DataBase-数据库基础函数(更新中~~)
Posted Leida_wanglin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DataBase-数据库基础函数(更新中~~)相关的知识,希望对你有一定的参考价值。
DataBase-数据库基础函数
部门表
CREATE TABLE dept( #部门表
deptno int primary key auto_increment NOT NULL, #部门编号
dname VARCHAR(20), #部门名称
location VARCHAR(13) #部门地点
);
INSERT INTO dept VALUES(1, 'accounting', '一区');
INSERT INTO dept VALUES(2, 'research', '二区');
INSERT INTO dept VALUES(3, 'operations', '二区');
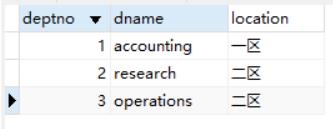
员工表
CREATE TABLE emp( #员工表
empno int primary key auto_increment NOT NULL, #员工编号
ename VARCHAR(10), #员工名称
job VARCHAR(10), #职位
mgr int, #上级编号
moneydate DATE, #月工资
price double, #奖金
comm NUMERIC(7,2), #奖金
deptno int #所属部门,外键
);
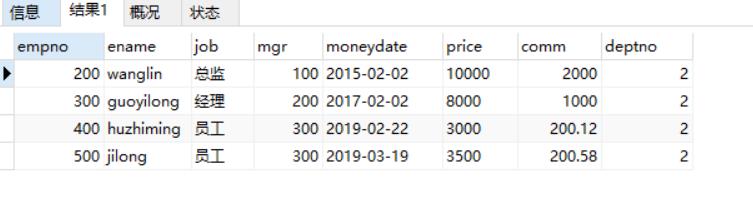
INSERT INTO emp VALUES(100,'tedu','副总',NULL,'2002-05-03',90000,NULL,1);
INSERT INTO emp VALUES(200,'wanglin','总监',100,'2015-02-02',10000,2000,2);
INSERT INTO emp VALUES(300,'guoyilong','经理',200,'2017-02-02',8000,1000,2);
INSERT INTO emp VALUES(400,'huzhiming','员工',300,'2019-02-22',3000,200.12,2);
INSERT INTO emp VALUES(500,'jilong','员工',300,'2019-03-19',3500,200.58,2);
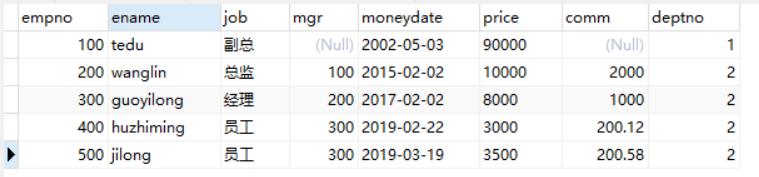
lower:数据转小写
select 'ABC', lower('ABC') from dept;
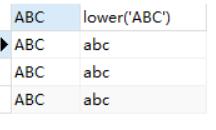
upper:数据转大写
select upper(dname) from dept;
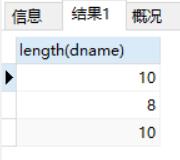
length:数据的长度
select length(dname) from dept;
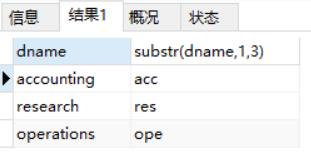
substr:截取[1,3]
select dname, substr(dname,1,3) from dept;
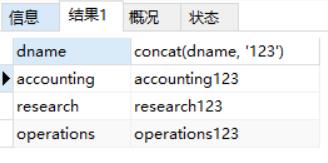
concat:拼接数据
select dname, concat(dname, '123') from dept;
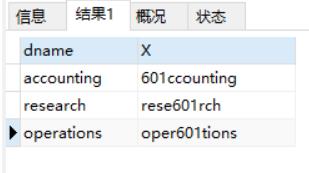
replace:把a字符替换成601
select dname, replace(dname, 'a', '601') X from dept;
ifnull:判断,如果comm是null,用10替换
select ifnull(comm, 10) comm from emp;
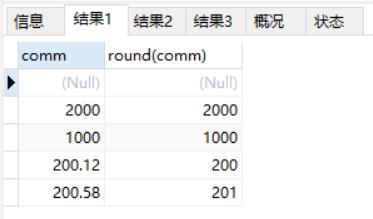
round:四舍五入
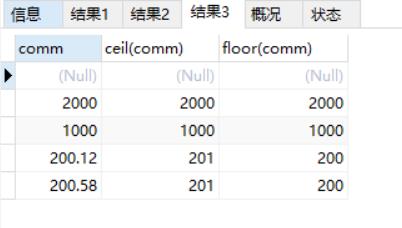
ceil:向上取整
floor:向下取整
select comm, round(comm) from emp;
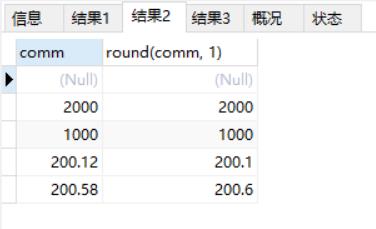
select comm, round(comm, 1) from emp; #四舍五入并保留一位小数
