如何使用pg_chameleon迁移MySQL数据库至openGauss
Posted openGauss
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何使用pg_chameleon迁移MySQL数据库至openGauss相关的知识,希望对你有一定的参考价值。
pg_chameleon介绍
通过读取MySQL的binlog,提供实时在线复制的功能。
支持从多个MySQL schema读取数据,并将其恢复到目标openGauss数据库中。源schema和目标schema可以使用不同的名称。
通过守护进程实现实时复制,包含两个子进程,一个负责读取MySQL侧的日志,一个负责在openGauss侧重演变更。
pg_chameleon在openGauss上的使用注意事项
pg_chameleon依赖psycopg2,psycopg2内部通过pg_config检查PostgreSQL版本号,限制低版本PostgreSQL使用该驱动。而openGauss的pg_config返回的是openGauss的版本号(当前是 openGauss 2.0.0),会导致该驱动报版本错误,“Psycopg requires PostgreSQL client library (libpq) >= 9.1”。解决方案为通过源码编译使用psycopg2,并去掉源码头文件 psycopg/psycopg.h 中的相关限制。
pg_chameleon通过设置LOCK_TIMEOUT GUC参数限制在PostgreSQL中的等锁的超时时间。openGauss不支持该参数(openGauss支持类似的GUC参数lockwait_timeout,但是需要管理员权限设置)。需要将pg_chameleon源码中的相关设置去掉。
pg_chameleon用到了upsert语法,用来指定发生违反约束时的替换动作。openGauss支持的upsert功能语法与PostgreSQL的语法不同。openGauss的语法是 ON DUPLICATE KEY UPDATE { column_name = { expression | DEFAULT } } [, ...]。PostgreSQL的语法是 ON CONFLICT [ conflict_target ] DO UPDATE SET { column_name = { expression | DEFAULT } }。两者在功能和语法上略有差异。需要修改pg_chameleon源码中相关的upsert语句。
pg_chameleon用到了CREATE SCHEMA IF NOT EXISTS、CREATE INDEX IF NOT EXISTS语法。openGauss不支持SCHEMA和INDEX的IF NOT EXISTS选项。需要修改成先判断SCHEMA和INDEX是否存在,然后再创建的逻辑。
openGauss对于数组的范围选择,使用的是 column_name[start, end] 的方式。而PostgreSQL使用的是 column_name[start : end] 的方式。需要修改pg_chameleon源码中关于数组的范围选择方式。
pg_chameleon使用了继承表(INHERITS)功能,而当前openGauss不支持继承表。需要改写使用到继承表的SQL语句和表。
接下来我们将演示如何使用pg_chameleon迁移MySQL数据库至openGauss。
配置pg_chameleon
pg_chameleon通过~/.pg_chameleon/configuration下的配置文件config-example.yaml定义迁移过程中的各项配置。整个配置文件大约分成四个部分,分别是全局设置、类型重载、目标数据库连接设置、源数据库设置。全局设置主要定义log文件路径、log等级等。类型重载让用户可以自定义类型转换规则,允许用户覆盖已有的默认转换规则。目标数据库连接设置用于配置连接至openGauss的连接参数。源数据库设置定义连接至MySQL的连接参数以及其他复制过程中的可配置项目。
详细的配置项解读,可查看官网的说明:
https://pgchameleon.org/documents_v2/configuration_file.html
下面是一份配置文件示例:
# global settings
pid_dir: '~/.pg_chameleon/pid/'
log_dir: '~/.pg_chameleon/logs/'
log_dest: file
log_level: info
log_days_keep: 10
rollbar_key: ''
rollbar_env: ''
# type_override allows the user to override the default type conversion
# into a different one.
type_override:
"tinyint(1)":
override_to: boolean
override_tables:
- "*"
# postgres destination connection
pg_conn:
host: "1.1.1.1"
port: "5432"
user: "opengauss_test"
password: "password_123"
database: "opengauss_database"
charset: "utf8"
sources:
mysql:
db_conn:
host: "1.1.1.1"
port: "3306"
user: "mysql_test"
password: "password123"
charset: 'utf8'
connect_timeout: 10
schema_mappings:
mysql_database:sch_mysql_database
limit_tables:
skip_tables:
grant_select_to:
- usr_migration
lock_timeout: "120s"
my_server_id: 1
