Android 进阶之探索 OkHttp 原理
Posted 涂程
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Android 进阶之探索 OkHttp 原理相关的知识,希望对你有一定的参考价值。
前言
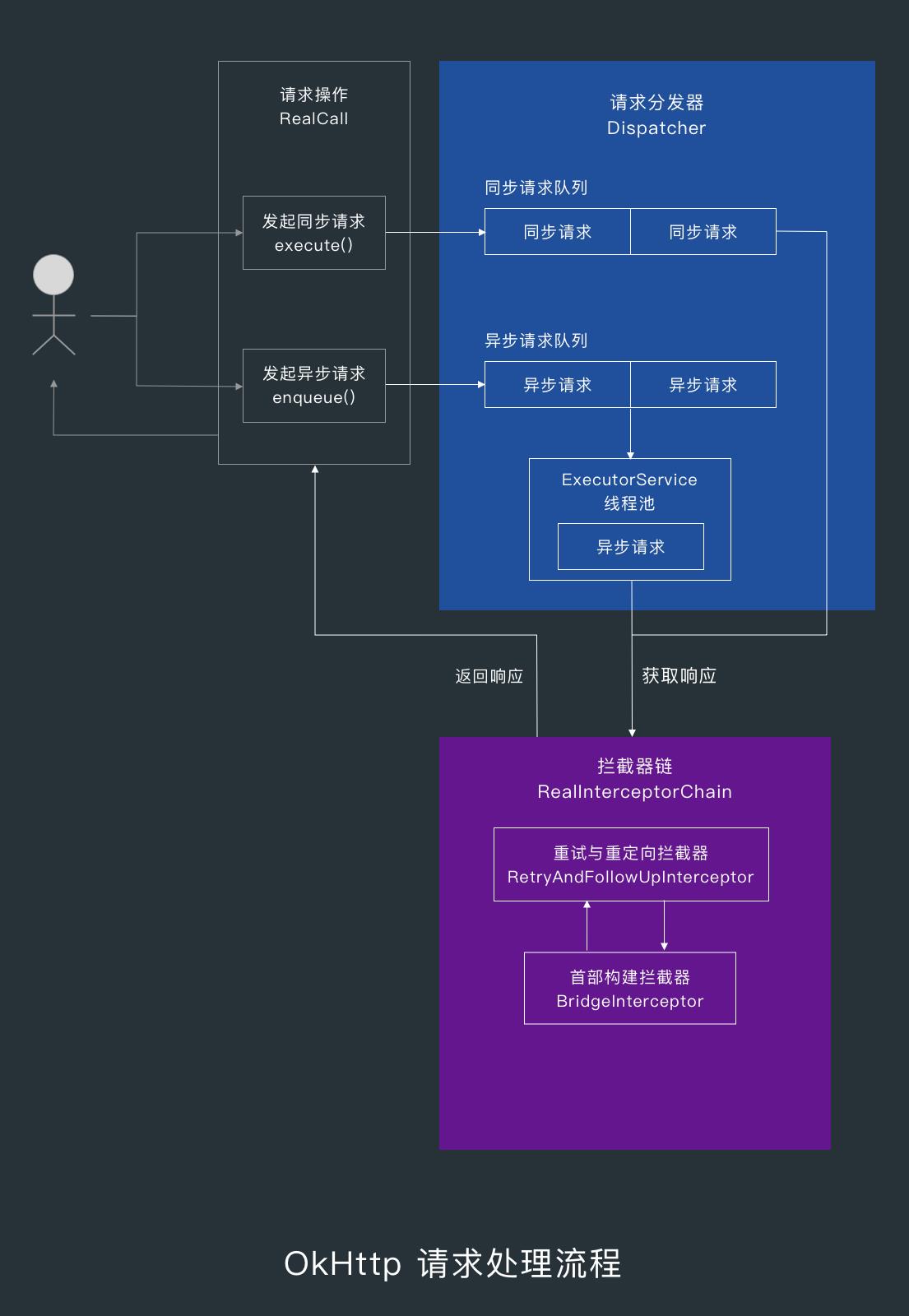
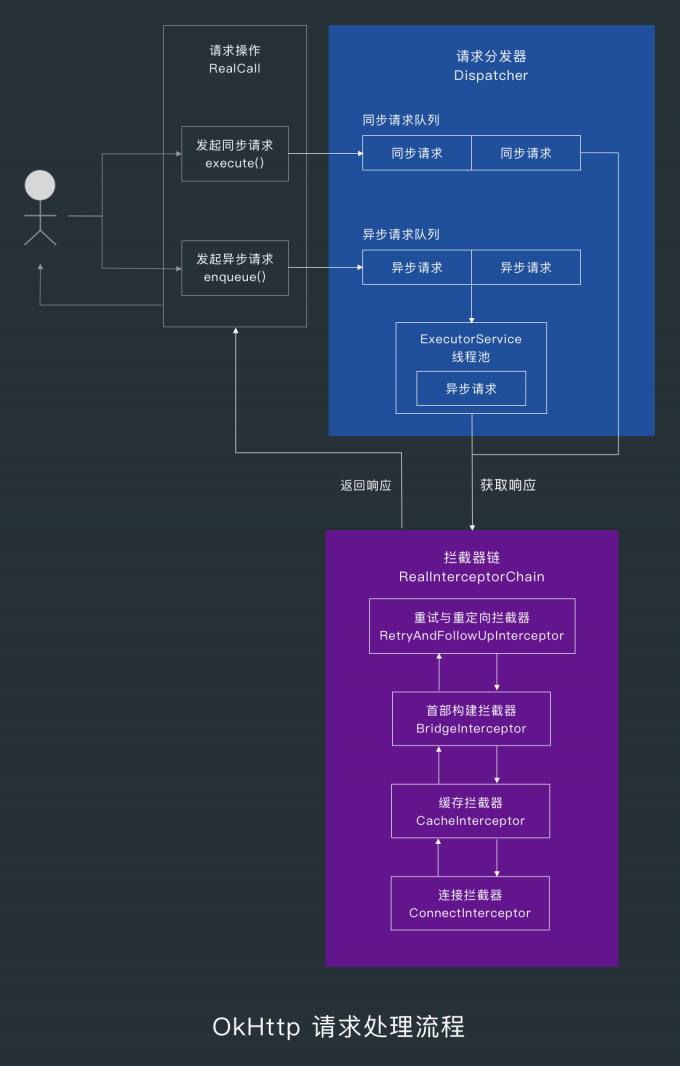
1. OkHttp 请求处理流程概述
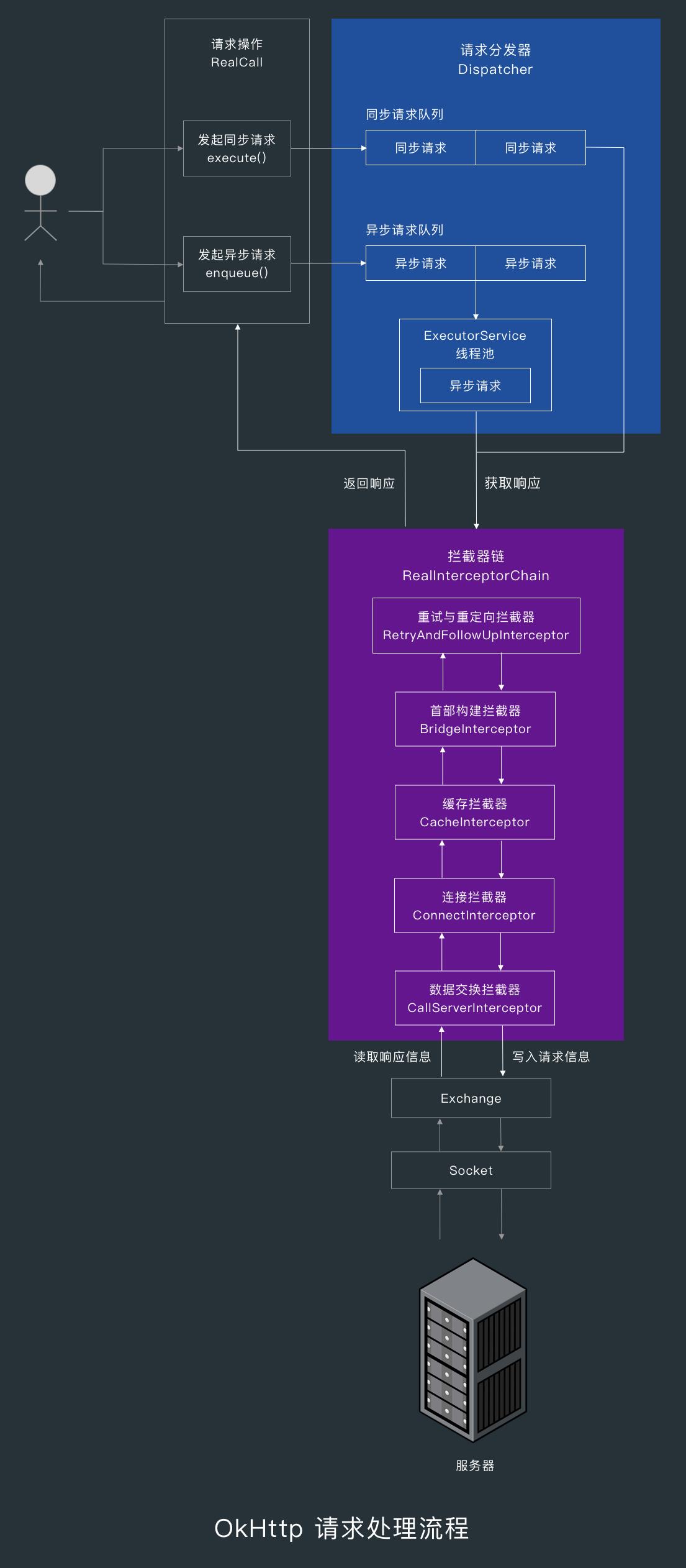
当我们发起同步请求时,请求会被 Dispatcher 放到同步请求队列中,然后直接执行请求。
当我们发起异步请求时,Dispatcher 会把请求放到异步请求队列,然后在合适的时机把异步请求提交到线程池中执行。
请求的执行由拦截器链负责,处理的顺序为:重试与重定向拦截器—首部构建拦截器—缓存拦截器—连接拦截器—数据交换拦截器。
当数据交换拦截器 CallServerInterceptor 接收到请求时,会通过数据交换器 Exchange 写入请求信息,而 Exchange 会通过 Socket 提供的的输出流写入请求信息,通过输入流读取响应信息。
当 CallServerInterceptor 读取完了响应信息后,就会往上传递,直到把响应信息返回给最开始发起请求的地方。
2. OkHttp 基本用法
接下来将基于 OkHttp 4.9.0 进行讲解,演示代码是用 Kotlin 写的。
1. 添加依赖
2. 发起请求

3. 内容概览
1. 请求信息 Request
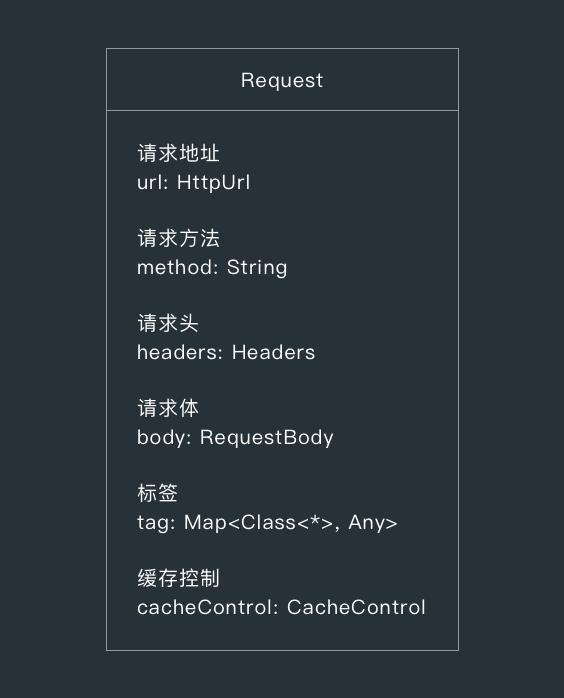
Request 包含了请求相关信息,比如请求方法和请求地址和请求头等信息。
1.1.1 统一资源定位器 HttpUrl
Request 会把我们传入 url() 函数中的请求地址转化为 HttpUrl 对象。
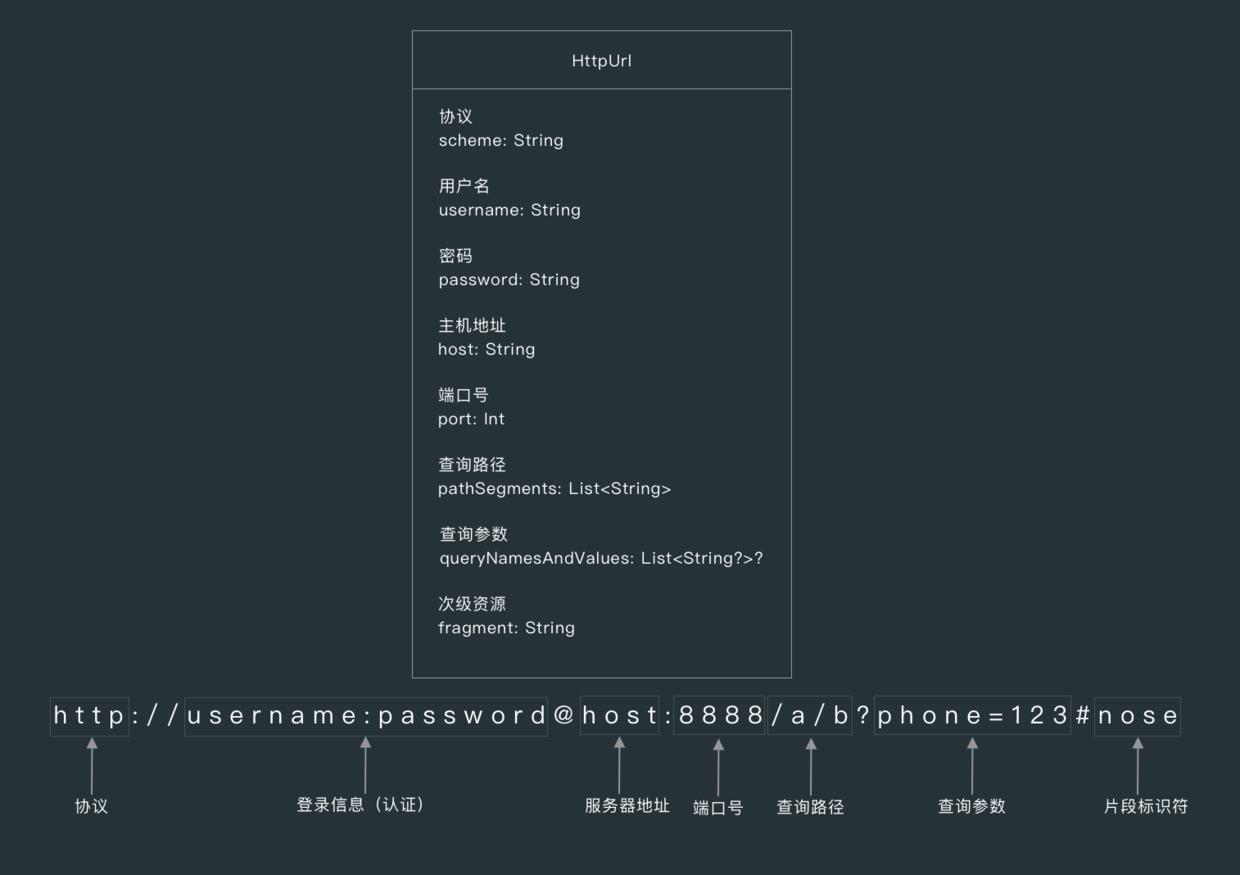
1. 协议
使用 http: 或 https 等协议方案名获取访问资源时,要指定协议类型,不区分字母大小写,最后加一个冒号( : )。
2. 登录信息(认证)
指定用户名和密码作为从服务端获取资源时必要的登录信息(身份认证),这是可选项。
3. 主机
主机组件标识了因特网上能够访问资源的宿主机器,比如 www.xxx.com 或 192.168.1.66 。
4. 端口号
端口组件标识了服务器正在监听的网络端口,对下层使用了 TCP 协议的 HTTP 来说,默认端口为 80 。
5. 查询路径
服务器上资源的本地名,由斜杠( / )将其与前面的 URL 组件分隔开来,路径组件的语法与服务器的方案有关。
的路径组件说明了资源位于服务器的什么地方,类似于分级的文件系统路径,比如 /goods/details 。
6. 查询参数
比如数据库服务是可以通过提供查询参数缩小请求资源范围的,传入页码和页大小查询列表 http://www.xxx.com/?page=1&pageNum=20 。
7. 片段
片段(fragment)表示一部分资源的名字,该字段不会发送给服务器,是在客户端内部使用的,通过井号(#)将其与 URL 其余部分分割开来。·
1.1.2 首部字段 Headers
Header 用于存放 HTTP 首部,Headers 中只有一个字段,就是 namesAndValues ,类型为 Array ,比如 addHeader(a, 1) 对应的 namesAndValues 为 [a, 1]。
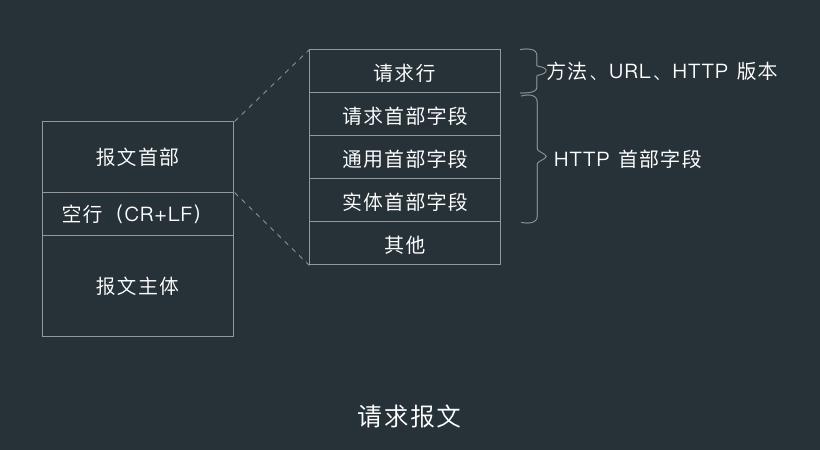
HTTP 协议的请求和响应报文中必定包含 HTTP 首部,首部内容为客户端和服务器分别处理请求和响应提供所需要的信息,下面是 HTTP 请求报文和 HTTP 响应报文中包含的首部字段。
在请求中,HTTP 报文由方法、URI、HTTP 版本、HTTP 首部字段等部分构成。
1.1.3 请求体 RequestBody
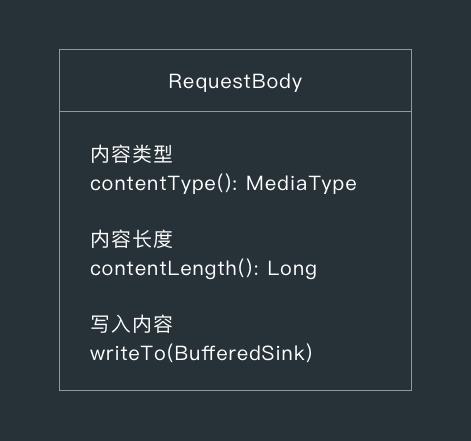
RequestBody 是一个抽象类,有下面 3 个方法。
- 内容类型 contentType()
比如 application/x-www-form-urlencoded ;
- 内容长度 contentLength()
- 写入内容 writeTo()
把请求的内容写入到 okio 提供的 Sink 中;
RequestBody 中还有 4 个用于创建 RequestBody 的扩展方法 xxx.toRequestBody() ,比如 Map.toString().toRequestBody()。
1.1.4 标签
我们可以用 tag() 方法给请求加上标签,然后在拦截器中根据不同的标签栏做不同的操作。
val request = Request.Builder()
.url(...)
