VGG 系列的探索与pytorch实现 (CIFAR10 分类问题) - Acc: 92.58 % (一文可通VGG + pytorch)
Posted Real&Love
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了VGG 系列的探索与pytorch实现 (CIFAR10 分类问题) - Acc: 92.58 % (一文可通VGG + pytorch)相关的知识,希望对你有一定的参考价值。
VGG 系列的探索与pytorch实现 CIFAR10 分类问题 - Acc: 92.58 %
VGG简单介绍
VGG模型是Oxford的Visual Geometry Group的组提出的,这个网络是在ILSVRC 2014上进行相关的工作,在ILSVRC 2014中超过Alex Net网络,拿到了当时分类项目的top 2 和 定位项目的top 1,VGGNet的拓展性很强,迁移到其他图片数据上的泛化性非常好。从此VGG进入了我们的视野,主要证明了增加网络的深度能够在一定程度上影响了网络最终的性能。
VGG net可以说是从Alex-net发展而来的网络,VGGNet论文中全部使用了33的卷积核和22的池化核,通过不断加深网络结构来提升性能,现在主要的都是VGG16和VGG19,顾名思义,就是有16层和19层。
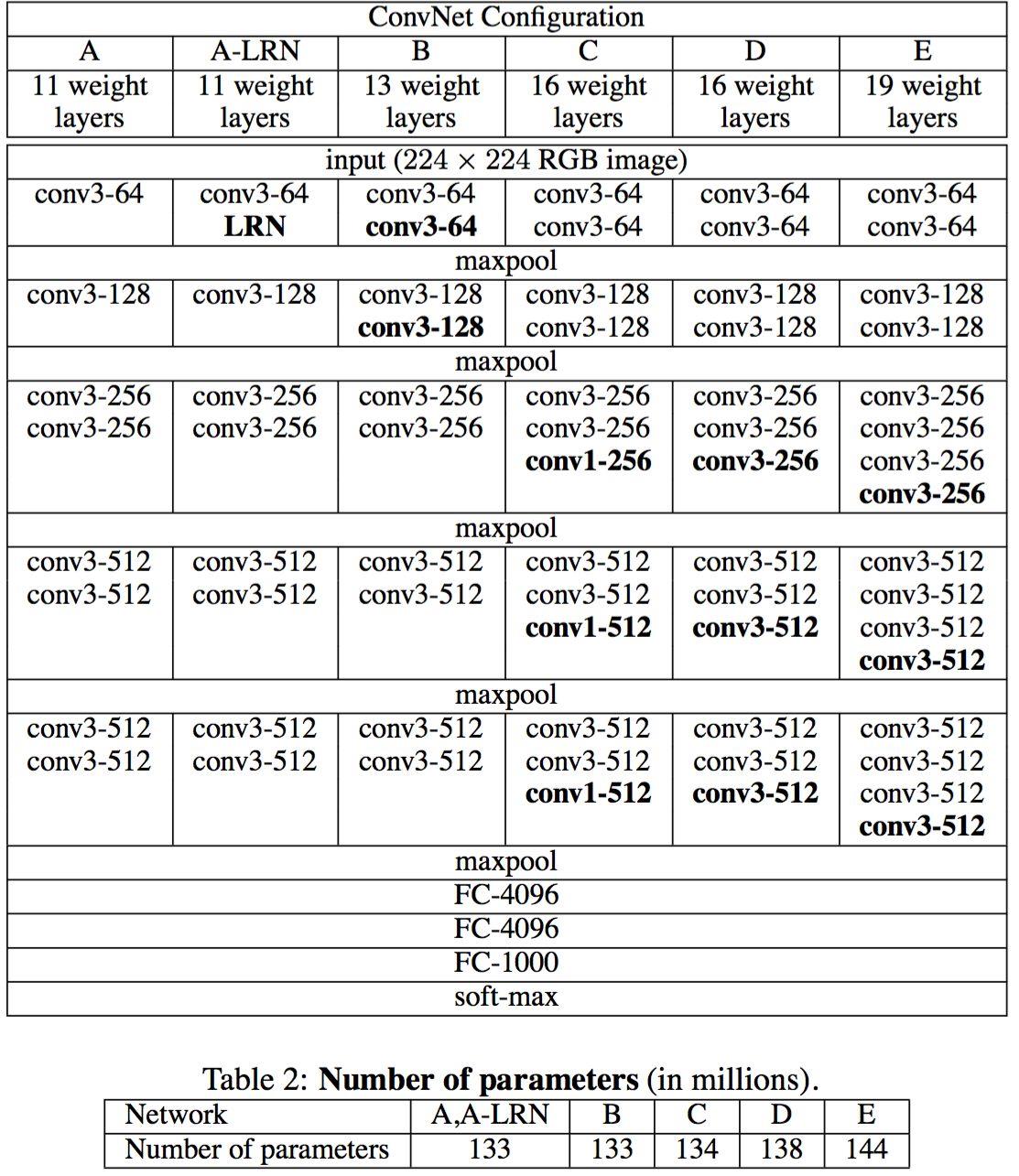
在论文《Very Deep Convolutional Networks for Large-Scale Image Recognition》详细的给出了VGG的详细介绍,D和E分别就是我们的VGG16和VGG19。先以VGG16为例子,VGG有16层,我把它分为六块.
