基础GCN图卷积层的pytorch的三种实现。
Posted MarToony|名角
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基础GCN图卷积层的pytorch的三种实现。相关的知识,希望对你有一定的参考价值。
主要内容:
1 实现基于Parameter的GCN层定义;
2 调整模型以实现Batch计算;
3 基于Linear全连接层的GCN层定义;
4 DGL和Pytorch_geometric对GCN的定义;
5 基于Conv2D的GCN图卷积的方式的定义(待补充);
一、基于Parameter的GCN层定义
import math
from torch import nn
import torch.nn.init as init
import torch
import torch.nn.functional as F
def import_class(name):
components = name.split('.')
mod = __import__(components[0])
for comp in components[1:]:
mod = getattr(mod, comp)
return mod
def bn_init(bn, scale):
nn.init.constant_(bn.weight, scale)
nn.init.constant_(bn.bias, 0)
class GraphConvolution(nn.Module):
def __init__(self, input_dim, output_dim, use_bias=True):
super(GraphConvolution, self).__init__()
self.input_dim = input_dim
self.output_dim = output_dim
self.use_bias = use_bias
self.weight = nn.Parameter(torch.Tensor(input_dim, output_dim))
if self.use_bias:
self.bias = nn.Parameter(torch.Tensor(output_dim))
else:
self.register_parameter('bias', None)
self.reset_parameters()
def reset_parameters(self):
init.kaiming_uniform_(self.weight)
if self.use_bias:
init.zeros_(self.bias)
def forward(self, adjacency, input_feature):
support = torch.mm(input_feature, self.weight).cuda()
output = torch.sparse.mm(adjacency, support)
if self.use_bias:
output += self.bias
return output
def __repr__(self):
return self.__class__.__name__ + ' (' \\
+ str(self.input_dim) + ' -> ' \\
+ str(self.output_dim) + ')'
class Model(nn.Module):
def __init__(self, input_dim=3, num_point=7, adjacency):
super(Model, self).__init__()
self.adjacency = torch.tensor(adjacency, dtype=torch.float32).cuda()
self.data_bn = nn.BatchNorm1d(input_dim * num_point)
self.gcn1 = GraphConvolution(input_dim, 16)
self.data_bn1 = nn.BatchNorm1d(16 * num_point)
self.gcn2 = GraphConvolution(16, 32)
self.data_bn2 = nn.BatchNorm1d(32 * num_point)
self.gcn3 = GraphConvolution(32, 16)
self.data_bn3 = nn.BatchNorm1d(16 * num_point)
self.gcn4 = GraphConvolution(16, 8)
self.data_bn4 = nn.BatchNorm1d(8 * num_point)
self.fc = nn.Linear(8, 2)
nn.init.normal_(self.fc.weight, 0, math.sqrt(2. / 2))
bn_init(self.data_bn, 1)
bn_init(self.data_bn1, 1)
bn_init(self.data_bn2, 1)
bn_init(self.data_bn3, 1)
bn_init(self.data_bn4, 1)
def forward(self, x):
N, V, C = x.size()
x = x.view(N, V * C)
x = self.data_bn(x)
x = x.view(N, V, C)
x = F.relu(self.gcn1(self.adjacency, x))
N, V, C = x.size()
x = x.contiguous().view(N, V * C)
# print("- x:{}".format(x.size()))
x = self.data_bn1(x)
x = x.resize(N, V, C)
x = F.relu(self.gcn2(self.adjacency, x))
N, V, C = x.size()
x = x.contiguous().view(N, V * C)
x = self.data_bn2(x)
x = x.view(N, V, C)
x = F.relu(self.gcn3(self.adjacency, x))
N, V, C = x.size()
x = x.contiguous().view(N, V * C)
x = self.data_bn3(x)
x = x.view(N, V, C)
x = F.relu(self.gcn4(self.adjacency, x))
N, V, C = x.size()
x = x.contiguous().view(N, V * C)
x = self.data_bn4(x)
x = x.view(N, V, C)
x = x.mean(1)
# print("out:{}".format(out.shape))
return self.fc(x)
- 以上的重点是,
GraphConvolution类,是GCN的基本计算单元, A∗X∗W。 - Model类只不过是像调用常见的pytorch的网络层的API一样定义和调用。其中,批归一化操作对提升模型捕捉区分性特征有很大帮助;而最终用于预测的特征是图卷积之后对所有节点取平均值。
- 这个图卷积层也是github中的pygcn项目所使用的。
二、GCN层走向实用的关键一步:Batch计算
需要更换的位置在:GraphConvolution类的forward函数。重点在于引入了爱因斯坦约定函数,以实现batch矩阵计算。
如果是使用原来的矩阵相乘的mm函数,且feedbatchsize量的数据,则会引起错误:
RuntimeError: tensors must be 2-D,指明此处的张量必须是二维的。
def forward(self, adjacency, input_feature):
support = torch.einsum('mik,kj->mij', input_feature, self.weight).cuda()
output = torch.einsum('ki,mij->mkj', adjacency, support)
if self.use_bias:
output += self.bias
return output
爱因斯坦求和约定sinsum函数,在numpy和torch中都有API。重点是学会如何使用,推荐阅读文章:
https://www.cnblogs.com/mengnan/p/10319701.html
文章中重点介绍了:爱因斯坦求和约定常用的几个场合。其中介绍了本节需要的“batch矩阵相乘”。除此之外,还提及,batch矩阵相乘是另一个场景“张量缩约”的一个特例,即不是一般性的规则如“张量缩约”,它描述了两个张量的相乘规则,只要看懂这个,就能够理解深度学习中的一些代码实现,主要公式和描述摘抄如下:

a=torch.randn(2,3,5,7)
b=torch.randn(11,13,3,17,5)
torch.einsum('pqrs,tuqvr->pstuv', [a, b]).shape
>>>torch.Size([2, 7, 11, 13, 17])
