资源调度框架YARN
Posted 一杯敬朝阳一杯敬月光
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了资源调度框架YARN相关的知识,希望对你有一定的参考价值。
目录
YARN产生背景
- MapReduce1.x存在的问题
- 资源利用率 & 运维成本
- 解决方案:所有的计算框架运行在一个集群中,共享一个集群的资源,按需分配
========================附========================
MapReduce1.x
- master / slave架构:JobTracker / TaskTracker
- JobTracker
- 单点,整个架构只有一个JobTracker
- 压力大:负责和client和TaskTracker之间的请求通信
- 集群想要扩展,JobTracker是一个很大的瓶颈
- 仅仅只能支持MapReduce作业(例如Spark等无法在上面跑)
MapReduce1.x架构图

左侧是没有YARN的,有三个集群,可以看到三个集群在不同的时候可能会有空闲,这些资源在多个集群中得不到充分的利用,若可以整合到一个集群,就可以充分利用集群了。
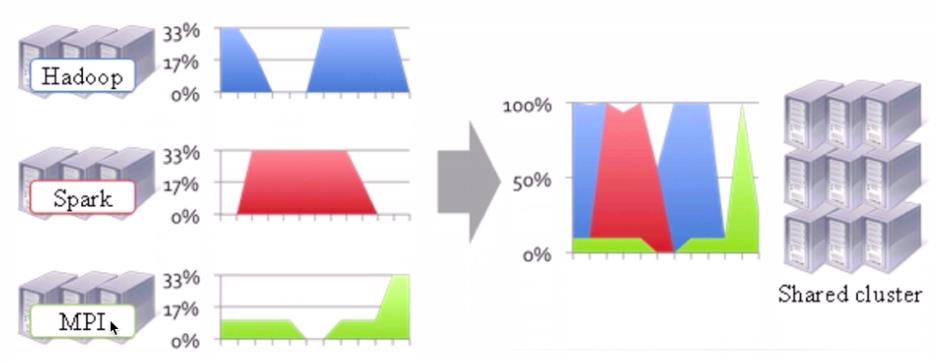
YARN:集群的资源管理,在YARN之上能跑很多不同的作业 ,YARN是在Hadoop2.x采用与生产的,1.x也有一些但还是不能用于生产环境。
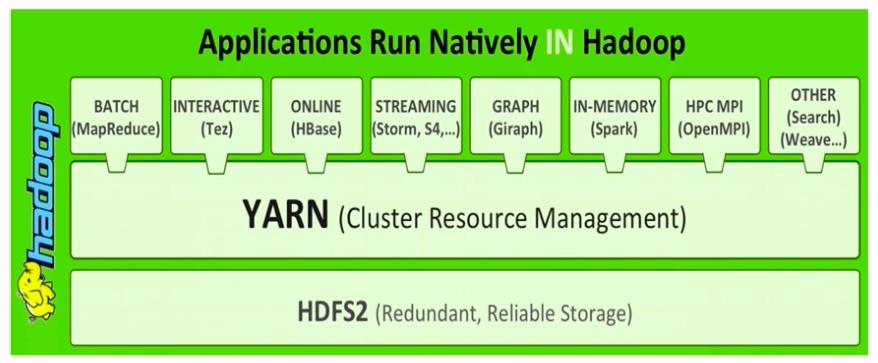
YARN概述
YARN: Yet Another Resource Negotiator
- 通用的资源管理系统
- 为上层应用提供统一的资源管理和调度
- 将JobTracker拆分成resource management和job scheduling/monitoring两个独立的功能(The fundamental idea of YARN is to split up the functionalities of resource management and job scheduling/monitoring into separate daemons)
- 重要概念
- master:resource management: ResourceManager(RM)
- job scheduling/monitoring: per-application ApplicationMaster(AM)
- slave:NodeManager(NM)

========================附========================
The fundamental idea of YARN is to split up the functionalities of resource management and job scheduling/monitoring into separate daemons. The idea is to have a global ResourceManager (RM) and per-application ApplicationMaster (AM). An application is either a single job or a DAG of jobs. YARN的基本思想是将资源管理和作业调度/监视的功能划分为单独的守护进程。拥有一个全局资源管理器(RM)和每个应用程序应用程序管理员(AM)。应用程序可以是单个作业,也可以是DAG作业。
The ResourceManager and the NodeManager form the data-computation framework. The ResourceManager is the ultimate authority that arbitrates resources among all the applications in the system. The NodeManager is the per-machine framework agent who is responsible for containers, monitoring their resource usage (cpu, memory, disk, network) and reporting the same to the ResourceManager/Scheduler. ResourceManager和NodeManager构成了数据计算框架。ResourceManager对所有应用能使用的资源有最终的决定权。NodeManager是每台机器的框架代理,负责容器,监视其资源使用情况(cpu、内存、磁盘、网络),并将其报告给ResourceManager/Scheduler。
The per-application ApplicationMaster is, in effect, a framework specific library and is tasked with negotiating resources from the ResourceManager and working with the NodeManager(s) to execute and monitor the tasks. 每个应用程序ApplicationMaster实际上是一个特定于框架的库,其任务是与ResourceManager协商资源,并与NodeManager协作执行和监视任务。
YARN架构详解
YARN架构
- client、ResourceManager、NodeManager、ApplicationMaster
- master / slave: RM / NM
- client:向RM提交任务、杀死任务等等
- ApplicationMaster
