MySQL.MySQL基础
Posted qq_51102350
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL.MySQL基础相关的知识,希望对你有一定的参考价值。
一,计算字段
储存在表中的数据不一定是应用程序想要的模式,所以我们需要在数据库中检索出转换、计算或格式化过的数据。
字段(field):在SQL中约等于 列(column),由此,计算字段约等于计算列
计算字段:
在 SELECT 语句中创建,在数据表中并没有实际存在,只是一个运算过程
相当于通过对列的运算,形成一个新的列
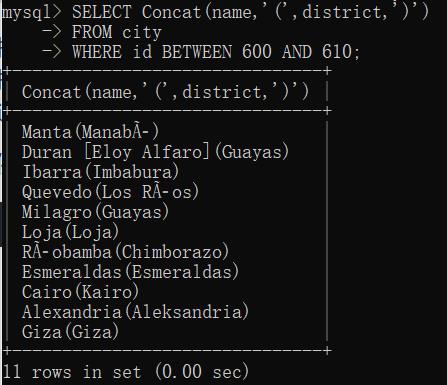
①拼接字段:
拼接:将值联结到一起构成单个值
运用Concat()函数来实现
例:
Trim(),LTrim(),RTrim():
去掉串两边、左边、右边的空格
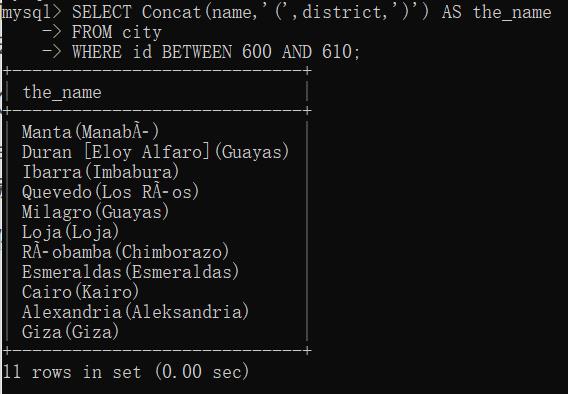
②使用别名
所得到的计算字段只是一个值,为了让客户机能引用它,给它一个别名(alias),用关键字AS赋予
例:
执行算术计算:
如:
SELECT prod_id,
quantity,
item_price,
quantity*item_price AS expanded_price
FROM orderitems
MySQL支持+,-,*,/等基本运算符
二,数据处理函数
函数分类:
- 文本函数:处理文本串
- 数值函数:对数值数据进行算术操作的算术函数
- 日期和时间函数:处理日期和时间值
- 系统函数:返回DBMS相关信息
①文本函数
这些函数参数皆为文本值
| 函数 | 说明 |
|---|---|
| Left() | 返回串左边的字符 |
| Right() | 返回串右边的字符 |
| Length() | 返回串的长度 |
| Locate() | 找出串的一个子串 |
| Lower() | 将串转换为小写 |