三、基于Linear全连接层的GCN层定义
class GCN(nn.Module):
'''
Z = AXW
'''
def __init__(self , A, dim_in , dim_out):
super(GCN,self).__init__()
self.A = A
self.fc1 = nn.Linear(dim_in ,dim_in,bias=False)
self.fc2 = nn.Linear(dim_in,dim_in//2,bias=False)
self.fc3 = nn.Linear(dim_in//2,dim_out,bias=False)
def forward(self,X):
'''
计算三层gcn
'''
X = F.relu(self.fc1(self.A.mm(X)))
X = F.relu(self.fc2(self.A.mm(X)))
return self.fc3(self.A.mm(X))
- 其实这一点与基于Parameter的GCN定义方式一致,只不过后者将Linear的定义拆开来。
- pytorch中linear的源码与上面定义的
GraphConvolution类基本一致,且基本相同。 - 该形式参考文章:https://zhuanlan.zhihu.com/p/54525205
四、DGL和Pytorch_geometric
- DGL:https://docs.dgl.ai/en/0.6.x/tutorials/models/1_gnn/1_gcn.html
- pytorch_geometric:https://pytorch-geometric.readthedocs.io/en/latest/_modules/torch_geometric/nn/conv/gcn_conv.html#GCNConv,代码如下,粗略观察可知,该网络层的定义方式与LInear的定义方式十分相似,由此,其他类别的网络层也大致为此。
class GCNConv(MessagePassing):
def __init__(self, in_channels: int, out_channels: int,
improved: bool = False, cached: bool = False,
add_self_loops: bool = True, normalize: bool = True,
bias: bool = True, **kwargs):
kwargs.setdefault('aggr', 'add')
super(GCNConv, self).__init__(**kwargs)
self.in_channels = in_channels
self.out_channels = out_channels
self.improved = improved
self.cached = cached
self.add_self_loops = add_self_loops
self.normalize = normalize
self._cached_edge_index = None
self._cached_adj_t = None
self.weight = Parameter(torch.Tensor(in_channels, out_channels))
if bias:
self.bias = Parameter(torch.Tensor(out_channels))
else:
self.register_parameter('bias', None)
self.reset_parameters()
def reset_parameters(self):
glorot(self.weight)
zeros(self.bias)
self._cached_edge_index = None
self._cached_adj_t = None
def forward(self, x: Tensor, edge_index: Adj,
edge_weight: OptTensor = None) -> Tensor:
""""""
if self.normalize:
if isinstance(edge_index, Tensor):
cache = self._cached_edge_index
if cache is None:
edge_index, edge_weight = gcn_norm( # yapf: disable
edge_index, edge_weight, x.size(self.node_dim),
self.improved, self.add_self_loops)
if self.cached:
self._cached_edge_index = (edge_index, edge_weight)
else:
edge_index, edge_weight = cache[0], cache[1]
elif isinstance(edge_index, SparseTensor):
cache = self._cached_adj_t
if cache is None:
edge_index = gcn_norm( # yapf: disable
edge_index, edge_weight, x.size(self.node_dim),
self.improved, self.add_self_loops)
if self.cached:
self._cached_adj_t = edge_index
else:
edge_index = cache
x = x @ self.weight
# propagate_type: (x: Tensor, edge_weight: OptTensor)
out = self.propagate(edge_index, x=x, edge_weight=edge_weight,
size=None)
if self.bias is not None:
out += self.bias
return out
def message(self, x_j: Tensor, edge_weight: OptTensor) -> Tensor:
return x_j if edge_weight is None else edge_weight.view(-1, 1) * x_j
def message_and_aggregate(self, adj_t: SparseTensor, x: Tensor) -> Tensor:
return matmul(adj_t, x, reduce=self.aggr)
def __repr__(self):
return '{}({}, {})'.format(self.__class__.__name__, self.in_channels,
self.out_channels)
五、基于Conv2D的图卷积方式的对比
Conv2D的卷积形式,基本上见于STGCN及其之后的一系列模型的延伸。
以ST-GCN中的空间卷积代码:
self.gcn = ConvTemporalGraphical(in_channels, out_channels,kernel_size[1])
class ConvTemporalGraphical(nn.Module):
def __init__(self,
in_channels,
out_channels,
kernel_size,
t_kernel_size=1,
t_stride=1,
t_padding=0,
t_dilation=1,
bias=True):
super().__init__()
self.kernel_size = kernel_size
self.conv = nn.Conv2d(
in_channels,
out_channels * kernel_size,
kernel_size=(t_kernel_size, 1),
padding=(t_padding, 0),
stride=(t_stride, 1),
dilation=(t_dilation, 1),
bias=bias)
def forward(self, x, A):
assert A.size(0) == self.kernel_size
x = self.conv(x)
n, kc, t, v = x.size()
x = x.view(n, self.kernel_size, kc//self.kernel_size, t, v)
x = torch.einsum('nkctv,kvw->nctw', (x, A))
return x.contiguous(), A
- 它是一种类似CNN卷积公式的表达:
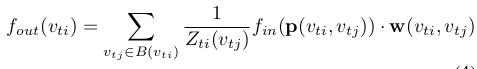
这一点目前不太理解,不能解释。详情见论文:《Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition》
以上是关于基础GCN图卷积层的pytorch的三种实现。的主要内容,如果未能解决你的问题,请参考以下文章