Pytorch的独特归纳
Posted MarToony|名角
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Pytorch的独特归纳相关的知识,希望对你有一定的参考价值。
我相信书本中的内容即使归纳得再详细,也需要自己动手归纳,因为过程很重要。
归纳的价值取决于其内容是否有价值:归纳的体系和归纳的侧重点。
2.4 pytorch包的结构
pytorch主要模块
归纳特点:一句话,各模块的作用;一句话,额外解释。
- torch模块:常用的激活函数和面向张量的操作
- torch.Tensor模块:定义张量的类型和相应操作方法(比如,是否在原张量基础上进行修改)
- torch.sparse模块:定义稀疏张量及相应操作的方法
- torch.cuda模块:定义和cuda运算相关的函数(比如,cuda是否可用,清除GPU缓存等)
- torch.nn模块:定义神经网络的模块和系列损失函数。构建模型时,通过继承nn.Module类并重写forward方法实现。
- torch.nn.functional函数模块:定义和神经网络模块相关的函数(比如卷积函数和池化函数)。torch.nn中的模块一般会调用torch.nn.functional中的函数。
- torch.nn.init模块:定义神经网络的权重初始化方法。这里的初始化方法都是inplace原地操作。
- torch.optim模块:定义优化器和学习率的衰减算法。
- torch.autograd模块:定义自动微分算法函数。
- torch.distributed模块:提供pytorch分布式并行运行的环境。
- pytorch分布式工作原理
- torch.distributions模块:定义针对不同分布的采样策略。
- torch.hub模块:定义预训练好的模型与相应模型的支持方法。
- torch.jit模块:即时编译器使pytorch的动态图转换成可以优化和序列化的静态图。
- torch.multiprocessing模块:定义多进程API。启动不同的进程,运行不同的模型,并且实现进程间的张量共享(本质使共享内存的方式)。
- torch.random模块:定义保存和设置随机数生成器状态的方法。
- 设置随机数种子的意义
- torch.onnx模块:定义pytorch导出和载入ONNX格式的深度学习模型描述文件。
- ONNX文件存在的意义
可以不了解其具体的code,但是要对其有个大概的了解。
Pytorch辅助模块
一句话,模块的作用;一句话,作用的方式。
- torch.utils.bottlenect模块:检查深度学习模型中各模块的运行时间,以找到导致性能瓶颈的模块。
通过优化相应模块的运行时间,以优化整个模型性能。 - torch.utils.checkpoint模块:以计算时间换内存空间,实现对深度学习过程中的内存的节约。
因为模型训练过程中进行反向梯度计算需要反向传播,因此需要在构建计算图的时候保存中间的数据,这一点会增加训练的内存消耗。具体地,通过该模块记录中间数据的计算过程,然后丢弃这些中间数据,等需要时再按照记录的计算过程计算这些中间数据。 - torch.utils.cpp_extension模块:定义pytorch的C++扩展。
- torch.utils.data模块:定义数据集Dataset和数据载入器DataLoader。
前者包含了所有的数据,通过索引能够得到某一条特定的数据。
后者通过对数据集包装,通过对数据集进行随机排列Shuffle和采样Sample,得到一系列打乱数据顺序的迷你批次mini-batch。 - torch.utils.dlpacl模块:定义Pytorch张量和DLPack张量存储格式之间的转换。用于不同框架之间张量数据的交换。
- torch.utils.tensorboard模块:实现对模型训练过程中一些训练细节的可视化。
相关知识点
-
pytorch分布式工作原理:
- 启动多个并行的进程;
- 每个进程都拥有一个模型的备份;同时被输入不同的训练数据;
- 每个进程独立前向传播计算损失函数;
- 每个进程独立反向传播计算权重张量的梯度;
- 数据的收集Gather:所有进程的梯度值从其他节点转移到特定节点,计算平均梯度。
- 数据的广播Broadcast:平均梯度从某个特定节点传播到其他节点。
-
设置随机数种子的意义:
因为神经网络的训练使一个随机性质的过程,比如数据的输入、权重的初始化、训练集和测试集之间的样本划分等操作都具有一定的随机性。
