Flink + Iceberg 在去哪儿的实时数仓实践
Posted zhisheng_blog
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink + Iceberg 在去哪儿的实时数仓实践相关的知识,希望对你有一定的参考价值。
摘要:本文介绍去哪儿数据平台在使用 Flink + Iceberg 0.11 的一些实践。内容包括:
背景及痛点
Iceberg 架构
痛点一:Kafka 数据丢失
痛点二:近实时 Hive 压力大
Iceberg 优化实践
总结
Tips:点击文末「阅读原文」即可查看更多技术干货~
 GitHub 地址
GitHub 地址 
https://github.com/apache/flink
欢迎大家给 Flink 点赞送 star~
一、背景及痛点
1. 背景
我们在使用 Flink 做实时数仓以及数据传输过程中,遇到了一些问题:比如 Kafka 数据丢失,Flink 结合 Hive 的近实时数仓性能等。Iceberg 0.11 的新特性解决了这些业务场景碰到的问题。对比 Kafka 来说,Iceberg 在某些特定场景有自己的优势,在此我们做了一些基于 Iceberg 的实践分享。
2. 原架构方案
原先的架构采用 Kafka 存储实时数据,其中包括日志、订单、车票等数据。然后用 Flink SQL 或者 Flink datastream 消费数据进行流转。内部自研了提交 SQL 和 Datastream 的平台,通过该平台提交实时作业。
3. 痛点
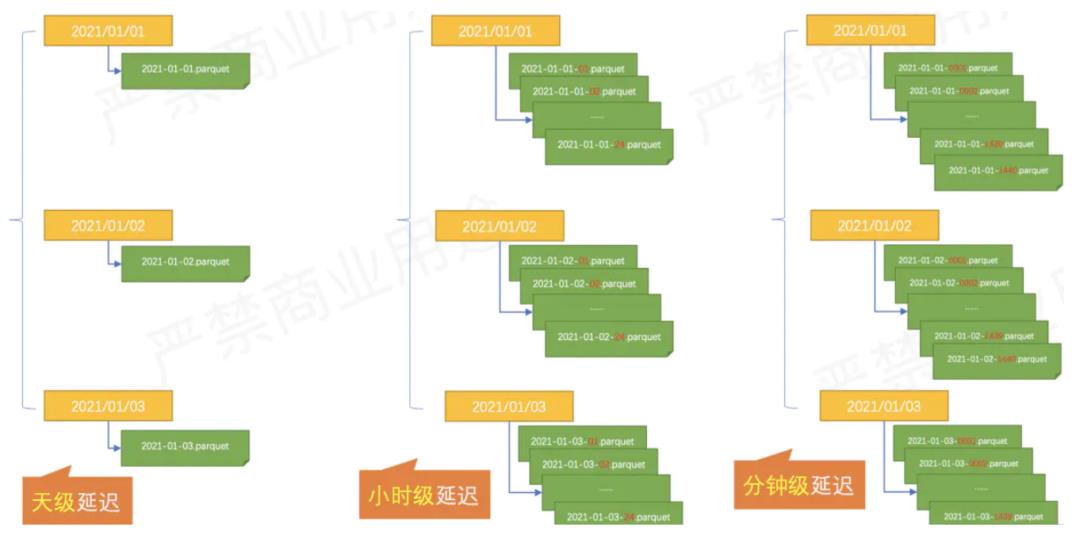
Kafka 存储成本高且数据量大。Kafka 由于压力大将数据过期时间设置的比较短,当数据产生反压,积压等情况时,如果在一定的时间内没消费数据导致数据过期,会造成数据丢失。
Flink 在 Hive 上做了近实时的读写支持。为了分担 Kafka 压力,将一些实时性不太高的数据放入 Hive,让 Hive 做分钟级的分区。但是随着元数据不断增加,Hive metadata 的压力日益显著,查询也变得更慢,且存储 Hive 元数据的数据库压力也变大。
二、Iceberg 架构
1. Iceberg 架构解析
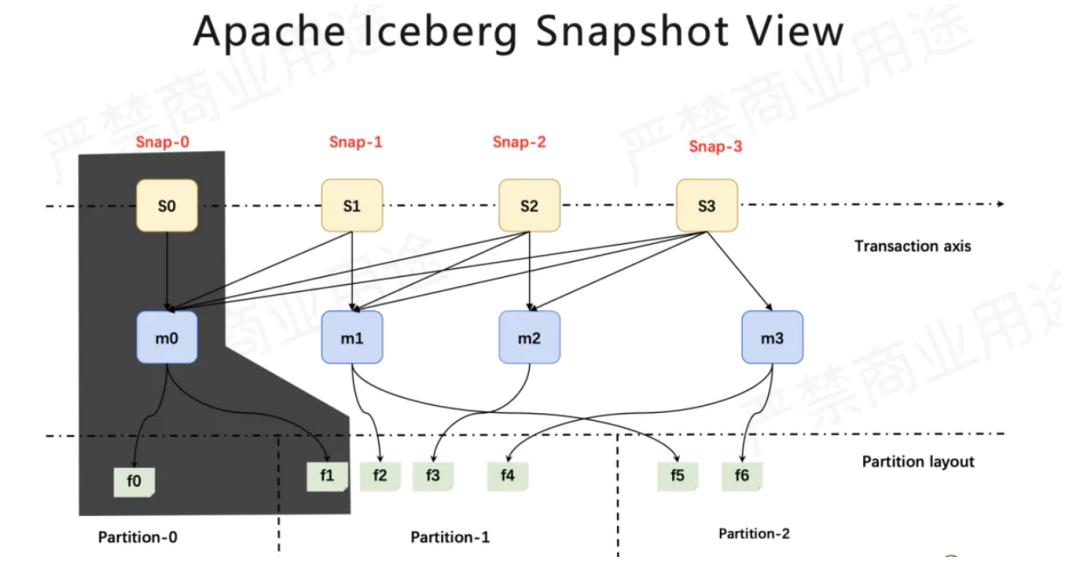
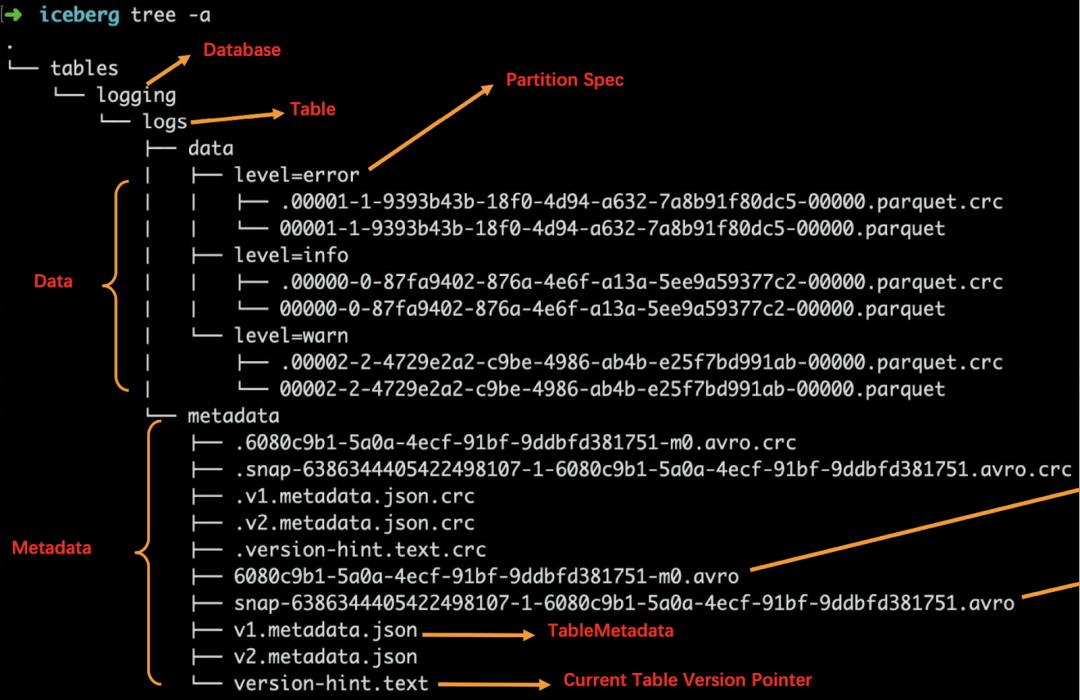
术语解析
数据文件(data files)
