精通springcloud:分布式日志记录和跟踪使用,Spring Cloud Sleuth
Posted jinggege795
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了精通springcloud:分布式日志记录和跟踪使用,Spring Cloud Sleuth相关的知识,希望对你有一定的参考价值。
Spring Cloud Sleuth
Spring Cloud Sleuth是一个相当小的简单项目,它为日志记录和跟踪提供了一些有用的功能。如果仔细研究“使用LogstashTCPAppender"小节中讨论的示例,就可以很容易地看出它不可能过滤与单个请求相关的所有日志。在基于微服务的环境中,在处理进入系统的请求时,关联应用程序交换的消息也非常重要。这是创建Spring Cloud Sleuth项目的主要动机。
如果为应用程序启用了Spring Cloud Sleuth,它会向请求添加一些HTTP标头,这允许开发人员将请求与响应和已交换的消息链接起来,这个交换是由独立应用程序完成的,而链接则可以通过RESTful API 之类的接口完成。它定义了两个基本的工作单位:跨度(Span)和跟踪(Trace) 。每一个单位都由唯一的64位ID标识。跟踪ID的值等于跨度ID的初始值。跨度是指单个交换,其中的响应将作为对请求的反应而发送。
跟踪通常称为关联IT (Correlation IT) ,它将帮助开发人员链接来自不同应用程序的所有日志,而这些日志是在处理进入系统的请求期间生成的。每个跟踪和跨度ID都会添加到Slf4J映射诊断上下文(MDC)中,因此,可以在日志聚合器(Log Aggregator) 中提取具有给定跟踪或跨度的所有日志。MDC只是一个存储当前线程上下文数据的映射。进入服务器的每个客户端请求都由不同的线程处理。由于这个原因,每个线程都可以在线程生命周期内访问其MDC的值。除了spanld和traceld之外,Spring Cloud Sleuth还向MDC添加了以下两个跨度。
口appName: 生成日志条目的应用程序的名称。
口exportable:指定是否应将日志导出到Zipkin。除了上述功能之外,Spring Cloud Sleuth还可以提供以下功能。
口对常见分布式跟踪数据模型的抽象,这允许与Zipkin的集成。
口记录计时信息,以帮助进行延迟分析。它还包括不同的采样策略以管理导出到Zipkin的数据量。
口与参与通信的常见Spring组件集成,如servlet过滤器、异步端点、RestTemplate、消息通道、Zuul 过滤器和Feign客户端等。
将 Sleuth与应用程序集成
要为应用程序启用Spring Cloud Sleuth功能,只需将spring-cloud-starter-sleuth启动器添加到依赖项即可。
<dependeney>
<groupId>org。springframework. cloud</groupId>
<artifactId>spring-cloud- starter-sleuth</artifactId>
</dependency>
包含此依赖项之后,应用程序生成的日志条目的格式已更改。具体如下所示。
2017-12-30 00:21:31. 639
INFO [order-service, 9a3fef0169864e80 , 9a3fef0169864e80, false]