Block1 首先第一块有两个输出通道为64的卷积层,卷积核为3x3,他的padding填充是1,然后最后加上一个最大池化层,kernel_size 为 2x2, 他的步长是2,填充padding为0,包括后面的池化层都是一样的
Block2 在第二块有两个输出通道为128的卷积层,卷积核为3x3,他的padding填充是1,也加上一个最大池化层,kernel_size 为2x2,步长为2,填充padding为0。
Block3 在第三块有三个输出通道为256的卷积层,卷积核为3x3,他的padding填充是1,也加上一个最大池化层,kernel_size 为2x2,步长为2,填充padding为0。
Block4 and Block5 第四块和第五块是一样的,都有三个输出通道为512的卷积层,卷积核为3x3,他的padding填充是1,也加上一个最大池化层,kernel_size 为2x2,步长为2,填充padding为0。
最后就是三个全连接层fully connected,这个论文的输入图像是224 x 224的RGB图像,然后我们的数据集是32 x 32 的 RGB图像,所以我们最后的全连接层的输出通道就分别是512,512,10,最后通过softmax得到我们的类别。
最后我们用pytorch做出来的VGG16的神经网络就是如此,在这中间我妹还加了Batch和Dropout,这些层都是为了使我们的程序能更好的拟合我们的数据,不至于过拟合。

VGG16 与 VGG19的区别
然后我们可以看出来VGG16 到 VGG19全连接层并没有什么变化,但是在VGG16第三,第四,第五块,我们分别加了一个卷积核,就是多加了三层,使得神经网络的层数增加了,更深了,得到了我们的VGG19的新类型。
这里我们引用论文中的一张图,这里其实嗐有很早期的VGG11,VGG13,可是慢慢随着时代的变换,现在会比较用VGG16和VGG19。
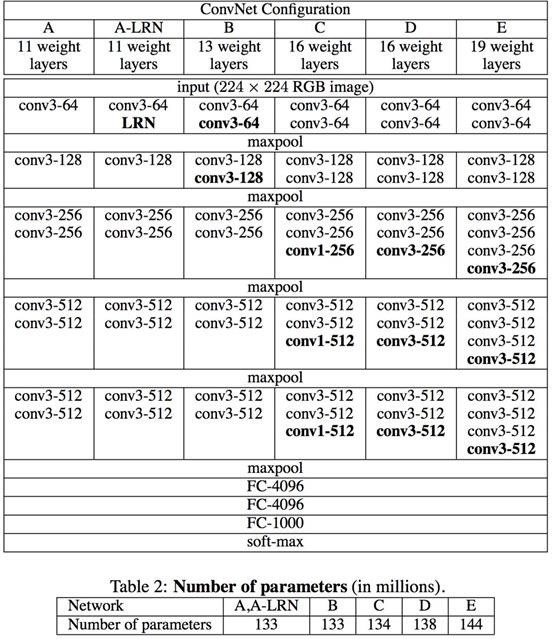
- VGG16包含了16个隐藏层(13个卷积层和3个全连接层),如上图中的D列所示
- VGG19包含了19个隐藏层(16个卷积层和3个全连接层),如上图中的E列所示
VGGNet拥有5段卷积,每一段内有2~3个卷积层,同时每段尾部会连接一个最大池化层用来缩小图片尺寸。每段内的卷积核数量一样,越靠后的段的卷积核数量越多:64-128-256-512-512。其中经常出现多个完全一样的3*3的卷积层堆叠在一起的情况,这其实是非常有用的设计。
但是不好的一点是它耗费更多计算资源,并且使用了更多的参数,导致更多的内存占用(140M)。其中绝大多数的参数都是来自于第一个全连接层,有些人研究除去最后的全连接层,我们的模型也没有很多变化,但是如果训练我们的VGG,会对计算负担有所增加,会花费比较长的时间。
在训练的过程中,比AlexNet收敛的要快一些,原因为:(1)使用小卷积核和更深的网络进行的正则化;(2)在特定的层使用了预训练得到的数据进行参数的初始化。
对于较浅的网络,如网络A,可以直接使用随机数进行随机初始化,而对于比较深的网络,则使用前面已经训练好的较浅的网络中的参数值对其前几层的卷积层和最后的全连接层进行初始化。
VGG原理
VGG16相比AlexNet的一个改进是采用连续的几个3x3的卷积核代替AlexNet中的较大卷积核(11x11,7x7,5x5)。对于给定的感受野(与输出有关的输入图片的局部大小),采用堆积的小卷积核是优于采用大的卷积核,因为多层非线性层可以增加网络深度来保证学习更复杂的模式,而且代价还比较小(参数更少)。
我们可以看看AlexNet,其实AlexNet也是2012的ILSVRC中的top1
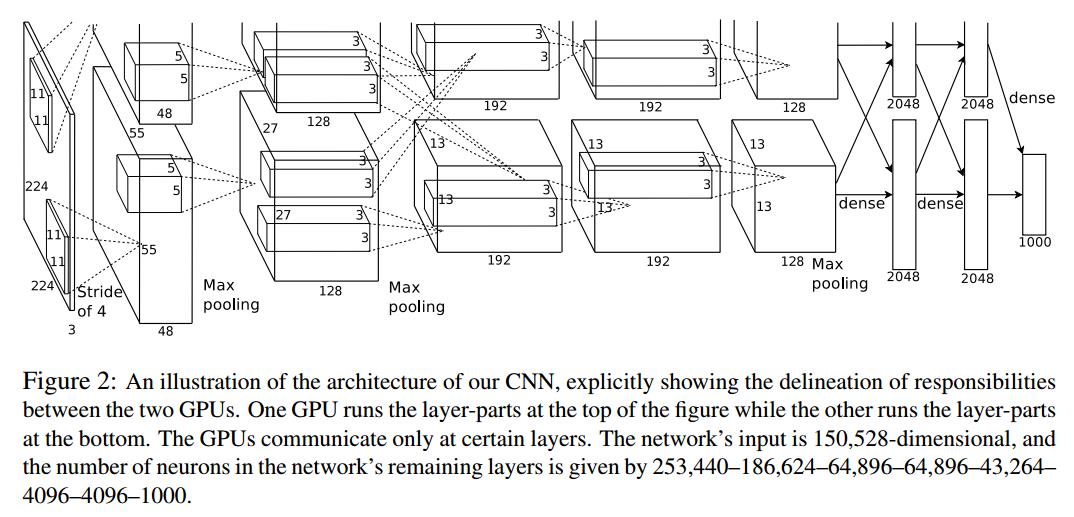
简单来说,在VGG中,使用了3个3x3卷积核来代替7x7卷积核,使用了2个3x3卷积核来代替5*5卷积核,这样做的主要目的是在保证具有相同感知野的条件下,提升了网络的深度,在一定程度上提升了神经网络的效果。
比如,3个步长为1的3x3卷积核的一层层叠加作用可看成一个大小为7的感受野(其实就表示3个3x3连续卷积相当于一个7x7卷积),其参数总量为 3x(9xC^2) ,如果直接使用7x7卷积核,其参数总量为 49xC^2 ,这里 C 指的是输入和输出的通道数。很明显,27xC^2 小于49xC^2,即减少了参数;而且3x3卷积核有利于更好地保持图像性质。
简单来说,就是2个3x3卷积核来代替5x5卷积核,3个3x3卷积核来代替7x7卷积核,如果你会继续推下去,就是5个3x3卷积核可以代替11x11卷积,这样我们就减少了参数,而且加深了我们的神经网络的深度,并在一定程度上提升了神经网络的效果。
VGG优点
VGGNet的结构非常简洁,整个网络都使用了同样大小的卷积核尺寸(3x3)和最大池化尺寸(2x2)。
几个小滤波器(3x3)卷积层的组合比一个大滤波器(5x5或7x7)卷积层好:
验证了通过不断加深网络结构可以提升性能。
在这个过程中,我得到了一些数据,当我
CIFAR-10图像分类
VGG缺点
VGG耗费更多计算资源,并且使用了更多的参数(这里不是3x3卷积的锅),导致更多的内存占用(140M)。其中绝大多数的参数都是来自于第一个全连接层。VGG可是有3个全连接层啊!