| upper() | 将串转换为大写 |
| LTrim() | 去掉串左边的空格 |
| RTrim() | 去掉串右边的空格 |
| Soundex() | 返回串的SOUNDEX值 |
| SubString() | 返回子串的字符 |
SOUNDEX:一串描述串的发音的字母数字
参见:SOUNDEX
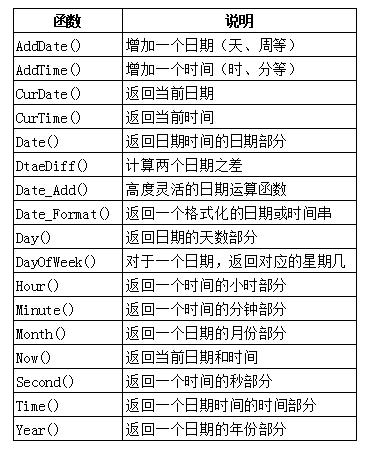
②日期和时间处理函数
MySQL日期格式yyyy-mm-dd
//不推荐
SELECT cust_id, order_num
FROM orders
WHERE order_date = '2005-09-01';
//推荐
SELECT cust_id, order_num
FROM orders
WHERE DATE(order_date) = '2005-09-01';
//返回九月的内容
SELECT cust_id, order_num
FROM orders
WHERE DATE(order_date) = BETWEEN '2005-09-01' AND '2005-09-30';
//返回九月的内容
SELECT cust_id, order_num
FROM orders
WHERE Year(order_date) = 2005 AND Month(order_date) = 9;
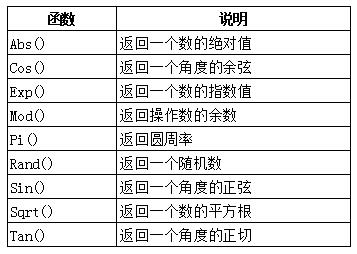
③数值处理函数
④聚集函数
运行在行组上,计算和返回单个值的函数
用于汇总数据
| 函数 | 说明 |
|---|---|
| AVG() | 返回某列的平均值 |
| COUNT() | 返回某列的行数 |
| MAX() | 返回某列最大值 |
| MIN() | 返回某列最小值 |
| SUM() | 返回某列值之和 |
AVG():
SELECT AVG(列名称) AS (别名)
FROM 表名称
WHERE 条件
说明:
- 参数为列名称
- 仅可用于单个列