49212 --- [ni0-8090- exec-6]
p.p.s.order。
controller.OrderController :Products found: [("id":2, "name":"Test2", "price":1500},
("id":9, "name" :"Test9","price":245011
2017-12-30 00:21:31.683
INFO [order-service, 9a3fef0169864e80, 9a3fef0169864e80, false ]
49212 --- [n10-8090- exec-6]
p.p.s.order。controller。OrderController :
Customer found: "id":2, "name":"Adam Smith",
"typel":"REGULAR", "accounts":
[("id":4, "number":"1234567893". "balance":50001,
("id":5, "number" :"1234567894", "balance":0},
{"id":6, "number":"1234567895", "balance":50001]1
2017-12-30 00:21:31.684
INFO [order-service, 9a3fef01 69864e80, 9a3fef0169864e80, false]
49212 --- [n1o-8090- exec-6]
p.p.s.order。controller。OrderController :
Discounted price:{"price":3752}
2017-12-30 00:21:31.684
INFO lorder-service, 9a3fef0169864e80, 9a3fef0169864e80, false]
49212 --- [n1o-8090- exec-6]
p.p.s.order。controller . OrderController :
Account found: {"id":4, "number": "1234567893","balance" :5000 }
2017-12-30 00:21:31.711
INFO [order-service, 58b06c4c412c76cc, 58b06c4c412c76cc, false]
49212 --- [ni0-8090- exec-7]
p.p.s.order . controller . OrderController :
Order found:{"id":4, "status": "ACCEPTED" ,
"price":3752, "customerId":2, "accountId":4, "prod uctIds":[9,2]1
2017-12-30 00:21:31.722
INFO lorder-service, 58b06c4c412c76cc,58b06c4c412c76cc,false]
49212 --- [n10-8090- exec-7]
p.p.s.order .controller.OrderController :
Account modified: {"accountId":4, "price":3752}