Iceberg 表真实存储数据的文件,一般存储在 data 目录下,以 “.parquet” 结尾。
清单文件(Manifest file)
每行都是每个数据文件的详细描述,包括数据文件的状态、文件路径、分区信息、列级别的统计信息(比如每列的最大最小值、空值数等)。通过该文件,可过滤掉无关数据,提高检索速度。
快照(Snapshot)
快照代表一张表在某个时刻的状态。每个快照版本包含某个时刻的所有数据文件列表。Data files 存储在不同的 manifest files 里面, manifest files 存储在一个 Manifest list 文件里面,而一个 Manifest list 文件代表一个快照。
2. Iceberg 查询计划
查询计划是在表中查找 “查询所需文件” 的过程。
元数据过滤
清单文件包括分区数据元组和每个数据文件的列级统计信息。在计划期间,查询谓词会自动转换为分区数据上的谓词,并首先应用于过滤数据文件。接下来,使用列级值计数,空计数,下限和上限来消除与查询谓词不匹配的文件。
Snapshot ID
每个 Snapshot ID 会关联到一组 manifest files,而每一组 manifest files 包含很多 manifest file。
manifest files 文件列表
每个 manifest files 又记录了当前 data 数据块的元数据信息,其中就包含了文件列的最大值和最小值,然后根据这个元数据信息,索引到具体的文件块,从而更快的查询到数据。
三、痛点一:Kafka 数据丢失
1. 痛点介绍
通常我们会选择 Kafka 做实时数仓,以及日志传输。Kafka 本身存储成本很高,且数据保留时间有时效性,一旦消费积压,数据达到过期时间后,就会造成数据丢失且没有消费到。
2. 解决方案
将实时要求不高的业务数据入湖、比如说能接受 1-10 分钟的延迟。因为 Iceberg 0.11 也支持 SQL 实时读取,而且还能保存历史数据。这样既可以减轻线上 Kafka 的压力,还能确保数据不丢失的同时也能实时读取。
3 .为什么 Iceberg 只能做近实时入湖?
Iceberg 提交 Transaction 时是以文件粒度来提交。这就没法以秒为单位提交 Transaction,否则会造成文件数量膨胀;
没有在线服务节点。对于实时的高吞吐低延迟写入,无法得到纯实时的响应;
Flink 写入以 checkpoint 为单位,物理数据写入 Iceberg 后并不能直接查询,当触发了 checkpoint 才会写 metadata 文件,这时数据由不可见变为可见。checkpoint 每次执行都会有一定时间。