select comm, ceil(comm), floor(comm) from emp;
时间:
select now(); #年,日,时,分,秒 2021-06-01 20:12:49
select curdate(); #年,日 2021-06-01
select curtime(); #时,分,秒 20:12:49
select now(), year(now()), month(now()),day(now()), hour(now()), minute(now()), second(now());from emp;

转义字符:\\
select 'ab\\'cd';
条件查询
distinct:去除重复记录行
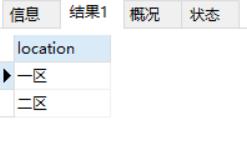
select distinct location from dept;
where:注意where不能使用列别名!!!
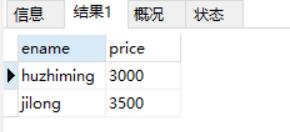
select ename, price p from emp where p = 3500 or p = 3000; #使用列别名
select ename, price from emp where price = 3500 or price = 3000; #不使用列别名
使用列别名: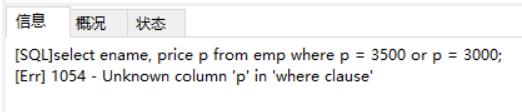
不使用列别名:
like:%代表0~n个字符,_代表1个字符
select * from emp where ename like 'w%'; --以w开头的
select * from emp where ename like '%g'; --以g结束的
select * from emp where ename like '%l%'; --中间包含l的
select * from emp where ename like 'h__'; --h后面有两个字符的 _代表一个字符位置
null:
select * from emp where mgr is null; --过滤字段值为空的
select * from emp where mgr is not null; --过滤字段值不为空的
between and:[1,2]闭区间
select * from emp where price between 3000 and 10000; #[3000,10000]
limit:
select * from emp limit 2; --列出前两条
select * from emp limit 1,2; --从第二条开始,展示2条记录
select * from emp limit 0,3; --从第一条开始,展示3条记录--前三条
order by:默认升序,desc降序
select * from emp order by price;
select * from emp order by price desc;
聚合:根据一列统计结果
count:
select count(*) from emp; --底层优化了
select count(1) from emp; --效果和*一样
select count(comm) from emp; --慢,只统计非NULL的
max/min:获取一列的最大最小值
select max(price), min(price) from emp;
sum:求和
avg:求平均
select sum(sal) from emp; --求和
select avg(sal) from emp; --平均数
分组:用于对查询的结果进行分组统计
group by:按照某一列分组
select deptno, job from emp group by deptno;#按照deptno分组
select deptno, job from emp group by job; #按照job分组
select deptno, job from emp group by deptno, job; #按照deptno,job分组
having:使用于group by,作用过滤条件
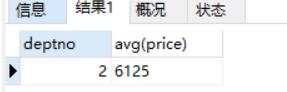
select deptno, avg(price) from emp group by deptno having avg(price) < 8000; #求平均price小于8000的部门
以上是关于DataBase-数据库基础函数(更新中~~)的主要内容,如果未能解决你的问题,请参考以下文章