文献阅读10期:ATTENTION, LEARN TO SOLVE ROUTING PROBLEMS!
Posted RaZLeon
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了文献阅读10期:ATTENTION, LEARN TO SOLVE ROUTING PROBLEMS!相关的知识,希望对你有一定的参考价值。
[ 文献阅读·路径规划 ] ATTENTION, LEARN TO SOLVE ROUTING PROBLEMS! [1]
推荐理由:这篇应该不用多说了,ATTENTION模型做路径规划,算是一篇MileStone了。
1. Attention Model
- 一个TSP实例假定有n个节点, i ∈ { 1 , … , n } i \\in\\{1, \\ldots, n\\} i∈{1,…,n},每个节点的特征为 x i \\mathbf{x}_{i} xi,对于TSP问题来说, x i \\mathbf{x}_{i} xi即节点i的坐标,且构成图为全连接图(其中包括自连接)。
- 总而言之,TSP问题的模型可以被认为是一个Graph Attention Network。
- 通过Mask来定义图结构。
- 解 π = ( π 1 , … , π n ) \\boldsymbol{\\pi}=\\left(\\pi_{1}, \\ldots, \\pi_{n}\\right) π=(π1,…,πn)为节点的排列组合
- 对于给定实例
s
\\mathcal{s}
s,选择解
π
\\pi
π的概率即一种随机策略概率
p
(
π
∣
s
)
p(\\boldsymbol{\\pi} \\mid s)
p(π∣s),则对于一个完整TSP问题,策略表达如下:
p θ ( π ∣ s ) = ∏ t = 1 n p θ ( π t ∣ s , π 1 : t − 1 ) (1) p_{\\theta}(\\boldsymbol{\\pi} \\mid s)=\\prod_{t=1}^{n} p_{\\boldsymbol{\\theta}}\\left(\\pi_{t} \\mid s, \\boldsymbol{\\pi}_{1: t-1}\\right)\\tag{1} pθ(π∣s)=t=1∏npθ(πt∣s,π1:t−1)(1) - 整个文章的大致思路是:把所有点依次输入编码器,然后解码器输出解序列。
1.1.编码器