- 忽略值为NULL的行
COUNT():
- COUNT(*):返回表中行数目
- COUNT(列名称):返回表中特点列的行数,不包括NULL值
SELECT COUNT(*) AS 别名
FROM 表名;
SELECT COUNT(列名称) AS 别名
FROM 表名;
SUM():
SELECT SUM(列名称) AS 别名
FROM 表名
WHERE 条件
//用于合计计算值
SELECT SUM(列名称1 运算符 列名称2) AS 别名
FROM 表名
WHERE 条件
聚集所有值,默认或ALL参数
聚集不同的值,DISTINCT参数
SELECT AVG(DISTINCT 列名称) AS 别名
FROM 表名
WHERE 条件
注意:DISTINCT后仅可跟列名,否则不合语法规则
三,数据分组
GROUP BY子句
HAVING子句
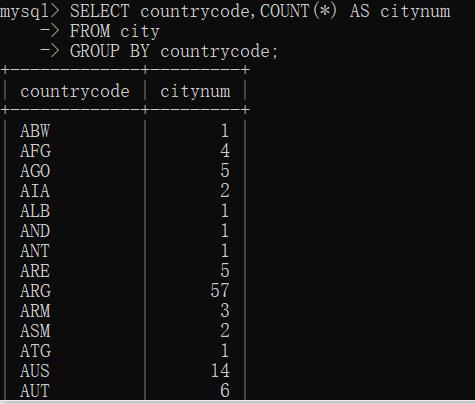
①创建分组
例子:
SELECT 列名称,COUNT(*) AS 别名
FROM 表名称
GROUP BY 列名称
此时,将输出包含各不同的列名称的行的数量
②过滤分组
HAVING 大部分情况可与 WHERE 互相替代
WHERE 过滤行,HAVING 过滤分组
HAVING 与 WHERE 句法相同
例子:
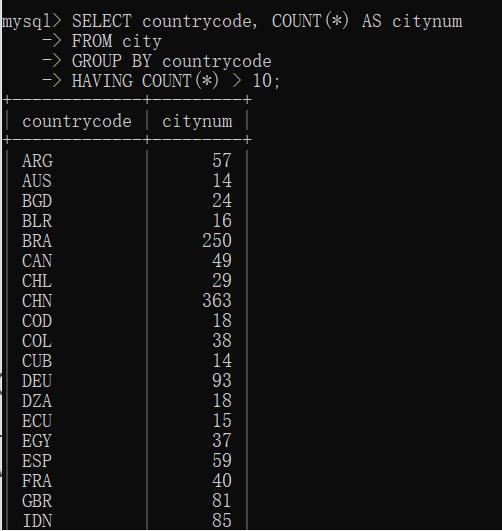
详解WHERE与HAVING
- 理解方法一:HAVING过滤基于分组聚集值,WHERE 基于特点行值
- 理解方法二:WHERE在数据分组前过滤,HAVING在数据分组后过滤
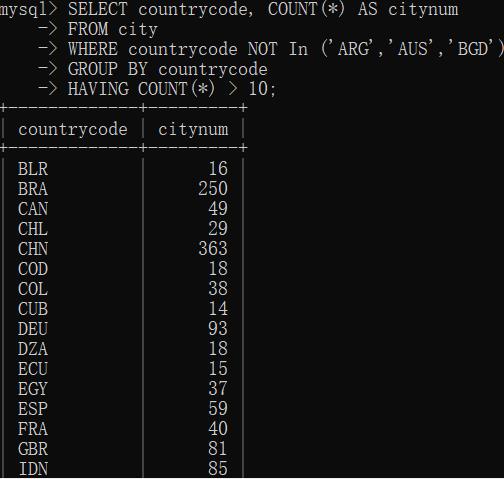
同时使用WHERE 和 HAVING:
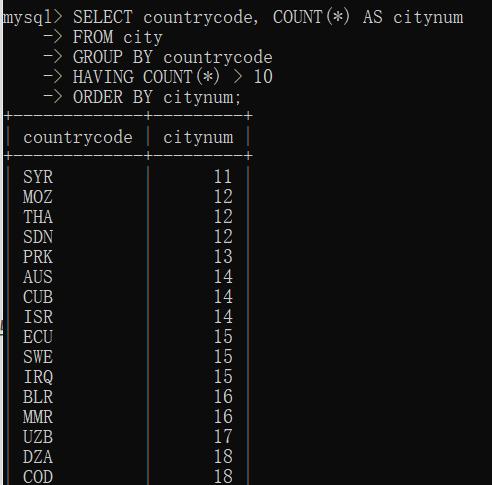
与ORDER BY一起使用:
③SELECT子句顺序
SELECT
FROM
WHERE
GROUP BY
HAVING