.tag("666")
.build()
在 Retrofit 中用的则是 @Tag 注解,比如下面这样。
@POST("app/login")
suspend fun login(
@Query("account") phone: String,
@Query("password") password: String,
@Tag tag: String
) : BaseResponse<User>
然后在拦截器中,就能根据 tag 的类型来获取 tag。
override fun intercept(chain: Interceptor.Chain): Response {
val request = chain.request()
val tag = request.tag(String::class.java)
Log.e("intercept", "tag: ${tag}")
return chain.proceed(request)
}
2. OkHttp 请求分发机制
2.1 请求操作 Call

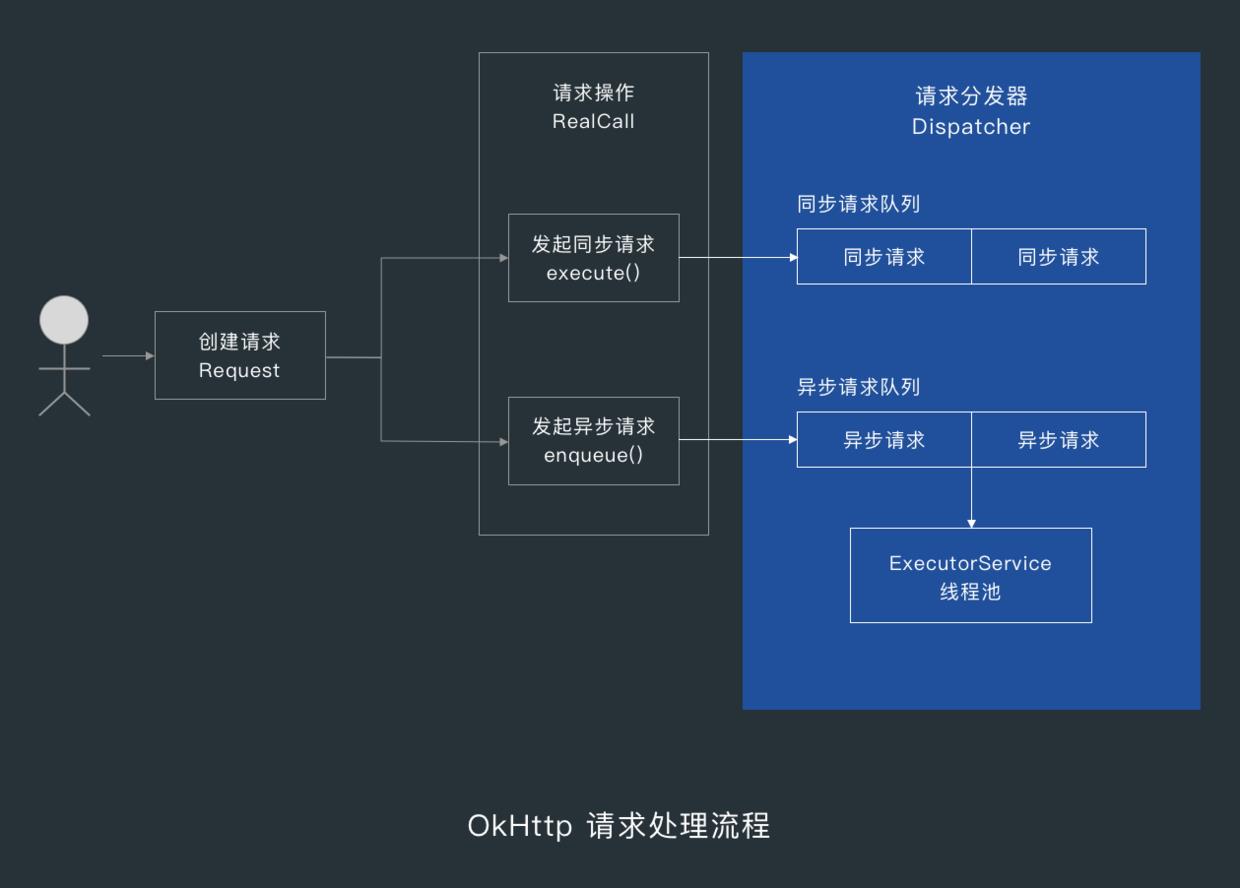
在我们创建请求 Request 后,我们要用 OkHttpClient.newCall() 创建一个 RealCall 对象,然后调用 execute() 发起同步请求或调用 enqueue() 发起异步请求。
RealCall 实现了 Call 接口,也是这个接口唯一的实现类,按注释来说,RealCall 是一个 OkHttp 应用与网络层之间的桥梁,该类暴露了高级应用层的原语(primitives):连接、请求、响应与流。
你也可以把 RealCall 理解为同步请求操作,而 RealCall 的内部类 AsyncCall 则是异步请求操作。
下面我们来看下 RealCall 中比较中要的两个方法的实现:execute() 与 enqueue() 。
1. 发起同步请求 execute()
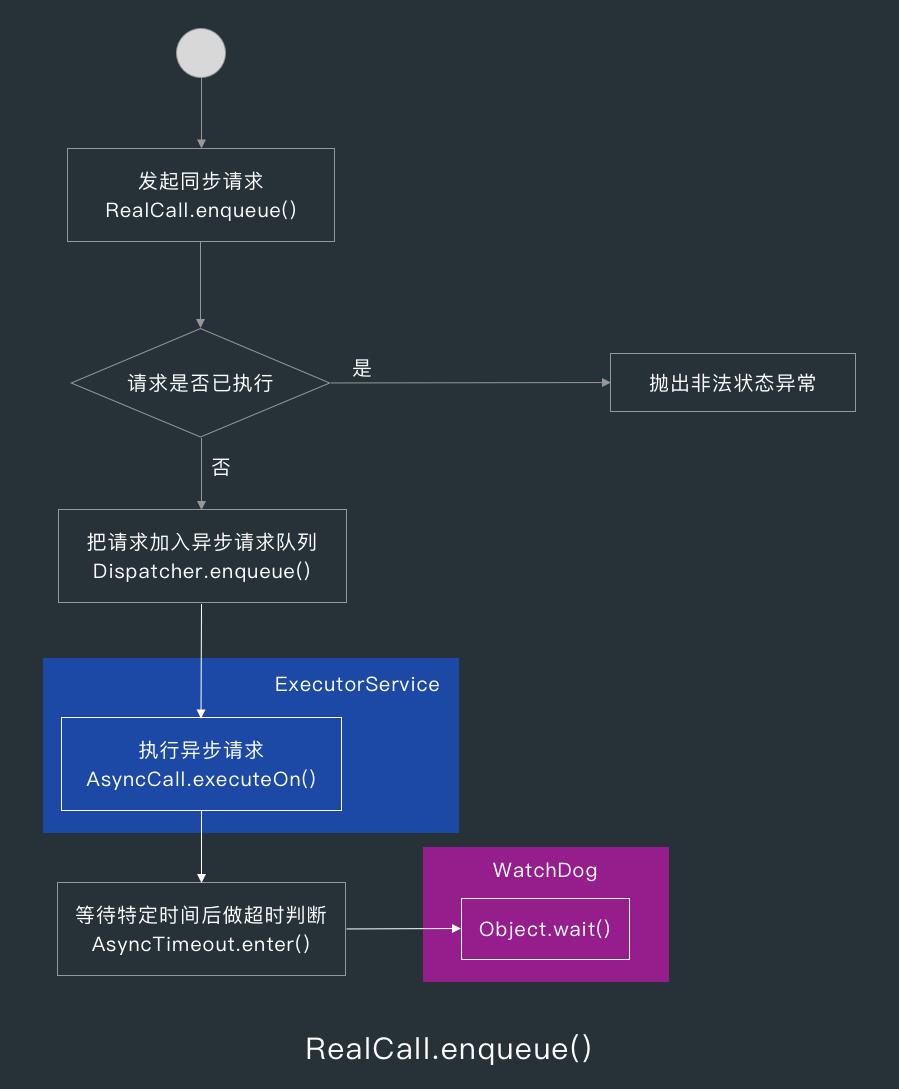
当我们调用 RealCall.execute() 发起同步请求时,如果该请求已执行,那么会抛出非法状态异常,所以我们在发起同步请求时要注意捕获异常。
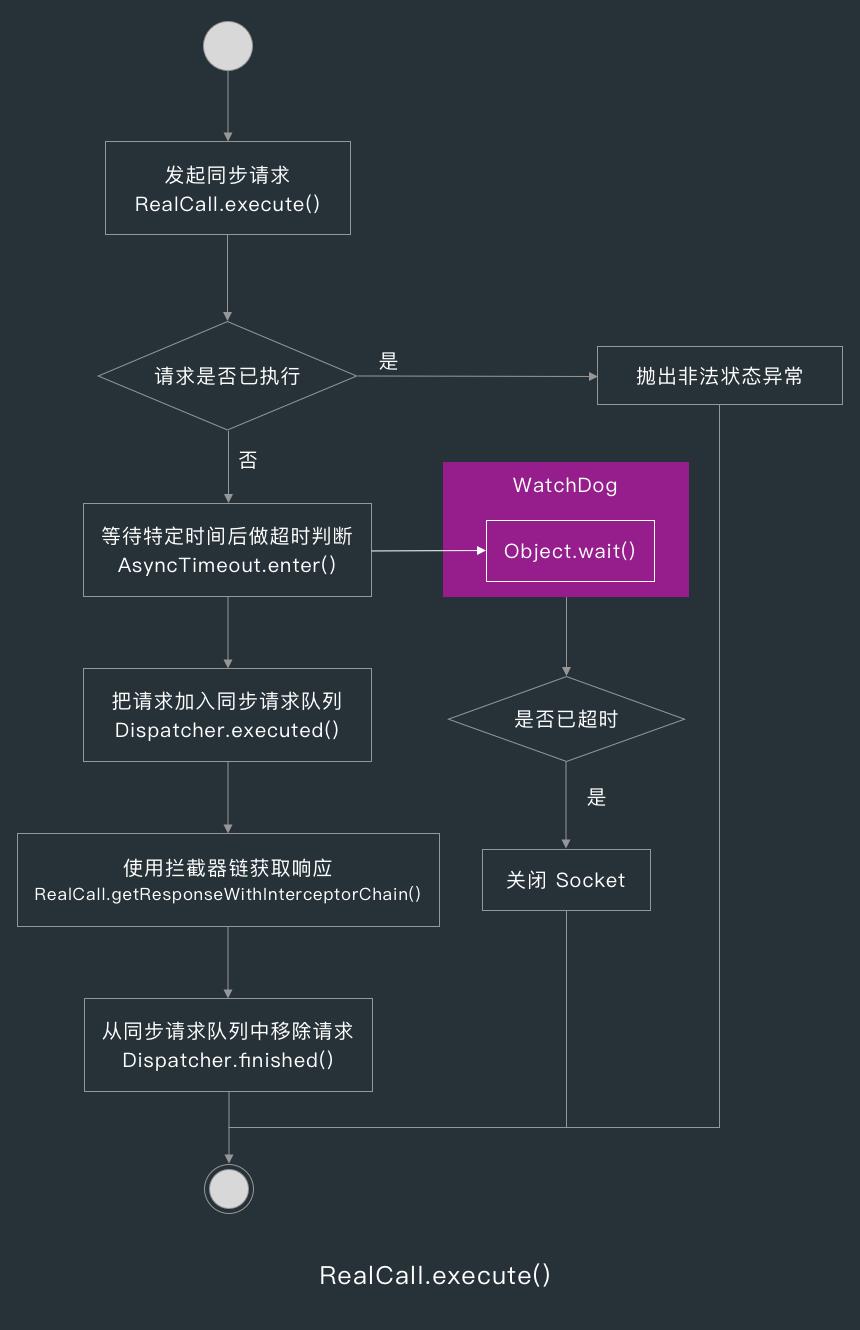
如果请求没有被执行的话,execute() 方法则会调用 AsyncTimeout 的 enter() 方法让 AsyncTimeout 做请求超时判断,AsyncTimeout 中有一个继承了 Thread 的内部类 WatchDog,而 AsyncTimeout 会用 Object.wait/notify() 阻塞和唤醒 Watchdog 线程。
当请求超时时,AsyncTimeout 会调用 RealCall 中实现的 timeOut() 方法关闭连接,关于 AsyncTimeout 的实现后面会进一步讲解。
RealCall 的 execute() 方法调用完 enter() 方法后,会调用 Dispatcher 的 executed() 把请求加入同步请求队列,然后调用 getResponseWithInterceptorChain() 方法获取响应,获取到响应后就会让 Dispatcher 把请求从同步请求队列中移除。
2. 发起异步请求 enqueue()
当该请求还没有被执行时,execute() 方法会创建一个异步请求操作 AsyncCall,并把它交给 Dispatcher 处理。
AsyncCall 实现了 Runnable 接口,Dispatcher 接收到 AsyncCall 后,会把 AsyncCall 添加到待执行异步请求队列 readyAsyncCalls 中,然后调用自己的 promoteAndExecute() 方法,关于 Dispatcher 的实现后面再讲。
把 AsyncCall 加入到异步请求队列后,Dispatcher 会看情况决定什么时候执行该异步请求,要执行的时候就会把请求任务提交到线程池 ExecutorService 中。
和同步请求一样,在 AsyncCall 的 run() 方法中做的第一件事情就是让 AsyncTimeout 进入超时判断逻辑,然后用拦截器链获取响应。
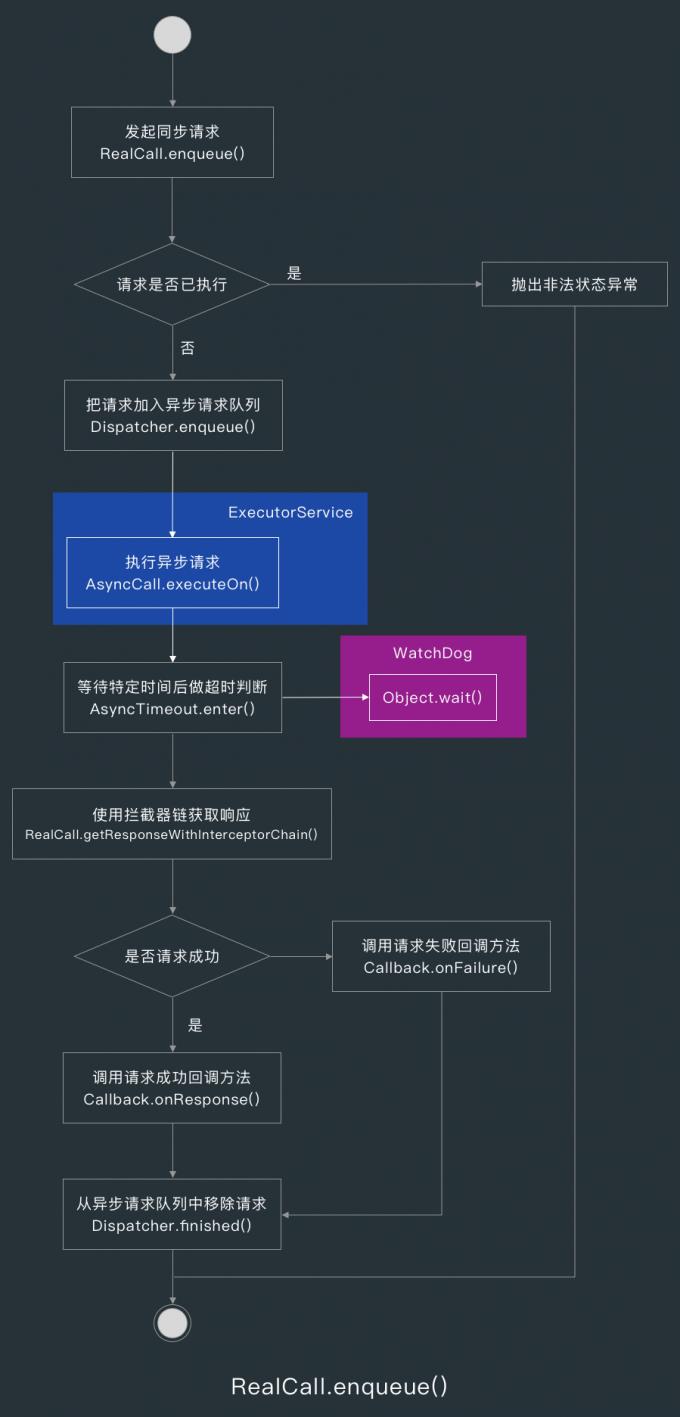
当请求的过程中没有遇到异常时,AsyncCall 的 run() 方法就会调用我们设定的 Callback 的 onResposne() 回调,如果遇到了异常,则会调用 onFailure() 方法。
不论异步请求是成功还是失败,RealCall 最后都会调用 Dispatcher 的 finished() 方法把请求从已运行异步请求队列 runningAsyncCalls 中移除。
2.2 请求分发器 Dispatcher
当我们调用了 RealCall 的 execute() 或 enqueue() 方法后,RealCall 会调用 Dispatcher 对应的 execute() 和 enqueue() 方法,请求分发器 Dispatcher 的 execute() 方法只是简单地把同步请求加入同步请求队列,下面我们来看下 Dipsatcher 中比较重要的 enqueue() 方法的实现。
Dispatcher 的 enqueue() 方法首先会把请求加入到待运行请求队列,然后重用 AsyncCall 的 callsPerHost 字段,callsPerHost 表示当前请求的主机地址的已执行请求数量。
在我们把某个异步请求加入队列时,Dispatcher 会从已运行异步请求队列和待运行异步请求队列中找出与该请求主机地址相同的请求,找到主机相同的请求的话,就重用该请求的 callsPerHost 字段,也就是是每执行一个该主机地址的请求时,这个值就会加 1 。