有的文章称:发现这些全连接层即使被去除,对于性能也没有什么影响,这样就显著降低了参数数量。(并且在后面的实验中,我去掉了几个全连接层,确实还是得到了比较好的结果,等等看看实验结果吧)
ILSVRC竞赛详细介绍
在实现VGG的实验结果前,我想先介绍一下这个ILSVRC比赛
**ILSVRC(ImageNet Large Scale Visual Recognition Challenge)**是近年来机器视觉领域最受追捧也是最具权威的学术竞赛之一,代表了图像领域的最高水平。
ImageNet数据集是ILSVRC竞赛使用的是数据集,由斯坦福大学李飞飞教授主导,包含了超过1400万张全尺寸的有标记图片。ILSVRC比赛会每年从ImageNet数据集中抽出部分样本,以2012年为例,比赛的训练集包含1281167张图片,验证集包含50000张图片,测试集为100000张图片。
ILSVRC从2010年开始举办,到2017年是最后一届(在算法层面已经刷过拟合了,再比下去意义不是很大了)。ILSVRC-2012的数据集被用在2012-2014年的挑战赛中(VGG论文中提到)。ILSVRC-2010是唯一提供了test set的一年。
ImageNet可能是指整个数据集(15 million),也可能指比赛用的那个子集(1000类,大约每类1000张),也可能指ILSVRC这个比赛。需要根据语境自行判断。
12-15年期间在ImageNet比赛上提出了一些经典网络,比如AlexNet,ZFNet,OverFeat,VGG,Inception,ResNet。
16年之后也有一些经典网络,比如WideResNet,FractalNet,DenseNet,ResNeXt,DPN,SENet。
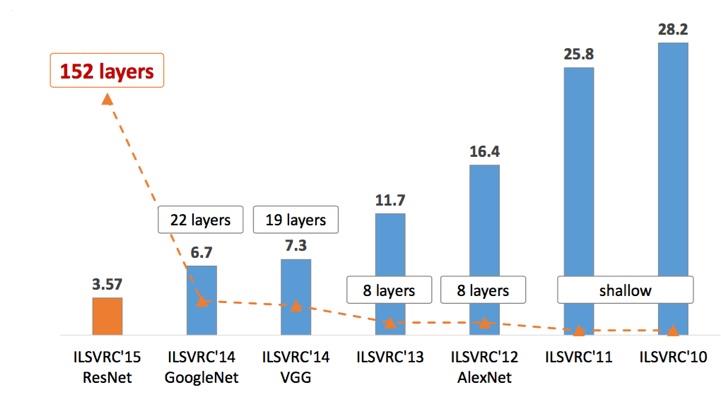
- LeNet[1998]:CNN的鼻祖。
- AlexNet[2012]:第一个深度CNN。
- ZFNet[2012]:通过DeconvNet可视化CNN学习到的特征。
- VGG[2014]:重复堆叠3x3卷积增加网络深度。(2014 亚军)
- GoogLeNet[2014]:提出Inception模块,在控制参数和计算量的前提下,增加网络的深度与宽度。(2014 冠军)
- ResNet[2015]:提出残差网络,解决了深层网络的优化问题。
- ResNeXt[2016]:ResNet和Inception的结合体,Inception中每个分支结构相同,无需人为设计。(2016 亚军)
- SENet[2017]:提出SE block,关注特征的通道关系。(2017 冠军)
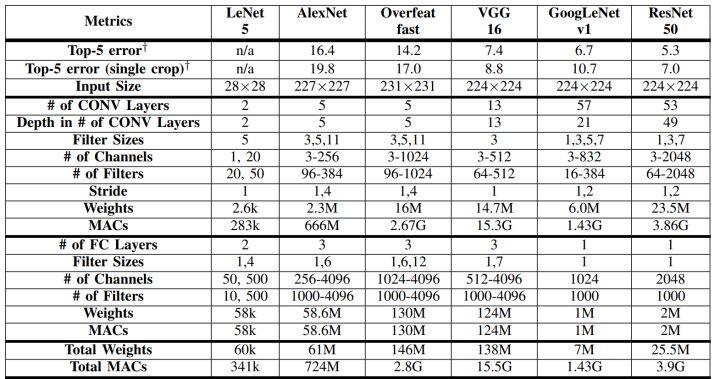
经典模型中结构、参数对比
CIFAR10 Classfication
CIFAR10是kaggle计算机视觉竞赛的一个图像分类项目。该数据集共有60000张32*32彩色图像,一共分为"plane", “car”, “bird”,“cat”, “deer”, “dog”, “frog”,“horse”,“ship”, “truck” 10类,每类6000张图。有50000张用于训练,构成了5个训练批,每一批10000张图;10000张用于测试,单独构成一批。
数据集可以去官网下,可以直接下载(选择对应工具的版本)

VGG的探索和实现CIFAR10分类
数据集的下载和预处理
我们可以和前面一样,进行手动下载数据集,然后利用 pickle 库可以提取我们的文件里面的数据,然后得到我们的数据集