4. Flink 入湖分析
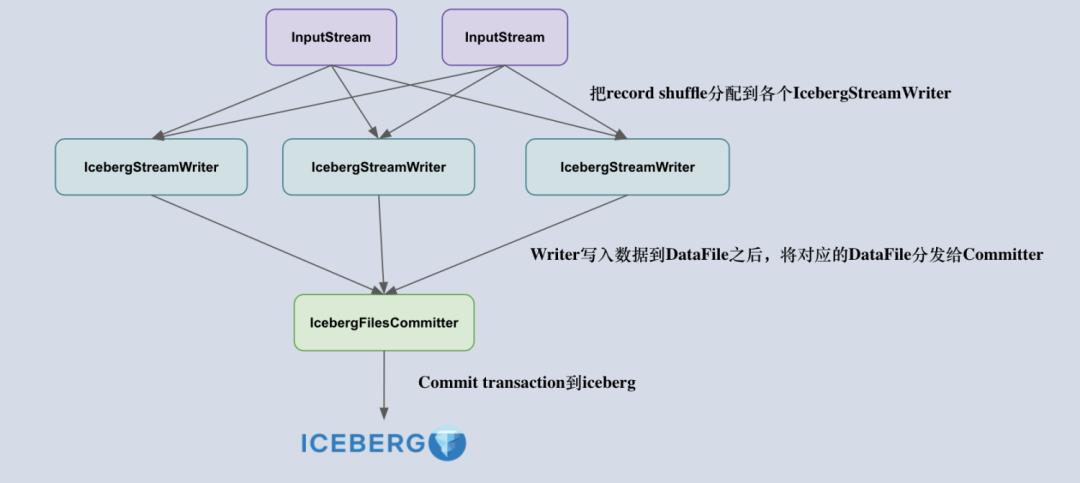
组件介绍
IcebergStreamWriter
主要用来写入记录到对应的 avro、parquet、orc 文件,生成一个对应的 Iceberg DataFile,并发送给下游算子。
另外一个叫做 IcebergFilesCommitter,主要用来在 checkpoint 到来时把所有的 DataFile 文件收集起来,并提交 Transaction 到 Apache Iceberg,完成本次 checkpoint 的数据写入,生成 DataFile。
IcebergFilesCommitter
为每个 checkpointId 维护了一个 DataFile 文件列表,即 map<Long, List<DataFile>>,这样即使中间有某个 checkpoint 的 transaction 提交失败了,它的 DataFile 文件仍然维护在 State 中,依然可以通过后续的 checkpoint 来提交数据到 Iceberg 表中。
5. Flink SQL Demo
Flink Iceberg 实时入湖流程,消费 Kafka 数据写入 Iceberg,并从 Iceberg 近实时读取数据。

■ 5.1 前期工作
开启实时读写功能
set execution.type = streaming
开启 table sql hint 功能来使用 OPTIONS 属性
set table.dynamic-table-options.enabled=true
注册 Iceberg catalog 用于操作 Iceberg 表
CREATE CATALOG Iceberg_catalog WITH (\\n" + " 'type'='Iceberg',\\n" + " 'catalog-type'='Hive'," + " 'uri'='thrift://localhost:9083'" + ");
Kafka 实时数据入湖
insert into Iceberg_catalog.Iceberg_db.tbl1 \\n select * from Kafka_tbl;
数据湖之间实时流转 tbl1 -> tbl2
insert into Iceberg_catalog.Iceberg_db.tbl2 select * from Iceberg_catalog.Iceberg_db.tbl1 /*+ OPTIONS('streaming'='true', 'monitor-interval'='10s',snapshot-id'='3821550127947089987')*/