ORDER BY
LIMIT
四,子查询
子查询:嵌套在其他查询中的查询
①基本使用
例子:
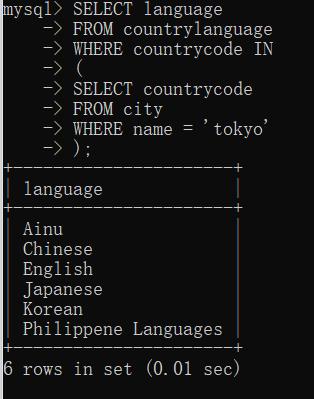
子查询可与IN、=、<>等结合使用
②将子查询作为计算字段使用
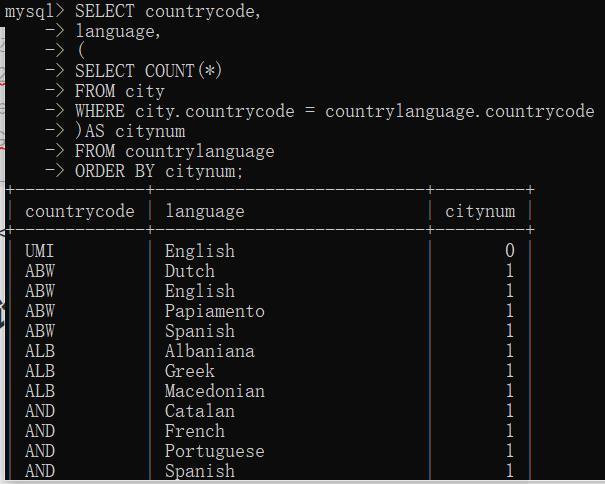
值得注意的是,WHERE子句使用了完全限定列名
相关子查询:涉及外部查询的子查询
若列名可能有多义性(属于不同的表),就应使用完全限定列名。
建立子查询的一点规范:
- 首先建立测试最内层的查询
- 然后用硬编码数据建立测试外层的查询
- 最后嵌入子查询并测试
五,联结表
关系表:把数据按类分为多个表,每个表通过某些常用的值(即所谓关系(relational))关联
主键(primary key):一个列,其值能唯一区分表中的每个行
外键(foreign key):外键为某个表中的一列,其值为另一个表的主键
可伸缩性(scale):数据库和软件适应不断增加的工作量的能力。
联结:一种机制,用于再一条SELECT语句中关联不同的表
使用特殊语法,可联结多个表返回一个联结表
①基本使用
规定要联结的表(FROM语句)以及其联结的方式(WHERE语句)
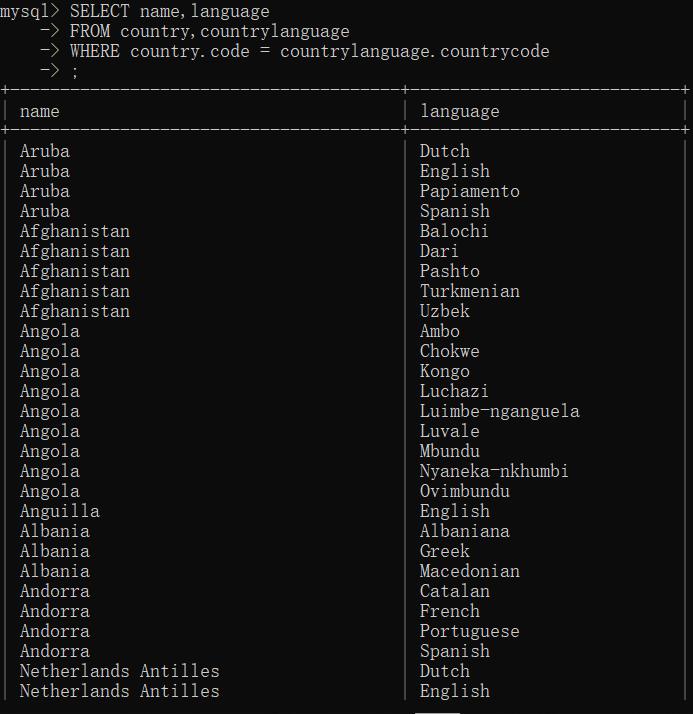
笛卡尔积:没有给定联结条件的联结表的行数为第一个表的行数与第二个表的行数的积
内部联结/等值联结:基于两个表间的相等测试的联结
INNER JOIN
ON子句
SELECT 列名称1,列名称2
FROM 表名称1 INNER JOIN 表名称2
ON 表名称1.列名称 = 表名称2.列名称
结果与上例的相同
②多表联结与表别名
多表联结
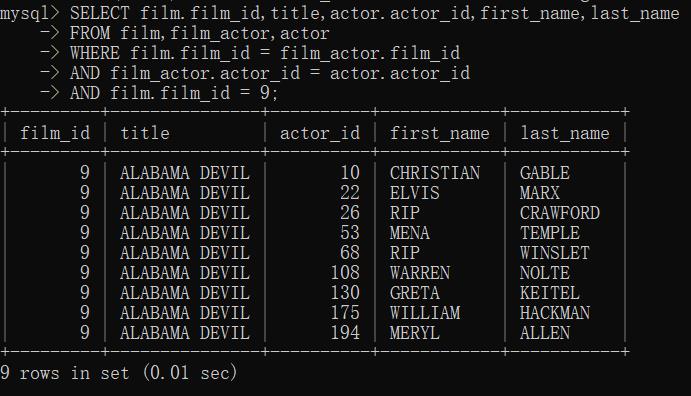
表别名:
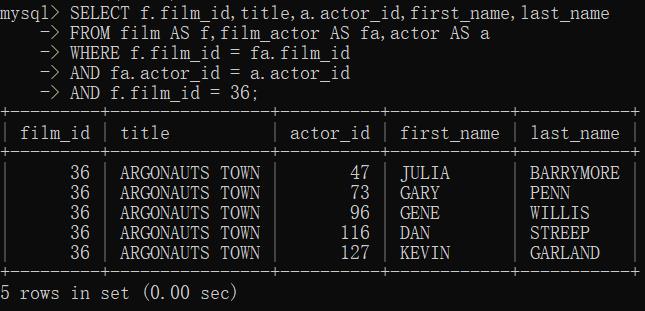
③自联结
考虑:知道一个城市很棒,你想知道该地区的其它城市如何,该怎么做呢?