也可以用我们的torchvision,一些经典的数据集,如Imagenet, CIFAR10, MNIST都可以通过torchvision来获取,并且torchvision还提供了transforms类可以用来正规化处理数据。
(1)数据集
数据集可分为训练集、验证集和训练集,训练集用于训练,验证集用于验证训练期间的模型,测试集用于测试最终模型的表现。这是基本的理解。验证集可用来设计一些交叉验证方法,在数据量较少的情况下能够提高模型的鲁棒性,通常任务分为训练集和测试集即可。
(2)数据预处理。
常用数据预处理方法可概述为2类,数据标准化处理和数据增广。
最常用的数据标准化处理就是数据的归一化,原数据可能数据量很大,维数很,计算机处理起来时间复杂度很高,预处理可以降低数据维度。同时,把数据都规范到0到1,这样使得它们对模型的影响具有同样的尺度。
这里我们会用我们的transform来实现
加载数据集
# 加载数据集
class CIFAR10Data(object):
def __init__(self, train_split=0.9):
train_transform = transforms.Compose([ # 可以串联多个transform函数
transforms.RandomCrop(size=(32, 32), padding=4),# 随机裁剪图片,即移动
transforms.RandomHorizontalFlip(), # 随机翻转图片
transforms.ToTensor(),
transforms.Normalize(mean=[0.4914, 0.4822, 0.4465],std=[0.2471, 0.2435, 0.2616])
])
val_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.4914, 0.4822, 0.4465],std=[0.2471, 0.2435, 0.2616])
])
test_transform = val_transform
# download the CIFAR10 by torchvision, trainset is a torchvision.datasets object
# transform is performed while obtaining the dataset
# the ./datas directory is automatically created, and once dowloaded, this code can sense it and will not
# download it again
# 简单来说,就是可以在我们的data目录下下载我妈的数据,如果我设置download为True就会自动下载,反之,已经有了可以修改
train_dataset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=train_transform)
val_dataset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=val_transform)
test_dataset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=test_transform)
# 取得我们的训练集 验证集 测试集
num_train = len(train_dataset)
indices = list(range(num_train))
