阿里云 RDS MySQL 数据库 性能优化与诊断
Posted 不畏过往不惧将来
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阿里云 RDS MySQL 数据库 性能优化与诊断相关的知识,希望对你有一定的参考价值。
阿里云 RDS mysql 数据库 性能优化与诊断
原文链接:
https://help.aliyun.com/document_detail/202152.html?spm=a2c4g.11186623.6.766.697e7cefJSbVVm
RDS MySQL慢SQL问题
本页目录
SQL异常
实例瓶颈
版本升级
参数设置不当
缓存失效
批量操作
未关闭事务
定时任务
总结
在相同业务场景下,架构设计和库表索引设计会影响查询性能,良好的设计可以提高查询性能,反之会出现很多慢SQL(执行时间很长的SQL语句)。本文介绍导致慢SQL的原因和解决方案。
SQL异常
原因及现象
SQL异常的原因很多,例如库表结构设计不合理、索引缺失、扫描行数太多等。
您可以在控制台的SQL洞察页面,查看慢SQL的执行耗时、执行次数等信息。
解决方案
根据实际业务情况优化SQL。具体操作,请参见SQL优化。
实例瓶颈
原因及现象
实例到达瓶颈的原因一般有如下几种:
您可以在控制台的监控与报警页面,单击标准监控页签,在资源监控内可以查看实例的资源使用情况。如果资源使用率各项指标都接近100%,可能是实例到达了瓶颈。
业务量持续增长而没有扩容。
硬件老化,性能有损耗。
数据量一直增加,数据结构也有变化,导致原来不慢的SQL变成慢SQL。
解决方案
判断实例是否到达瓶颈,较好的方法是先测试出实例的性能基准值,例如用SysBench进行基准测试,复杂场景下的QPS和TPS很少会超过基准值。
确认实例到达瓶颈后,建议升级实例规格。具体操作,请参见变更配置。
版本升级
原因及现象
实例升级版本可能会导致SQL执行计划发生改变,执行计划中连接类型从好到坏的顺序是system>const>eq_ref>ref>fulltext>ref_or_null>index_merge>unique_subquery>index_subquery>range>index>all。更多信息,请参见MySQL官方文档。
range和index连接类型时,如果SQL请求变慢,业务又不断重发请求,导致并行SQL查询比较多,会导致应用线程释放变慢,最终连接池耗尽,影响整个业务。
您可以在控制台的监控与报警页面,单击标准监控页签,在资源监控内可以查看实例的连接数情况。
解决方案
根据执行计划分析索引使用情况、扫描的行数等,预估查询效率,重构SQL语句、调整索引,提升查询效率。具体操作,请参见SQL优化。
