分布式文件系统HDFS
Posted 一杯敬朝阳一杯敬月光
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式文件系统HDFS相关的知识,希望对你有一定的参考价值。
HDFS概述
HDFS概述
- 分布式
- commodity hardware,运行在廉价机器上
- highly fault-tolerant,高容错
- high throughput,高吞吐
- large data sets,适用于大数据
文件系统:Linux、Windows、Mac...
目录结构: C /
存放的是文件或者文件夹
对外提供服务:创建、修改、删除、查看、移动等
HDFS是一个分布式的文件系统
普通文件系统 VS 分布式文件系统
普通文件系统
- 单机
分布式文件系统
- 分布式文件系统能够横跨N个机器
HDFS设计目标
- Hardware Failure 硬件错误
- each storing part of the file system’s data,每个机器只存储部分数据,blocksize=128M
- block存放在不同的机器上的,由于容错,HDFS默认采用3副本机
- Streaming Data Access 流式数据访问
- The emphasis is on high throughput of data access rather than low latency of data access,强调高吞吐量而非低延迟
- Large Data Sets 大规模数据集
- Moving Computation is Cheaper than Moving Data,移动计算比移动数据更划算。
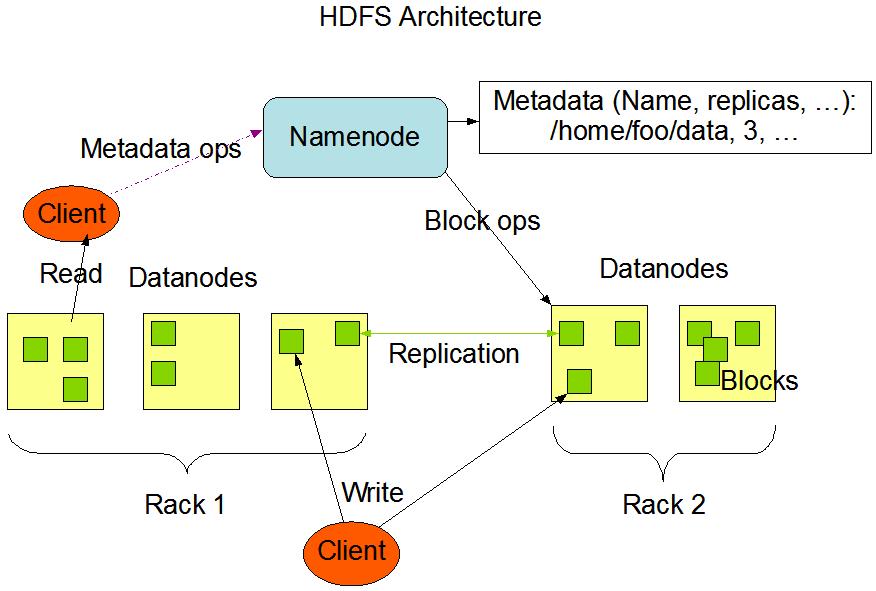
HDFS架构 *****
NameNode and DataNodes
1)NameNode(master) and DataNodes(slave)
2)master/slave 的架构
3)NameNode(NN):
the file system namespace,管理文件系统
/home/hadoop/software
/app
regulates access to files by clients.提供客户端对文件的访问
4)DataNodes(DN):storage,数据存储
5)HDFS exposes a file system namespace and allows user data to be stored in files。HDFS公开了一个文件系统命名空间,并允许用户数据存储在文件中。
6)a file is split into one or more blocks ,一个文件被拆分成多个块
blocksize:128M,则一个150M的数据将被拆成2个block
7)blocks are stored in a set of DataNodes,blocks存放在一系列的DN上,目的是为了容错。
8)NameNode executes file system namespace operations:CRUD,NameNode执行文件系统命名空间操作:增删改查
9)NameNode determines the mapping of blocks to DataNodes,决定DataNode和块的映射关系。
例如:a.txt=150M, blocksize:128M,则a.txt被拆分成2个block,一个是block1:128M,另一个是block2:22M。那么block1存放在哪个DN?block2存放在哪个DN?这个用户是无法感知的,NN会将文件拆分成多个块,这些块会被存放在不同的DN上。
a.txt 存放数据
block1:128M,192.168.199.1
block2:22M,192.168.199.3
get a.txt 获取数据也要通过NN,否则拿不到映射关系,即所谓的元数据信息,将这些数据拿到进行合并。