2017-12-30 00:21:31.723
INFO [order-service, 58b06c4c412c76cc, 58b06c4c412c76cc, falsel
49212 --- [ni0-8090- exec-7]
p.p.s.order .controller .OrderController :
Order status changed: {"status": "DONE"}
使用Kibana搜索事件
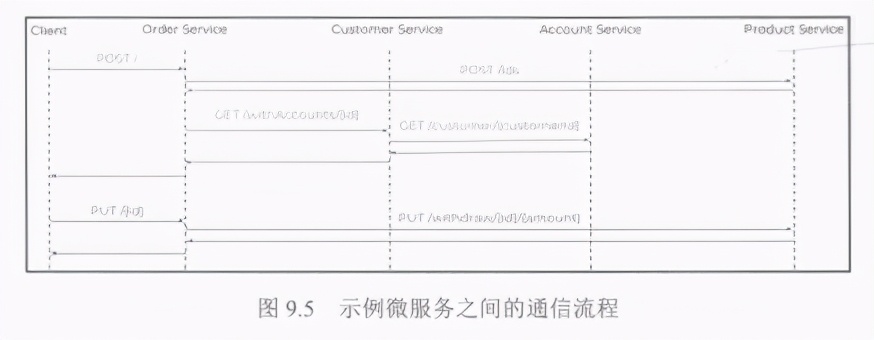
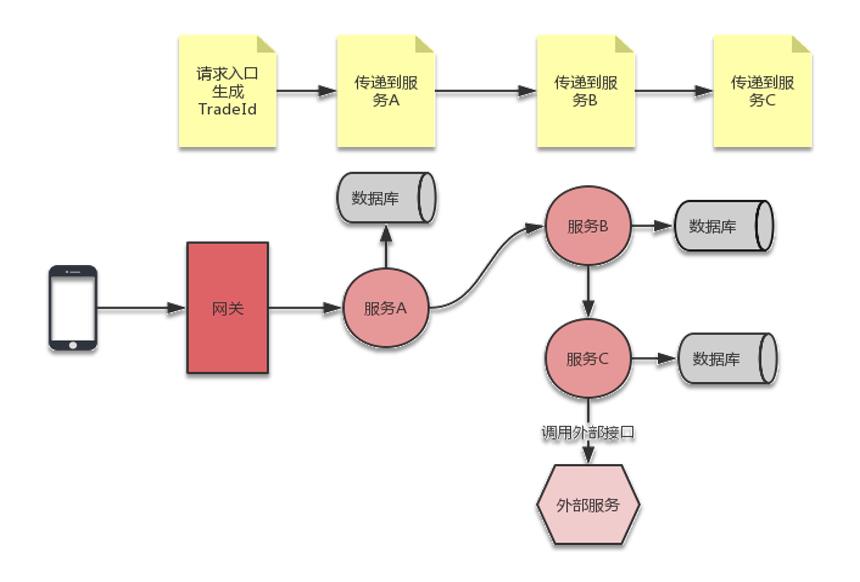
Spring Cloud Sleuth会自动将HTTP标头X .B3-Spanld和X- B3-Traceld添加到所有请求和响应中。这些字段也将作为spanld和traceld包含在MDC中。但在转移到查看Kibana仪表板之前,不妨来看一,看图9.5,这是一个顺序示意图,它说明了示例微服务之间的通信流程。
order-service服务公开了两个可用的方法。第一个方法是创建新订单,第二个方法是确认订单。事实上,第一个POST 1方法将通过customer service服务直接从customer-service服务、produt-service 服务和account-service服务调用所有其他服务的端点。第二个PUT/{id}方法仅与account-service服务中的一个端点集成。
现在可以通过存储在ELK堆栈中的日志条目来映射先前描述的流程。在使用Kibana作为日志聚合器的情况下,再加上由Spring Cloud Sleuth生成的字段,开发人员即可通过使用跟踪或跨度ID过滤它们来轻松查找条目。在图9.6所示的示例中,可以发现与POST方法调用的order-service 服务端点相关的所有事件,其X-B3-Traceld字段等于103c949877519c2。

图9.7也是一个示例,它类似于上一个示例,但处理请求期间存储的所有事件都将发送到PUT/{id}端点。这些条目也已经被X-B3-Traceld字段过滤掉,X-B3-TraceId 字段的值等于7070b90bfb36c961。

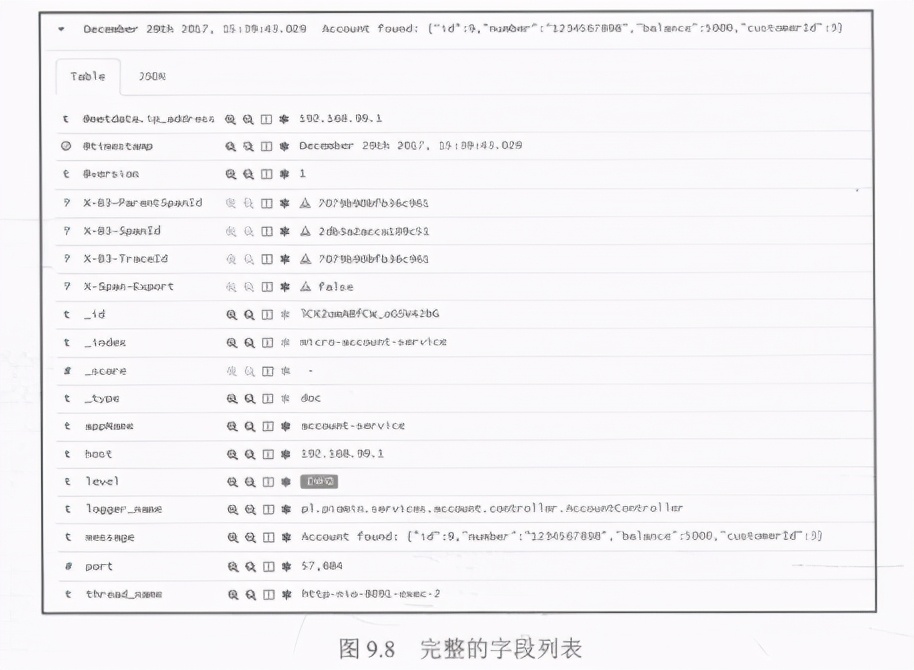
在图9.8中可以看到完整的字段列表,这些字段已由微服务应用程序发送到Logstash。Spring Cloud Sleuth库已将包含X-前缀的字段包含在消息中。
集成 Sleuth和Zipkin
Zipkin是一种流行的开源分布式跟踪系统,它有助于收集分析基于微服务的架构中的延迟问题所需的计时数据。它能够使用用户界面Web控制台收集、查找和可视化数据。Zipkin用户界面提供了一个依赖关系图,显示系统中所有应用程序处理了多少个跟踪请求。Zipkin由4个元素组成,前面已经提到过其中一个,即Web用户界面。第二个是Zipkin收集器,它负责验证、存储和索引所有传入的跟踪数据。Zipkin 使用Cassandra作为默认的后端存储。它本身也支持Elasticsearch和mysql.最后一个元素是查询服务,它提供了一个简单的JSONAPI,用于查找和检索跟踪。它主要由Web用户界面使用。
1.运行Zipkin服务器
开发人员可以通过多种方式在本地运行Zipkin 服务器。其中一种方法涉及使用Docker容器。以下命令将启动内存服务器实例。