参数设置不当
原因及现象
参数innodb_buffer_pool_instances、join_buffer_size等设置不当会导致性能变慢。
您可以在控制台的参数设置页面,单击修改历史页签,查看实例的参数修改情况。

解决方案
调整相关参数,使其适合业务场景。
缓存失效
原因及现象
缓存可以很好地承担大量查询,但是并不能保证缓存命中率100%,如果缓存失效,也会有大量的查询路由到数据库端,导致性能下降。
您可以在控制台的监控与报警页面,单击标准监控页签,在引擎监控内可以查看实例的缓存命中率、QPS、TPS等。
解决方案
可以使用Thread Pool、Fast Query Cache、自动SQL限流等功能提高性能。
批量操作
原因及现象
如果有大批量的数据导入、删除、查询操作,会导致SQL执行变慢。
可以从磁盘空间、SQL洞察或者慢查询里找到对应语句。例如查看Binlog大小,正常情况单个Binlog大小是500 MB,如果有超过500 MB的,可以查看是否有异常。
您也可以在控制台的监控与报警页面,单击标准监控页签,在资源监控和引擎监控内可以查看实例的磁盘空间、IOPS、事务等情况。
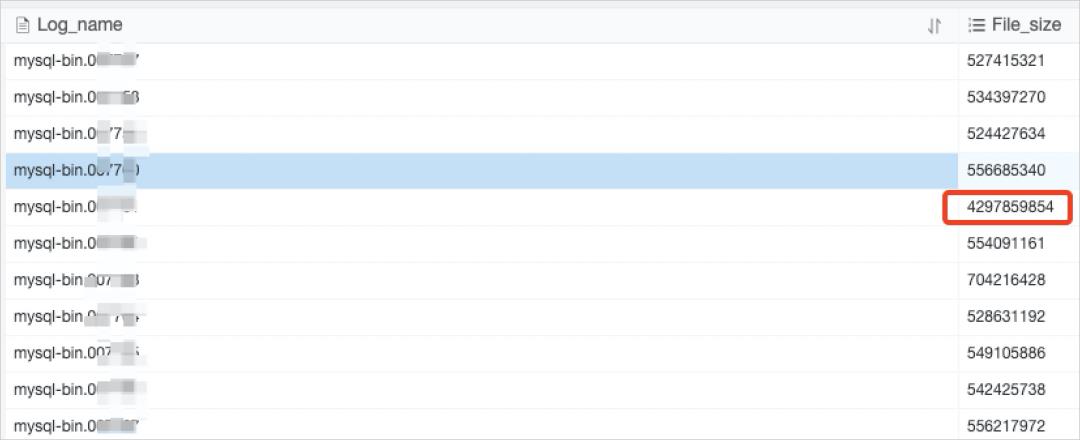
解决方案
在业务低峰期执行大批量操作,或将大批量操作拆分后分批执行。
未关闭事务
原因及现象
如果某个任务突然变慢,查看CPU和IOPS的使用率并不高,而且活跃会话持续增多,通常是因为存在未关闭的事务。
解决方案
检查导致事务冲突的锁并中止对应的SQL语句。
定时任务
原因及现象
如果实例负载随时间有规律性变化,可能是存在定时任务。
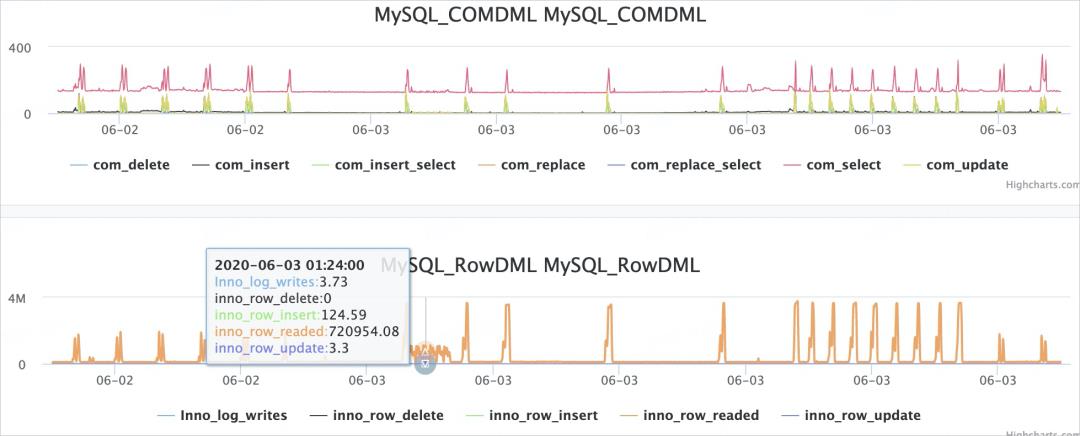
解决方案
调整定时任务的执行时间,建议在业务低峰期执行。
总结
RDS上定位慢SQL的主要方法如下:
检查监控指标
查看慢日志明细
使用SQL洞察
使用自治服务
结合RDS提供的这些功能,可以有效帮助您快速定位甚至自动解决慢SQL问题。
RDS MySQL内存使用问题
本页目录
背景信息
查看内存使用情况
RDS MySQL内存高常见原因
多语句(multiple statements)
缓冲池(Buffer Pool)问题
临时表
其他原因
本文介绍查看内存使用情况的方式,以及各种内存问题的原因和解决方案。
背景信息
查看内存使用情况
RDS管理控制台提供多种查看活跃线程的方法:
监控与报警
在控制台的监控与报警页面,单击标准监控页签,在资源监控和引擎监控内,可以查看实例的内存使用率和缓冲池的读命中率。
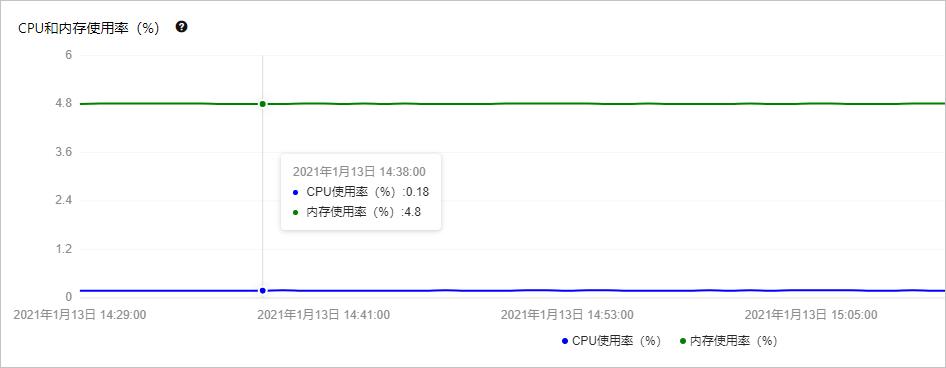
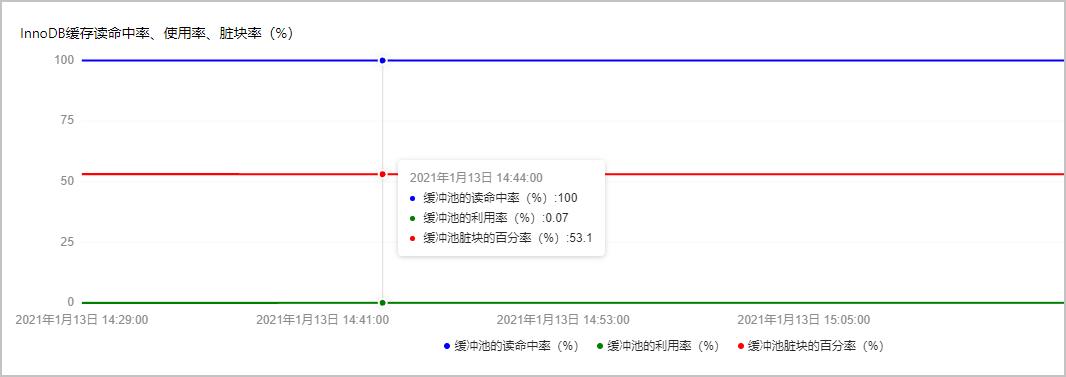