■ 5.2 参数解释
monitor-interval
连续监视新提交的数据文件的时间间隔(默认值:1s)。
start-snapshot-id
从指定的快照 ID 开始读取数据、每个快照 ID 关联的是一组 manifest file 元数据文件,每个元数据文件映射着自己的真实数据文件,通过快照 ID,从而读取到某个版本的数据。
6. 踩坑记录
我之前在 SQL Client 写数据到 Iceberg,data 目录数据一直在更新,但是 metadata 没有数据,导致查询的时候没有数,因为 Iceberg 的查询是需要元数据来索引真实数据的。SQL Client 默认没有开启 checkpoint,需要通过配置文件来开启状态。所以会导致 data 目录写入数据而 metadata 目录不写入元数据。
PS:无论通过 SQL 还是 Datastream 入湖,都必须开启 Checkpoint。
7. 数据样例
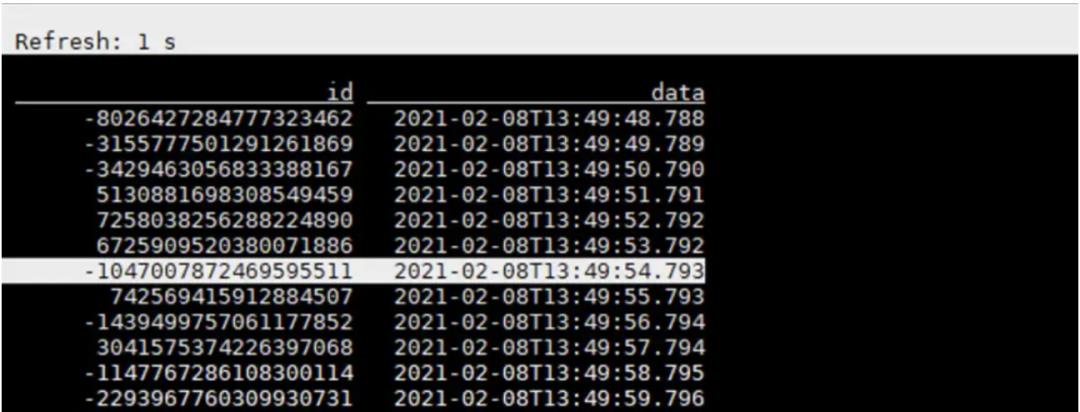
下面两张图展示的是实时查询 Iceberg 的效果,一秒前和一秒后的数据变化情况。
一秒前的数据
一秒后刷新的数据
四、痛点二:
Flink 结合 Hive 的近实时越来越慢
1. 痛点介绍
选用 Flink + Hive 的近实时架构虽然支持了实时读写,但是这种架构带来的问题是随着表和分区增多,将会面临以下问题:
元数据过多
Hive 将分区改为小时 / 分钟级,虽然提高了数据的准实时性,但是 metestore 的压力也是显而易见的,元数据过多导致生成查询计划变慢,而且还会影响线上其他业务稳定。
数据库压力变大
随着元数据增加,存储 Hive 元数据的数据库压力也会增加,一段时间后,还需要对该库进行扩容,比如存储空间。
2. 解决方案
将原先的 Hive 近实时迁移到 Iceberg。为什么 Iceberg 可以处理元数据量大的问题,而 Hive 在元数据大的时候却容易形成瓶颈?
Iceberg 是把 metadata 维护在可拓展的分布式文件系统上,不存在中心化的元数据系统;
Hive 则是把 partition 之上的元数据维护在 metastore 里面(partition 过多则给 mysql 造成巨大压力),而 partition 内的元数据其实是维护在文件内的(启动作业需要列举大量文件才能确定文件是否需要被扫描,整个过程非常耗时)。
