators=145, random_state=1)
GS = GridSearchCV(rfc, param_grid=params_grid, cv=10)
GS = GS.fit(X, y)
print(GS.best_params_)
print(GS.best_score_)
# {'max_features': 14}
# 0.9718804920913884
# 不错不错由提高了
不死心的调参(说不定效果很好呢)----criterion
然而事实证明还是白忙活了
# 条criterion参数
params_grid = {
'criterion' : ['gini', 'entropy']
}
rfc = RandomForestClassifier(n_estimators=145, random_state=1, max_features=14)
GS = GridSearchCV(rfc, param_grid=params_grid, cv=10)
GS = GS.fit(X, y)
print(GS.best_params_)
print(GS.best_score_)
# {'criterion': 'gini'}
# 0.9718804920913884
# 好吧看来这个参数没有意义
最终结果
# 经过不断的尝试终于调出了最好的参数了
# 这个参数是再random_state=1的情况下的,还可以试着改变这个参数看看结果
# 目前的最优参数
'''
n_estimators=145
random_state=1
max_features=14
criterion=gini
'''
rfc = RandomForestClassifier(n_estimators=145, random_state=1, max_features=14)
final_score=cross_val_score(rfc, X, y, cv=10).mean()
print("调参前准确率:{}".format(init_score))
print("调参后准确率: {}".format(final_score))
print("准确度提高了:{}".format(final_score-init_score))
总结
需要对模型由了解,**明确的调参目标,一个清晰的调参思路,先影响最大再慢慢往后,分析每一次的调参结果,**不然就会做很多不必要的操作,然后就是一次次的尝试,最后就是耐心了,这很重要
总结:调参好耗时,好辛苦,我的头发啊…
以上是关于机器学习中调参调优思想以随机森林乳腺癌数据集为例子的主要内容,如果未能解决你的问题,请参考以下文章