数据库自治服务DAS
在控制台的自治服务 > 性能趋势页面,单击性能趋势页签,查看MySQL CPU/内存 利用率和InnoDB Buffer Pool 命中率情况。
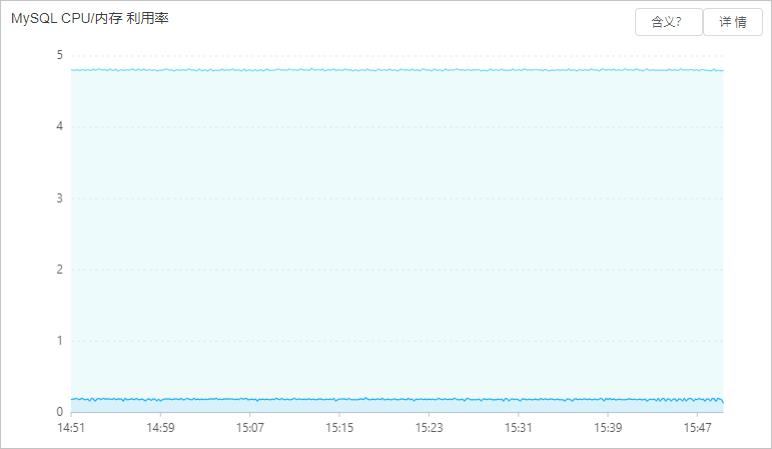
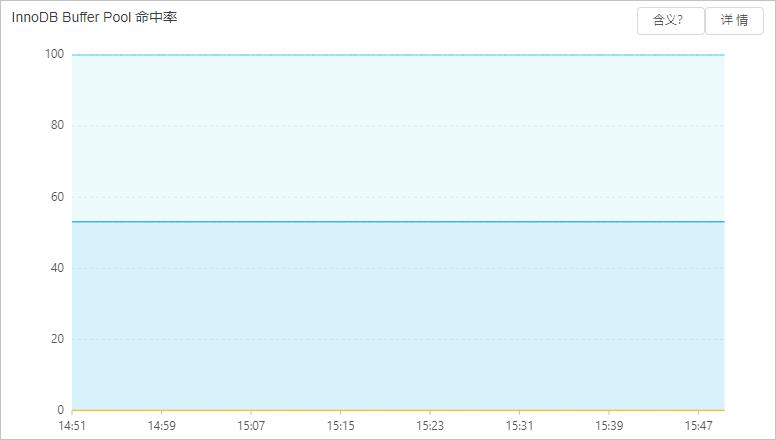
您还可以使用performance_schema,设置相关的内存仪表(instrumentation),通过内存占用统计表查看内存占用。详情请参见MySQL官方文档。
要在实例启动时开启内存检测,请修改my.cnf文件,添加
performance_schema = on,然后重启实例即生效。要在实例运行中开启内存检测,请执行如下命令:
update performance_schema.setup_instruments set enabled = 'yes' where name like 'memory%';
从各个维度统计内存消耗的相关表如下:
memory_summary_by_account_by_event_name:统计指定帐户(用户和主机组合)的事件和事件名称。
memory_summary_by_host_by_event_name:统计指定主机的事件和事件名称。
memory_summary_by_thread_by_event_name:统计指定线程的事件和事件名称。
memory_summary_by_user_by_event_name:统计指定用户的事件和事件名称。
memory_summary_global_by_event_name:统计指定事件名称的事件。
RDS MySQL内存高常见原因
通常InnoDB Buffer Pool的内存占用是最大的,Buffer Pool的内存占用上限受到Buffer Pool配置参数的限制,但是还有很多内存是在请求执行中动态分配和调整的,例如内存临时表消耗的内存、prefetch cache、table cache、哈希索引、行锁对象等,详细的内存占用和相关参数限制,请参见MySQL官方文档。
多语句(multiple statements)
MySQL支持将多个SQL语句用英文分号(;)分隔,然后一起发给MySQL,MySQL会逐条处理SQL,但是某些内存需要等到所有的SQL执行结束才释放。
这种multiple statements的发送方式,如果一次性发送的SQL非常多,例如达到数百兆,SQL实际执行过程中各种对象分配累积消耗的内存非常大,很有可能导致MySQL进程内存耗尽。
一般场景下,如果存在大批量的multiple statements,网络流量会有突增,可以从网络流量监控和SQL洞察,判断是否有这种现象。建议业务实现中尽量避免multiple statements的SQL发送方式。
