理解HashMap底层数据结构
Posted dingwen_blog
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了理解HashMap底层数据结构相关的知识,希望对你有一定的参考价值。
在
JDK8中HashMap是基于数组+链表+红黑树的实现。
hash
hash哈希,也称为散列。基本原理是把任意长度的输入通过一定的映射规则转换为固定长度的输出。映射规则就是对应的哈希算法。由于输出空间值小于输入空间值,根据“抽屉原理”一定会存在不同的输入转换为相同的输出的情况。作为一个好的哈希算法需要做到让这种冲突发生的几率尽可能小。
常用解决哈希冲突方法
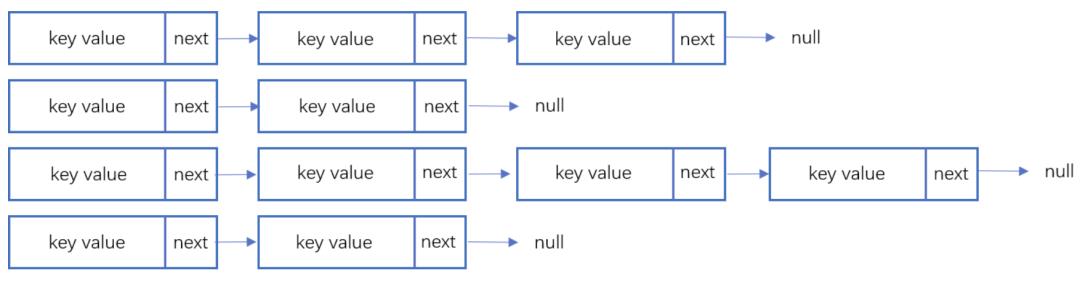
链地址法
链表地址法是使用一个链表数组,来存储相应数据,当hash遇到冲突的时候依次添加到链表的后面进行处理。
开放地址法
开放地址法是指大小为 M 的数组保存 N 个键值对,其中 M > N。我们需要依靠数组中的空位解决碰撞冲突。基于这种策略的所有方法被统称为“开放地址”哈希表。线性探测法,就是比较常用的一种“开放地址”哈希表的一种实现方式。线性探测法的核心思想是当冲突发生时,顺序查看表中下一单元,直到找出一个空单元或查遍全表。简单来说就是:一旦发生冲突,就去寻找下 一个空的散列表地址,只要散列表足够大,空的散列地址总能找到。
array
array数组, 是一种线性表数据结构。它用一组连续的内存空间,来存储一组具有相同类型的数。利用下标操作元素。查找效率高,插入、删除效率低(需要挪位等)
链表
链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。插入、删除效率高,查找效率低。
红黑树
红黑树是一种含有红黑结点并能自平衡的二叉查找树
HashMap
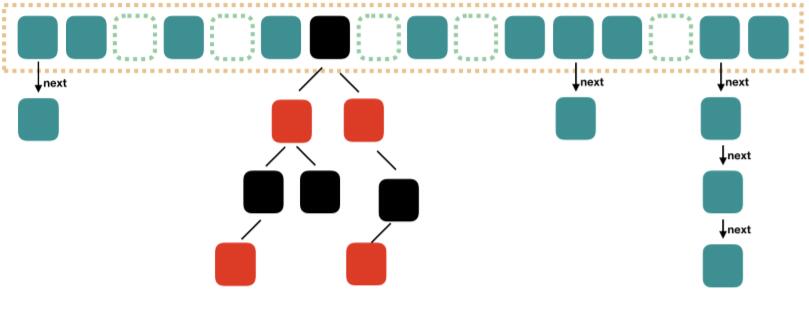
我们都知道
HashMap是以key、value的形式存储,存储时在内存中初始化一个长度为16的数组,根据一定的哈希算法得到哈希值。这个哈希值作为数组的下标。当哈希值冲突时数组中的元素将转为链表,同一个链表的元素哈希值一致。当链表长度达到8时,JDK8会把当前链表转为红黑树来提升效率。
参考文章
https://www.zhihu.com/question/26762707/answer/890181997
https://zhuanlan.zhihu.com/p/28501879
https://zhuanlan.zhihu.com/p/28587782
以上是关于理解HashMap底层数据结构的主要内容,如果未能解决你的问题,请参考以下文章