如果我们的应用中经常会发起多个请求,并且请求的主机地址不多时,我们可以修改 Dispatcher 中的 maxRequestsPerHost 的值,比如下面这样。
okHttpClient.dispatcher.maxRequestsPerHost = 10
这个值默认为 5 ,也就是单个主机地址在某一个时刻的并发请求只能是 5 个。
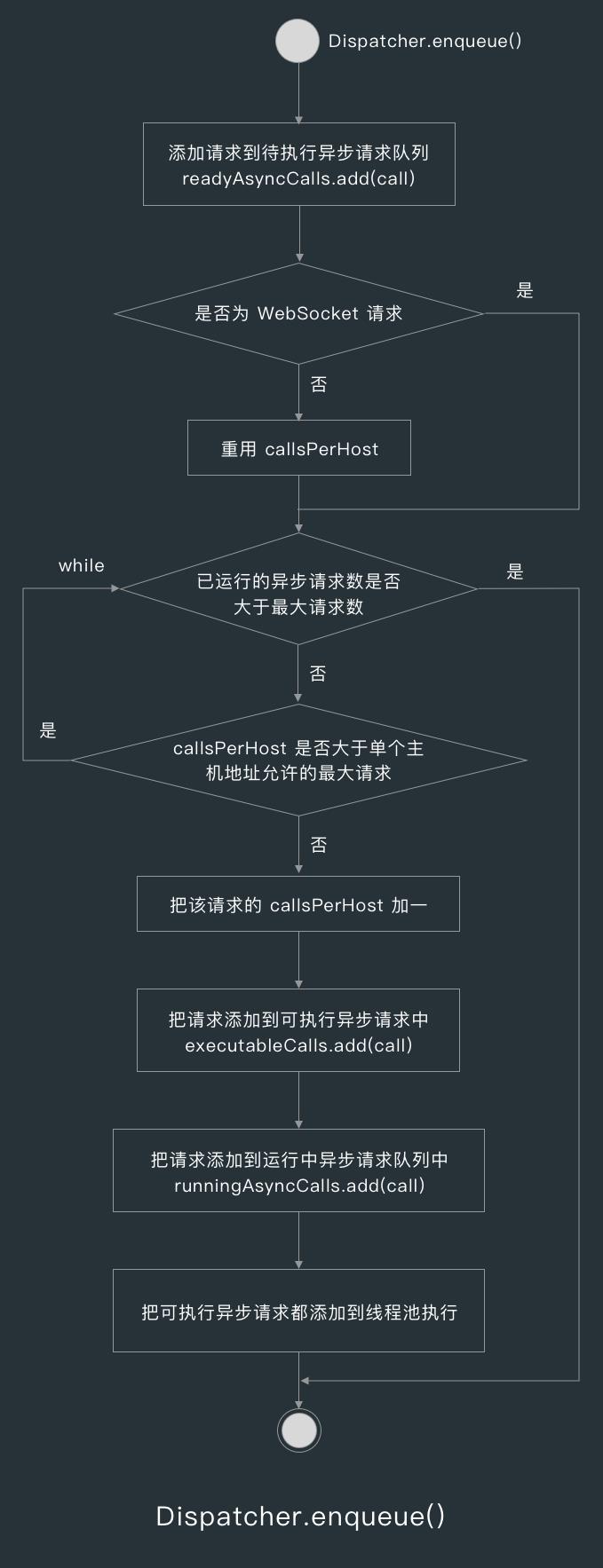
做完重用操作后,Dispatcher 就会创建一个可执行异步请求列表 executableCalls ,然后遍历待运行异步请求队列。
在遍历时,Dispatcher 会判断已运行的异步请求数量是否超出了允许的并发请求的最大值 maxRequests ,这个值默认为 64 ,也是可以被修改的。
当异步请求数量不超过最大值,并且对应主机地址的请求数量不超过最大值时,就会把该异步请求加入到 executableCalls ,然后把 executableCalls 中的请求都提交到线程池中执行。
2.3 拦截器链 RealInterceptorChain
当同步请求执行或异步请求被提交到线程池后执行时,RealCall 的 execute() 方法中就会调用getResponseWithInterceptorChain() 方法发起请求。
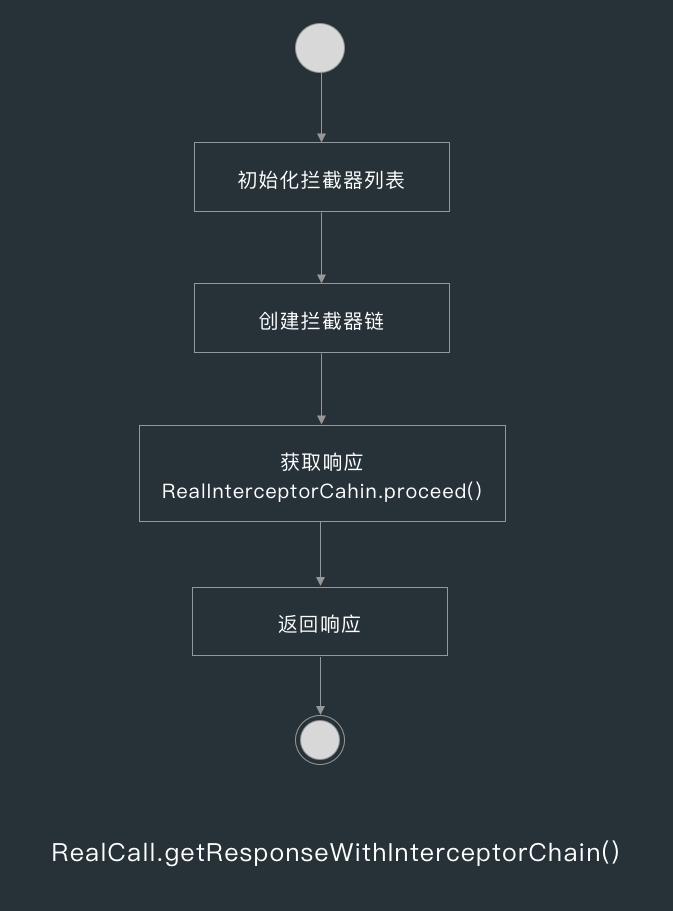
在 getResponseWithInterceptorChain() 方法中,首先会创建一个 interceptors 列表,然后按下面的顺序添加拦截器。
- 自定义拦截器
- 重试拦截器(RetryAndFollowUpInterceptor)
- 网络请求构建拦截器(BridgeInterceptor)
- 缓存拦截器(CacheInterceptor)
- 连接拦截器(ConnectInterceptor)
- 自定义网络拦截器(NetworkInterceptor)
- 数据传输拦截器(CallServerInterceptor)
添加完这些拦截器后,就会用 interceptors 创建一个拦截器链 RealInterceptorChain() ,然后调用拦截器链的 proceed() 方法,最后返回响应。
3. OkHttp 重试机制
当 RealCall 的 getResponseWithInterceptor() 方法被调用后,拦截器链就会先调用我们自定义的拦截器,然后再调用重试拦截器。

重试与重定向拦截器 RetryAndFollowUpInterceptor 负责在请求失败时重试和重定向,在重试拦截器的 intercept() 方法中的代码是放在 while 中执行的,只有当重试超过了一定次数或遇到异常时,执行才会被中断。
重试拦截器的 intercept() 方法首先会为请求操作 RealCall 初始化一个 ExchangeFinder,ExchangeFinder 是用来查找可重用的连接的,关于 ExchangeFinder 的实现后面会讲。
初始化 ExchangeFinder 后,intercept() 方法会通过拦截器链往下传递 Request 给其他拦截器处理,如果在这个过程中遇到了 IO 异常或路线异常,则会调用 rocover() 方法判断是否恢复请求,不恢复的话则抛出异常。
如果抛出的异常不是 IO 异常的话,那么 RealCall 就会调用 cancel() 方法关闭连接,下面来看下 recover() 方法的实现。
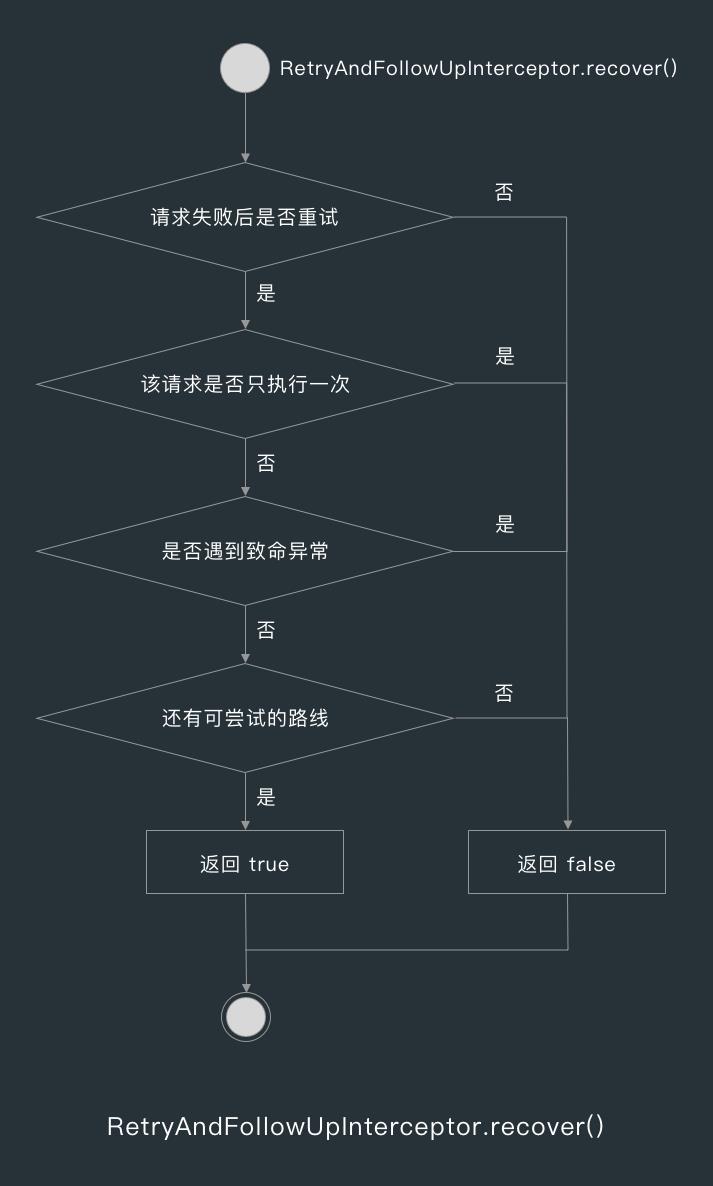
在 recover() 方法中,首先会判断 OkHttpClient 的 retryOnConnectionFailure 的值是否为 true,这个值表示是否所有请求都会要失败后重试,默认为 true ,如果我们不想取消掉所有请求都会失败重试的机制,可以在创建 OkHttpClient 时调用 retryOnConnectionFailure() 方法修改这个值。
如果 retryOnConnectionFailure 为 true,则判断当前请求是否只请求一次,这个对应的是 RequestBody 的 isOneShot() 方法,这个方法是可以重写的,也就是我们如果在调用 Post 方法创建 RequestBody 时,不想让这个请求在失败后重试,我们就可以重写 RequestBody 的 isOneShot() 方法,isOneShot() 的默认返回值为 false ,false 表示失败后重试。
如果 isOneShot() 为 false,那么 recover() 方法就会判断是否遇到了致命异常,如果是致命异常的话则不重试,这里的致命异常指的是下面这些异常。
- 协议异常 ProtocolException
- 证书异常 CertificateException
- SSL 对端验证失败异常 SSLPeerUnverifiedException
如果不是致命异常,则通过 RealCall 的 retryAfterFailure() 方法判断是否还有路线可以尝试,如果还有其他路线可尝试的话,则尝试其他路线。
4. OkHttp 重定向机制
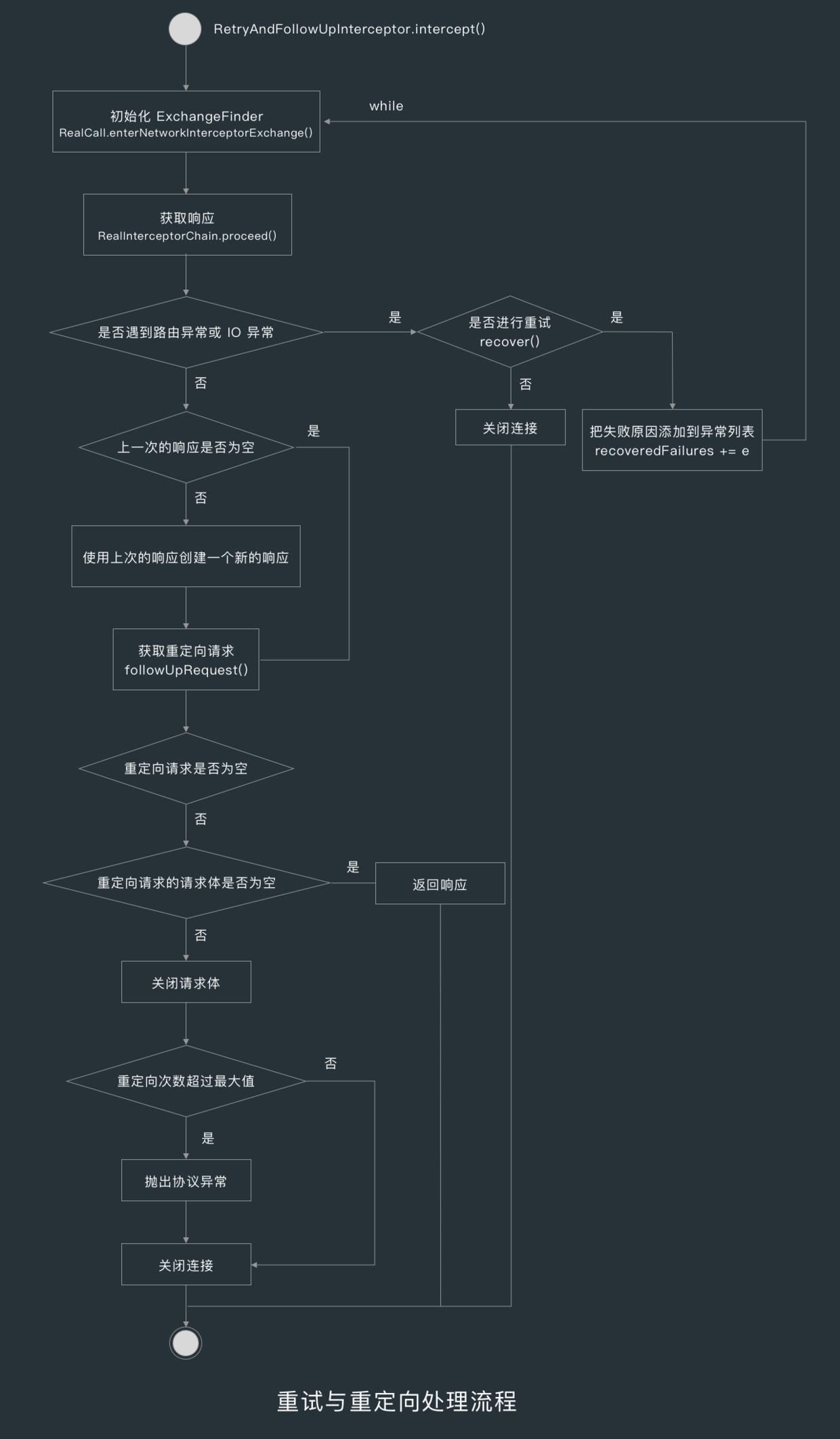
如果其他拦截器处理当前请求时没有抛出异常的话,那么 RetryAndFollowUpInterceptor 的 intercept() 方法就会判断上一个响应(priorResponse)是否为空,如果不为空的话,则用上一个响应的信息创建一个新的响应(Response),创建完新响应后,就会调用 followUpRequest() 方法 获取重定向请求。
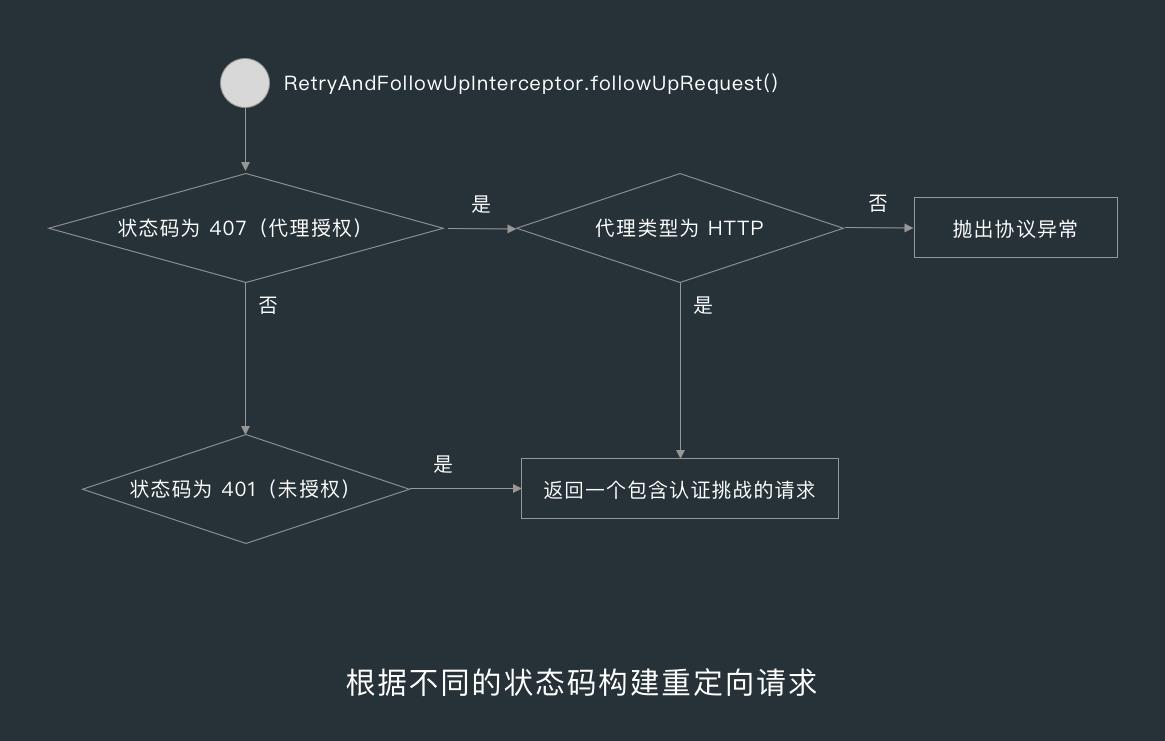