缓冲池(Buffer Pool)问题
所有表的数据页都存放在缓冲池中,查询执行的时候如果需要的数据页直接命中缓冲池,就不会发生物理I/O,SQL执行的效率较高,缓冲池采用LRU算法管理数据页,所有的脏页放到Flush List链表中。
RDS MySQL的InnoDB Buffer Pool大小默认设置为内存的75%,这部分内存通常是实例内存中占比最大的。
Buffer Pool相关的常见问题:
数据页预热不足导致查询的延迟较高。通常发生在实例重启、冷数据读取或缓冲池命中率较低的场景,建议升级实例规格或大促前预热数据。
脏页累积太多。当未刷新脏页的最旧LSN和当前LSN的距离超过76%时,会触发用户线程同步刷新脏页,导致实例性能严重下降。优化方式是均衡写入负载、避免写入吞吐过高、调整刷新脏页参数或升级实例规格等。
高内存实例的参数innodb_buffer_pool_instances设置较小。高QPS负载情况下,缓冲池的锁竞争会比较激烈。建议高内存的实例将参数innodb_buffer_pool_instances设置为8或16,甚至更高。
临时表
内存临时表大小受到参数tmp_table_size和max_heap_table_size限制,超过限制后将转化为磁盘临时表,如果瞬间有大量的连接创建大量的临时表,可能会造成内存突增。MySQL 8.0实现了新的temptable engine,所有线程分配的内存临时表大小之和必须小于参数temptable_max_ram,temptable_max_ram默认为1 GB,超出后转换为磁盘临时表。
其他原因
如果实例内表特别多或QPS很高,Table Cache可能也会消耗内存,建议实例避免创建太多表或设置参数table_open_cache过大。
自适应哈希索引占用的内存默认是Bufffer Pool的1/64。如果查询或写入长度非常大的Blob大字段,会对大字段动态分配内存,也会造成内存增加。
还有非常多的原因会造成内存上涨,如果碰见内存使用率异常增加或实例内存耗尽,您可以参考官方文档排查上涨原因,或者提交工单联系售后服务。
RDS MySQL空间不足问题
本页目录
查看空间使用情况
索引太多导致空间不足
大字段导致空间不足
空闲表空间太多导致空间不足
临时表空间过大导致空间不足
空间优化方案
RDS MySQL实例的空间使用率是日常需要重点关注的监控项之一,如果实例的存储空间不足,会导致严重后果,例如数据库无法写入、数据库无法备份、存储空间扩容任务耗时过长等。本文介绍查看空间使用情况的方式,以及各种空间问题的原因和解决方案。
查看空间使用情况
