爬虫日记(85):Scrapy的ExecutionEngine类
Posted caimouse
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫日记(85):Scrapy的ExecutionEngine类相关的知识,希望对你有一定的参考价值。
前面分析了Crawler类,这个类实现了爬虫创建和运行管理,同时也是一个爬虫的公共类,可以把这个类传送到各个类中去使用。紧接着就会把控制权交给下一个类ExecutionEngine,这个类的生命周期如下:

因此我们先来分析ExecutionEngine类的构造函数,理解它是怎么创建的,以及有什么样的数据结构,最后通过算法来理解这个类的功能实现。打开目录scrapy\\core,就可以找到文件engine.py,然后就可以分析这个类的代码了。
ExecutionEngine类的构造函数代码如下:
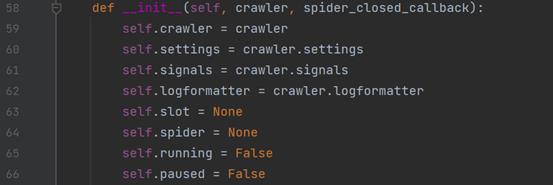
传入这个函数的参数crawler是Crawler类对象;参数spider_closed_callback是lambda _: self.stop()函数,就是爬虫类的结束函数的lambda函数。
第59
以上是关于爬虫日记(85):Scrapy的ExecutionEngine类的主要内容,如果未能解决你的问题,请参考以下文章