followUpRequest() 方法会根据不同的状态码构建重定向请求,状态码为 407 ,并且协议为 HTTP ,则返回一个包含认证挑战的请求,而获取这个请求用的是 Authenticator 。
Authenticator 有一个 authenticate() 方法,默认的是一个空实现 NONE,如果我们想替换的话,可以在创建 OkHttpClient 的时候调用 authenticator() 方法替换默认的空实现。
除了 NONE 以外,Authenticator 中还提供了另一个实现 JavaNetAutheitcator,对应的静态变量为 Authenticator.JAVA_NET_AUTHENTICATOR 。
在 JavaNetAuthenticator 的 authenticate() 方法中,会获取响应中的 Challenge(质询)列表,Challenge 列表就是对 WWW-Authenticate 和 Proxy-Authenticate 响应头解析后生成的。
4.1 基本认证
HTTP 通过一组可定制的控制首部,为不同的认证协议提供了一个可扩展框架,下面列出的首部格式和内容会随认证协议的不同而发生变化,认证协议也是在 HTTP 认证首部中指定的。
基本(BASIC)认证是 HTTP 定义的官方认证协议之一,基本认证相关的首部如下。
-
WWW-Authenticate
服务器上可以会分为不同的区域,每个区域都有自己的密码,所以服务器会在 WWW-Authenticate 首部对保护区域进行描述。
-
Authorization
客户端收到 401 状态码后,重新发出请求,这次会附加一个 Authorization 首部,用于说明认证算法以及用户名和密码;
-
Authentication-Info
如果授权书是正确的,服务器就会返回指定资源。有的授权算法会在可选的 Authentication-Info 首部返回一些与授权会话相关的附加信息;
4.2 处理 3XX 重定向状态码
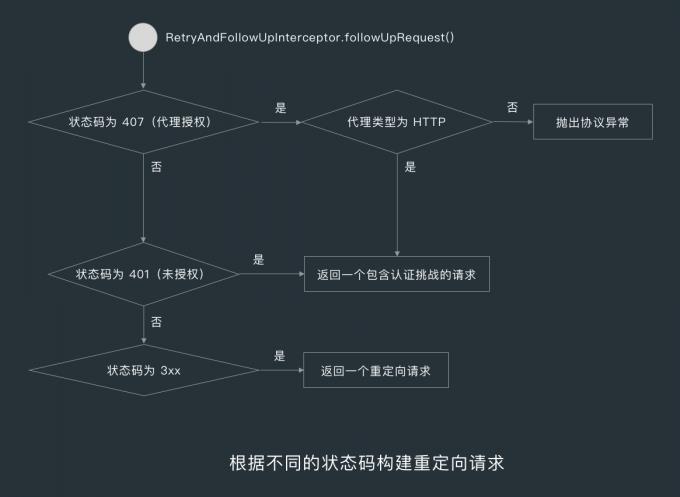
当响应的状态码为 300、301、302、303、307、308 时, followUpRequest() 方法就会调用 buildRedirectRequest() 构建重定向请求,3xx 重定向状态码要么告诉客户端使用替代位置访问客户端感兴趣的资源,要么提供一个替代的响应而不是资源的内容。
当资源被移动后,服务器可发送一个重定向状态码和一个可选的 Location 首部告诉客户端资源已被移走,以及现在哪里可以找到该资源,这样客户端就可以在不打扰使用者的情况在新的位置获取资源了。
4.3 处理 408、421 与 503 状态码
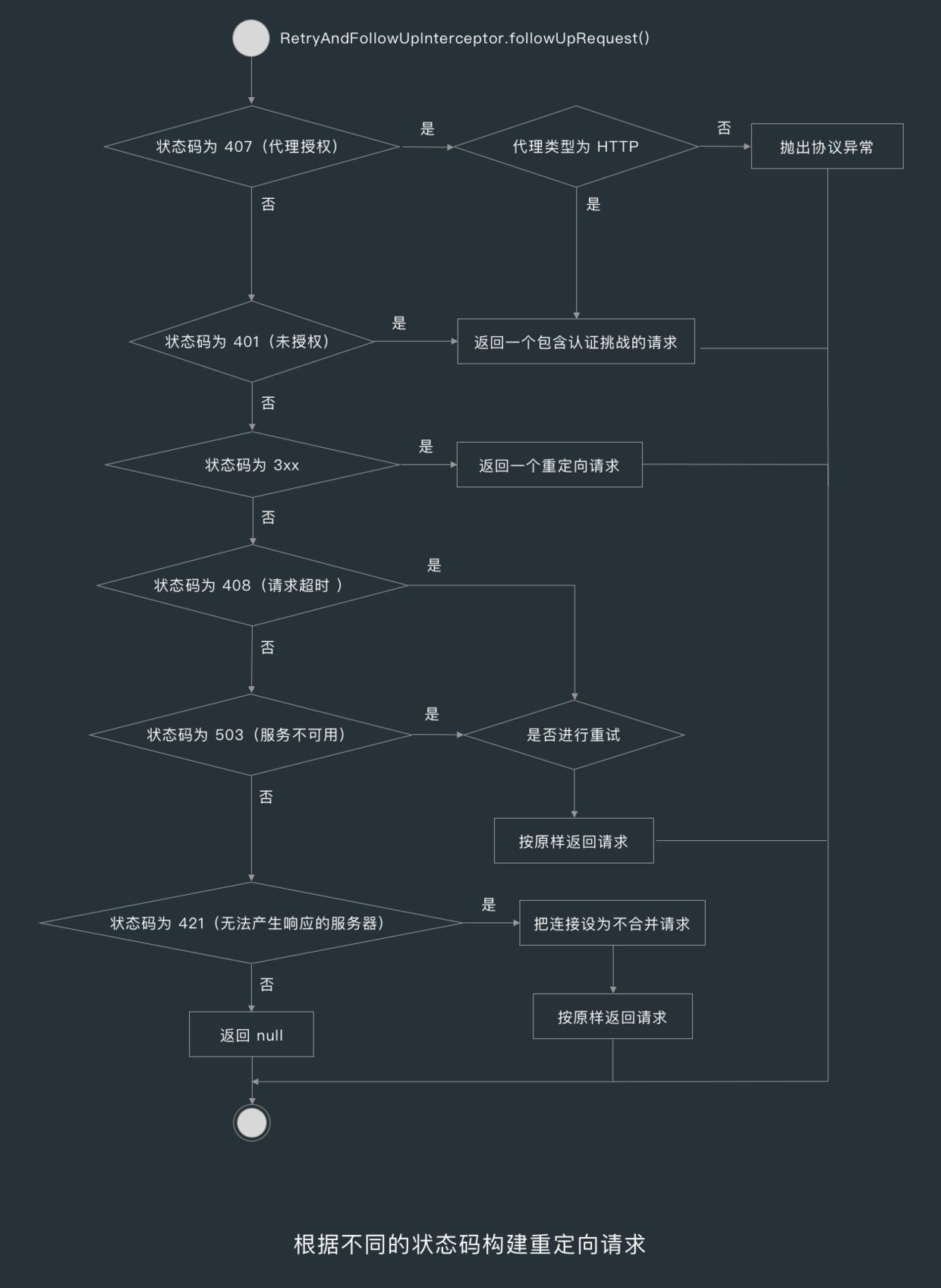
当状态码为 408(请求超时)时,followUpRequest() 方法就会判断是否进行重试,判断的依据也是 OkHttpClient 的 retryOnConnectionFailure 字段和 RequestBody.isOneShot() 方法。
当状态码为 503(服务不可用)时,followUpRequest() 方法就会判断上一次的响应是不是也是服务不可用,如果是的话则返回空。
当状态码为 42(无法产生响应)的服务器时,followUpRequest() 方法就会按原样返回请求。
5.OkHttp 首部构建机制
看完了 RetryAndFollowUpInterceptor 相关的重试与重定向机制,接下来看下网络请求构建拦截器 BridgetInterceptor。
重试与重定向拦截器只有在请求的过程中遇到异常或需要重定向的时候才有活干,在它收到请求后会把请求直接通过拦截器链交给下一个拦截器,也就是 BridgeInterceptor 处理。
之所以把 BridgeInterceptor 叫首部构建拦截器,是因为我们给 Request 设置的信息缺少了部分首部信息,这时就要 BridgeInterceptor 把缺失的首部放到 Request 中。
下面是 BridgeInterceptor 为请求添加的首部字段。
- Content-Type:实体主体的媒体类型
- Content-Length:实体主体的大小(字节)
- Transfer-Encoding:指定报文主体的传输方式
- Host:请求资源所在的服务器
- Connection:逐跳首部、连接的管理
- Accept-Encoding:优先的内容编码
- Cookie:本地缓存
- User-Agent:HTTP 客户端程序的信息
下面我们来看下这些首部的作用。
1. Content-Type:实体主体的媒体类型
Content-Type: text/html; charset-UTF-8
首部字段 Content-Type 说明了实体主体内对象的媒体类型,字段值用 type/subtype 形式赋值,比如 image/jpeg 。
2. Content-Length:实体主体的大小
首部字段 Content-Length 表明了实体主体部分的大小(单位是字节),对实体主体进行内容编码传输时,不能再使用 Content-Length 首部字段。
3. Transfer-Encoding:指定报文主体的传输方式
Transfer-Encoding: chunked
首部字段 Transfer-Encoding 规定了传输报文主体时采用的编码方式,HTTP/1.1 的传输编码方式仅对分块传输编码有效。
4. Host:请求资源所在的服务器
Host: www.xxx.com
首部字段 Host 告诉服务器请求的资源所处的互联网主机名和端口号,Host 首部字段在 HTTP/1.1 规范中是一个必须被包含在请求内的首部字段。
5. Connection