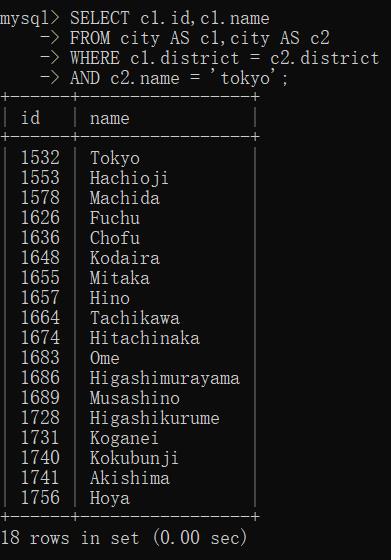
一点注释:
- 注意别名的使用
- 第一行中想要检索的数据以c1打头
- 最后一行中条件以c2打头
- WHERE 语句实现了所谓自联结
④自然联结
自然联结排除每个列多次出现,让每个列仅出现一次
参见:
自然联结
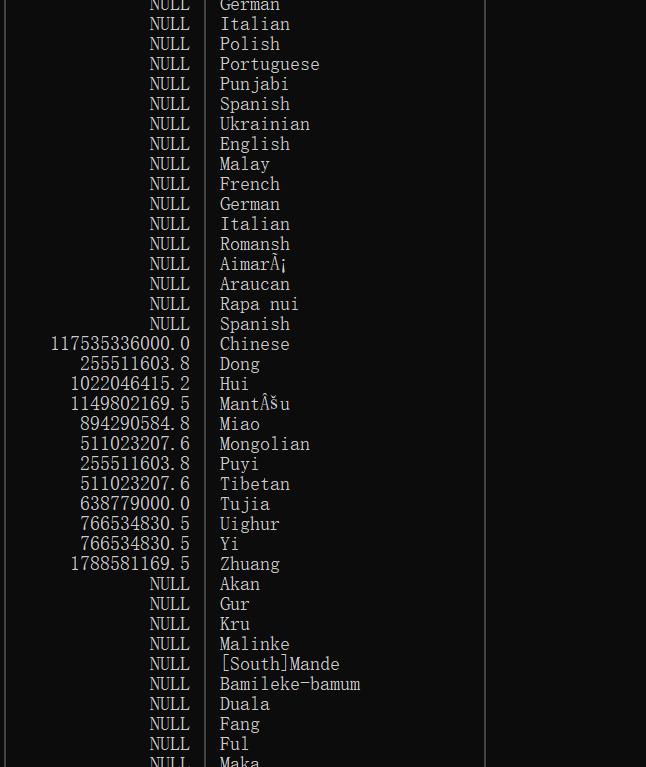
⑤外部联结
关键字OUTER JOIN:
使用时,必须通过关键字LEFT或RIGHT来指定包括所有行的的表(如下图包括了所有LANGUAGE
下接ON子句
考虑:检索语言,包括那些没有中国人使用的语言
代码:
SELECT (country.population * countrylanguage.percentage)AS language_user_num,
-> countrylanguage.language
-> FROM countrylanguage LEFT OUTER JOIN country
-> ON countrylanguage.countrycode = country.code
-> AND country.code = 'CHN';
结果:
③搭配聚集函数使用
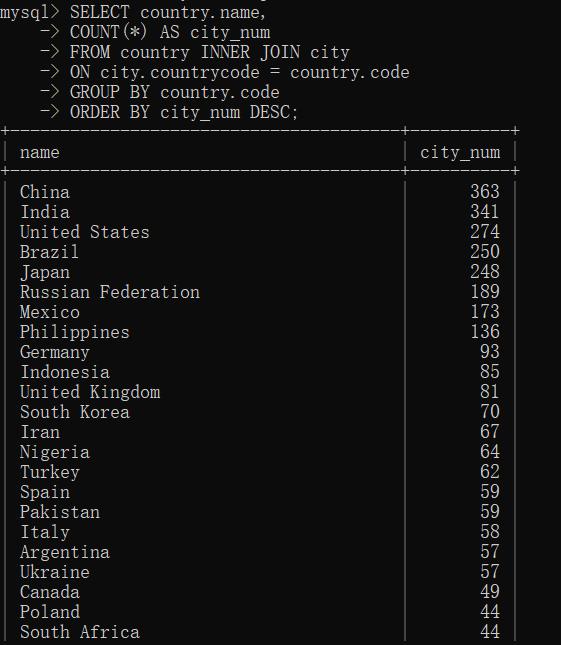
聚集函数可方便的与任何联结一起使用。
六,组合查询
亦称为并(union)或符合查询(compound query)
使用情景:
- 查询多个表返回相似结构的数据
- 多次查询一个表返回数据(该情景常由WHERE完成)
UNION操作符
使用规则:
- 由两条及以上的SELECT语句组成,使用UNION将这些语句分隔
- UNION中的每个查询需要包含相同的列、表达式或聚集函数
- 列数据类型必须兼容
- UNION将取消重复的行,若不想取消,则应使用UNION ALL
- 使用UNION组合查询时,仅可使用一条ORDER BY语句,出现再最后一条SELECT语句之后
总结:除了UNION ALL ,WHERE AND 和 UNION组合查询 看不出有啥区别
七,表的创建、更改和删除
①创建表
两种方式:
- 使用具有交互式创建和管理表的工具
- 直接使用MySQL语句
CREATE TABLE语句
需给出信息:
- 新表的名字
- 表列的名字和定义,以逗号分隔
补充知识:
MySQL数据类型
CREATE TABLE books
(