docker run -d --name zipkin -P 9411: 9411 openzipkin / zipkin
在运行Docker容器之后,Zipkin API在htp://192.1/8.99.100:9411可用。或者,也可以使用Java库和Spring Boot应用程序启动它。要为应用程序启用Zipkin,应该将以下依赖项包含在Maven的pom.xml文件中,如以下代码片段所示。默认版本由spring-cloud-dependencies管理。具体到本示例应用程序,则使用了Edgware.RELEASE Spring Cloud版本列车。
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-server</artifactId>
</ dependency>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactid>zipkin-autoconfigure-ui</artifactId>
</ dependency>
在本示例系统中添加了一个新的zipkin-service 模块。这很简单,唯一需要实现的是应用程序main类,它使用@EnableZipkinServer进行注解。由于这个原因,Zipkin 实例将嵌入Spring Boot应用程序中。
@SpringBootApplication
@EnableZipkinServer
public class zipkinApplication
public static void main(string[] args)
new
SpringApplicationBuilder (ZipkinApplication.class) .web(true) .run(args);
}
}
为了在其默认端口上启动Zipkin 实例,必须覆盖application.yml文件中的默认服务器端口。启动该应用程序之后,可在htp:/:ocalhost:9411处使用Zipkin API。
spring:
application:
name: zipkin-service
server:
port: S[PORT:94111
2.构建客户端应用程序
如果要在项目中同时使用Spring Cloud Sleuth 和Zipkin,则只需在依赖项中添加spring-cloud starter zipkin启动器即可,它将启用通过HTTP API与Zipkin的集成。如果已将Zipkin服务器作为Spring Boot应用程序内的嵌入式实例启动,则不必提供包含连接地址的任何其他配置。如果使用Docker 容器,则应覆盖pplicationyml中的默认URL。
spring:
zipkin:
baseUrl: http://192.168.99. 100:9411/
开发人员始终可以利用与服务发现的集成。如果通过@EnableDiscoveryClient为使用嵌入式Zipkin服务器的应用程序启用了发现客户端,则可以将属性spring zipkin locator.discovery.enabled设置为true.在这种情况下,即使它在默认端口下不可用,所有应用程序也可以通过已注册名称对其进行本地化。开发人员还应该使用spring zipkinbaseUrl属性覆盖默认的Zipkin应用程序名称。