HTTP 允许在客户端和最终的源服务器之间存在一串 HTTP 的中间实体(代理、高速缓存等),可以从客户端开始,逐跳地将 HTTP 报文经过这些中间设备转发到源服务器上。
在某些情况下,两个相邻的 HTTP 应用程序会为它们共享的连接应用一组选项,而 Connection 首部字段中有一个由逗号分隔的链接标签列表,这些标签为此连接指定了一些不会被传播到其他连接中的选项,比如用 Connection:close 说明发送完下一条报文后必须关闭的连接。
Connection 首部可以承载 3 种不同类型的标签。
- HTTP 首部字段名,列出了只与此连接有关的首部;
- 任意标签值,用于描述此连接的非标准选项;
- close,说明操作完成后要关闭这条持久连接;
在 BridgeInterceptor 中,当我们没有设置 Connection 首部时,BridgeInterceptor 会传一个值为 Keep-Alive 的 Connection 首部用于开启持久连接,关于持久连接后面会讲到。
6. Cookie
两个与 Cookie 有关的首部字段。
- 响应首部字段 Set-Cookie:开始状态管理所使用的 Cookie 信息
- 请求首部字段 Cookie:服务器接收到的 Cookie 信息
Cookie: status=enable
首部字段 Cookie 会告诉服务器,当客户端想获得 HTTP 状态管理支持时,就会在请求中包含从服务器接收到的 Cookie,接收到多个 Cookie 时,同样可以以多个 Cookie 形式发送。
在 BridgeInterceptor 中,与 Cookie 相关的实现为 CookieJar 接口,默认是一个空实现类,如果我们想传 Cookie 给服务器端的话,可以在创建 OkHttpClient 时调用 cookieJar() 传入我们自己的实现。
7. User-Agent:HTTP 客户端程序的信息
首部字段 User-Agent 会将创建请求的浏览器和用户代理名称等信息传达给服务器,由网络爬虫发起请求时,有可能会在字段内添加爬虫作者的电子邮件地址,如果请求经过代理,中间也有可能被添加上代理服务器的名称。
在 BridgeInterceptor 中,当我们没有设置 User-Agent 时,默认的 UserAgent 为 okhttp:版本号,也就是User-Agent: okhttp:4.9.0。
6. OkHttp 缓存机制
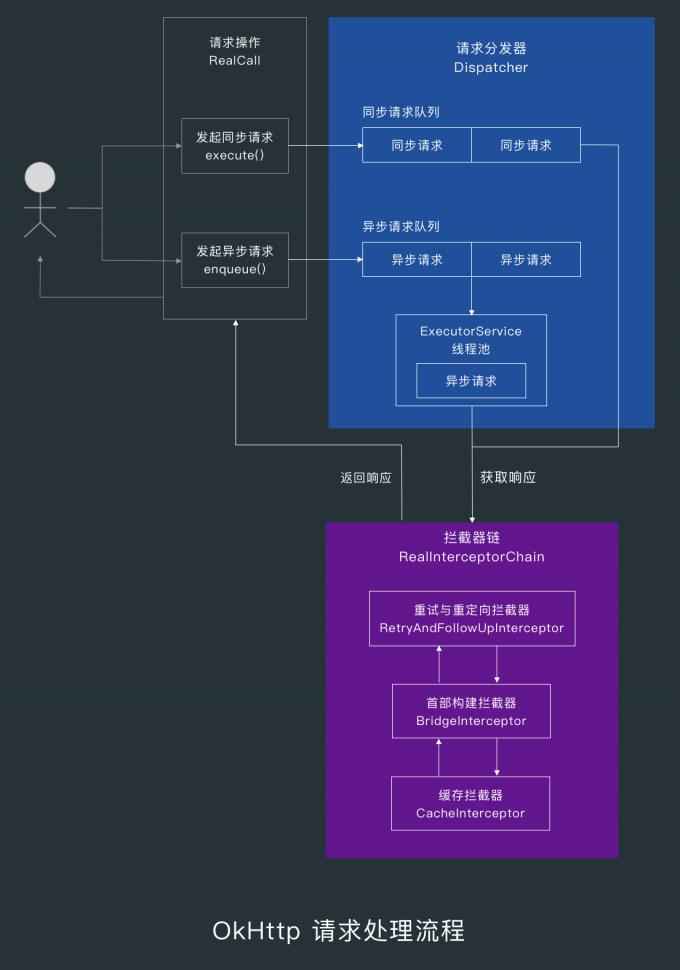
当首部构建拦截器 BridgeInterceptor 把要传给服务器端的首部放到 Request 中后,就会把请求交给缓存拦截器 CacheInterceptor 处理,为了更好地了解 CacheInterceptor 的实现,我们先来看下 HTTP 缓存机制以及相关的缓存控制首部。
6.1 HTTP 缓存机制
Web 缓存是可以自动保存常见文档副本的 HTTP 设备,当 Web 请求抵达缓存时,如果本地有已缓存的副本,就可以从本地存储设备中读取文档,不需要去源服务器提取,使用缓存有下面几个好处。
- 减少冗余的数据传输,节省用户的流量;
- 缓解网络瓶颈,不需要更多的贷款就能更快地加载页面;
- 降低对源服务器的要求,服务器可以更快地响应,避免过载;
- 降低了距离时延,因为从较远的地方加载页面会慢一些;
6.1.1 冗余的数据传输
有很多客户端访问一个流行的原始服务器页面时,服务器会多次传输同一份文档,每次传送给一个客户端,一些相同的字节会在网络中一遍遍地传输,冗余的数据传输会对导致的网络带宽费用增加、降低传输速度,加重 Web 服务器的负载。
如果有缓存,就可以保留第一条服务器响应的副本,后续请求就可以由缓存的副本来应对了,这样可以降低流量的消耗。
1. 带宽瓶颈
缓存还可以缓解网络的瓶颈问题,很多网路欧威本地服务器客户端提供的带宽比为远程服务器提供的带宽要宽,客户端会以路径上最慢的网速访问服务器,如果客户端从一个快速局域网的缓存中得到了一份副本,那么缓存就可以提高性能,尤其是传输大文件时。
2. 瞬间拥塞
缓存在破坏瞬间拥塞(Flash Crowds)时显得非常重要,突发事件(比如爆炸性新闻)会让很多人同时去访问同一个资源,这时机会出现拥塞,由此造成的流量峰值可能会导致 Web 服务器产生灾难性的崩溃。
3. 距离时延
即使带宽不是问题,距离也可能成为问题,每台网络路由器都会增加因特网流量的时延,即使客户端和服务器之间没有太多路由器,光速自身也会造成显著的时延。
6.1.2 缓存的处理步骤
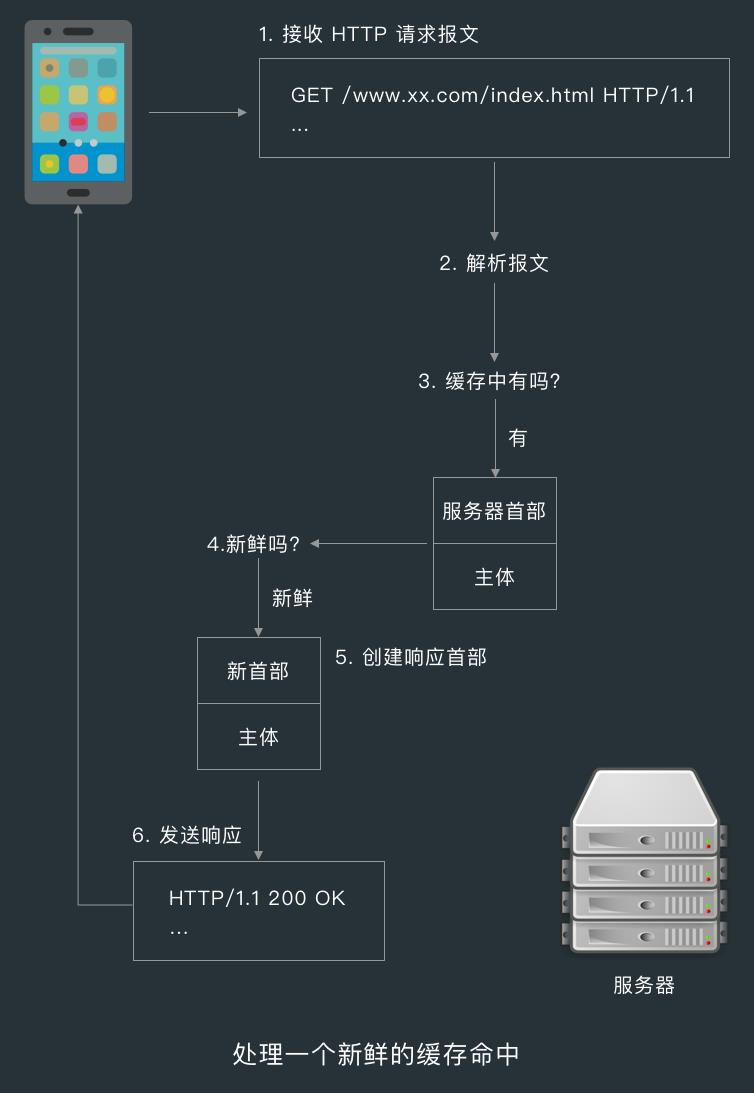
对一条 HTTP GET 报文的基本缓存处理包括下面 7 个步骤。
- 接收:缓存从网络中读取抵达的请求报文;
- 解析:缓存对报文进行解析,提取出 URL 和各种首部;
- 查询:缓存查看是否有本地副本可用,如果没有就获取一份副本并将其保存在本地;
- 新鲜度监测:缓存查看已缓存副本是否足够新鲜,如果不是就询问服务器是否有新的资源;
- 创建响应:缓存会用新的首部和已缓存的主题来构建一条响应报文;
- 发送:缓存通过网络把响应发挥给客户端;
- 日志:缓存可选地创建一个日志文件条目描述这个事务;
CacheInterceptor 大致上也是按这个流程来处理缓存的,只是在这个而基础上进行了一些细化。
6.2 缓存控制首部 CacheControl
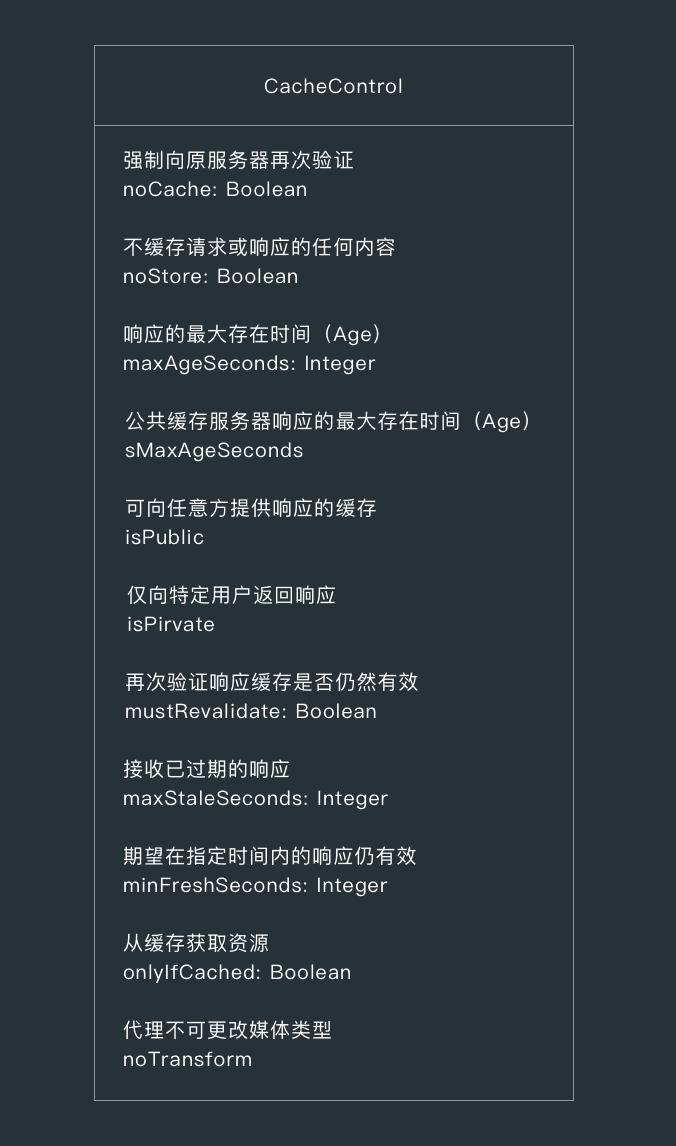
由于通用请求首部 Cache-Control 在 OkHttp 的缓存机制中发挥着主要作用,所以下面先来看下 CacheControl 中各个字段对应的指令的作用。
通过指定通用首部字段 Cache-Control 的指令,就能操作缓存的工作机制,该指令的参数是可选的,多个指令之间通过“,”分隔。