split = int(num_train * train_split)
train_idx, val_idx = indices[:split], indices[split:]
self.train_dataset = torch.utils.data.Subset(train_dataset, train_idx)
self.val_dataset = torch.utils.data.Subset(val_dataset, val_idx)
self.test_dataset = test_dataset
# 利用内置的torch.utils.data.DataLoader从数据集中取出相应batch_size的数据
# 并且,shuffle = True的意思就是会打乱数据集 ,num_works 就是多线程
def get_train_loader(self, batch_size=128):
train_loader = torch.utils.data.DataLoader(
self.train_dataset, batch_size=batch_size,
num_workers=2, shuffle=True
)
return train_loader
def get_val_loader(self, batch_size=128):
val_loader = torch.utils.data.DataLoader(
self.val_dataset, batch_size=batch_size,
num_workers=2, shuffle=False
)
return val_loader
def get_test_loader(self, batch_size=128):
test_loader = torch.utils.data.DataLoader(
self.test_dataset, batch_size=batch_size,
num_workers=2, shuffle=False
)
return test_loader
Image displaying
# Image displaying
import matplotlib.pyplot as plt
import numpy as np
def imshow(img):
# normalizing
img = img / 2 + 0.5 # imgs are already noramlized during Transforming in data prepration
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
# plt.show()
image_iter = iter(train_loader)
images, labels = image_iter.next()
imshow(torchvision.utils.make_grid(images[:4]))

我们可以可视化其中的图片,就可以看到数据集的图片,我们可以看出来,有些图片被翻转了,有些图片被随机裁剪了,这都是我们的transform造成的,如果你不希望得到这样的结果,可以进行调整。

VGG的构造
根据我们论文的介绍和VGG16的参考,我们可以很快得到我们VGG模型
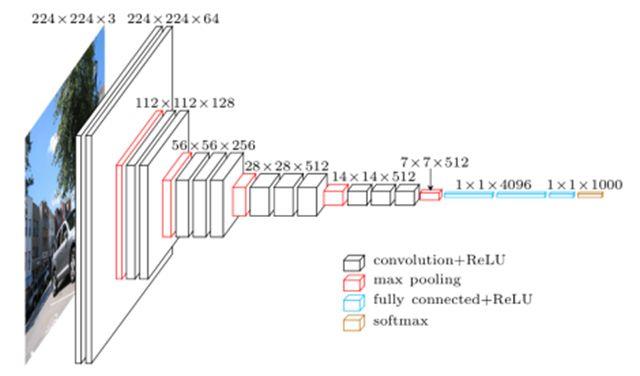