五、优化实践
1. 小文件处理
Iceberg 0.11 以前,通过定时触发 batch api 进行小文件合并,这样虽然能合并,但是需要维护一套 Actions 代码,而且也不是实时合并的。
Table table = findTable(options, conf);Actions.forTable(table).rewriteDataFiles() .targetSizeInBytes(10 * 1024) // 10KB .execute();
Iceberg 0.11 新特性,支持了流式小文件合并。
通过分区/存储桶键使用哈希混洗方式写数据、从源头直接合并文件,这样的好处在于,一个 task 会处理某个分区的数据,提交自己的 Datafile 文件,比如一个 task 只处理对应分区的数据。这样避免了多个 task 处理提交很多小文件的问题,且不需要额外的维护代码,只需在建表的时候指定属性 write.distribution-mode,该参数与其它引擎是通用的,比如 Spark 等。
CREATE TABLE city_table ( province BIGINT, city STRING ) PARTITIONED BY (province, city) WITH ( 'write.distribution-mode'='hash' );
2. Iceberg 0.11 排序
■ 2.1 排序介绍
在 Iceberg 0.11 之前,Flink 是不支持 Iceberg 排序功能的,所以之前只能结合 Spark 以批模式来支持排序功能,0.11 新增了排序特性的支持,也意味着,我们在实时也可以体会到这个好处。
排序的本质是为了扫描更快,因为按照 sort key 做了聚合之后,所有的数据都按照从小到大排列,max-min 可以过滤掉大量的无效数据。

■ 2.2 排序 demo
insert into Iceberg_table select days from Kafka_tbl order by days, province_id;
3. Iceberg 排序后 manifest 详解
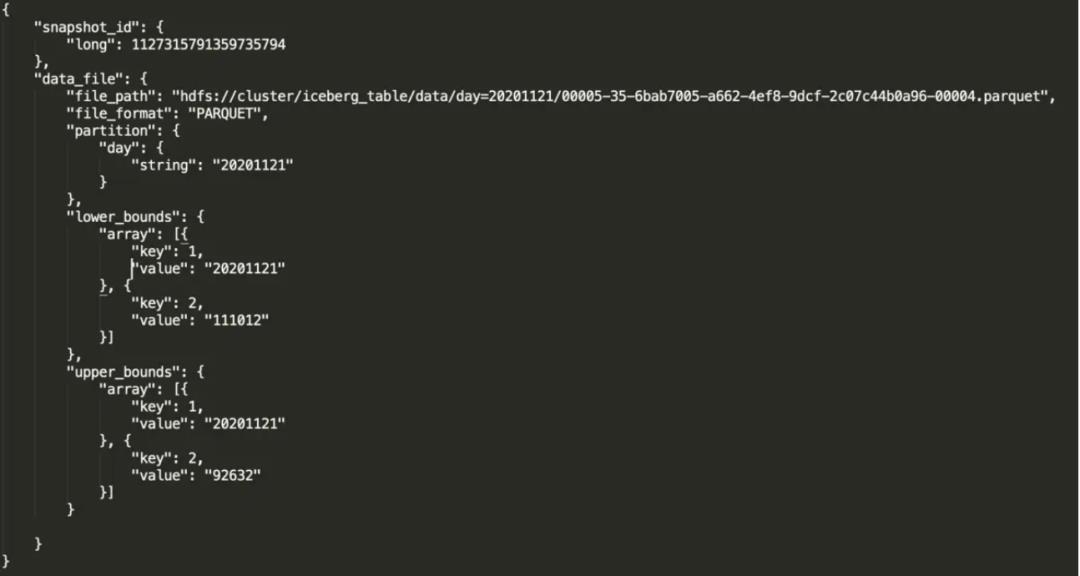
参数解释
file_path:物理文件位置。
partition:文件所对应的分区。
lower_bounds:该文件中,多个排序字段的最小值,下图是我的 days 和 province_id 最小值。
upper_bounds:该文件中,多个排序字段的最大值,下图是我的 days 和 province_id 最大值。