Cache-Control: private, max-age=0, no-cache
Cache-Control 可用的指令按请求和响应的分类如下。
- 缓存请求指令
- no-cache
- no-store
- max-age
- max-stale
- min-refreh
- only-if-cached
- 缓存响应指令
- public
- private
- no-cache
- no-store
- must-revalidate
- proxy-revalidate
- max-age
- s-maxage
- cache-extension
6.3 获取缓存
RealCall 在创建 CacheInterceptor 时,会把 OkHttpClient 中的 cache 字段赋值给 CacheInterceptor ,默认是空,如果我们想使用缓存的话,要在创建 OkHttpClient 的使用使用 cache() 方法设置缓存,比如下面这样。
/**
* 网络缓存数据的最大值(字节)
*/
const val MAX_SIZE_NETWORK_CACHE = 50 * 1024 * 1024L
private fun initOkHttpClient() {
val networkCacheDirectory = File(cacheDir?.absolutePath + "networkCache")
if (!networkCacheDirectory.exists()) {
networkCacheDirectory.mkdir()
}
val cache = Cache(networkCacheDirectory, MAX_SIZE_NETWORK_CACHE)
okHttpClient = OkHttpClient.Builder()
.cache(cache)
.build()
}
这里要注意的是,CacheInterceptor 只会缓存 GET 和 HEAD 等获取资源的方法的请求,而对于 POST 和 PUT 等修改资源的请求和响应数据是不会进行缓存的。
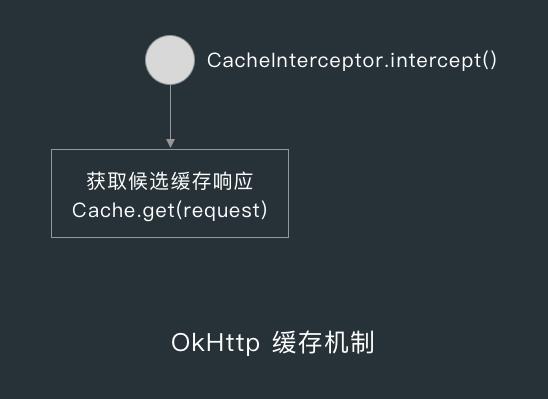
在 CacheInterceptor 的 intercept() 方法中,首先会通过 Cache.get() 获取候选缓存。
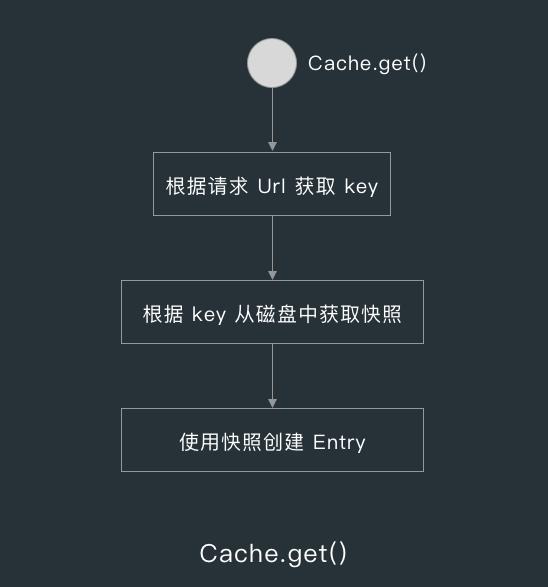
在 Cache.get() 方法中,首先会根据请求地址获取 key ,而缓存快照的 key 就是 URL 经过 md5 处理后的值,而缓存快照 Snapshot 就是 Cache 中的磁盘缓存 DiskLruCache 缓存的值,并且快照中有对应缓存文件的输入流。
当 get() 方法获取到快照后,就会用快照的输入流创建 Entry ,在 Entry 的构造方法中,会从输入流读取缓存的请求和响应的相关信息,读取完后就会完毕输入流。
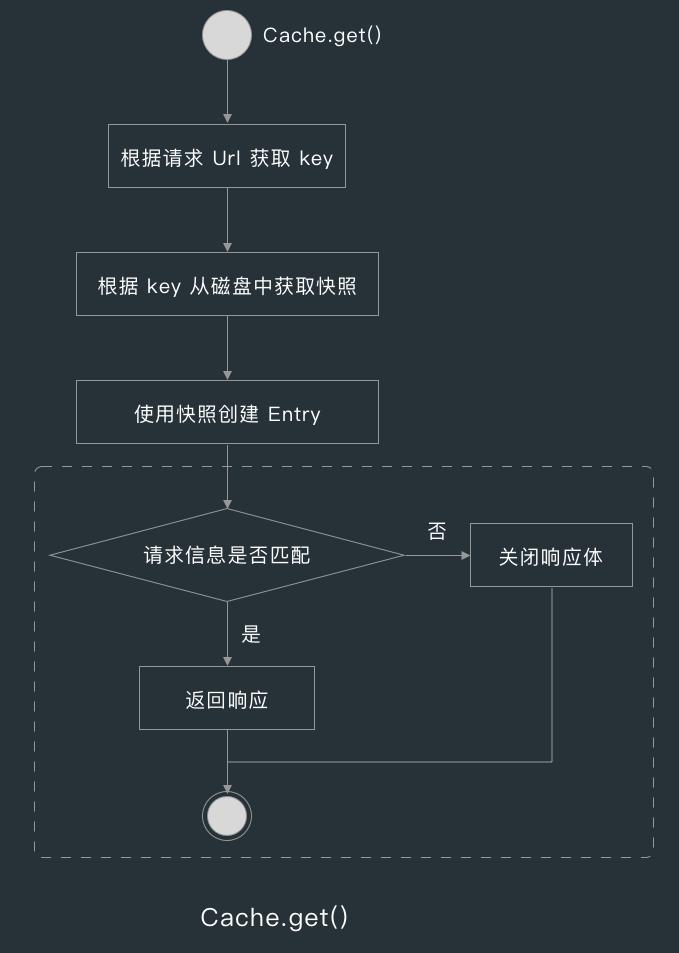
创建完 Entry 后,Cache.get() 就会判断缓存中的请求地址和请求方法与当前请求是否匹配,匹配的话则返回响应,不匹配的话则关闭响应体并返回 null ,这里说的关闭响应体指的是关闭要用来写入响应体的文件输入流。
6.4 缓存策略 CacheStrategy
获取完候选缓存响应后,CacheInterceptor 就会用缓存策略工厂的 compute() 方法生产一个缓存策略 CacheStrategy ,CacheStrategy 中比较重要的方法就是用来判断是否对当前请求和响应进行缓存的 isCacheable() 。
6.4.1 可缓存响应的状态码
在 CacheStrategy 的 isCacheable() 方法中,首先会判断响应的状态码是否为“可缓存的状态码”。
为了简化 isCacheable() 的活动图,我把下面的状态码称为“可缓存的状态码”;
- 200 OK
- 203 Not Authoritative Information
- 204 No Content
- 300 Multiple Choices
- 301 Moved Permanently
- 308 Permanent Redirect
- 404 Not Found
- 405 Method Not Allowed
- 410 Gone
- 414 Request-URI Too Large
- 501 Not Implemented
6.4.2 临时重定向状态码的缓存判断
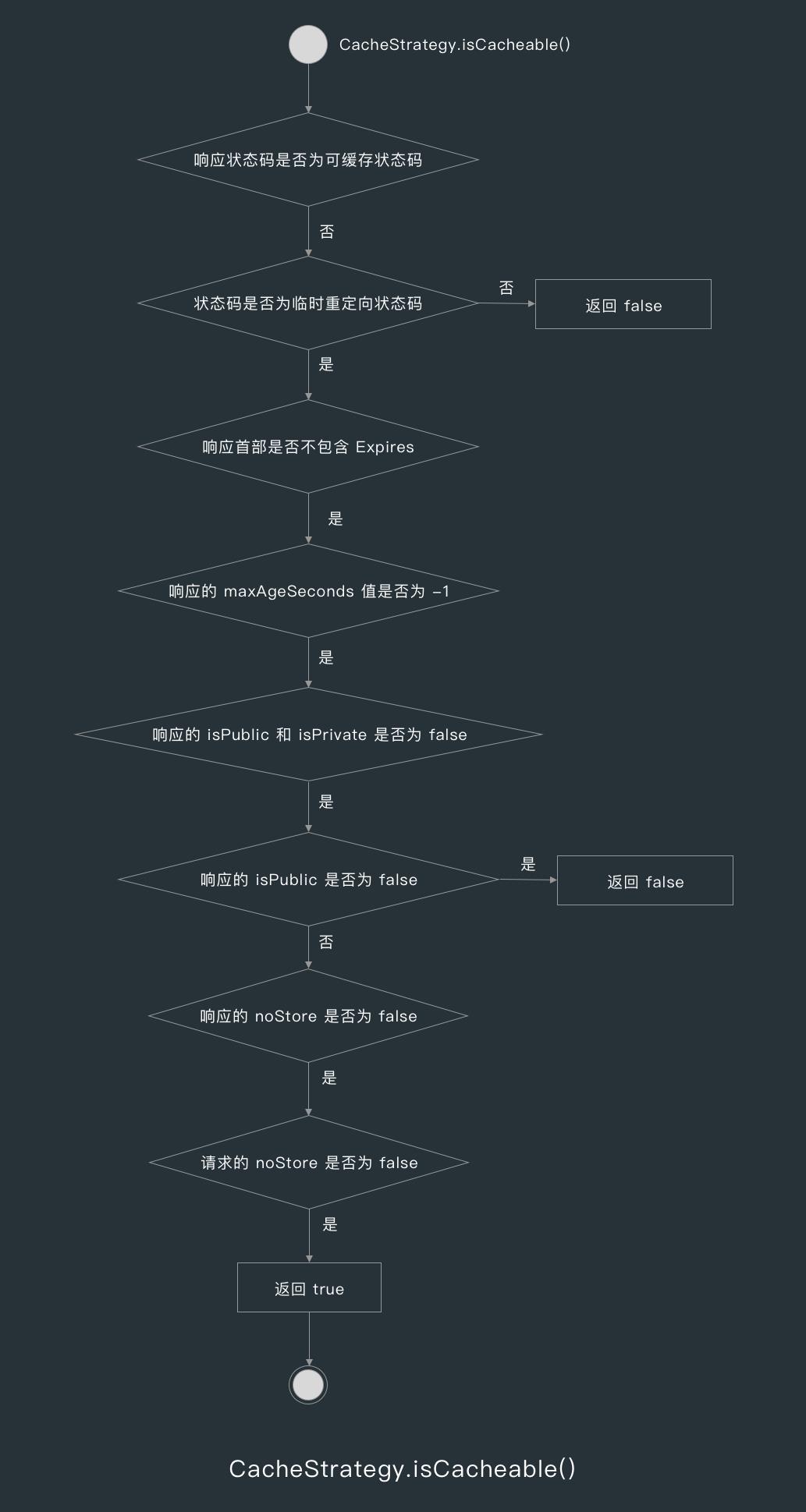
当响应的状态码为 302 或 307 时,isCacheable() 方法就会根据响应的 Expires 首部和 Cache-Control 首部判断是否返回 false(不缓存)。
Expires 首部的作用是服务器端可以指定一个绝对的日期,如果已经过了这个日期,就说明文档不“新鲜”了。
6.5 获取响应
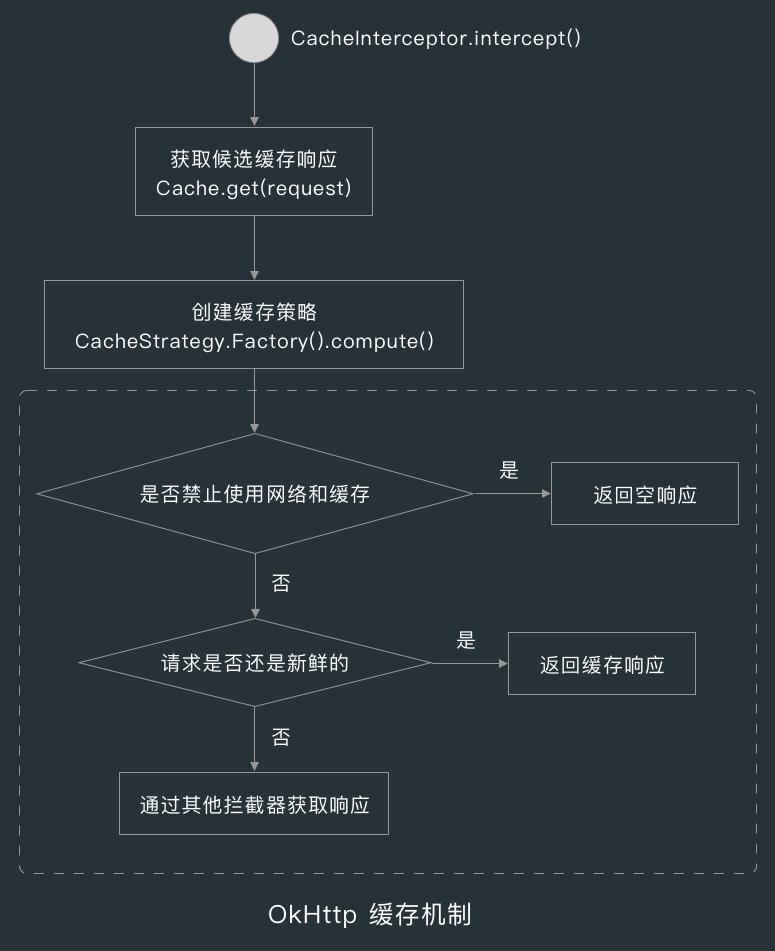
在 CacheInterceptor 调用 compute() 方法创建 CacheStrategy 时,如果 CacheControl 中有 onlyIfCached(不重新加载响应)指令,那么 CacheStrategy 的 cacheResponse 字段也为空。
当 CacheControl 中有 onlyIfCached 指令时,表明不再用其他拦截器获取响应,这时 CacheInterceptor 就会直接返回一个内容为空的响应。
当请求还是新鲜的(存在时间 age 小于新鲜时间 fresh ),那么 CacheStrategy 的 networkRequest 字段就为空,这时 CacheInterceptor 就会返回缓存中的响应。