- 每个应用程序对应一个AM
- AM向RM申请资源用于在NM上启动对应的Task
- 数据切分
- 为每个task向RM申请资源(container)
- NM的通信
- 任务的监控
- NodeManager:有多个
- 干活
- 向RM发送心跳信息、任务的执行情况,启动任务
- 接受来自RM的请求来启动任务
- 处理来自AM的命令
- ResourceManager:集群中同一时刻对外提供服务的只有一个,负责资源相关
- 处理来自客户端的请求:提交、杀死
- 启动/监控AM:因为一个应用对应一个AM
- 监控NM
- 资源相关
- container:任务的运行抽象
- memory、cpu ... 的抽象
- task是运行在container里面的
- 可以运行am,也可以运行map / reduce Task
YARN执行流程
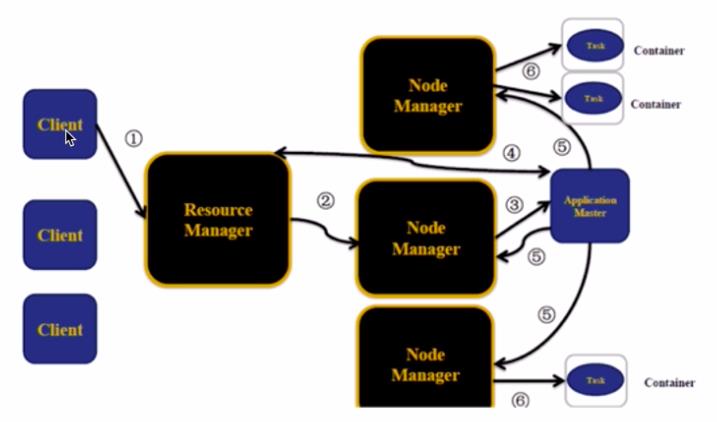
- 客户端提交应用程序到YARN,必先和RM交互
- NM接受来自RM的命令为我们的job分配第一个container,例如这边RM要求在第二个NM上分配一个container
- container运行我们作业的AM
- AM启动后需要先注册到RM(我们的客户端可以和RM通信,而AM又注册到RM上去了,所以客户端可以通过AM查询到作业运行的情况),AM到RM上申请资源,申请成功则箭头回来
- 第4步申请到资源后,去相应的NM上启动container
- 被启动的container跑我们的task
运行过程中,AM知道task的运行情况。
YARN环境部署
YARN on Single Node
etc/hadoop/mapred-site.xml,即让我们的MapReduce运行在YARN之上
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>etc/hadoop/yarn-site.xml,RM和NM相当于一对多的,那么NM配在哪,还是和Hadoop一样,有一个slave,已经配过了。
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>启动前
77219 NameNode
77305 DataNode
16889 Launcher
启动RM和NM
sbin/start-yarn.sh
启动后
77219 NameNode
21414 NodeManager
77305 DataNode
16889 Launcher
21341 ResourceManager
现在可以去浏览器上愉快的访问啦,http://localhost:8088/cluster
提交作业:
hadoop jar hadoop-mapreduce-examples-2.6.0-cdh5.15.1.jar(jar包) pi(作业名称)[.....](每个作业需要的参数)
报错
Error: org.apache.hadoop.mapreduce.task.reduce.Shuffle$ShuffleError: error in shuffle in fetcher#1
at org.apache.hadoop.mapreduce.task.reduce.Shuffle.run(Shuffle.java:134)
at org.apache.hadoop.mapred.ReduceTask.run(ReduceTask.java:376)
解决方法:
hdfs-site.xml中hadoop.tmp.dir配的什么目录,在yarn-site.xml的yarn.nodemanager.local-dirs中就配这个目录加上nm-local-dir
<property> <name>yarn.nodemanager.local-dirs</name> <value>/Users/hh/app/tmp/nm-local-dir</value> </property>
- 打包,在工程所在的目录(hadoop-train-v2)下,运行: mvn clean package -DskipTests,其中-DskipTests表示跳过测试用例
- 这个包在工程目录的target目录下,找到hadoop-train-v2-1.0这个jar文件,上传到服务器scp命令scp hadoop-train-v2-1.0.jar 用户名:服务器地址:~/lib/
- 将所需要的数据也上传服务器,scp access.log 用户名:服务器地址:~/data/
- 将数据从服务器上传到HDFS, hadoop fs -mkdir -p /access/input, hadoop fs -put access.log /access/input
- 运行:hadoop jar hadoop-train-v2-1.0.jar com.imooc.bigdata.hadoop.mr.access.AccessYARNApp(包名+类名) /access/input/access.log /access/output/
- 到YARN UI(8088)上去观察作业的运行情况
- 到输出目录去查看对应的输出结果
用脚本跑的话,写成一个xxx.sh的脚本,脚本内容同上,类似hadoop jar xxx/xxx/hadoop-train-v2-1.0.jar com.imooc.bigdata.hadoop.mr.access.AccessYARNApp(包名+类名) hdfs://xxx.xxx.xxx::8020/access/input/access.log hdfs://xxx.xxx.xxx::8020/access/output/,再给脚本赋一下可执行权限:chmod u+x xxx.sh。运行./xxx.sh 即可。
参考:慕课网 - Hadoop 系统入门+核心精讲
Hadoop官网
以上是关于资源调度框架YARN的主要内容,如果未能解决你的问题,请参考以下文章