您可以在实例的基本信息页面查看存储空间使用情况,但是这里只展示当前的空间使用总量,没有展示各类数据分别占用的磁盘空间信息,也没有空间使用的历史信息。

您可以在控制台的监控与报警页面,单击标准监控页签内的资源监控,查看实例各类数据占用的磁盘空间信息,并且会显示历史变化曲线。
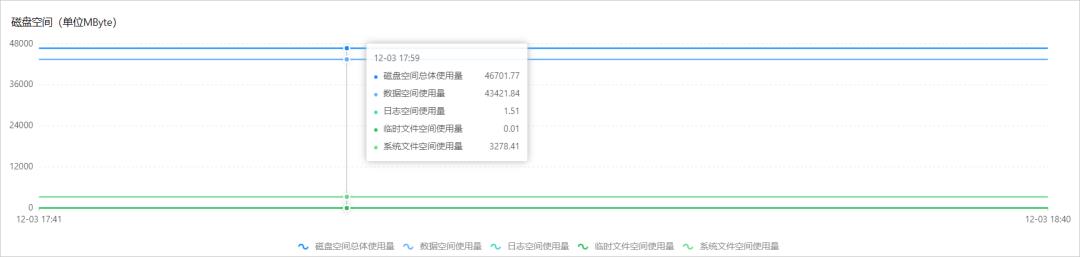
您可以在控制台的自治服务 > 一键诊断页面,单击空间分析页签,查看实例更详细的空间使用情况,包括数据与日志的空间使用对比、空间使用的历史变化趋势、Top数据库空间明细、Top表空间明细等。
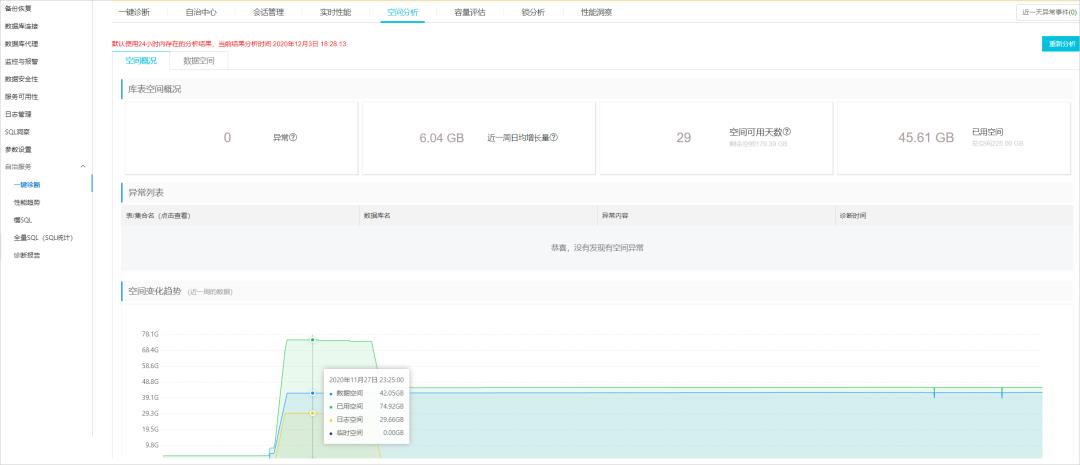

说明
表空间包含数据空间、索引空间和未使用空间(已保留给该表但还未分配使用的空间)。
空间大小是从统计信息中采集的,和真实的空间大小可能会存在误差。
登录数据库后执行命令
show table status like '<表名>';查看表空间。
索引太多导致空间不足
现象
通常表上除了主键索引,还存在二级索引,二级索引越多,整个表空间越大。
解决方案
优化数据结构,减少二级索引数量。
大字段导致空间不足
现象
如果表结构定义中有blob、text等大字段或很长的varchar字段,也会占用更大的表空间。
解决方案
将数据压缩以后再插入。
空闲表空间太多导致空间不足
现象
空闲表空间太多是指InnoDB表的碎片率高。InnoDB是按页(Page)管理表空间的,如果Page写满记录,然后部分记录又被删除,后续这些删除的记录位置又没有新的记录插入,就会产生很多空闲空间。
解决方案
可以通过命令
show table status like '<表名>';查看表上空闲的空间,如果空闲空间过大,可以执行命令optimize table <表名>;整理表空间。
临时表空间过大导致空间不足
现象
半连接(Semi-join)、去重(distinct)、不走索引的排序等操作,会创建临时表,如果涉及的数据量过多,可能导致临时表空间特别大。
DDL操作重建表空间时,如果表特别大,创建索引排序时产生的临时文件也会特别大。RDS MySQL 5.6和5.7不支持即时增加字段,很多DDL是通过创建新表实现的,DDL执行结束再删除旧表,DDL过程中会同时存在两份表。
解决方案
可以查看执行计划,确认是否包含Using Temporary。
大表DDL需要注意实例的空间是否足够,不足的话需要提前升级存储空间。
空间优化方案
使用空间碎片自动回收。开启该功能后,主实例会自动执行Optimize Table命令来回收表空间碎片,帮助您整理物理空间碎片。
使用云盘存储。云盘支持的存储空间比本地盘更大。
使用X-Engine引擎。X-Engine是支持高压缩比的存储引擎。
