论文泛读108一种基于强化学习的粗到细问答系统
Posted 及时行樂_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文泛读108一种基于强化学习的粗到细问答系统相关的知识,希望对你有一定的参考价值。
贴一下汇总贴:论文阅读记录
论文链接:《A Coarse to Fine Question Answering System based on Reinforcement Learning》
一、摘要
在本文中,我们提出了一个基于强化学习的从粗到细的问答(CFQA)系统,该系统可以通过选择适当的动作来有效地处理不同长度的文档。该系统是使用基于演员-评论家的深度强化学习模型设计的,以实现多步问答。与以前针对主要包含短文档或长文档的数据集的 QA 模型相比,我们的多步粗到精模型利用了多个系统模块的优点,可以处理短文档和长文档。因此,与当前最先进的模型相比,该系统获得了更好的准确性和更快的训练速度。我们在四个 QA 数据集 WIKEREADING、WIKIREADING LONG、CNN 和 SQuAD 上测试我们的模型,并演示 1.3%-1.7% 与使用最先进模型的基线相比,精度提高了 1.5-3.4 倍的训练速度。
二、结论
在本文中,我们提出了一个多步骤粗到精的问答(CFQA)系统,它可以通过选择适当的动作来有效地处理长文档和短文档。该系统在四个不同的质量保证数据集上显示了良好的准确性和训练速度。提出了用DRL模型来指导多步问答推理过程的新概念,使其更接近人类的判断行为。在未来,我们希望通过增加更多可能的动作和状态来研究如何改进系统的设计,从而使系统更加智能和快速。
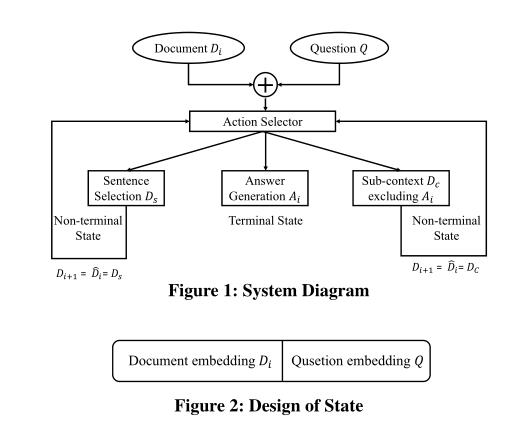
三、模型
包括四个部分:第一部分是基于DRL的动作选择器,第二部分是句子选择模块(M1),第三部分是答案生成模块(M2),最后一部分是子上下文生成模块(M3)。
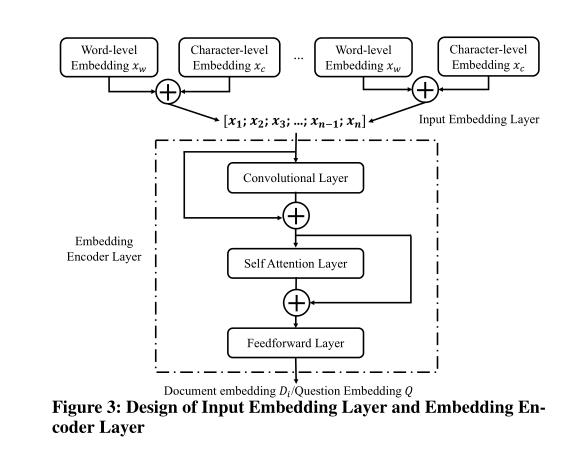
输入嵌入层和嵌入编码器层的设计:
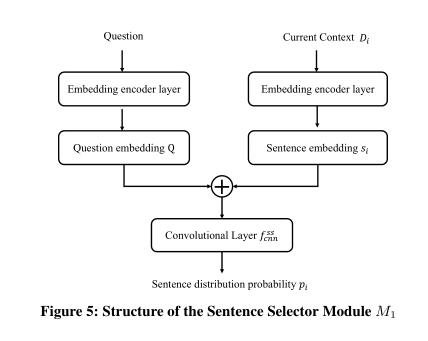
句子选择模块M1的结构:
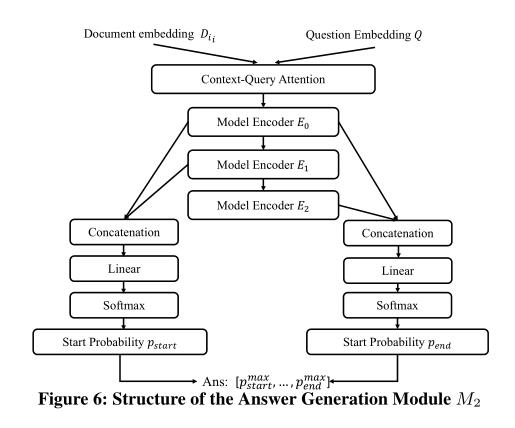
答案生成模块M2的结构:
该模型主要是在速度上的提升,在准确率上并不是最优的模型,也许会在工业应用中实时问答上有不错的效果。
以上是关于论文泛读108一种基于强化学习的粗到细问答系统的主要内容,如果未能解决你的问题,请参考以下文章