我们会发现,我们的数据集的图片是32x32x3的图片,所以这里面有一些通道是和224x224x3图片是不一样,我们需要调整,比如在后面全连接层,我们是512的输出通道,最后是10个类,所以我们不能照搬参考图片,对适当的输入输出进行调整,不过都是小事,很简单就可以成功了。
class VGG(nn.Module):
def __init__(self, vgg_name):
super(VGG, self).__init__()
self.features = self._make_layers(cfg[vgg_name])
self.classifier = nn.Sequential(
nn.Linear(512,512),
nn.ReLU(True),
nn.Dropout(0.2),
nn.Linear(512,512),
nn.ReLU(True),
nn.Dropout(0.2),
nn.Linear(512,10),
)
# self.classifier = nn.Linear(512,10)
self._initialize_weight()
def forward(self, x):
out = self.features(x)
# 在进入
out = out.view(out.size(0), -1)
out = self.classifier(out)
return out
# make layers
def _make_layers(self, cfg):
layers = []
in_channels = 3 # RGB 初始通道为3
for x in cfg:
if x == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)] # kernel_size 为 2 x 2,然后步长为2
else:
layers += [nn.Conv2d(in_channels, x, kernel_size=3, padding=1), # 都是(3.3)的卷积核
nn.BatchNorm2d(x),
nn.ReLU(inplace=True)] # RelU
in_channels = x # 重定义通道
# layers += [nn.AvgPool2d(kernel_size=1, stride=1)]
return nn.Sequential(*layers)
# 初始化参数
def _initialize_weight(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
# xavier is used in VGG's paper
nn.init.xavier_normal_(m.weight.data)
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
m.weight.data.normal_(0, 0.01)
m.bias.data.zero_()
代码就是那么简单的,就是定义模型,然后初始化参数,我们就可以得到我们的VGG模型了,并且我们这个代码不只是VGG16的,他可以根据你传入类的参数得到我们的VGG模型,既然搞定了我们的VGG模型,接下来我们就测试一下,这个模型是否正确吧
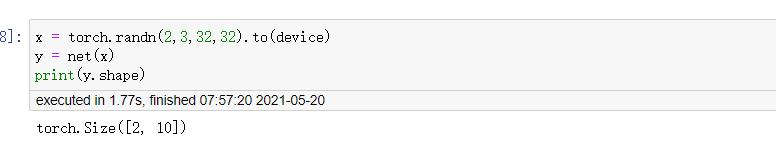
看起来还是正确的,我随机一个输入,输出确实是我们想要的,所以我们的程序构建就完成了。
接下来就是我们的训练了。
要求
分别使用数据集中训练集的1%、10%、50%、80%样本进行训练模型,使用测试样本进行测试,简述步骤并对比使用不同比例的训练样本对于训练结果的影响(即模型训练完成后,使用测试样本输入模型得到的准确率)。随着数据量的增大,观察每一次模型迭代(模型每完成一次迭代,即所有训练样本输入到模型中进行训练更新)所需的计算时间、内存消耗变化,并做比较。