使用PolarDB。PolarDB采用分布式存储,支持超大存储空间,且支持自动扩容,结合PolarDB历史库(采用X-Engine引擎),可以大大降低数据占用的磁盘空间。
采用分析型数据库。
RDS MySQL I/O高问题
本页目录
存储类型
高吞吐导致实例I/O高
临时表导致实例I/O高
读取冷数据导致实例I/O高
DDL语句导致实例I/O高
大事务写Binlog导致实例I/O高
附:InnoDB I/O系统介绍
RDS MySQL的I/O性能受硬件层存储介质、软件层数据库内核架构和具体SQL语句(扫描或修改数据量)的影响。本文介绍实例I/O高的原因和解决方案。
存储类型
RDS MySQL的存储类型有2种:
本地SSD盘
本地SSD盘拥有最低的I/O延迟,但是本地SSD盘的存储大小有限,如果数据增多,本地空间不够时,需要迁移数据到其他的主机,时间较长且切换时会有闪断。
云盘(分布式存储)
云盘包括SSD云盘和ESSD云盘,云盘拥有更高的性价比,支持更大的存储空间,扩容速度快且不需要迁移数据。
存储类型的更多信息,请参见存储类型。
高吞吐导致实例I/O高
现象
如果表上有很多索引或大字段,频繁地更新、删除、插入,读取数据和刷新脏页时会有大量的I/O。
您可以在控制台的自治服务 > 性能趋势页面,单击性能趋势页签,查看读写负载情况。
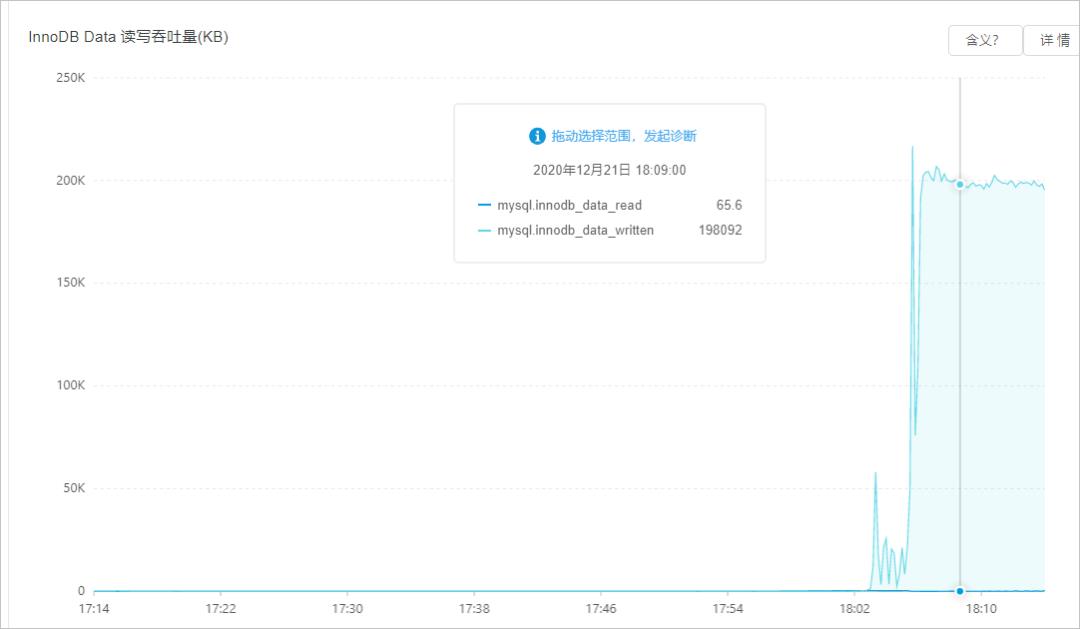
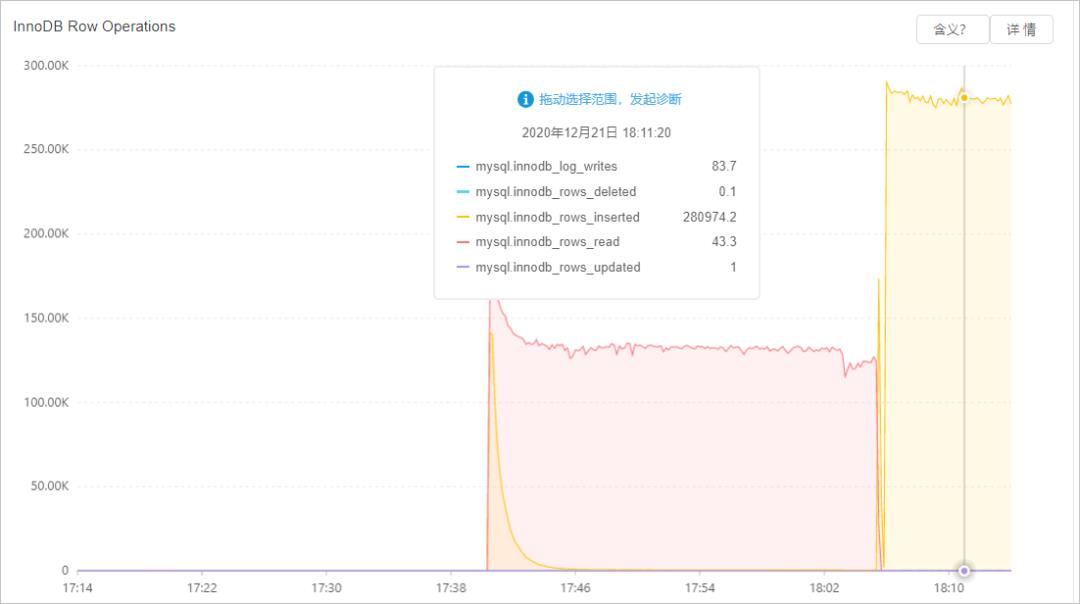
解决方案
建议降低读写频率或升级实例规格、优化刷新脏页相关的参数来解决高吞吐问题。和刷新脏页相关的参数如下:
innodb_max_dirty_pages_pct:缓冲池中允许的脏页百分比,默认值为75。
innodb_max_dirty_pages_pct_lwm:脏页比例的低水位线。当缓冲池里的脏页比例超过这个低水位线时,能够触发脏页预刷功能,逐步控制脏页比例。默认值为0,表示禁用该功能。
说明 innodb_max_dirty_pages_pct_lwm的值不能大于innodb_max_dirty_pages_pct的值,否则会强制修改为与innodb_max_dirty_pages_pct相同。
innodb_io_capacity:设置InnoDB后台任务每秒执行的I/O操作数的上限,影响刷新脏页和写入缓冲池的速率。默认值为20000。
innodb_io_capacity_max:如果刷新操作过于落后,InnoDB可以超过innodb_io_capacity的限制进行刷新,但是不能超过本参数的值。默认值为40000。
临时表导致实例I/O高
现象
如果临时目录很大,可能存在慢SQL排序、去重等操作导致创建很大的临时表。临时表写入也会造成I/O增加。