当请求已经不新鲜时,CacheInterceptor 就会通过 ConnectInterceptor 和 CallServerInterceptor 获取响应。
6.6 保存响应
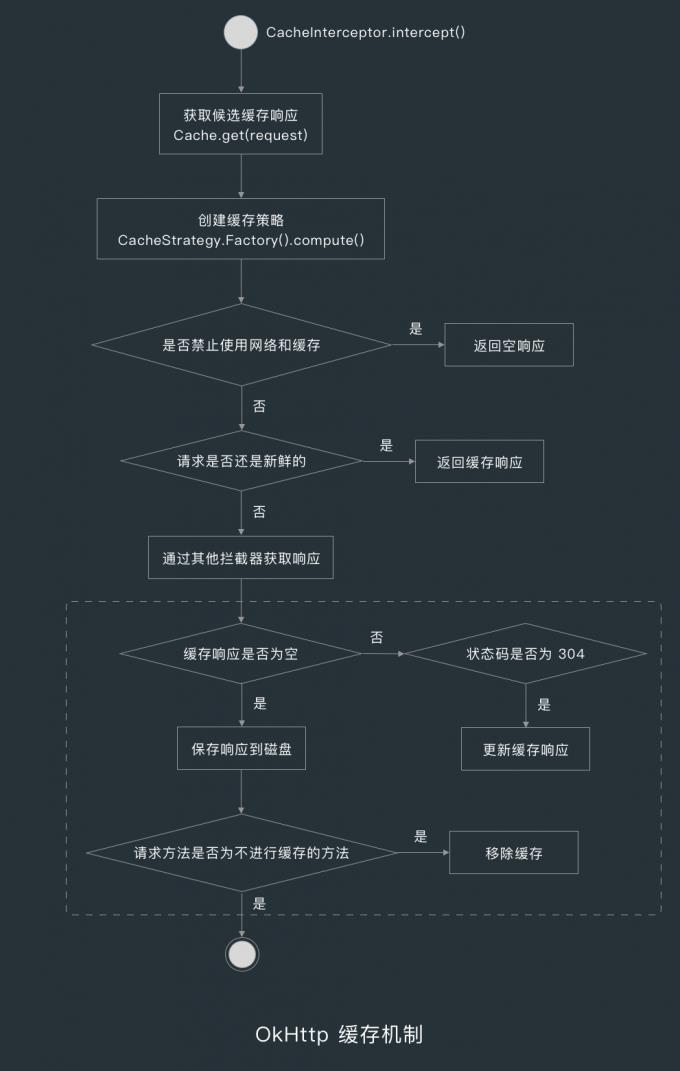
在获取到响应后,CacheInterceptor 会判断缓存响应的是否为空,如果不为空,并且状态码为 304(未修改)的话,则用新的响应替换 LruCache 中的缓存。
如果缓存响应为空,就把响应通过 Cache.put() 方法保存到磁盘中,保存后,如果请求方法为 PATCH、PUT、DELETE 会 MOVE 等修改资源的方法,那就把响应从缓存中删除。
7. OkHttp 连接建立机制
看完了缓存处理机制后,下面我们来看下 OkHttp 中负责建立连接的 ConnectInterceptor。
ConnectInterceptor 的 intercept() 方法没做什么事情,主要就是调用了 RealCall 的 initExchange() 方法建立连接。
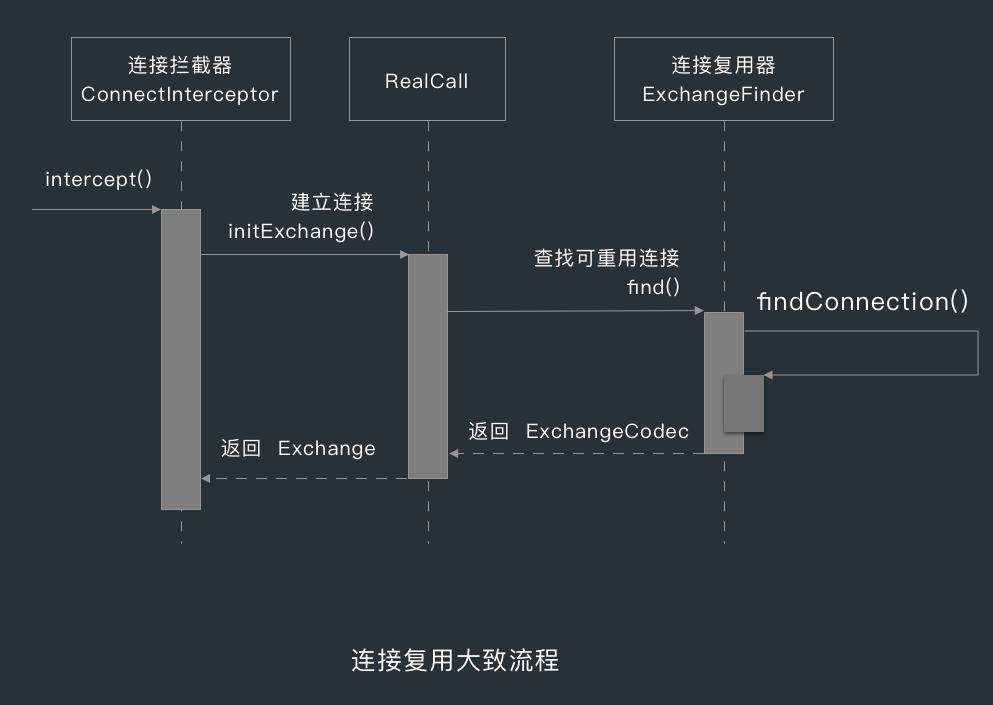
在 RealCall 的 initExchange() 方法中,会用 ExchangeFinder.find() 查找可重用的连接或创建新连接,ExchangeFinder.find() 方法会返回一个 ExchangeCodec。
ExchangeCodec 是数据编译码器,负责编码 HTTP 请求进行以及解码 HTTP 响应,Codec 为 Coder-Decoder 的缩写。
RealCall 获取到 ExchangeCodec 后,就会用 ExchangeCodec 创建一个数据交换器 Exchange ,而下一个拦截器 CallServerInterceptor 就会用 Exchange 来写入请求报文和获取响应报文。
ExchangeFinder 的 find() 方法会辗转调用到它最核心的 findConnection() 方法,在看 findConnection() 方法的实现前,我们先来了解一些 HTTP 连接相关的知识。
7.1 HTTP 连接管理
HTTP 规范对 HTTP 报文解释得很清楚,但对 HTTP 连接介绍的并不多,HTTP 连接是 HTTP 报文传输的文件通道,为了更好地理解网络编程中可能遇到的问题,HTTP 应用程序的开发者需要理解 HTTP 连接的来龙去脉以及如何使用这些连接。
世界上几乎所有的 HTTP 通信都是由 TCP/IP 承载的,TCP/IP 是全球计算机及网络设备都在使用的一种常用的分组交换网络分层鞋以及。
客户端应用程序可以打开一条 TCP/IP 连接,连接到可能运行在世界任何地方的服务器应用程序,一旦连接建立起来了,在客户端与服务器的计算机之间交换的报文就永远不会丢失、受损或失序。
1. TCP/IP 通信传输流

用 TCP/IP 协议族进行网络通信时,会通过分层顺序与对方进行通信,发送端从应用层往下走,接收端从链路层往上走。
以 HTTP 为例,首先作为发送端的客户端在应用层(HTTP 协议)发出一个想看某个 Web 页面的 HTTP 请求。
接着发送端在传输层把从应用层收到的 HTTP 报文进行分割,并在各个报文上打上标记序号及端口号转发给网络层,然后接收端的服务器在链路层接收到数据,按顺序往上层发送,一直到应用层。
也就是发送端在层与层之间传输数据时,每经过一层就会被打上该层所属的首部信息,接收端在层与层传输数据时,每经过一层就会把对应的首部消去,这种把数据信息包装起来的做法称为封装(encapsulate)。
2. TCP 套接字编程
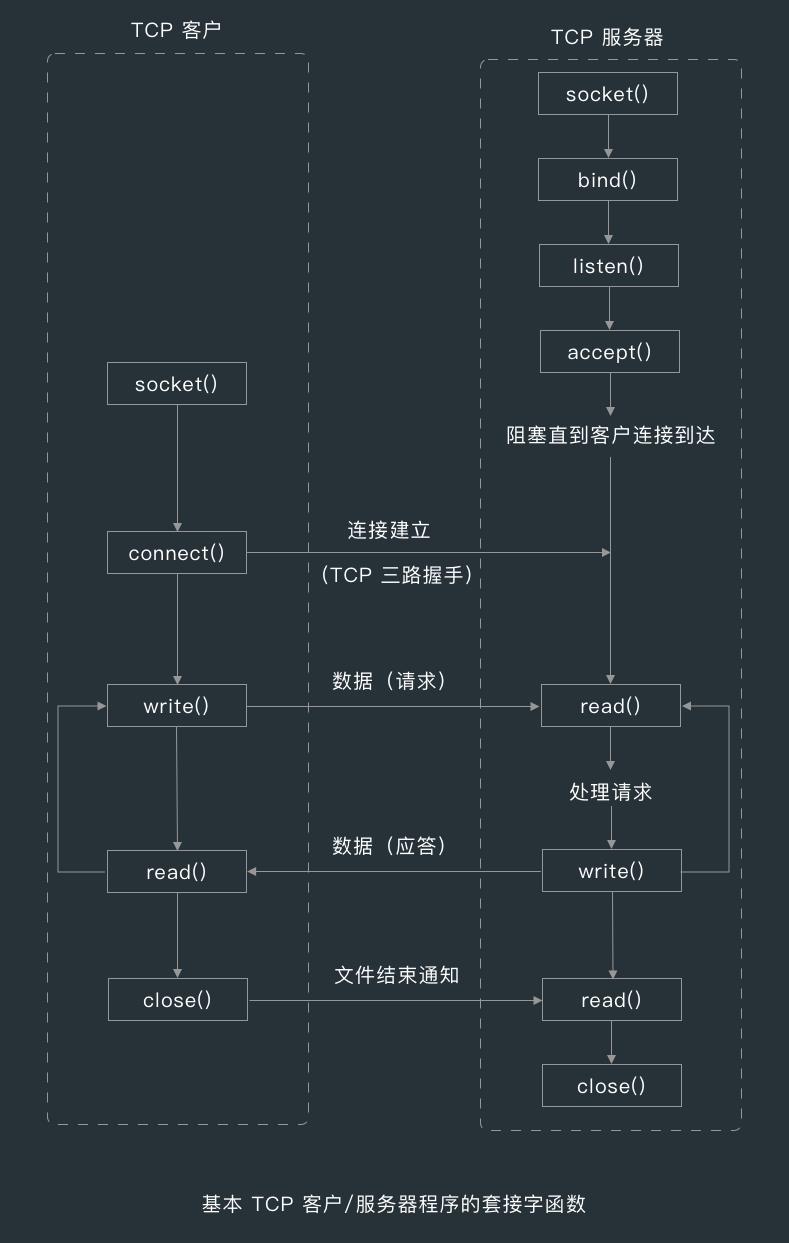
操作系统提供了一些操作 TCP 连接的工具,下面是 Socket API 提供的一些主要接口,Socket API 最初是为 Unix 操作系统开发的,但现在几乎所有的操作系统和语言中都有其变体存在。
- socket():创建一个新的、未命名、未关联的套接字;
- bind():向 Socket 赋一个本地端口号和接口;
- listen():标识一个本地 Socket,使其可以合法地接收连接;
- accept():等待某人建立一条到本地端口的连接;
- connect():创建一条连接本地 Socket 与远程主机及端口的连接;
- read():尝试从套接字向缓冲区读取 n 个字符;
- write():尝试从缓冲区向套接字写入 n 个字节;
- close():完全关闭 TCP 连接;
- shutdown():只关闭 TCP 连接的输入或输出端;
Socket API 允许用户创建 TCP 的端点和数据结构,把这些端点与远程服务器的 TCP 端点进行连接,并对数据流进行读写。
7.2 释放连接
看完了 HTTP 连接的相关知识,下面我们来看下 ExchangeFinder 的 findConnection() 方法的实现。
findConnection() 方法大致做了 3 件事,首先是释放 RealCall 已有的连接,然后是尝试从连接池中获取已有的连接以进行复用,如果没有获取到连接时,则创建一个新连接并返回给 CallServerInterceptor 使用。
在 ExchangeFinder 的 findConnection() 方法中,首先会看下是否要释放当前 RealCall 的连接。
ExchangeFInder 会判断 RealCall 的 connection 字段是否为空,如果不为空,表示该请求已经被调用过并且成功建立了连接。
这时 ExchangeFinder 就会判断 RealCall 的 connection 的 noNewExchanges 是否为 true,这个值表示不能创建新的数据交换器,默认为 false。
