Tensorflow 2.0|网络优化与参数选择及Dropout抑制过拟合原则
Posted 码丽莲梦露
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Tensorflow 2.0|网络优化与参数选择及Dropout抑制过拟合原则相关的知识,希望对你有一定的参考价值。
1 网络容量
可以认为网络容量与网络中的可训练参数成正比,网络中神经元数越多,层数越多,神经网络的拟合能力越强。但是训练速度、难度越大,越容易产生过拟合。
增加网络容量:增加层或增加神经元个数。
2 如何选择超参数?
所谓超参数,也就是搭建神经网络中,需要我们自己去选择(不是通过梯度下降算法去优化)的那些参数。比如,中间层的神经元个数、学习率。
3 如何提高网络的拟合能力
一种显然的想法是增大网络容量:
1 增加层
2 增加隐藏神经元的个数
哪种好呢?
单纯增加神经元个数对于网络性能的提高并不明显,增加层会大大提高网络的拟合能力,这也是为什么现在深度学习的层越来越深的原因。
注意:单层的神经元个数,不能太小,太小的话,会造成信息瓶颈,使得模型欠拟合。
案例1
注:这是用的一个tensorflow自带的一个数据库fashion_mnist
import tensorflow as tf
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
(train_image,train_label),(test_image,test_label)=tf.keras.datasets.fashion_mnist.load_data()
train_image=train_image/255 #数据归一化
test_image=test_image/255
#采用独热编码
train_label_onehot=tf.keras.utils.to_categorical(train_label)
test_label_onehot=tf.keras.utils.to_categorical(test_label)
#建立模型
model=tf.keras.Sequential()
model.add(tf.keras.layers.Flatten(input_shape=(28,28)))#每个数据是一个二维数据,要Flatten一下
model.add(tf.keras.layers.Dense(128,activation='relu'))
model.add(tf.keras.layers.Dense(128,activation='relu'))
model.add(tf.keras.layers.Dense(128,activation='relu'))
model.add(tf.layers.Dense(10,activation='softmax')) #softmax,将十个输出输出为概率
#编译
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
loss='categorical_crossentropy',
matrics='acc'
)
history=model.fit(train_image,train_label_onehot,
epochs=10,
validation_data=(test_image,test_label_onehot))
plt.plot(history.epoch,history.history.get('loss'),label='loss')
plt.plot(history.epoch,history.history.get('val_loss'),label='val_loss')
plt.legend()
plot.show()
plot.plot(history.epoch,history.history.get('acc'),label='acc')
plot.plot(history.epoch,history.history.get('val_acc'),label='val_acc')
plt.legend()
plot.show() 
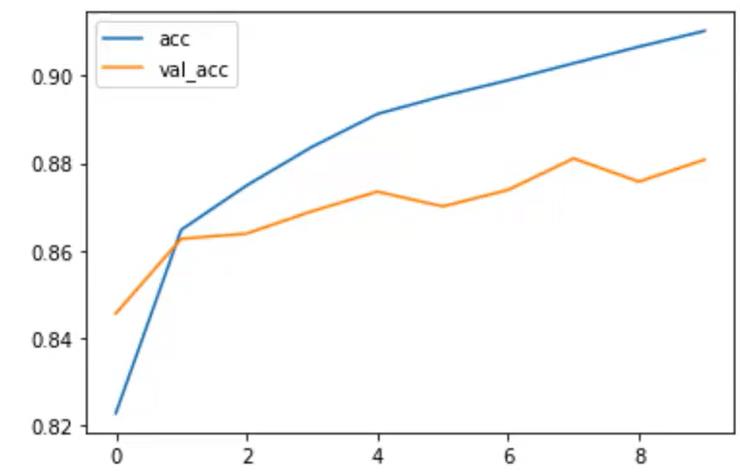
由上面两张图可以看到,已经有增加了神经网络的层数,已经达到了一点过拟合的趋势
4 Dropout抑制过拟合与参数选择
原理图:

注:上面是输出,在训练的过程中,让标准神经网络人为的丢掉一些层,使它得到一部分层,得到右图所示结果。
Dropout可以解决过拟合的原因:
(1)取平均作业:先回到标准的模型即没有dropout,我们用相同的训练数据去训练5个不同的神经网络,一般会得到5个不同的结果,此时我们采用“5个结果取均值”或者“多数取胜的投票策略”去决定最终结果。