spring:
zipkin:
baseUrl: http://zipkin-service/
默认情况下,Spring Cloud Sleuth 仅发送一些选定的传入请求。 它由属性
spring.sleuth.sampler.percentage确定,其值必须是0.0和1.0之间的两倍。这个采样的解决方案已经实现,因为分布式系统之间交换的数据量有时非常高。SpringCloudSleuth提供了可以实现的采样器接口,以控制采样算法。PercentageBasedSampler 类中提供了默认实现。如果想要跟踪应用程序交换的所有请求,只需声明AlwaysSamplerbean.它可能对测试目的有用。
@Bean
public Sampler defaultSampler() {
return new Alwayssampler();
}
(1)使用Zipkin用户界面分析数据
现在回到刚才的示例系统。如前所述,新的zipkin-service模块已被添加。我们还为所有微服务(包括gateway-service服务)启用了Zipkin 跟踪。默认情况下,Sleuth 将采用值spring application.namne作为span 的服务名称。开发人员可以使用spring zipkin.service.name属性覆盖该名称。
要使用Zipkin成功测试我们的系统,必须启动微服务、网关、发现和Zipkin服务器。要生成并发送一些测试数据, 可以运行由plpiomin services gateway CGatewayotollerTest类实现的JUnit测试。它将通过gateway-service服务向order-service 服务发送100条消息,这可从
htp:/locahost:8080/api/order/**处获得。
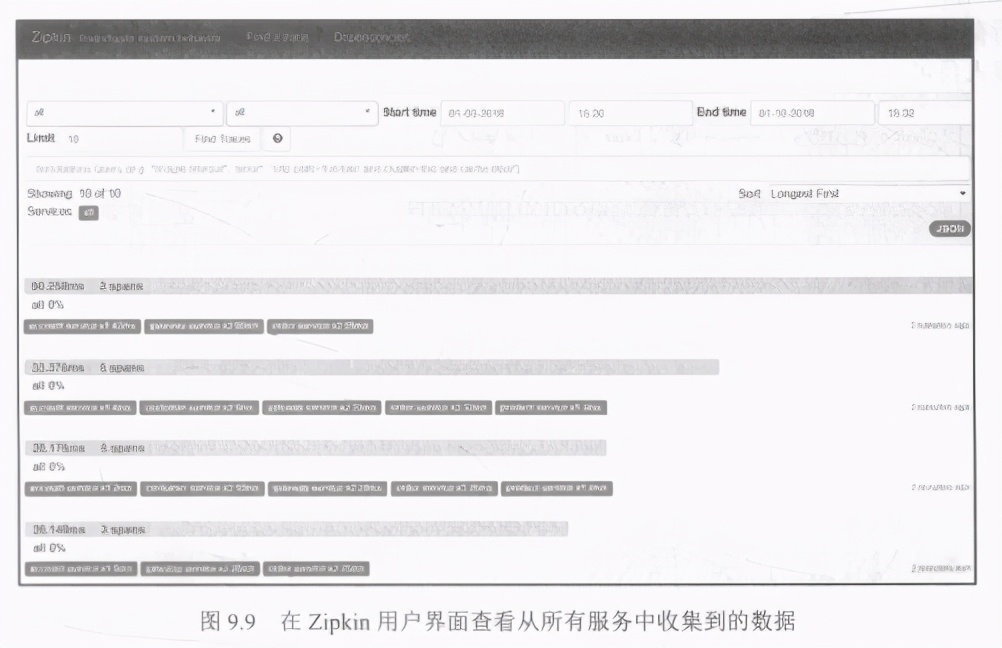
现在来分析Zipkin从所有服务中收集到的数据。可以使用其用户界面Web控制台轻松检查它。所有跟踪都标记有服务的名称跨度。如果条目有5个跨度,则表示进入系统的请求已由5个不同的服务处理,如图9.9所示。
开发人员可以使用不同的条件筛选条目,如服务名称、跨度名称、跟踪ID、请求时间或持续时间等。Zipkin 还可以显示失败的请求,并按持续时间、降序或升序对它们进行排序,如图9.10所示。

开发人员还可以查看每个条目的详细信息。Zipkin 将以可视化方式显示参与通信的所有微服务之间的流程。如图9.11 所示,它显示的是对每个传入请求的数据的计时。开发人员可以通过它了解系统中延迟的原因。

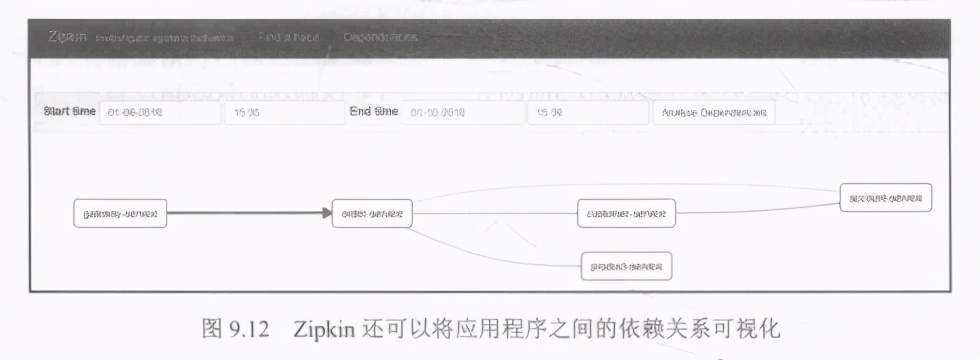
Zipkin还提供了一些额外的有趣功能。其中之一是可视化应用程序之间的依赖关系。如图9.12所示,它显示了本示例系统的通信流程。
开发人员可以通过单击相关元素来查看服务之间已交换的消息数量,如图9.13所示。

(2)通过消息代理集成
通过HTTP与Zipkin集成不是唯一-的选择。 与Spring Cloud 一样,开发人员也可以使用消息代理作为代理。有两个可用的代理一RabbitMQ 和Kafka。第一个可以通过使用springrabbit依赖项包含在项目中,而第二个则可以使用spring kafka包含在项目中。这两个代理的默认目标名称都是zipkin.
<dependency>
