特征工程之特征选择----包装法
Posted iostreamzl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了特征工程之特征选择----包装法相关的知识,希望对你有一定的参考价值。
文章目录
包装法概述
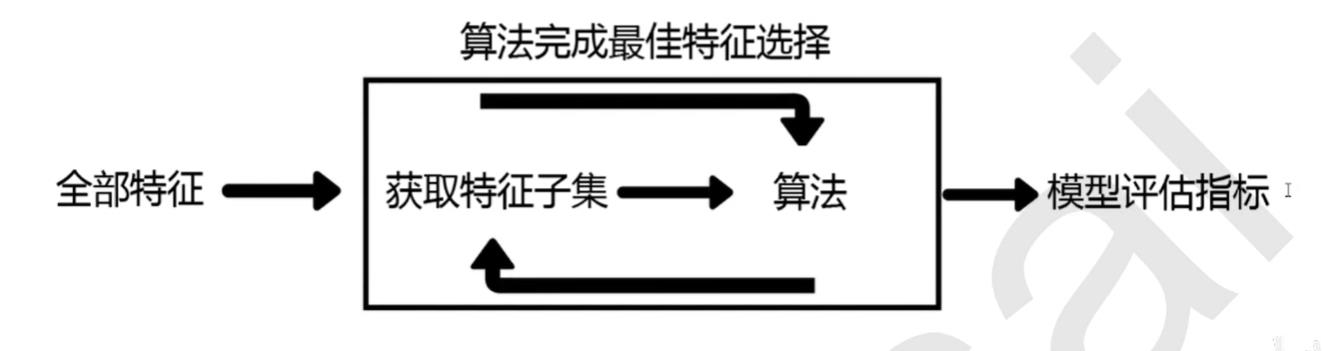
包装法,也是一个特征选择和算法训练同时进行的方法,与嵌入法十分相似
它也是依赖于算法自身的选择,比如coef_或feature_importances_属性来完成特征选择
不同的是我们往往使用一个目标函数作为黑盒来帮助我们完成特征选择,而不是我们自己输入某个评估指标或统计量的阈值
包装法在初始训练集上训练我们的评估器,并且通过coef_属性或feature_importances_属性获得每个特征的重要性
然后从当前的一组特征中删除掉一些最不重要的特征,然后在修改后的集合上重复该过程,直到最后剩下的特征是我们规定的数量
注意点:时间复杂度位于过滤法和嵌入法之间
目标函数
最典型的目标函数是递归特征消除法(Recursive feature elimination,简写为RFE)。
它是一种贪婪的优化算法,旨在找到性能最佳的特征子集。
它反复创建模型,并在每次迭代时保留最佳特征或剔除最差特征,
下一次迭代时,它会使用上一次建模中没有被选中的特征来构建下一个模型,直到所有特征都耗尽为止。然后,它根据自己保留或剔除特征的顺序来对所有特征进行排名,最终选出一个最佳子集。
包装法的效果是所有特征选择方法中最利于提升模型表现的,它可以使用很少的特征达到很优秀的效果。
除此之外,在特征数目相同时,包装法和嵌入法的效果能够匹敌,不过它比嵌入法算得更快,
虽然它的计算量也十分庞大,不适用于太大型的数据。但是,包装法任然是最高效的特征选择方法。
feature_selection.RFE简述
重要参数
- estimator:实例化后的评估器
- n_features_to_select:要选择的特征个数
- step:每次迭代中希望删除的特征最大数量。每次删除的特征数量一定是小于等于step值的
重要属性
- support_:返回所有特征最后的选择情况的bool矩阵
- ranking_:特征重要性的排名
示例
导入相关库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestClassifier
from sklearn.feature_selection import RFE # 目标函数
from sklearn.model_selection import cross_val_score
%matplotlib inline
导入数据,分割特征标签
这次使用的仍然是digit-recognizer数据集。原数据下载地址,快捷下载
file_name = "E://anaconda/machine-learning/test1/data/digit-recognizer/train.csv"
df = pd.read_csv(file_name)
X = df.loc[:, df.columns != 'label']
y = df.loc[:, df.columns == 'label'].values.ravel()
X.shape # (42000, 784)
实例化模型
# 实例化模型
rfc_21_1 = RandomForestClassifier(n_estimators=21, random_state=1)
实例化目标函数(选择器)
这里为了展示属性将fit 和transform分开实现,熟练后可以直接fit_transfrom一步实现
# 实例化选择器
wrap_selector = RFE(rfc_21_1, n_features_to_select=392, step=50)
wrap_selector = wrap_selector.fit(X, y)
查看相关属性
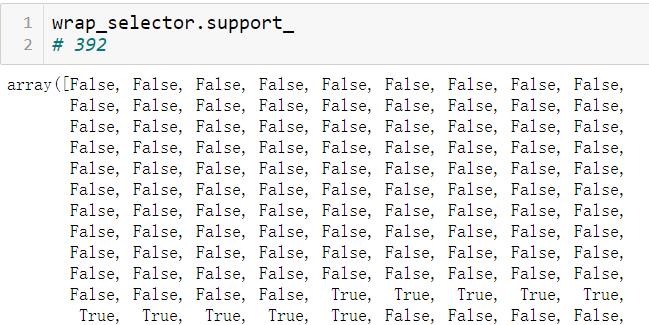
wrap_selector.support_.sum() # 392
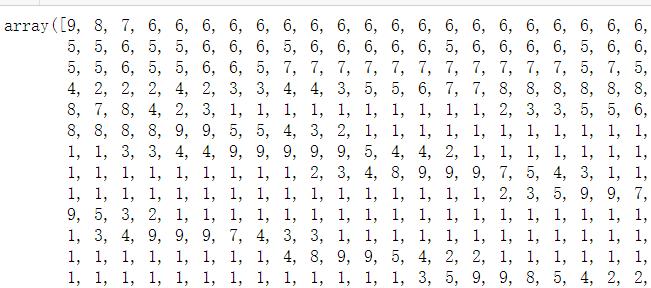
# 返回的是原始数据每一个重要性的排名
wrap_selector.ranking_.shape
# (784,)
特征选择情况矩阵:
重要性排名矩阵,数值越小重要性越大,越不容易被删除
获得过滤后的数据
# 获得过滤后的数据
X_warp_392 = wrap_selector.transform(X)
X_warp_392.shape # (42000, 392)
模型评估
# 模型评估
score_392 = cross_val_score(rfc_21_1, X_warp_392, y, cv=5).mean()
score_392