(2)减少神经元之间的复杂的共适应关系:因为dropout程序导致两个神经元不一定每次都在一个dropout网络中出现,这样的权值的更新不再依赖于有固定关系的隐含节点的共同作用,阻止了某些特征仅仅在其他特定特征下才有效果的情况。
(3)Dropout类似于性别在生物进化中的角色:物种为了生存往往会倾向于适应这种环境,环境突变则会导致物种难以做出及时反应,性别的出现可以繁衍出适应新环境的变种,有效的阻止过拟合,即避免环境改变物种可能面临的灭绝
4.1 参数选择原则
理想的模型是刚好在欠拟合和过拟合的界限上,也就是正好拟合数据
4.1.1 首先开发一个过拟合模型
原因:保证网络足够的拟合能力
(1)添加更多的层
(2)让每一层变得更大
(3)训练更多的轮次
4.1.2 抑制过拟合
抑制的方法:
(1)dropout
(2)正则化
(3)图像增强
4.1.3 再次调节超参数
(1)学习速率
(2)隐藏层单元数
(3)训练轮次
注:超参数的选择是一个经验与不断测试的结果
4.2 构建网络的总规则
(1)增大网络容量,直到过拟合
(2)采取措施抑制过拟合
(3)继续增大网络容量,直到过拟合
案例2:案例1的延伸
import tensorflow as tf
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
(train_image,train_label),(test_image,test_label)=tf.keras.datasets.fashion_mnist.load_data()
train_image=train_image/255 #数据归一化
test_image=test_image/255
#采用独热编码
train_label_onehot=tf.keras.utils.to_categorical(train_label)
test_label_onehot=tf.keras.utils.to_categorical(test_label)
#建立模型
model=tf.keras.Sequential()
model.add(tf.keras.layers.Flatten(input_shape=(28,28)))#每个数据是一个二维数据,要Flatten一下
model.add(tf.keras.layers.Dense(128,activation='relu'))
model.add(tf.keras.Dropout(0.5)) #表示丢弃百分之50
model.add(tf.keras.layers.Dense(128,activation='relu'))
model.add(tf.keras.Dropout(0.5)) #表示丢弃百分之50
model.add(tf.keras.layers.Dense(128,activation='relu'))
model.add(tf.keras.Dropout(0.5)) #表示丢弃百分之50
model.add(tf.layers.Dense(10,activation='softmax')) #softmax,将十个输出输出为概率
#编译
model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
loss='categorical_crossentropy',
matrics='acc'
)
history=model.fit(train_image,train_label_onehot,
epochs=10,
validation_data=(test_image,test_label_onehot))
plt.plot(history.epoch,history.history.get('loss'),label='loss')
plt.plot(history.epoch,history.history.get('val_loss'),label='val_loss')
plt.legend()
plot.show()
plot.plot(history.epoch,history.history.get('acc'),label='acc')
plot.plot(history.epoch,history.history.get('val_acc'),label='val_acc')
plt.legend()
plot.show()
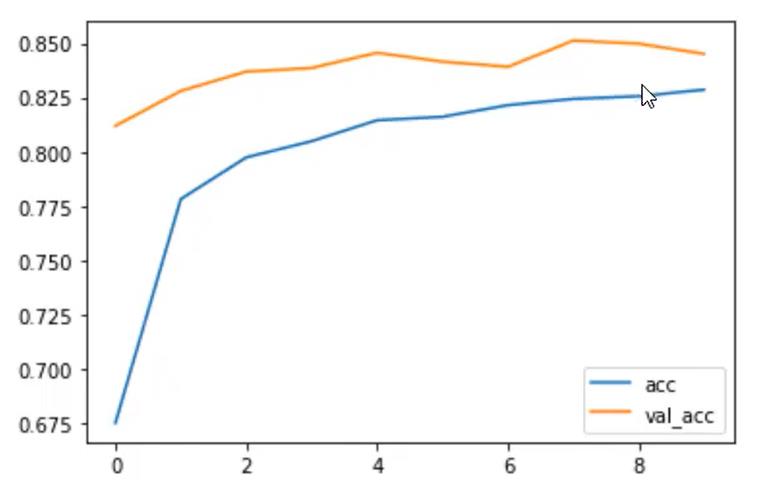
增加了Dropout后再训练可以看到,已经没有过拟合了,且准确率比train的正确率还高。
以上是关于Tensorflow 2.0|网络优化与参数选择及Dropout抑制过拟合原则的主要内容,如果未能解决你的问题,请参考以下文章