由于这是我们老师的要求,我就先根据老师的要求去做先
train_split == 0.01 (取训练集的1%)- Acc:36%
训练及测试模型
我们还取出几张图片,上面四个是正确值,下面四个是预测值,我们可以看出来,准确率确实有点低

查看模型在每一个类的准确率

可视化误差曲线,准确率曲线,学习率曲线
在之后的每个模型中,我都会给出三个曲线,分别是
- 训练集的损失函数曲线和测试集的损失函数曲线
- 训练集的准确率函数曲线和测试集的准确率函数曲线
- 学习率曲线的变化
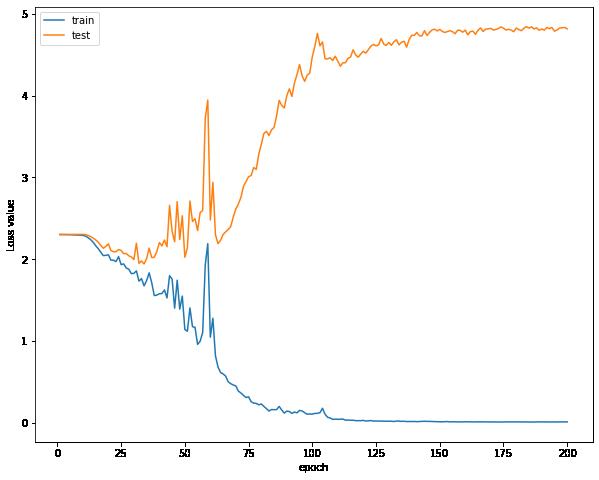
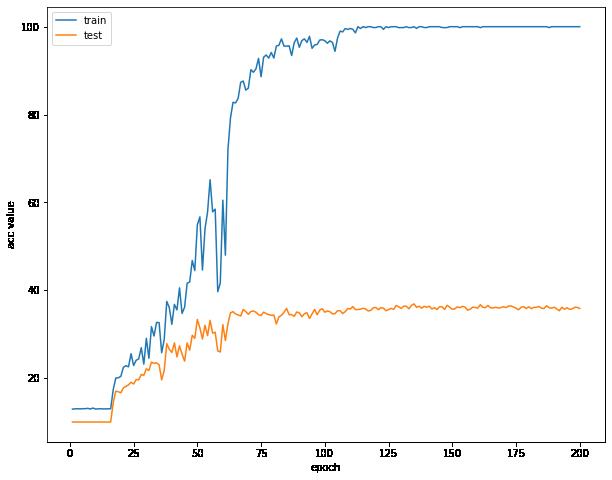
我发现在我训练集比较小的时候,误差曲线的趋势并不是同步的,训练的时候模型会注重于训练集的误差,尽量减小训练集的误差,但是训练集的数据太少了,会导致我们的测试集的误差不断增大
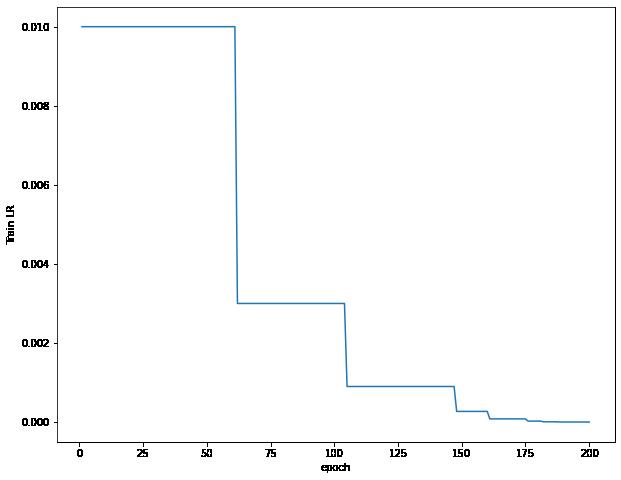
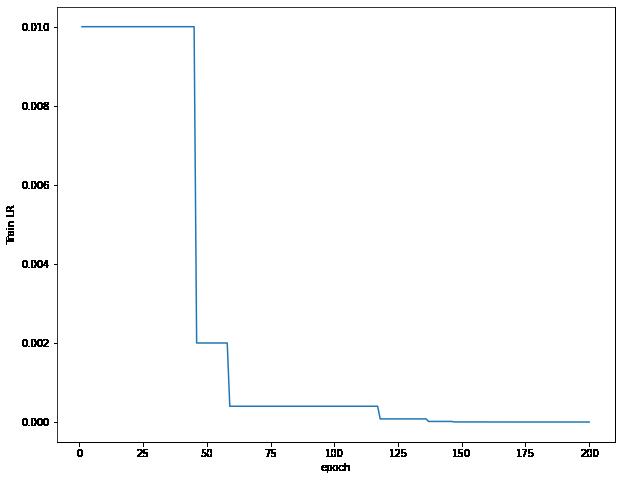
学习率不断下降
train_split == 0.1(取训练集的10%)- Acc:72%
训练及测试模型
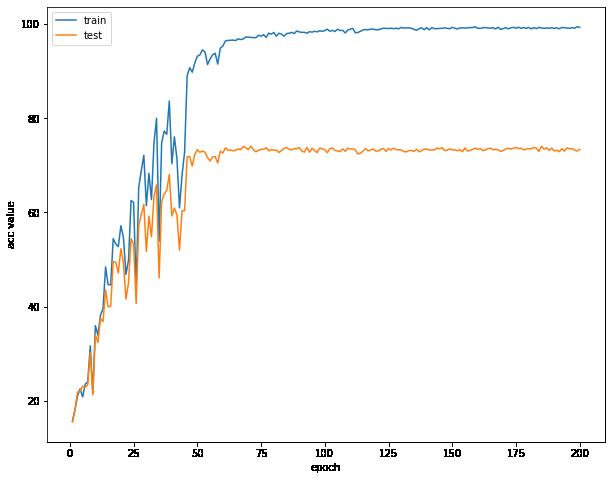
我们会发现,我们的准确率提高了几乎两倍左右,现在我们的准确率大概是72%了

查看模型在每一个类的准确率
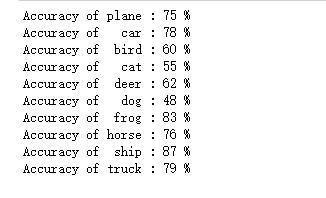
可视化误差曲线,准确率曲线,学习率曲线
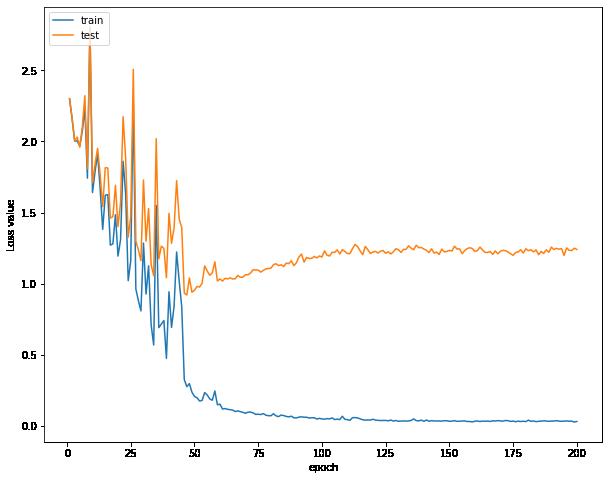
这个时候开始,我们的训练集和测试集的误差逐渐同步了
train_split == 0.5(取训练集的50%)- Acc:88%
训练及测试模型
这时候我们的准确率可以达到88%

查看模型在每一个类的准确率

可视化误差曲线,准确率曲线,学习率曲线
train_split == 0.8(取训练集的80%)- Acc:91.2%
训练及测试模型

我们可以看到我们的准确率可以到达91.13%的地步,已经是很不错的

查看模型在每一个类的准确率

可视化误差曲线,准确率曲线,学习率曲线
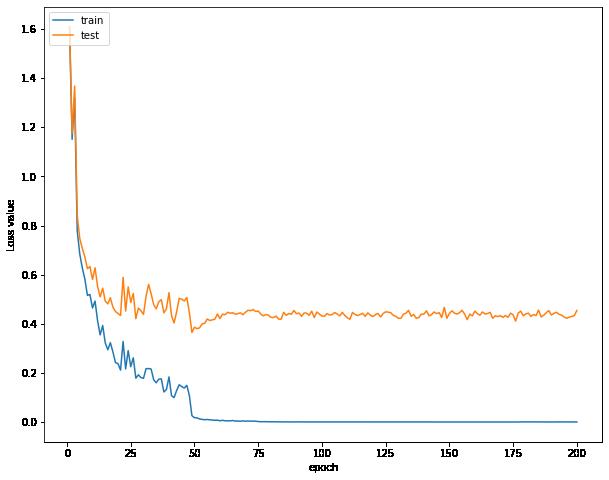
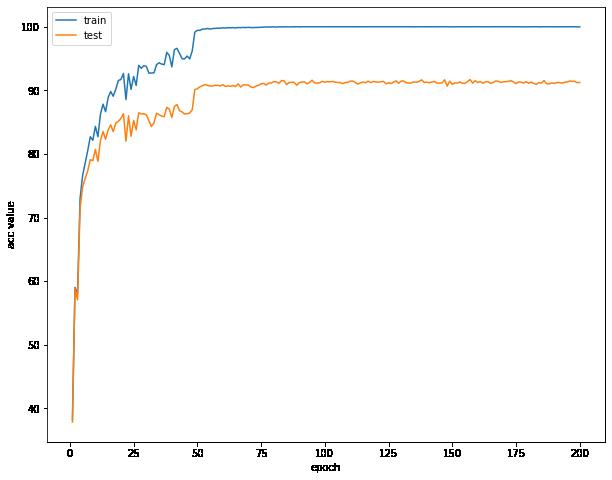
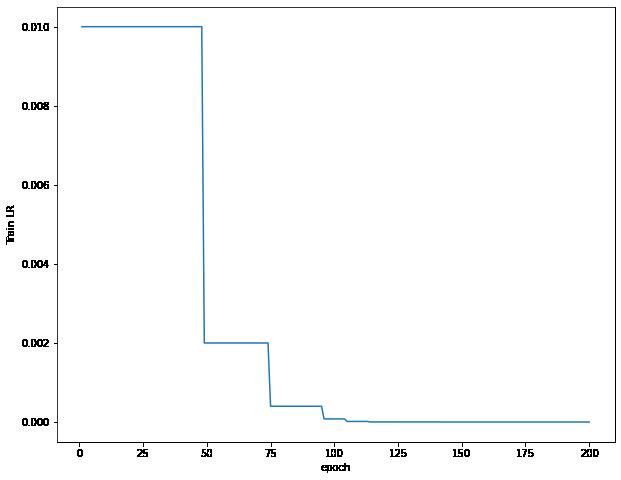
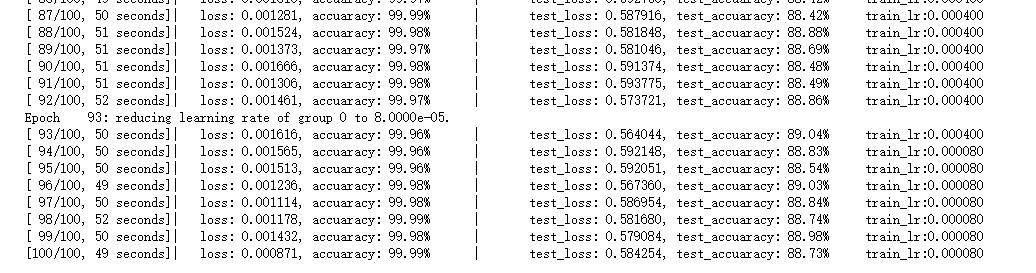
VGG探索与惊人发现 -Acc: 92.58 %
虽然我达到了91.2的准确率,但是我感觉还是比较少,我就专门去调参,查资料,看论文,是否有更好的方法去将我们的结果更加提高。
废话不多说,上结果
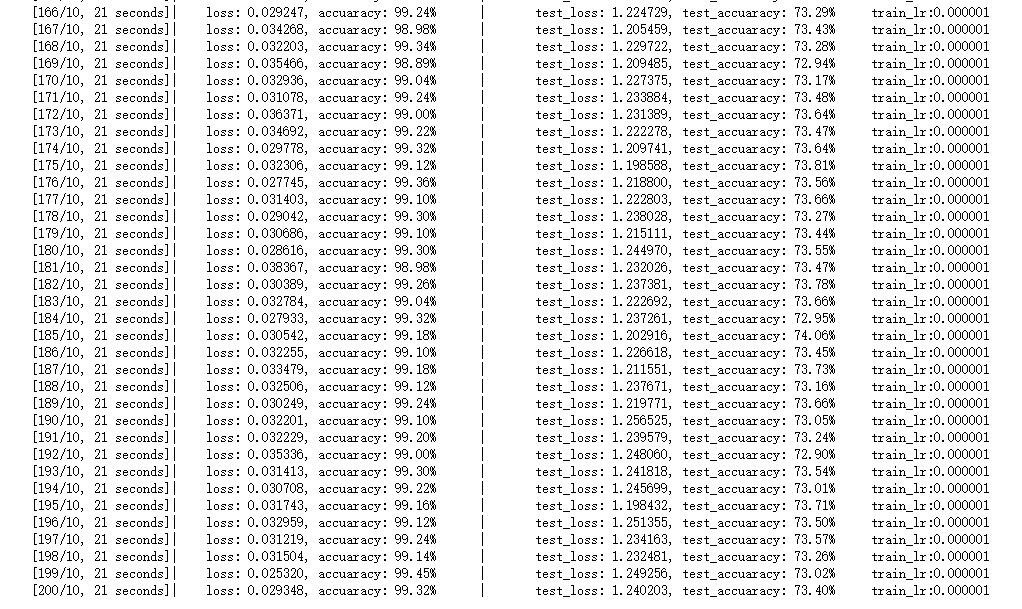
训练及测试模型
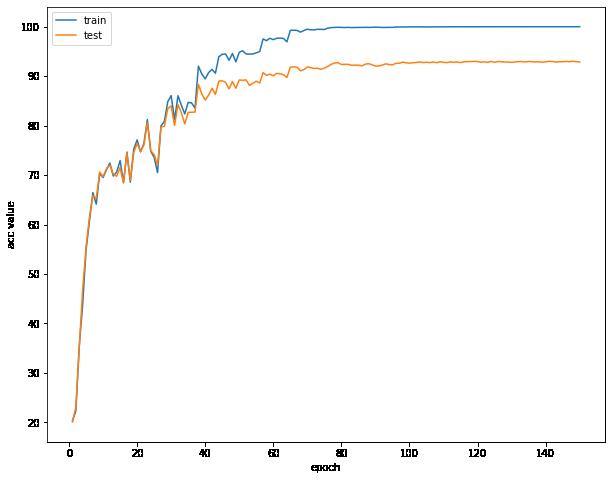
在后面迭代过程中,我们的模型对验证集偶尔能上93的准确率,令人欣慰
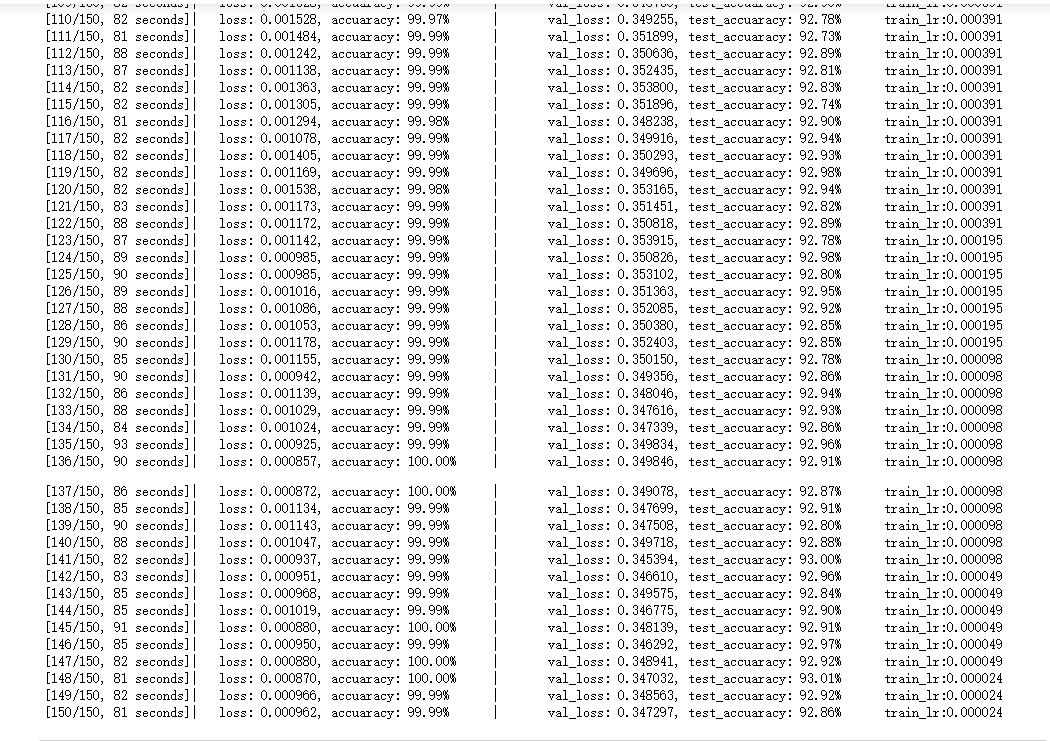
这时候我们的模型达到了惊人的92.58%的准确率,超级开心(NICE!!!)