通过分区、列的上下限信息来确定是否读取 file_path 的文件,数据排序后,文件列的信息也会记录在元数据中,查询计划从 manifest 去定位文件,不需要把信息记录在 Hive metadata,从而减轻 Hive metadata 压力,提升查询效率。
利用 Iceberg 0.11 的排序特性,将天作为分区。按天、小时、分钟进行排序,那么 manifest 文件就会记录这个排序规则,从而在检索数据的时候,提高查询效率,既能实现 Hive 分区的检索优点,还能避免 Hive metadata 元数据过多带来的压力。
六、总结
相较于之前的版本来说,Iceberg 0.11 新增了许多实用的功能,对比了之前使用的旧版本,做以下总结:
Flink + Iceberg 排序功能
在 Iceberg 0.11 以前,排序功能集成了 Spark,但没有集成 Flink,当时用 Spark + Iceberg 0.10 批量迁移了一批 Hive 表。在 BI 上的收益是:原先 BI 为了提升 Hive 查询速度建了多级分区,导致小文件和元数据过多,入湖过程中,利用 Spark 排序 BI 经常查询的条件,结合隐式分区,最终提升 BI 检索速度的同时,也没有小文件的问题,Iceberg 有自身的元数据,也减少了 Hive metadata 的压力。
Icebeg 0.11 支持了 Flink 的排序,是一个很实用的功能点。我们可以把原先 Flink + Hive 的分区转移到 Iceberg 排序中,既能达到 Hive 分区的效果,也能减少小文件和提升查询效率。
实时读取数据
通过 SQL 的编程方式,即可实现数据的实时读取。好处在于,可以把实时性要求不高的,比如业务可以接受 1-10 分钟延迟的数据放入 Iceberg 中 ,在减少 Kafka 压力的同时,也能实现数据的近实时读取,还能保存历史数据。
实时合并小文件
在Iceberg 0.11以前,需要用 Iceberg 的合并 API 来维护小文件合并,该 API 需要传入表信息,以及定时信息,且合并是按批次这样进行的,不是实时的。从代码上来说,增加了维护和开发成本;从时效性来说,不是实时的。0.11 用 Hash 的方式,从源头对数据进行实时合并,只需在 SQL 建表时指定 ('write.distribution-mode'='hash') 属性即可,不需要手工维护。
以上是关于Flink + Iceberg 在去哪儿的实时数仓实践的主要内容,如果未能解决你的问题,请参考以下文章