您可以在控制台的自治服务 > 性能趋势页面,单击性能趋势页签,查看tmp或other目录大小。
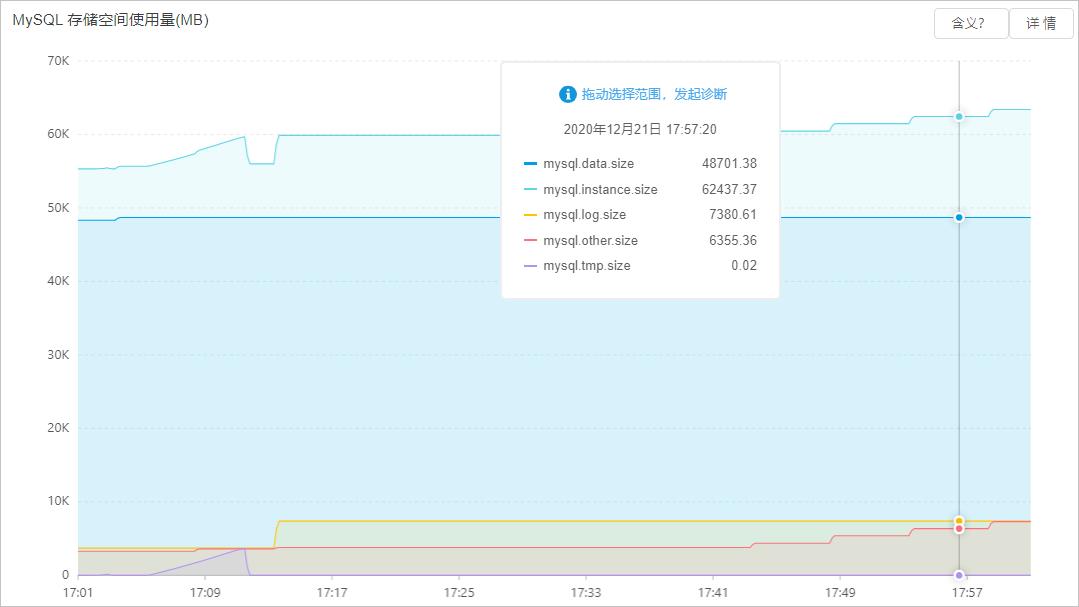
解决方案
建议进行SQL优化,避免慢SQL。数据库自治服务DAS提供自助SQL优化功能,具体操作,请参见SQL优化。
读取冷数据导致实例I/O高
现象
如果SQL查询或修改的数据不在缓冲池(Buffer Pool),则需要从存储中读取,可能会产生大量的I/O吞吐。
您可以在控制台的自治服务 > 性能趋势页面,单击性能趋势页签,查看Buffer Pool命中率。
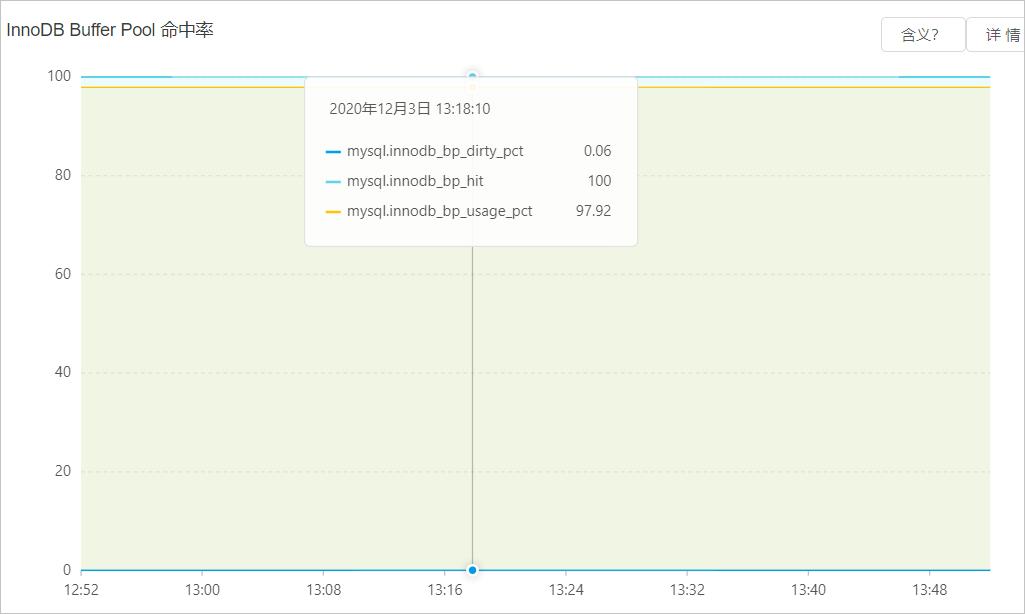
解决方案
根据业务场景重新设计缓存策略,或者升级实例规格。
DDL语句导致实例I/O高
现象
DDL语句可能会重建表空间,期间会扫描全表数据、创建索引排序、刷新新表产生的脏页,这些都会导致大量的I/O吞吐。另外一种场景是删除大表造成的I/O抖动。
您可以在控制台的监控与报警页面,单击标准监控页签内的资源监控,可以查看实例的磁盘空间和IOPS信息。
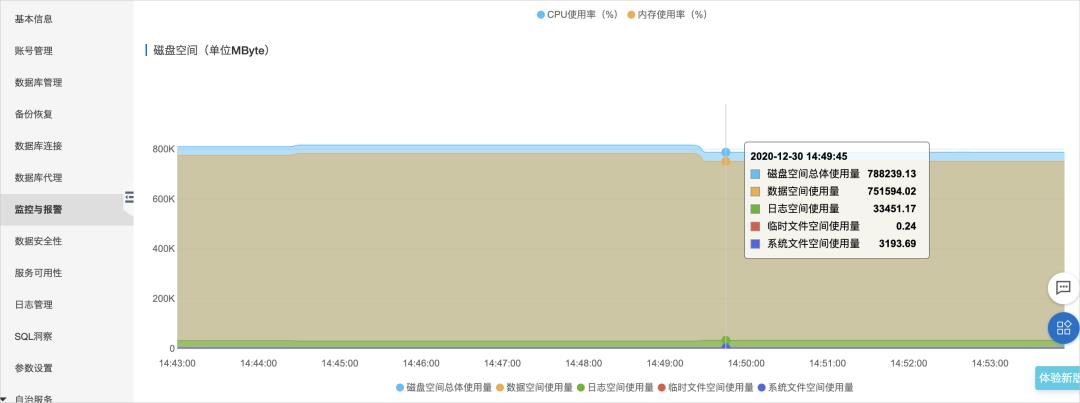
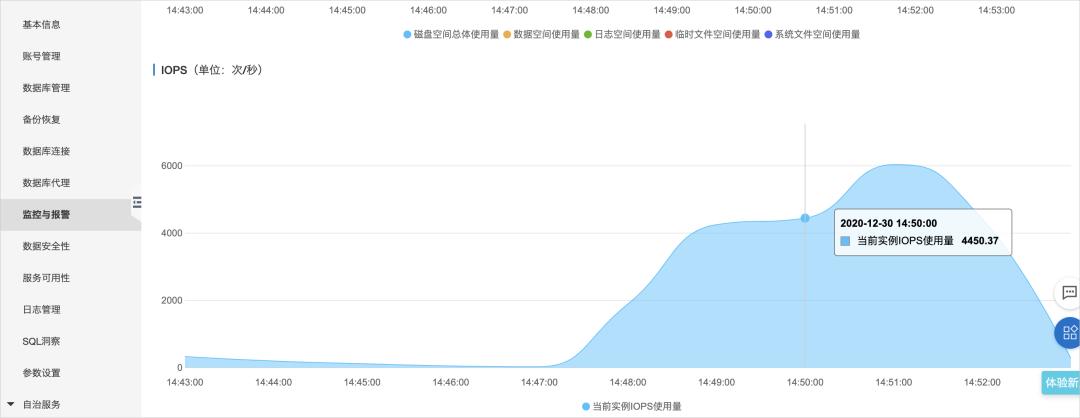
解决方案
可以使用阿里云自研内核AliSQL提供的异步删除大文件功能解决问题,更多信息,请参见Purge Large File Asynchronously。
大事务写Binlog导致实例I/O高
现象
事务只有在提交时才会写Binlog文件,如果存在大事务,例如一条Delete语句删除大量的行,可能会产生几十GB的Binlog文件,Binlog文件刷新到磁盘时,会造成很高的I/O吞吐。
解决方案
建议尽量将事务拆分,避免大事务和降低刷新磁盘频率。
附:InnoDB I/O系统介绍
InnoDB通过一套独立的I/O系统来处理数据页的读取和写入,如果SQL请求的数据页不在Buffer Pool中,会产生物理I/O,需要读写底层存储的数据:
读数据页操作
通过同步I/O实现,同步I/O调用底层的读接口。
写数据页操作
通过异步I/O实现,例如后台线程刷新脏页,后台I/O线程会异步的将脏页刷到磁盘。
除了对普通数据文件的读写I/O操作,写Redo日志、写Undo日志、写Binlog日志、排序临时表、重建DDL表空间等也会造成大量I/O。
RDS MySQL活跃线程数高问题
本页目录
背景信息
查看活跃线程数
排查慢SQL堆积问题
排查表缓存(Table Cache)问题
排查元数据锁(MDL)问题
排查行锁冲突问题
本文介绍RDS MySQL活跃线程数高的原因及解决方案。