- 如图1所示,本文采用了Transformer结构,但本文不使用位置编码所以节点Embedding的结果相比输入顺序没有改变。
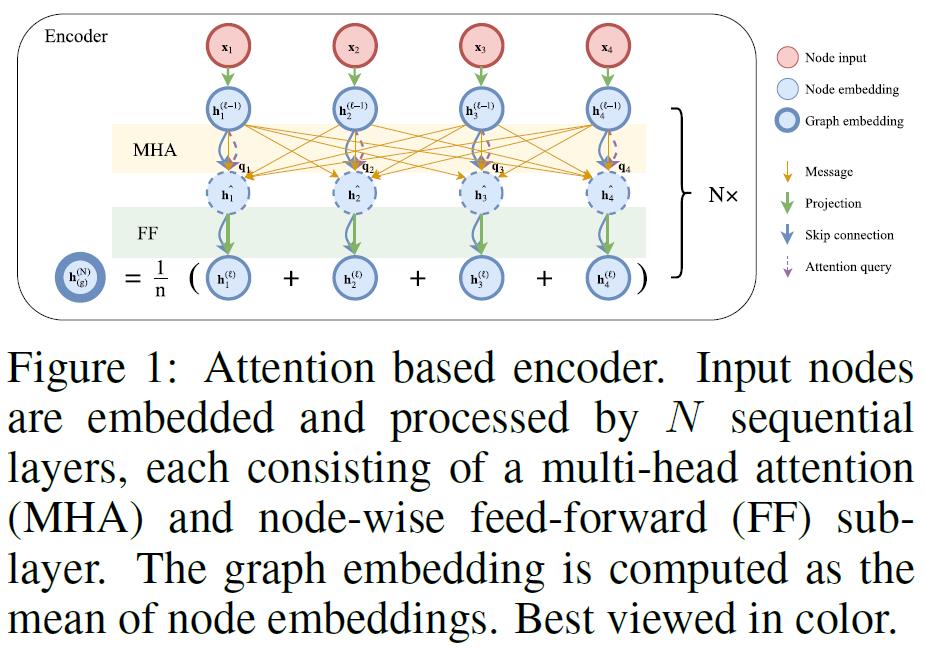
- 从NodeInput到GraphEmbedding总共分为两步,Multi-Head Attention(MHA)& Feed-Forward(FF):
h ^ i = B N ℓ ( h i ( ℓ − 1 ) + M H A i ℓ ( h 1 ( ℓ − 1 ) , … , h n ( ℓ − 1 ) ) ) (2) \\hat{\\mathbf{h}}_{i}=\\mathrm{B} \\mathrm{N}^{\\ell}\\left(\\mathbf{h}_{i}^{(\\ell-1)}+\\mathrm{MHA}_{i}^{\\ell}\\left(\\mathbf{h}_{1}^{(\\ell-1)}, \\ldots, \\mathbf{h}_{n}^{(\\ell-1)}\\right)\\right)\\tag{2} h^i=BNℓ(hi(ℓ−1)+MHAiℓ(h1(ℓ−1),…,hn(ℓ−1)))(2)
h i ( ℓ ) = B N ℓ ( h ^ i + F F ℓ ( h ^ i ) ) (3) \\mathbf{h}_{i}^{(\\ell)}=\\mathrm{BN}^{\\ell}\\left(\\hat{\\mathbf{h}}_{i}+\\mathrm{FF}^{\\ell}\\left(\\hat{\\mathbf{h}}_{i}\\right)\\right)\\tag{3} hi(ℓ)=BNℓ(h^i+FFℓ(h^i))(3)
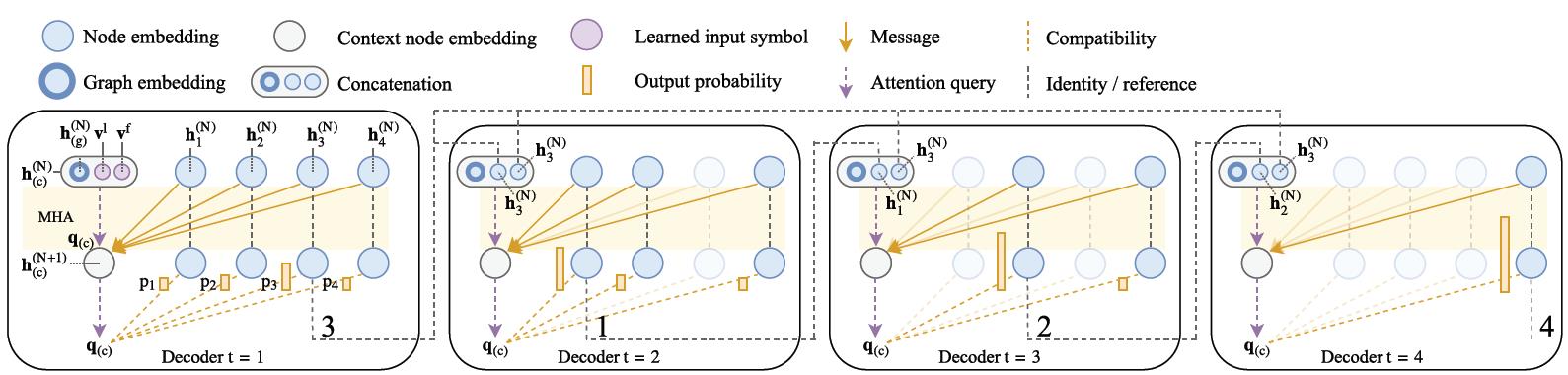
2.解码器
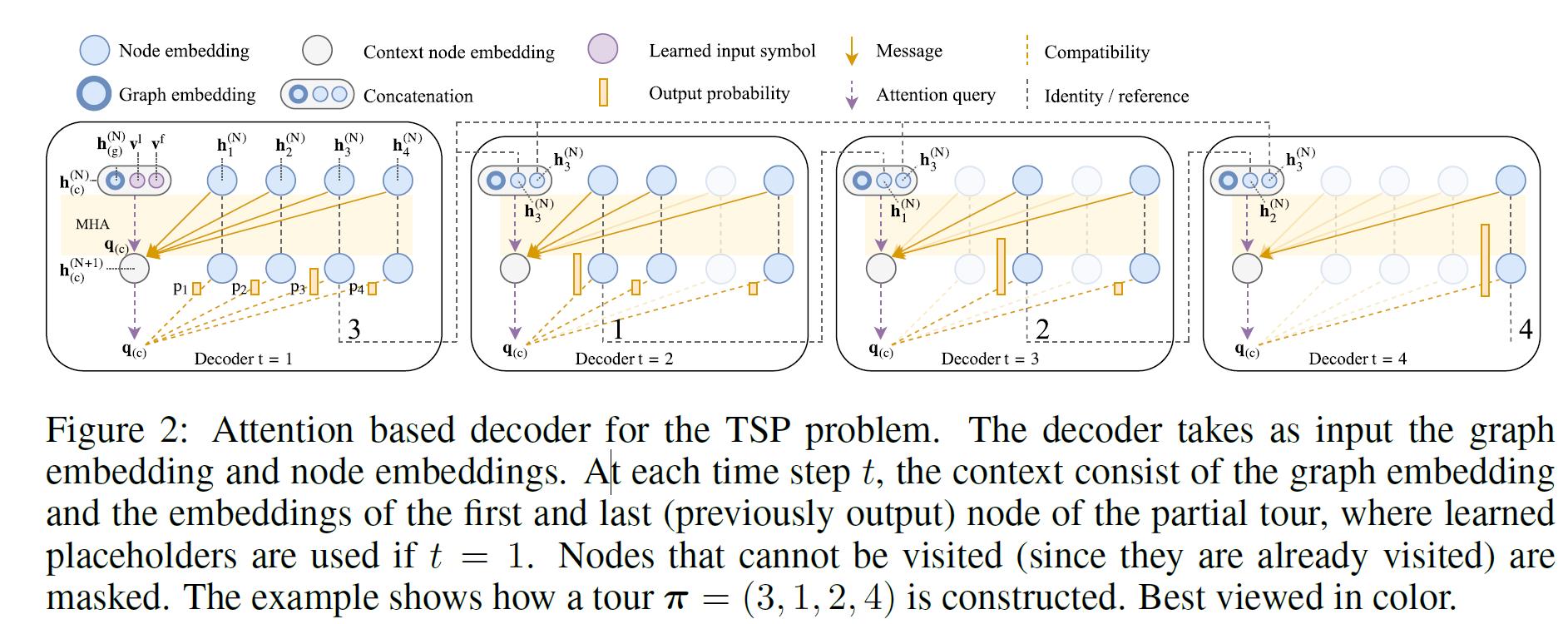
- Context embedding:解码器在t时刻的上下文有两个源头,一是编码器,二是直到t时刻的输出。每一个TSP问题,由三个部分组成:Graph Embedding, 初始点,终点。对于第一时刻则有:
h ( c ) ( N ) = { [ h ‾ ( N ) , h π t − 1 ( N ) , h π 1 ( N ) ] t > 1 [ h ‾ ( N ) , v 1 , v f ] t = 1 (4) \\mathbf{h}_{(c)}^{(N)}=\\left\\{\\begin{array}{ll} {\\left[\\overline{\\mathbf{h}}^{(N)}, \\mathbf{h}_{\\pi_{t-1}}^{(N)}, \\mathbf{h}_{\\pi_{1}}^{(N)}\\right]} & t>1 \\\\ {\\left[\\overline{\\mathbf{h}}^{(N)}, \\mathbf{v}^{1}, \\mathbf{v}^{\\mathrm{f}}\\right]} & t=1 \\end{array}\\right.\\tag{4} h(c)(N)=⎩⎨⎧[h(N),hπt−1(N),hπ1(N)][h(N),v1,vf]t>1t=1(4) - 对于已经经过的点,需要Mask掉:
u ( c ) j = { q ( c ) T k j d k if j ≠ π t ′ ∀ t ′ < t − ∞ otherwise (6) u_{(c) j}=\\left\\{\\begin{array}{ll} \\frac{\\mathbf{q}_{(c)}^{T} \\mathbf{k}_{j}}{\\sqrt{d_{\\mathrm{k}}}} & \\text { if } j \\neq \\pi_{t^{\\prime}} \\quad \\forall t^{\\prime}<t \\\\ -\\infty & \\text { otherwise } \\end{array}\\right.\\tag{6} u(c)j={dkq(c)Tkj−∞ if j=πt′∀t′<t otherwise 文献阅读21期:Attention mechanisms and deep learning for machine vision: A survey
文献阅读21期:Attention mechanisms and deep learning for machine vision: A survey
文献阅读21期:Attention mechanisms and deep learning for machine vision: A survey
文献阅读21期:Attention mechanisms and deep learning for machine vision: A survey
论文阅读-ICLR2019-ATTENTION, LEARN TO SOLVE ROUTING PROBLEMS
文献阅读:Synthesizer: Rethinking Self-Attention in Transformer Models