其实HDFS并不神秘,就是一个拆文件组合文件的过程,该过程对于用户来说是不感知的。
10)通常情况下:一个Node部署一个组件
文件系统NameSpace详解
The NameNode maintains the file system namespace. Any change to the file system namespace or its properties is recorded by the NameNode. An application can specify the number of replicas of a file that should be maintained by HDFS. The number of copies of a file is called the replication factor of that file. This information is stored by the NameNode.NameNode维护文件系统名称空间。对文件系统名称空间或其属性的任何更改都由NameNode记录。应用程序可以指定HDFS应该维护的文件副本的数量。文件的副本数称为该文件的副本系数。这些信息存储在NameNode。
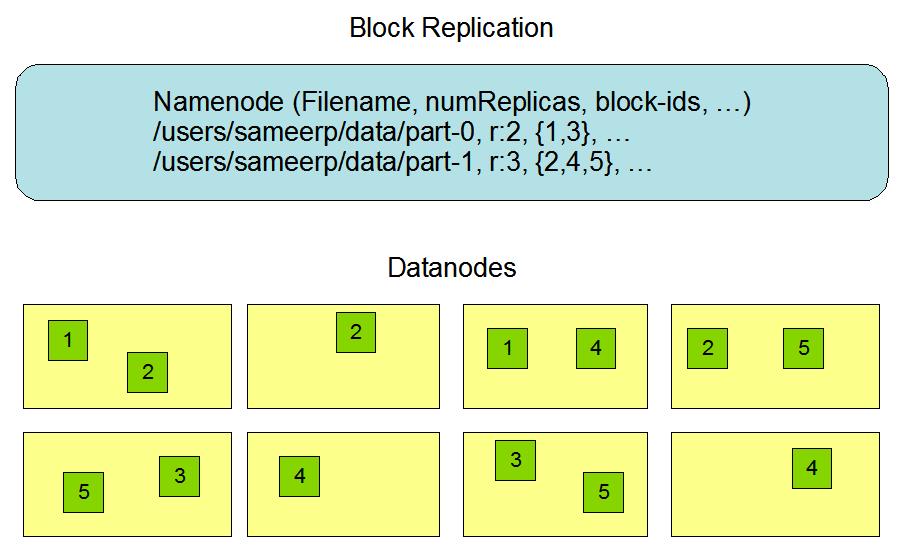
HDFS副本机制
- 每个文件存储为一系列的block
- 一个文件中除最后一个块外的所有块的大小都相同
- 每个文件都可以配置块大小和复制因子。应用程序可以指定文件的副本数。复制因子可以在文件创建时指定,以后可以更改。
- 除了追加appends和阶段truncates之外,HDFS中的文件只写一次。
- 在任何时候都严格地只有一个writer。
下面的part-0有2个副本,part-1有3个副本
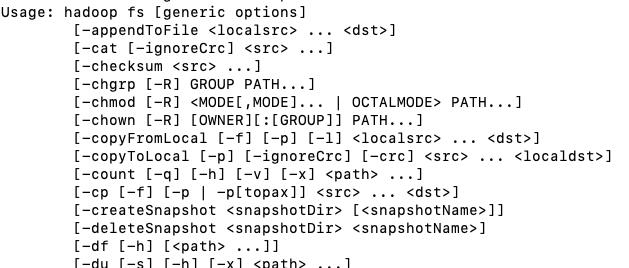
HDFS命令行操作
$HADOOP_HOME/bin下hadoop可以查看该命令提示,同理hadoop fs
hadoop fs -ls /
hadoop fs -put README.txt /
hadoop fs -copyFromLocal cdh_version.properties / 将文件从本地copy到hadoop
hadoop fs -moveFromLocal cdh_version.properties_bak / 将文件从本地move到hadoop,操作后本地该文件会被删除
hadoop fs -cat /README.txt
hadoop fs -text /README.txt
hadoop fs -get /README.txt 从hadoop copy到本地
hadoop fs -mkdir /hdfs-test 创建目录
hadoop fs -mv /README.txt /hdfs-test/ 将文件从hadoop的根目录move到/hdfs-test目录下
hadoop fs -cp /hdfs-test/README.txt /hdfs-test/README.txt-bak 将文件从hadoop的一个目录下copy到hadoop的另一个目录下文件合并
命令:hadoop fs -getmerge /hdfs-test ./t.txt
将hadoop文件系统指定目录下的文件拷贝到本地(本地的文件是hadoop指定目录下文件合并后的结果,不会影响hadoop文件系统该目录下的文件存储)
hadoop fs -ls /hdfs-test:有两个文件
-rw-r--r-- 1 hh supergroup 1366 2021-05-24 21:49 /hdfs-test/README.txt
-rw-r--r-- 1 hh supergroup 1366 2021-05-24 22:26 /hdfs-test/README.txt-bak
执行命令后,会在本地得到合并后的t.txt文件: ls -Al
-rw-r--r-- 1 hh staff 2732 5 24 22:32 t.txt
删除文件