# 0.9547384304678289 # 当前得分
# 0.9547383538977157 # 嵌入法画学习曲线后最佳阈值的得分
这里只是我们自己设定特征个数,还没有经过学习曲线寻找最佳参数时的得分,已经比嵌入法最佳参数的得分高了。不得不说包装法真的很强大。
第一次学习曲线(跨度50)
# 上面的表现还是没有画学习曲线调参的结果,看来画学习曲线很有搞头
scores = []
n = range(1, X.shape[1], 50)
for i in n :
X_new = RFE(rfc_21_1, n_features_to_select=i, step=50).fit_transform(X, y)
scores.append(cross_val_score(rfc_21_1, X_new, y, cv=5).mean())
plt.figure(figsize=(20, 5))
plt.plot(n, scores)
plt.xticks(n)
plt.show()
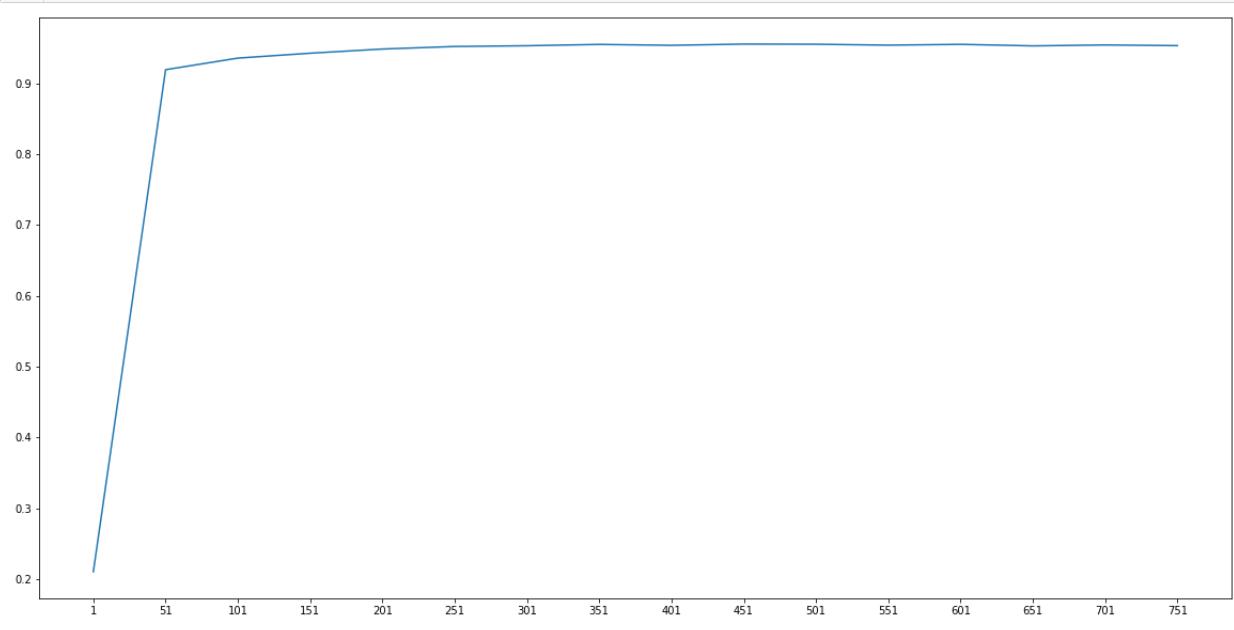
从图中可以看出来,在特征数为50往上的时候,模型表现以及超过了90%,这比方差过滤好了很多很多,方差过滤几百个特征,才能模型达到90%以上。
max(scores) # 0.9552621777696707
n[scores.index(max(scores))]
# 451
在特征为451时取得最大值,这里的跨度为50.我们完全可以相信在451附近有某个地方让模型表现更好
第二次学习曲线(跨度10)
# 在451的时候模型表现最好
# 现在缩小区间跨度,进一步找出最佳参数范围
scores = []
for i in range(400, 500, 10) :
X_new = RFE(rfc_21_1, n_features_to_select=i, step=50).fit_transform(X, y)
scores.append(cross_val_score(rfc_21_1, X_new, y, cv=5).mean())
plt.figure(figsize=(20, 5))
plt.plot(range(400, 500, 10), scores)
plt.xticks(range(400, 500, 10))
plt.show()
max(scores) # 0.9554289947538559
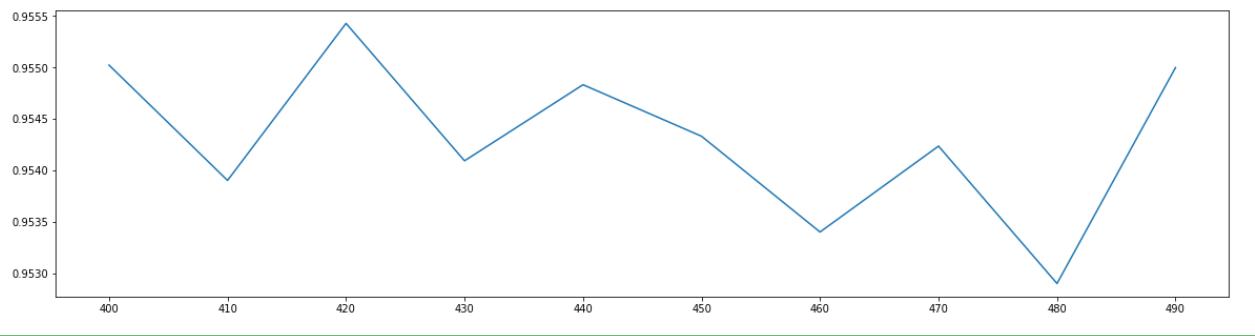
从图中可以看出在420时取得最大值,这时的跨度为10.接下来再进一步画学习曲线,就能找到最佳的参数值了。