而通过设置一个统一的随机数种子可以有效地帮助我们测试不同网络的表现与调试神经网络的结构。 -
ONNX文件存在的意义:
ONNX格式的文件的存在是为了方便不同深度学习框架之间交换模型,即pytorch可以导出模型给其他深度学习框架使用,或者让pytorch可以载入其他深度学习框架构建的深度学习模型。
2.5 Pytorch中张量的创建和维度的操作
2.5.1 张量的数据类型
- torch.Tensor类,根据张量数据的格式和需要使用张量的设备,为张量开辟不同的存储区域,对张量的元素进行存储。
- Pytorch中的张量一共支持九种数据类型,而每种数据类型都对应CPU和GPU的两种子类型。
- 通过直接访问张量的dtype属性可以获得一个张量具体的类型。
- 通过调用张量的type方法可以同时获取张量的数据类型和存储位置。
从上面的代码可以看出,定义张量时,使用的是pytorch类型;而一旦定义好数据类型和存储位置,通过dtype得到pytorch类型,但是通过tensor.type()得到CPU上的张量数据类型或者GPU上的张量数据类型。这也就是为什么说通过张量的type方法可以得到张量的存储位置。>>> t = torch.tensor([1,2,3,4,5,6,7,8,9,10,11,12],dtype=torch.float32) >>> t tensor([ 1., 2., 3., 4., 5., 6., 7., 8., 9., 10., 11., 12.]) >>> type(t) # python自带的type方法。 <class 'torch.Tensor'> >>> t.type() 'torch.FloatTensor' >>> t.dtype torch.float32 - Pytorch的不同类型之间,通过调用to方法实现。to方法的参数是pytorch的数据类型。
这里要注意区分pytorch的数据类型、CPU上张量的数据类型和GPU上张量的数据类型。
2.5.2 张量的创建方式(四种)
通过torch.tensor函数创建张量
- 预先有数据(列表和numpy数组或能够转化为python列表的对象);
- 可以通过传入的dtype参数来指定生成的张量的数据类型;
这里要注意,python中的float默认是双精度浮点数,不存在单精度,因而当其传入numpy的array方法中时,会保持原来的数据类型,即双精度;而pytorch中会默认转化为单精度数据类型。
通过pytorch内置的函数创建张量
- 指定张量的形状,数据由内置函数及相应参数生成。
通过已知张量创建形状相同的张量
- 复制给定张量的形状。数据由内置函数生成。
通过已知张量创建形状不同但数据类型相同的张量
- 通过张量自身的方法创建。
比较而言,前三者时通过torch的内置函数创建;后者通过张量的自身方法创建。
2.5.3 张量的存储设备
- 在未指定设备的时候,Pytorch会默认存储张量到CPU上。
- 指定设备时,时通过2.5.2中前三种张量创建函数中添加参数device,指定“cpu”或“cuda:0”等。
- cpu中的张量要转移到Gpu,使用cuda(0)方法或者to(“cuda:0”)方法;
- GPU中的张量要转移到CPU中,使用cpu()方法实现。
- 两个或者多个张量之间的运算只能在相同的设备中才能进行。
2.5.4 和张量维度相关的方法
- 获取张量的维度数目:调用张量的ndimension方法;
- 获取张量的元素数目:调用张量的nelement方法;
- 获取张量的形状:调用张量的size方法或者shape属性;
- 改变张量的形状:保证新张量和原张量的元素数目相同;
- 调用张量的view方法:
- 重新生成一个张量时,要使用contiguous;
- 如果信息兼容,则不会创建新的张量
- 如果信息不兼容,则如我们所愿,创造一个新的张量;
- 这里的能够创建新张量,表示新张量和原张量的指针指向不同;(通过调用张量的data_ptr方法得到)
- 调用张量的reshape方法:
- 等价于信息不兼容的时候,连续调用view方法和contiguous方法;
- 调用张量的view方法:
相关知识点
-
reshape和view的区别
除了两者在信息不兼容下重新生成张量的执行方式上不同以外;
view不能接受张量中元素的内存地址不连续的张量;而reshape不挑食。
每次在使用view()之前,该tensor只要使用了transpose()和permute()这两个函数一定要contiguous(). -
既然两者都可以达到相同的形状,那么什么时候使用view什么时候使用transpose?