命令:hadoop fs -rm /cdh_version.properties
将文件从hadoop的文件系统中移除
删除目录:
命令:hadoop fs -rmdir /hdfs-test
只能删除空目录,目录下不为空,用该命令不能删除
命令:hadoop fs -rm -r /hdfs-test
删除目录
HDFS存储机制
put:1 file ==> 1 ... n block ==> 存放在不同的节点上
get:去nn上查找这个file对应的元数据信息
例如:我们存储一个414M的文件hadoop-2.6.0-cdh5.15.1.tar.gz,其将会被切成3个128M的block+1个30M的block
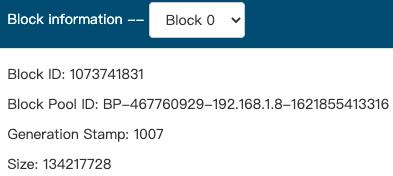
我们看看文件存储在什么地方,我们在配置中设置了
<property>
<name>hadoop.tmp.dir</name>
<value>/Users/hh/app/tmp</value>
</property>所以去该文件下找,最终在该路径下/Users/hh/app/tmp/dfs/data/current/BP-467760929-192.168.1.8-1621855413316/current/finalized/subdir0/subdir0可以看到数据的存储,其中路径里的BP-467760929-192.168.1.8-1621855413316对应图中的Block Pool ID, 然后我们的block id从 1073741831-1073741834共4个,文件名blk_后面的id对应上图的Block ID。
-rw-r--r-- 1 hh staff 128M 5 25 00:02 blk_1073741831
-rw-r--r-- 1 hh staff 1.0M 5 25 00:02 blk_1073741831_1007.meta
-rw-r--r-- 1 hh staff 128M 5 25 00:02 blk_1073741832
-rw-r--r-- 1 hh staff 1.0M 5 25 00:02 blk_1073741832_1008.meta
-rw-r--r-- 1 hh staff 128M 5 25 00:02 blk_1073741833
-rw-r--r-- 1 hh staff 1.0M 5 25 00:02 blk_1073741833_1009.meta
-rw-r--r-- 1 hh staff 30M 5 25 00:02 blk_1073741834
-rw-r--r-- 1 hh staff 239K 5 25 00:02 blk_1073741834_1010.meta
我们尝试自己将这四个文件拼起来,Block 0 - Block 4的id由小到大,我们也按这个顺序拼,[cat blk_1073741831 >>hadoop.tgz cat blk_1073741832 >>hadoop.tgz cat blk_1073741833 >>hadoop.tgz cat blk_1073741834 >>hadoop.tgz],最终得到大小为414M的hadoop.tgz,与上传的hadoop-2.6.0-cdh5.15.1.tar.gz一样大,同时hadoop.tgz这个文件是可以解压出来的。但是若我们不按照顺序拼接,例如[cat blk_1073741834 >>hadoop.tgz cat blk_1073741831 >>hadoop.tgz cat blk_1073741832 >>hadoop.tgz cat blk_1073741833 >>hadoop.tgz],虽然也能得到同样大小的hadoop.tgz文件,但却没有办法解压。
由此可见HDFS并不神秘,就是一个拆文件组合文件的过程,自然了,HDFS做的比较复杂鲁棒,有副本容错等等。
参考:慕课网-Hadoop 系统入门+核心精讲
以上是关于分布式文件系统HDFS的主要内容,如果未能解决你的问题,请参考以下文章