查看模型在每一个类的准确率
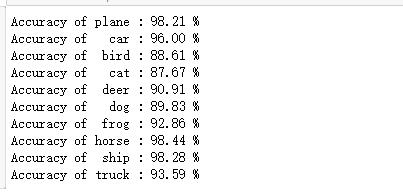
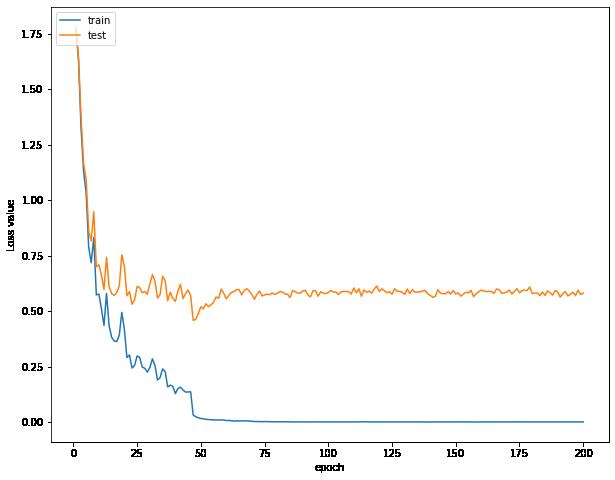
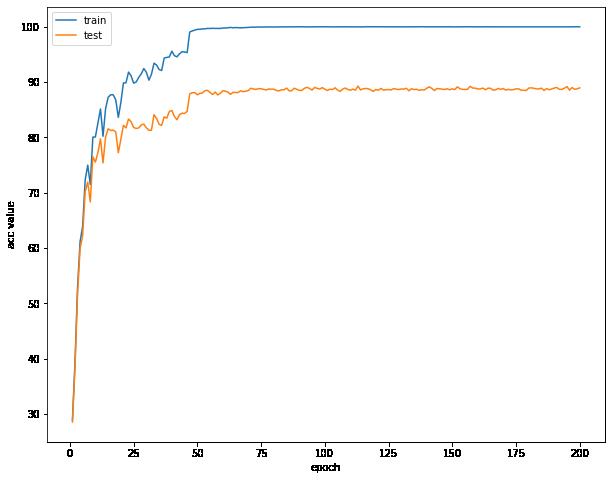
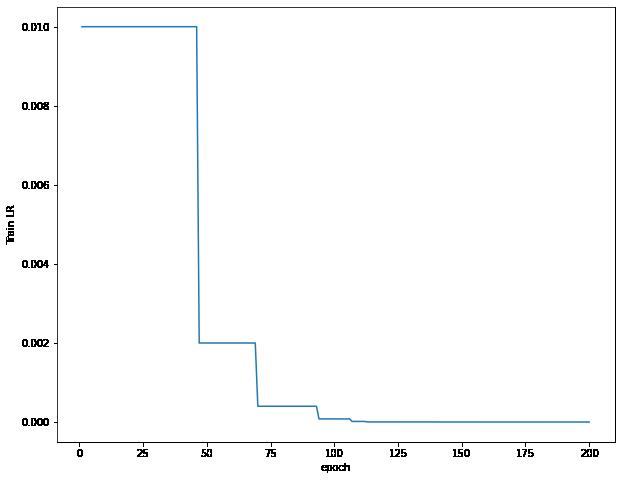
可视化误差曲线,准确率曲线,学习率曲线
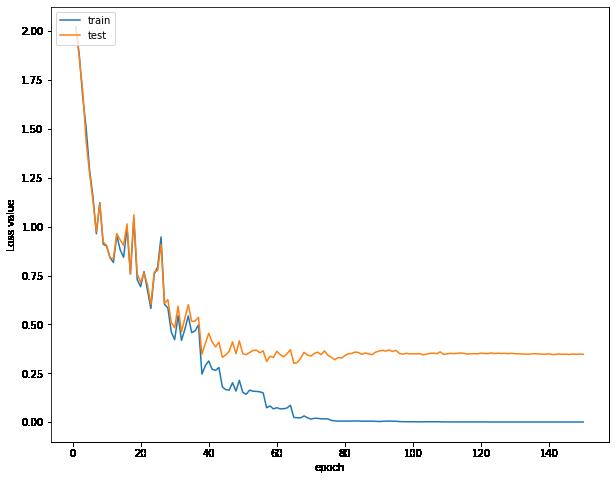
误差曲线不断下降到达一个瓶颈上下波动
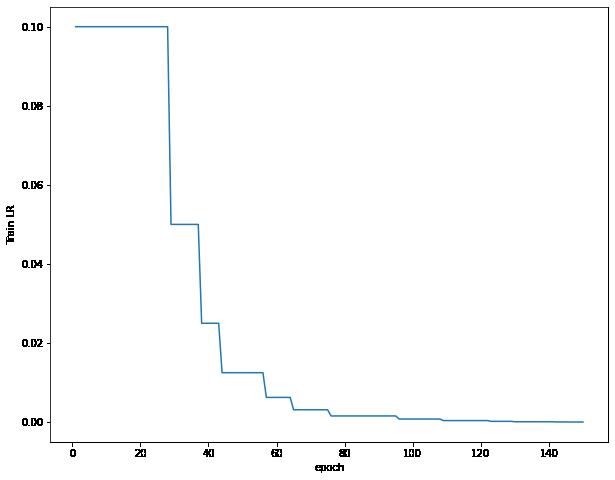
可以看出来,我们的学习率变化的极为陡峭
参数调整和中间算法介绍
这样一突破,有人一定好奇,到底是什么参数可以达到这样的效果。
首先整个过程中,我都是用了SGD,随机梯度下降,在前面的训练中,我们的
初始学习率都是lr = 1e-3,momentum = 0.9,weight_decay = 5e-4
然后有很多种的学习率调整的方法,可以根据我们step来调整,并且可以设计调整率。
具体的pytorch学习率的调整方法可以去看PyTorch学习之六个学习率调整策略,然后根据自己的模型去调整。
除此之外,我们的optimization方法除了SGD还有很多方法,比如Adam方法(我比较少试),不过如果想得到更好的结果可以去试一下,不过这些优化方法一般是减少我们的训练次数,能更快的得到最优的结果,理论上,训练次数长是没什么问题的。
总结
在这个过程中,虽然遇到了很多困难,自学很多不懂的东西,包括tensorflow,keras我也全部接触了一遍,搭载GPU,不断的调参数,冒着电脑爆炸的风险跑神经网络,到现在把这篇博客完完整整的写出来。
从小白到现在,这个过程不久,可能就几天吧,所以大家一起努力也是可以的,只要你相信自己,没有什么困难是不能客服的,路很长,也很遥远,一起努力!
以上是关于VGG 系列的探索与pytorch实现 (CIFAR10 分类问题) - Acc: 92.58 % (一文可通VGG + pytorch)的主要内容,如果未能解决你的问题,请参考以下文章