book_id int NOT NULL AUTO_INCREMENT,
book_name char(50) NOT NULL,
book_price int NULL,
book_writer char(50) NULL,
book_publisher char(50) NOT NULL DEFAULT 'I_publisher',
PRIMARY KEY (book_id)
)ENGINE=InnoDB;
说明:
- NOT NULL:不允许NULL值
- NULL:允许NULL值
- 每个列至少包含名字,数据类型,是否允许NULL值
- 关键字AUTO_INCREMENT:告诉MySQL,本列每当增加一行时自动增量,每个表只允许一个AUTO_INCREMENT列
- 主键值唯一:若主键使用单个列,则其值必须唯一;若使用多个列,则其组合值唯一
- 使用
PRIMARY KEY (列名称1,列名称2)来指定主键,主键不能使用允许NULL的列 - DEFAULT 指定默认值
ENGINE=引擎名指定引擎,可以省略,若省略,将使用默认引擎
结果:
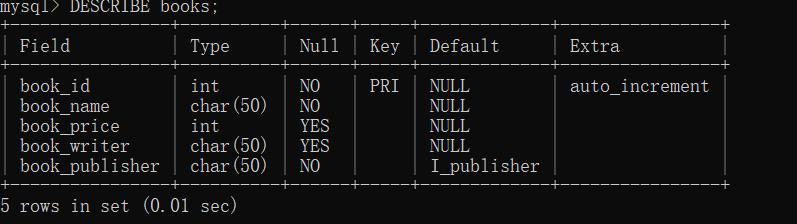
关于引擎:
DBMS都有一个管理和处理数据的内部引擎
当使用CREATE TABLE语句时,该引擎执行创建表的任务
当使用SELECT等语句时,该引擎在内部处理各种请求
外键不能跨引擎
②更新表
更新表是一种不被建议的举动,我们应该花更多的时间在表的设计和创建上
ALTER TABLE 语句
ALTER TABLE 表名
ADD 列名 类型名 NULL/NOT NULL
ALTER TABLE 表名
DROP 列名 类型名 NULL/NOT NULL
③删除表、重命名表
DROP TABLE 表名;
RENAME TABLE 旧表名1 TO 新表名1,
旧表名2 TO 新表名2;
八、数据操作
①数据插入
INSERT语句
用途:
- 插入完整的行
- 插入行的一部分
- 插入多行
- 插入某些查询的结果
基本操作:
要求指定表名和属于新行的各列的值
//不建议使用
INSERT INTO books
VALUES(1,
'La frantumaglia',
69,
'Elena Ferrante',
'Publisher of People'
);
//建议使用
INSERT INTO books
(
book_id,
book_name,
book_price,
book_writer,