背景信息
活跃线程数或活跃连接数是衡量MySQL负载状态的关键指标,通常来说一个比较健康的实例活跃连接数应该低于10,高规格和高QPS的实例活跃连接数可能20、30,如果出现几百、上千的活跃连接数,说明出现了SQL堆积和响应变慢,严重时会导致实例停止响应,无法继续处理SQL请求。
查看活跃线程数
RDS管理控制台提供多种查看活跃线程数的方法:
监控与报警
在控制台的监控与报警页面,单击标准监控页签内的引擎监控,可以查看实例的活跃线程数监控信息。
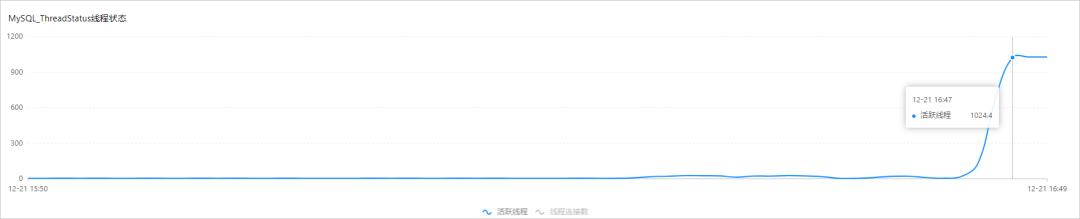
数据库自治服务DAS
在控制台的自治服务 > 性能趋势页面,单击性能趋势页签,查看会话连接情况,如果线程数过高,说明实例会话有阻塞。
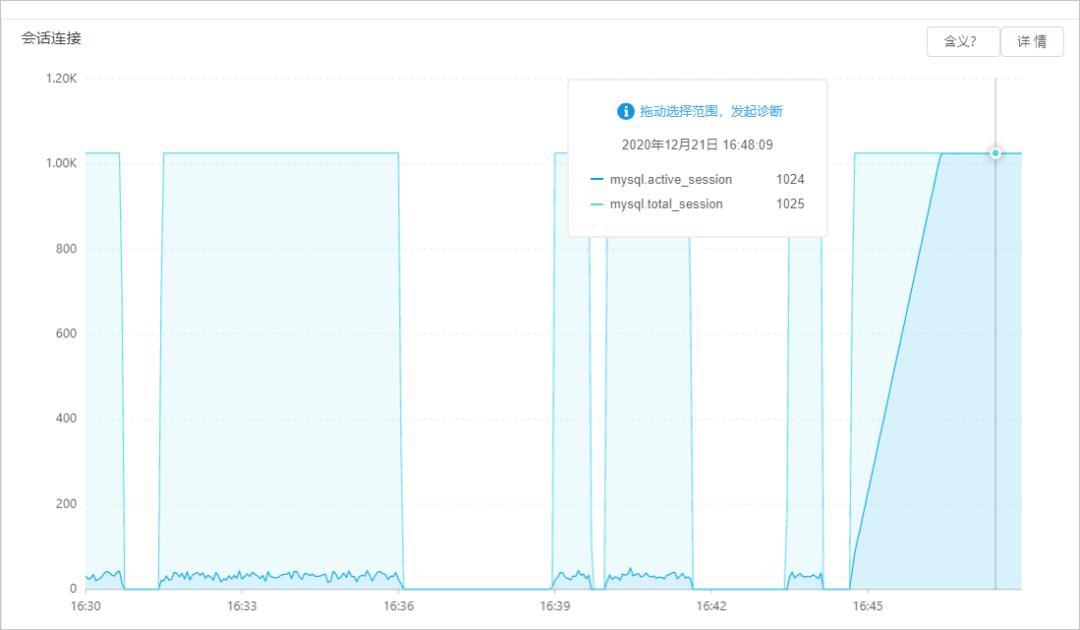
排查慢SQL堆积问题
现象
如果通过监控发现活跃线程数升高,首先通过
show processlist;命令查看是否有慢SQL。如果有很多扫描行数太多的SQL,容易导致活跃连接数升高。您可以在控制台的自治服务 > 一键诊断页面,单击会话管理页签,查看当前正在执行的SQL。
解决方案
使用SQL限流功能或结束会话,降低慢SQL的影响。
排查表缓存(Table Cache)问题
现象
Table Cache不足时,会导致大量SQL处于
Opening table状态,在QPS过高或者表很多的场景容易出现。解决方案
将参数table_open_cache(不需要重启实例)和table_open_cache_instances(需要重启实例)调大。
排查元数据锁(MDL)问题
现象
出现MDL锁时,会导致大量SQL处于
Waiting for table metadata lock的状态,在DDL prepare和commit阶段,DDL语句需要获取MDL锁,如果表上有未提交事务或慢SQL,会阻塞DDL操作,DDL操作又会阻塞其他的SQL,最终导致活跃线程数升高。解决方案
中止未提交事务、慢SQL或正在执行的DDL都可以解决问题。
排查行锁冲突问题
现象
行锁冲突表现为Innodb_row_lock_waits和Innodb_row_lock_time监控项的指标升高。
您可以在控制台的自治服务 > 性能趋势页面,单击性能趋势页签,查看行锁内的监控项,
解决方案
您可以通过
show engine innodb status;命令查看是否有大量会话处于Lock wait状态,如果有,说明行锁冲突比较严重,需要通过优化热点更新、降低事务大小、及时提交事务等方法避免行锁冲突。
以上是关于阿里云 RDS MySQL 数据库 性能优化与诊断的主要内容,如果未能解决你的问题,请参考以下文章