<groupId>org. springframework. cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</ dependency>
<dependency>
<groupId>org. springfr amework. amqp</groupId>
<artifactId>spring-rabbit</artifactId>
</dependency>
此功能还需要在Zipkin 服务器端进行更改。我们已经配置了一个用户来侦听进入RabbitMQ或Kafka队列的数据,所以,要实现此目的,只需在项目中包含以下依赖项即可。开发人员仍然需要在类路径中使用zipkin server和zipkin autoconfigure-ui工件。
<dependency>
<groupId>org. springframework. cloud</groupId>
<artifactid>spring-cloud-sleuth-zipkin-stream</artifactId>
</dependency>
<dependency>
<groupId>org.spr ingframework.cloud</groupId>
<artifactId>spring-cloud- starter-stream- rabbit</artifactId>
</ dependency>
开发人员应该使用@EnableZipkinStreamServer而不是@EnableZipkinServer来注解应用程序main 类。幸运的是,@EnableZipkinStreamServer 也是使用@EnableZipkinServer注解的,这意味着开发人员还可以使用标准的Zipkin服务器端点来收集HTTP上的跨度,并使用UIWeb控制台进行搜索。
@SpringBootApplication
@EnableZipkinst reamServer
public class ZipkinApplication {
public static void main(stringl] args) {
new
SpringApplicationBuilder (ZipkinApplication.class) .web(true) .run(args);
}
}
小结
在开发过程中,记录日志和跟踪通常都不是很重要,但这些是维护系统时使用的关键功能。本章将重点放在开发和运营领域,展示了如何以多种方式将Spring Boot微服务应用程序与Logstash和Zipkin集成。本章还提供了一些示例,以说明如何为应用程序启用Spring Cloud Sleuth功能,从而更轻松地监视许多微服务之间的调用。阅读完本章之后,开发人员还应该能够有效地使用Kibana作为日志聚合工具,并使用Zipkin作为跟踪工具来发现系统内部通信的“瓶颈”。
Spring Cloud Sleuth与Elastic Stack和Zipkin一起,似乎是一个非常强大的生态系统,它提供了由许多独立微服务组成的系统监控问题的解决方案,消除了对于该问题的任何疑虑。
觉得文章不错的朋友可以转发此文关注小编,有需要的可以扫码下方获取;

以上是关于精通springcloud:分布式日志记录和跟踪使用,Spring Cloud Sleuth的主要内容,如果未能解决你的问题,请参考以下文章