book_publisher
)
VALUES(2,
'Marcovaldo',
42,
'Italo Calvino',
'Publisher of People'
);
//插入多行1(可以一次提交)
INSERT INTO books
(
book_id,
book_name,
book_writer,
book_price,
book_publisher
)
VALUES(3,
'Fly Already',
'Etgar Keret',
49,
'Publisher of People'
);
INSERT INTO books
(
book_id,
book_name,
book_price,
book_writer
)
VALUES(4,
'SAKER MIN SON BEHÖVER VETA OM VÄRLDEN',
40,
'Fredrik Backman'
);//省略列
//插入多行2
INSERT INTO books
(
book_id,
book_name,
book_writer,
book_price
)
VALUES(5,
'And A Voice to Sing With: A Memoir',
'Joan Baez',
68
),
(6,
'The Origins of Political Order',
'Francis Fukuyama',
88
);
//插入检索数据
INSERT INTO books
(
book_name,
book_price,
book_writer,
book_publisher
)
SELECT book_name,
book_price,
book_writer,
book_publisher
FROM books2;//别忘了空格
结果:
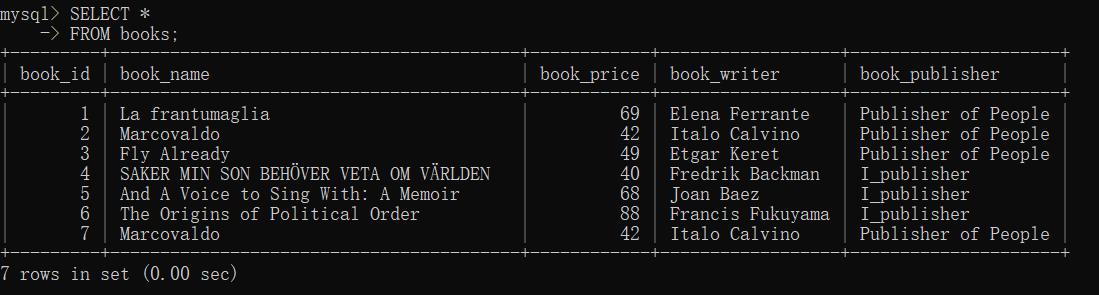
省略列:
可以在INSERT语句中省略某些列,这些列应满足:
- 该列允许NULL值
- 表定义中给出默认值
②数据更新、删除
UPDATE SET语句
IGNORE关键字
UPDATE 表名
SET 列名1=值1,
列名2=值2
WHERE 条件
//即使某项修改失败,其它修改仍会进行
UPDATE IGNORE 表名
SET 列名1=值1,
列名2=值2
WHERE 条件
DELETE关键字
DELETE FROM 表名
WHERE 条件
以上是关于MySQL.MySQL基础的主要内容,如果未能解决你的问题,请参考以下文章