replica_batch_size: 10000
replay_max_rows: 10000
batch_retention: '1 day'
copy_max_memory: "300M"
copy_mode: 'file'
out_dir: /tmp
sleep_loop: 1
on_error_replay: continue
on_error_read: continue
auto_maintenance: "disabled"
gtid_enable: false
type: mysql
keep_existing_schema: No
以上配置文件的含义是,迁移数据时,MySQL侧使用的用户名密码分别是 mysql_test 和 password123。MySQL服务器的IP和port分别是1.1.1.1和3306,待迁移的数据库是mysql_database。
openGauss侧使用的用户名密码分别是 opengauss_test 和 password_123。openGauss服务器的IP和port分别是1.1.1.1和5432,目标数据库是opengauss_database,同时会在opengauss_database下创建sch_mysql_database schema,迁移的表都将位于该schema下。
需要注意的是,这里使用的用户需要有远程连接MySQL和openGauss的权限,以及对对应数据库的读写权限。同时对于openGauss,运行pg_chameleon所在的机器需要在openGauss的远程访问白名单中。对于MySQL,用户还需要有RELOAD、REPLICATION CLIENT、REPLICATION SLAVE的权限。
下面开始介绍整个迁移的步骤。
创建用户及database
在openGauss侧创建迁移时需要用到的用户以及database。
在MySQL侧创建迁移时需要用到的用户并赋予相关权限。
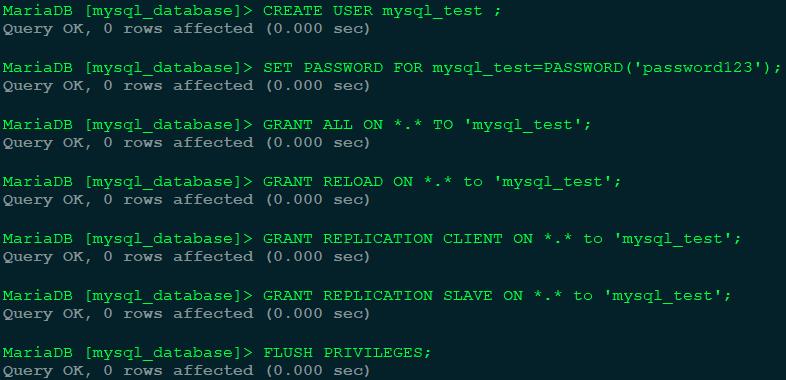
开启MySQL的复制功能
修改MySQL的配置文件,一般是/etc/my.cnf或者是 /etc/my.cnf.d/ 文件夹下的cnf配置文件。在[mysqld] 配置块下修改如下配置(若没有mysqld配置块,新增即可):
[mysqld]
binlog_format= ROW
log_bin = mysql-bin
server_id = 1
binlog_row_image=FULL
expire_logs_days = 10
修改完毕后需要重启MySQL使配置生效。
运行pg_chameleon进行数据迁移
1. 创建python虚拟环境并激活
python3 -m venv venv
source venv/bin/activate
2. 下载安装psycopg2和pg_chameleon
更新pip:pip install pip --upgrade
将openGauss的 pg_config 工具所在文件夹加入到 $PATH 环境变量中。例如:
export PATH={openGauss-server}/dest/bin:$PATH
下载psycopg2源码(https://github.com/psycopg/psycopg2 ),去掉检查PostgreSQL版本的限制,使用 python setup.py install编译安装。
下载pg_chameleon源码(https://github.com/the4thdoctor/pg_chameleon ),修改前面提到的在openGauss上的问题,使用 python setup.py install编译安装。
3. 创建pg_chameleon配置文件目录
chameleon set_configuration_files
4. 修改pg_chameleon配置文件
cd ~/.pg_chameleon/configuration
cp config-example.yml default.yml
根据实际情况修改 default.yml 文件中的内容。重点修改pg_conn和mysql中的连接配置信息,用户信息,数据库信息,schema映射关系。前面已给出一份配置文件示例供参考。
5. 初始化复制流
chameleon create_replica_schema --config default
chameleon add_source --config default --source mysql
此步骤将在openGauss侧创建用于复制过程的辅助schema和表。
6. 复制基础数据
chameleon init_replica --config default --source mysql
做完此步骤后,将把MySQL当前的全量数据复制到openGauss。
可以在openGauss侧查看全量数据复制后的情况。
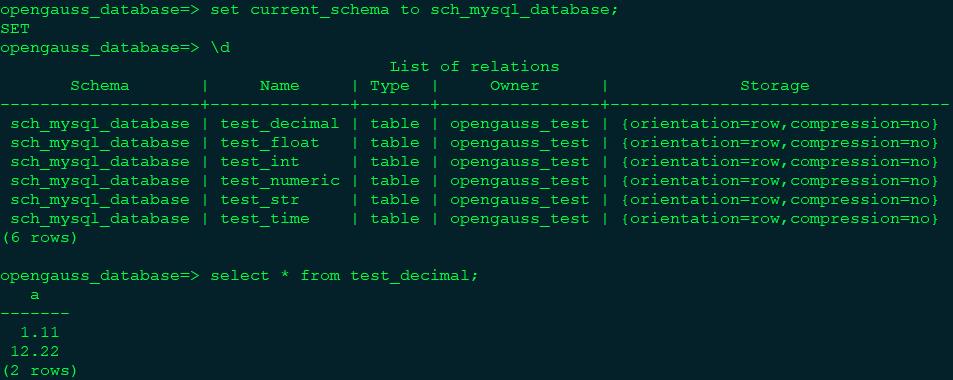
7. 开启在线实时复制
chameleon start_replica --config default --source mysql
开启实时复制后,在MySQL侧插入一条数据:
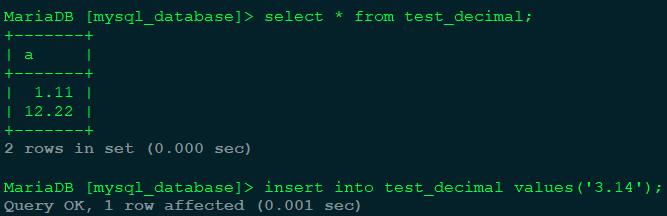
在openGauss侧查看 test_decimal 表的数据:
可以看到新插入的数据在openGauss侧成功被复制过来了。
8. 停止在线复制
chameleon stop_replica --config default --source mysql
chameleon detach_replica --config default --source mysql
chameleon drop_replica_schema --config default
|
往期回顾 |
|
|
|
以上是关于如何使用pg_chameleon迁移MySQL数据库至openGauss的主要内容,如果未能解决你的问题,请参考以下文章
如何使用文件将数据从 mysql 迁移到 clickhouse?
如何在mysql中使用laravel迁移将数据库列'null'更改为'nullable'?