特征工程之特征选择----卡方过滤
Posted iostreamzl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了特征工程之特征选择----卡方过滤相关的知识,希望对你有一定的参考价值。
文章目录
问题的引入
方差过滤掉的是哪些特征方差不高于阈值的特征,留下了的是方差比较大的特征,这只能反应该特征变化比较多,并不能反映于标签之间的直接相关性。
我们希望选出的是与标签相关且有意义的特征,因为这样的特征能为我们提供大量的信息。如果特征与标签相关性很差,只会白白浪费我们的计算内存与时间。并且可能给我们的模型引入噪声。
sklearn中为我们提供了三种相关性判断的方法:卡方检验,F检验,互信息。这篇文章只将卡方检验。
卡方检验
卡方检验概述
卡方过滤是专门针对离散型标签(即分类问题)的相关性过滤
卡方检验sklearn.feature_selection.chi2计算每个非负特征和标签的卡方统计量。并依照统计量由高到低对特征进行排序。
再结合sklearn.feature_selection-SelectKBest类选择出K个相关性最高的特征
注意点:如果卡方检验检测到某个特征中所有的值都相同,会提示我们使用方差先进行方差过滤
对负数特征的处理
由于卡方检验只支持计算非负特征,遇到负数特征我们可以考虑将数据进行归一化,具体看这篇博文
示例1
再前面方差过滤这篇博文中,我们使用方差过滤筛掉一半特征之后模型的准确度有一些上升,说明我们删除的特征与标签基本是无关的。这里继续使用方差筛掉一般的数据。需要说明的是,如果方差过滤后模型表现下降,我们就不要使用筛选后的数据了,而是使用原始数据。
导入相关模块
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score # 交叉检验
from sklearn.feature_selection import VarianceThreshold # 方差过滤
from sklearn.feature_selection import chi2 # 卡方检验
from sklearn.feature_selection import SelectKBest # 特征选择
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
数据处理
# 加载数据
path = "E://anaconda/machine-learning/test1/data/digit-recognizer/train.csv"
df = pd.read_csv(path)
df.shape # (42000, 785)
# 特征标签提取
X = df.loc[:, df.columns != 'label']
y = df.loc[:, df.columns == 'label'].values.ravel()
# 通过方差中位数过滤掉一半特征
X_var_median_filter = VarianceThreshold(threshold=var_median).fit_transform(X)
X_var_median_filter.shape
# (42000, 392)
过滤前随机森林分类器表现
这里使用随机森林来评估特征过滤,主要是随机森林是真的快,其他模型可能要指数级上升的时间。,随机森林相关知识看这里
rfc = RandomForestClassifier(n_estimators=21, random_state=1)
score = cross_val_score(rfc, X_var_median_filter, y, cv=5).mean()
score
# 0.9530719990312726
卡方过滤1—保留300个特征
X_chi2_filter = SelectKBest(chi2, k=300).fit_transform(X_var_median_filter, y)
X_chi2_filter.shape # (42000, 300)
score_chi2_filter_300 = cross_val_score(rfc, X_chi2_filter, y, cv=5).mean()
score_chi2_filter_300
# 0.9482857056213806
# emmm模型表现变差了,说明我们过滤掉的特征中有与标签相关的特征
# 或者是过滤掉的特征太多了
# 接下看可以考虑画学习曲线看看了
参数k的学习曲线
scores = []
for i in range(392, 250, -10) :
X_new = SelectKBest(chi2, k=i).fit_transform(X_var_median_filter, y)
scores.append(cross_val_score(rfc, X_new, y, cv=5).mean())
plt.plot(range(392, 250, -10), scores)
plt.show()
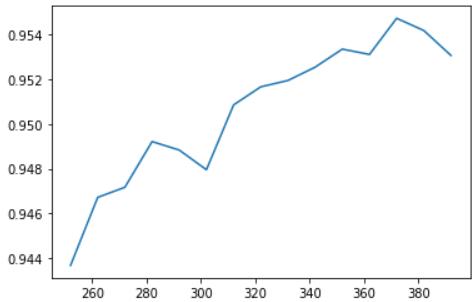
通过学习曲线看出,随着特征数的增加,模型表现变好,说明了前面方差过滤完成的特征已经很好了,不需要再进一步过滤了。
对方法1中k值设定的思考
上面的例子中要保留的特征数k是我们人为设定了,事实上我们并不知道哪些特征与标签有关,也不知带具体要保留几个在特征才是最好的,这样的情况下,只能画学习曲线了,但是画学习曲线特别耗时。所以就需要用到下面的方法了,通过p值来计算k
示例2
概述
卡方检验的本质是推测两组数据之间的差异
卡方检验的原假设是:两组数据相互独立,
卡方检验chi2返回卡方值和p值两个统计量,其中卡方值很难界定范围,而p值,一般使用0.05或0.01来作为显著性水平,即p值的判断边界
| p值 | <=0.05或0.01 | >0.05或0.1 |
|---|---|---|
| 数据差异 | 差异不是自然形成的 | 这些差异是很自然的样本误差 |
| 相关性 | 两组数据相关 | 两组数据相互独立 |
| 结果 | 拒绝原假设,接受备择假设 | 接受原假设 |
获得p值
chi2_values, chi2_pvalues = chi2(X_var_median_filter, y)
chi2_pvalues
# 一眼看去都是相关的
# 看来通过方差过滤后的数据不需要再次删除了
k值计算
# 计算需要保留的特征个数的方式
k = chi2_values.shape[0] - (chi2_pvalues > 0.05).sum()
k # 392
k值有了,接下来,要进行的操作就是和上面一样的了。这里就不展示了。
总结
一般情况下,我们可以通过方差过滤,先筛掉方差=0或方差极小的特征,然后再通过卡方检验筛掉一些特征。最后一个小tip:可以通过get_support()查看每个特征的具体删除情况。
以上是关于特征工程之特征选择----卡方过滤的主要内容,如果未能解决你的问题,请参考以下文章