其实从上面的例子可以看出,当一个张量为t.view(3,4)时,transpose()的形状转换更加具有语义性,即维持原张量各个维度的含义;
比如十张连续图片中N个人物的18个节点的坐标(分x,y)矩阵:(10,N,18,2)。而此时,如果使用permute(0,2,3,1)做转换,得到(10,18,2,N),此时的矩阵各个维度依旧保持着原有的维度意义,内部的语义结构仍有保持。而view相对来说,就是单纯的没有感情色彩的功能。 -
transpose和permute两者的区别
transpose:只能选择高维tensor中两个维度进行转置
permute:可以让高维tensor按照指定维度顺序(维度的个数就是该tensor的维度数)进行转置# 创造二维数据x,dim=0时候2,dim=1时候3 x = torch.randn(2,3) 'x.shape → [2,3]' # 创造三维数据y,dim=0时候2,dim=1时候3,dim=2时候4 y = torch.randn(2,3,4) 'y.shape → [2,3,4]' # 对于transpose x.transpose(0,1) 'shape→[3,2] ' x.transpose(1,0) 'shape→[3,2] ' y.transpose(0,1) 'shape→[3,2,4]' y.transpose(0,2,1) 'error,操作不了多维' # 这里尤其要注意的是:transpose和permute都是inplace操作。!!! # 对于permute() x.permute(0,1) 'shape→[2,3]' x.permute(1,0) 'shape→[3,2], 注意返回的shape不同于x.transpose(1,0) ' y.permute(0,1) "error 没有传入所有维度数" y.permute(1,0,2) 'shape→[3,2,4]' -
大多数情况下,Pytorch的张量在改变形状的时候不需要调用contiguous;
兼容是指:新张量的两个连续维度的乘积等于原来张量的某一维度。
具体的决策树图如下图所示:
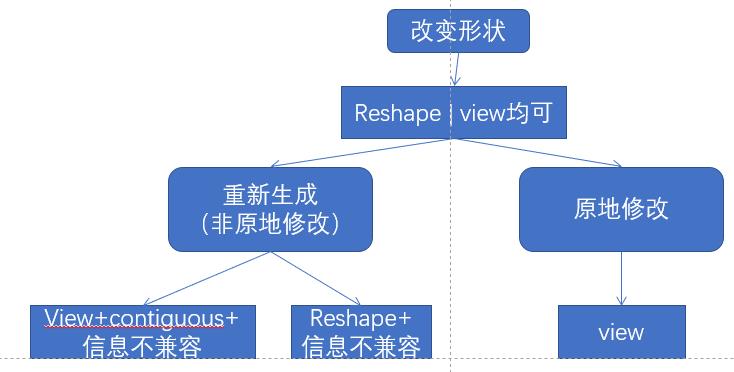
-
检查
t.view(3,4).view(4,3)和t.view(3,4).transpose(0,1)的输出是否有差别:>>> import torch >>> t = torch.tensor([1,2,3,4,5,6,7,8,9,10,11,12]) >>> t.view(3,4) tensor([[ 1, 2, 3, 4], [ 5, 6, 7, 8], [ 9, 10, 11, 12]]) >>> t.view(3,4).view(4,3) tensor([[ 1, 2, 3], [ 4, 5, 6], [ 7, 8, 9], [10, 11, 12]]) >>> t.view(3,4).transpose(0,1) tensor([[ 1, 5, 9], [ 2, 6, 10], [ 3, 7, 11], [ 4, 8, 12]]) >>> t.view(3,4).transpose(0,1).view(1,12) Traceback (most recent call last): File "<input>", line 1, in <module> RuntimeError: view size is not compatible with input tensor's size and stride (at least one dimension spans across two contiguous subspaces). Use .reshape(...) instead. >>> t.view(3,4).transpose(0,1).contiguous().view(1,12) tensor([[ 1, 5, 9, 2, 6, 10, 3, 7, 11, 4, 8, 12]]) >>> t.view(3,4).is_contiguous() True >>> t.view(3,4).view(4,3).is_contiguous() True >>> t.view(3,4).transpose(0,1).is_contiguous() False可以看出两种方式完全不同;
2.5.5 张量的索引和切片
- 索引和切片后的张量,以及初始的张量共享一个内存区域。
- 如果想在不改变原张量的条件下改变索引和切片后张量的值,可以调用张量的clone方法得到索引或者切片后张量的一份副本。然后进行赋值;
- 索引操作支持掩码选择,即传入一个和原来张量形状相同的布尔型张量。
以上是关于Pytorch的独特归纳的主要内容,如果未能解决你的问题,请参考以下文章