第三次学习曲线(跨度1)
score_accurate = []
for i in range(410, 430, 1) :
X_new = RFE(rfc_21_1, n_features_to_select=i, step=50).fit_transform(X, y)
score_accurate.append(cross_val_score(rfc_21_1, X_new, y, cv=5).mean())
plt.figure(figsize=(20, 8))
plt.plot(range(410, 430, 1), score_accurate)
plt.xticks(range(410, 430))
plt.show()
max(score_accurate)
# 0.955476772483796
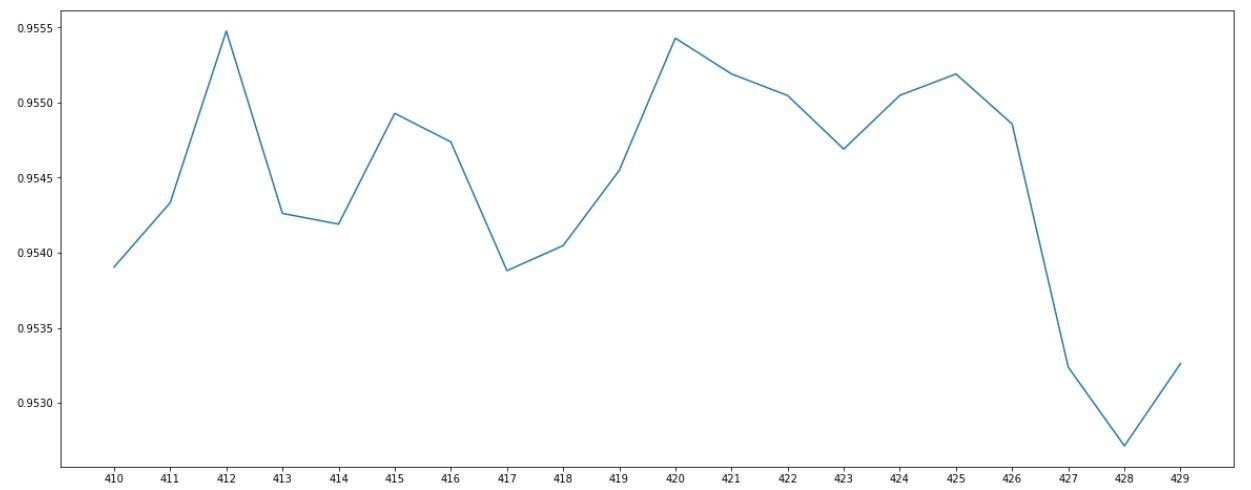
再411时模型取得最大值0.955476772483796。
调参随机森林,效果立竿见影
# 在411的时候模型表现最好
X_wrap_411 = RFE(rfc_21_1, n_features_to_select=411, step=50).fit_transform(X, y)
score_411 = cross_val_score(RandomForestClassifier(n_estimators=101, random_state=1),
X_wrap_411, y, cv=5).mean()
score_411
# 0.9641908471261844 当前表现
# 0.9633097415038214 嵌入法最好表现
这里只是调了一下随机森林中数=书的数量,模型表现就有了很大的提高,有时间的小伙伴可以去试着调试其他参数。关于随机森林调参看这里
总结
至此,我们讲完了降维之外的所有特征选择的方法。这些方法的代码都不难,
但是每种方法的原都不相同,并且都涉及到不同调整方法的超参数。
经验来说,过滤法更快速,但更粗糙。
包装法和嵌入法更精确,比较适合具体到算法去调整,但计算量比较大,运行时间长。
当数据量很大的时候,优先使用方差过滤和互信息法调整,再上其他特征选择方法。
使用逻辑回归时,优先使用优先使用嵌入法。
使用支持向量机时,优先使用包装法。
迷茫的时候,从过滤法走起,看具体数据具体分析。
以上是关于特征工程之特征选择----包装法的主要内容,如果未能解决你的问题,请参考以下文章