当请求或响应有 Connection 首部,并且 Connection 首部的值为 close 时,那么 Connection 的 noNewExchanges 的值就会被改为 true ,因为 Connection:close 表示不重用连接,如果你忘了 Connection 首部的作用,可以回到第 4 大节首部拦截器看一下。
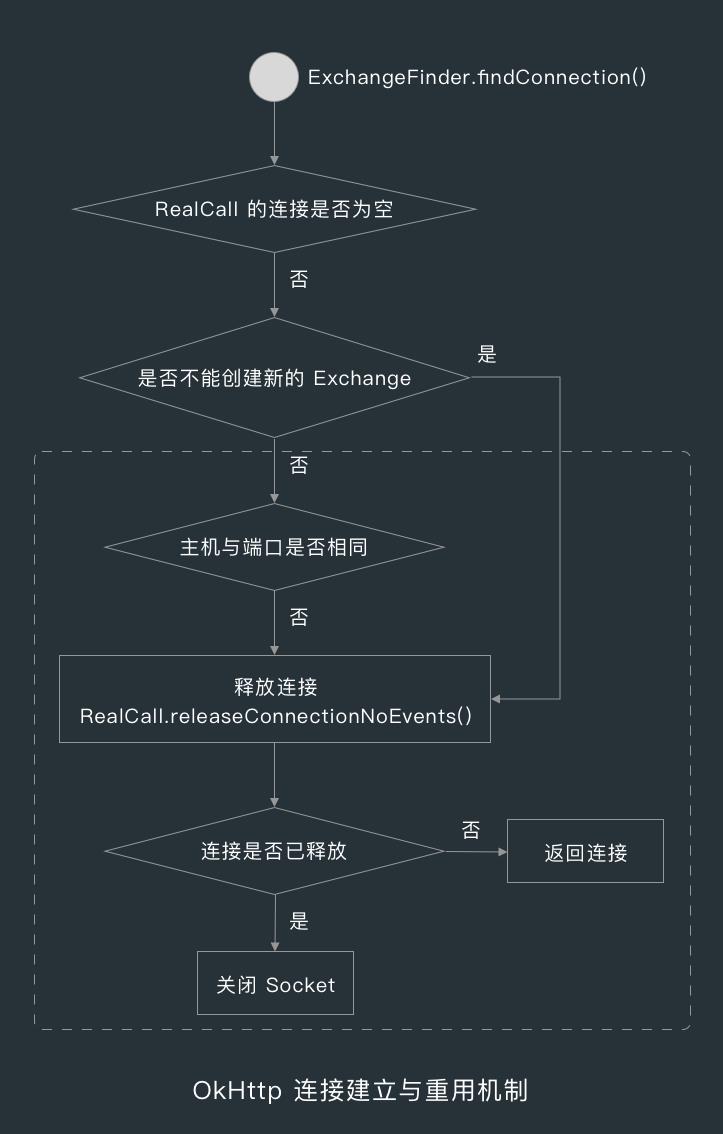
当连接的 noNewExchanges 的值为 true 时,或当前请求地址的主机和端口号和与有连接中的主机和端口号不相同时,ExchangeFinder 就会调用 RealCall 的 releaseConnectionNoevents() 方法尝试释放连接,如果如果连接未释放,则返回该连接,否则关闭连接对应的 Socket。
RealCall 的 connection 的类型为 RealConnection,RealConnection 中维护了一个 Call 列表,每当有一个 RealCall 复用该连接时,RealConnection 就会把它添加到这个列表中。
而释放连接的操作,其实就是看下 RealConnection 的 Call 列表中有没有当前 RealCall ,有的话就把当前 RealCall 从列表中移除,这时就表示连接已释放,如果连接的 Call 列表中没有当前 Call 的话,则返回当前 Call 的连接给 CallServerInterceptor 用。
7.3 从连接池获取连接
当 RealCall 的连接释放后 ExchangeFinder 就会尝试从连接池 RealConnectionPool 获取连接,RealConnectionPool 中比较重要的两个成员是 keepAliveDuration 和 connection。
keepAliveDuration 是持久连接时间,默认为 5 分钟,也就是一条连接默认最多只能存活 5 分钟,而 connections 是连接队列,类型为 ConcurrentLinkedQueue 。
每次建立一条连接时,连接池就会启动一个清理连接任务,清理任务会交给 TaskRunner 运行,在 DiskLruCache 中,也会用 TaskRunner 来清理缓存。
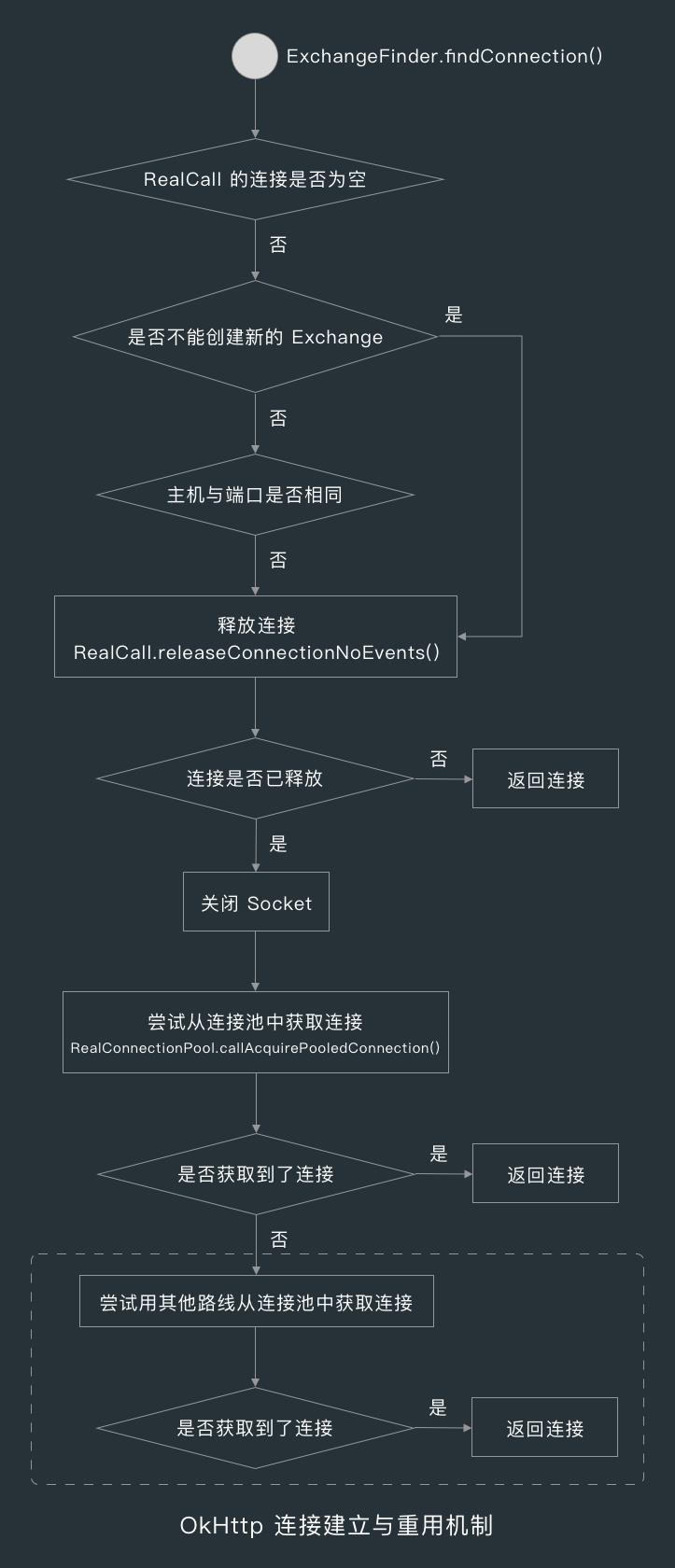
当第一次从连接池获取不到连接时,ExchangeFinder 会尝试用路线选择器 RouteSelector 来选出其他可用路线,然后把这些路线(routes)传给连接池,再次尝试获取连接,获取到则返回连接。
7.4 创建新连接
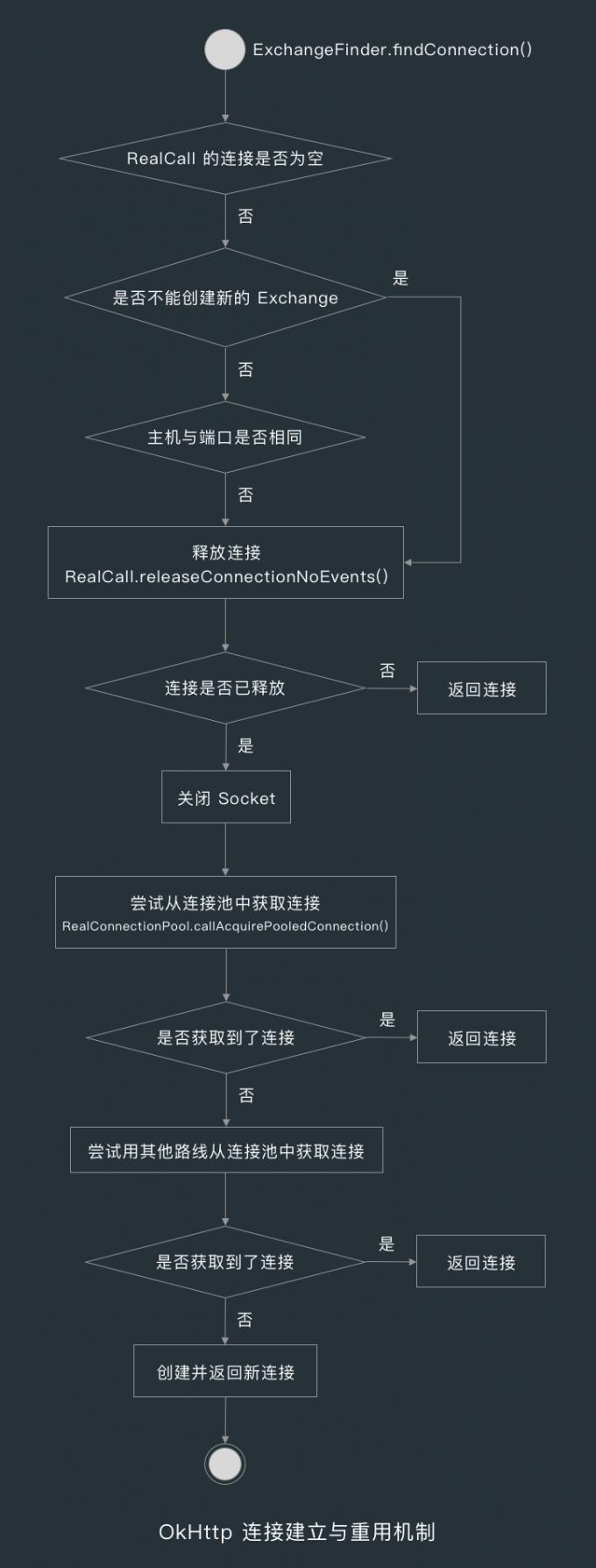
当两次从尝试从连接池连接都获取不到时,ExchangeFinder 就会创建一个新的连接 RealConnection,然后调用它的 connect() 方法,并返回该连接。
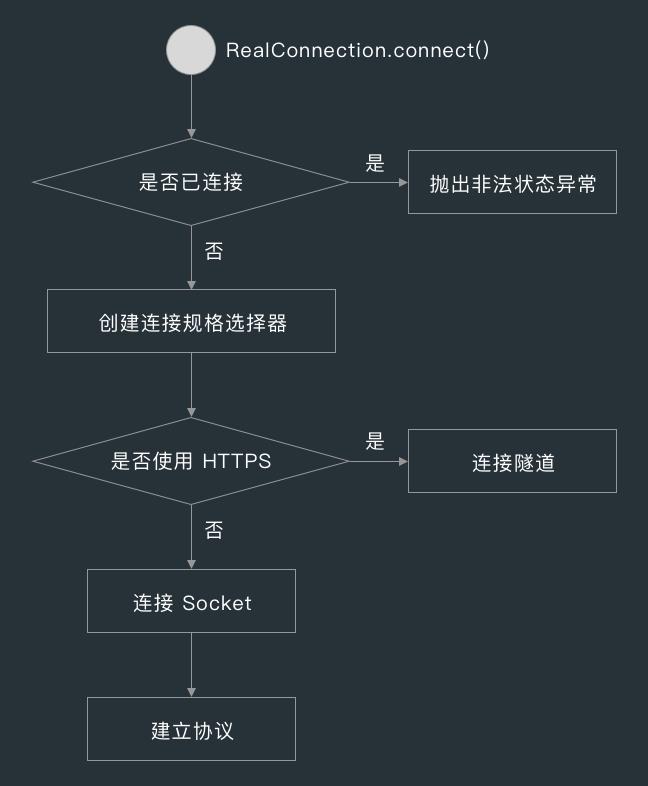
7.5 连接 Socket
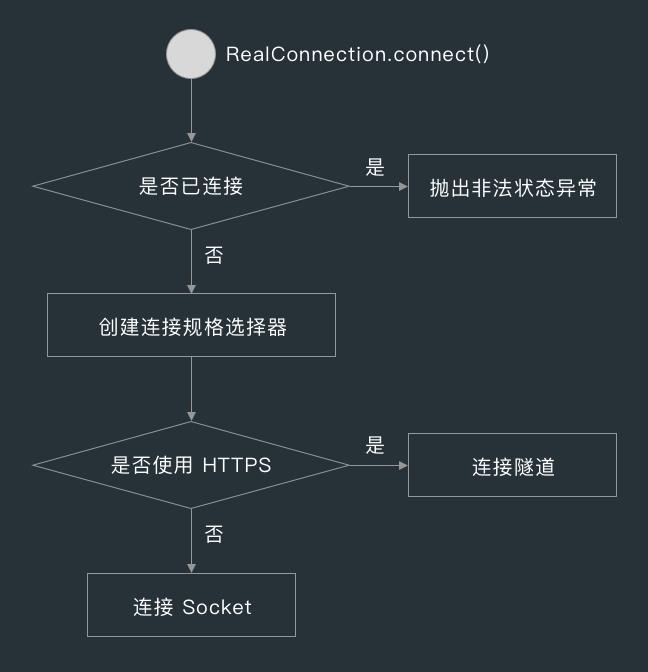
在 RealConnection 的 connect() 方法中,RealConnection 的 connect() 方法首先会判断当前连接是否已连接,也就是 connect() 方法被调用过没有,如果被调用过的话,则抛出非法状态异常。
如果没有连接过的话,则判断请求用的是不是 HTTPS 方案,是的话则连接隧道,不是的话则调用 connectSocket() 方法连接 Socket。
关于连接隧道在后面讲 HTTPS 的时候会讲到,下面先来看下 connectSocket() 方法的实现。
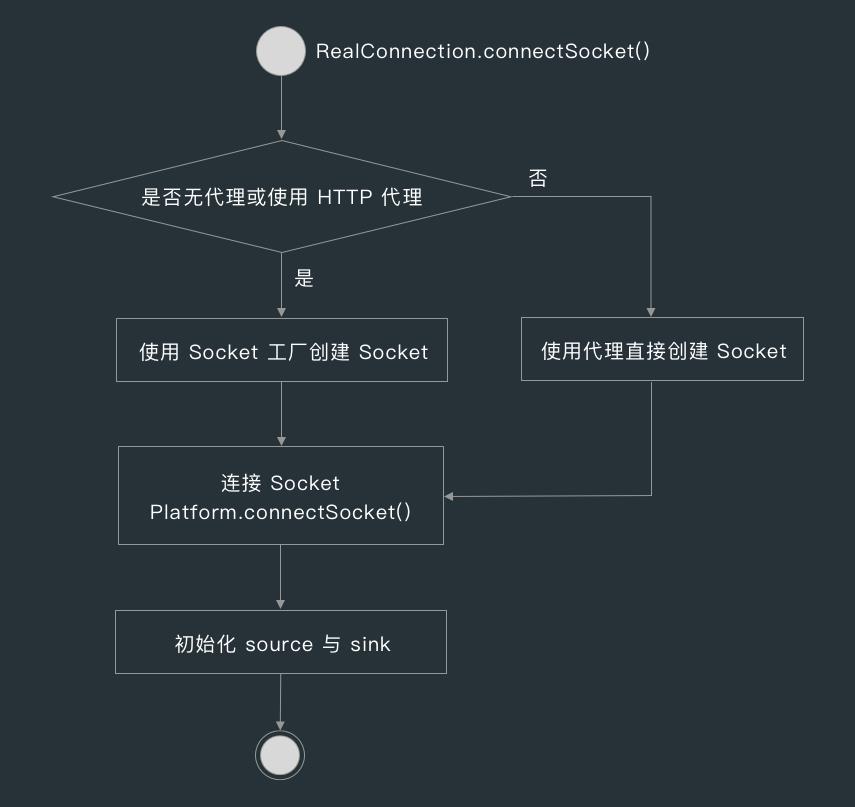
在 RealConnection 的 connectSocket() 方法中,首先会判断代理方式,如果代理方式为无代理(DIRECT)或 HTTP 代理,则使用 Socket 工厂创建 Socket,否则使用 Socket(proxy) 创建 Socket。
创建完 Socket 后,RealConnection 就会调用 Platform 的 connectSocket() 方法连接 Socket ,再初始化用来与服务器交换数据的 Source 和 Sink。
Platform 的 connectSocket() 方法调用了 Socket 的 connect() 方法,后面就是 Socket API 的活了。
7.6 建立协议
创建完 Socket 后,RealConnection 的 connect() 方法就会调用 establishProtocol() 方法建立协议。
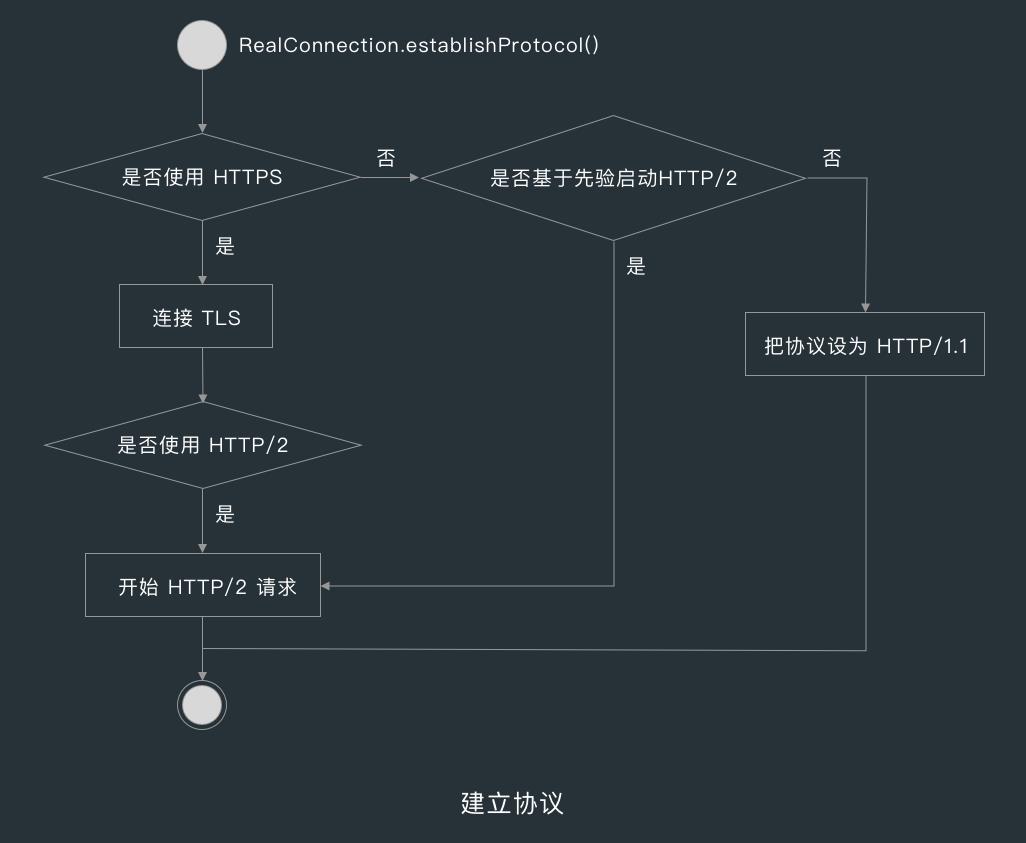
在 establishProtocol() 方法中会判断,如果使用的方案是 HTTP 的话,则判断是否基于先验启动 HTTP/2(rfc_7540_34),先验指的是预先知道,也就是客户端知道服务器端支持 HTTP/2 ,不需要不需要升级请求,如果不是基于先验启动 HTTP/2 的话,则把协议设为 HTTP/1.1 。
OkHttpClient 默认的协议有 HTTP/1.1 和 HTTP/2 ,如果我们已经知道服务器端支持明文 HTTP/2 ,我们就可以把协议改成下面这样。
val client = OkHttpClient.Builder()
.protocols(mutableListOf(Protocol.H2_PRIOR_KNOWLEDGE))
.build()
如果请求使用的方案为 HTTP 的话,establishProtocol() 方法则会调用 connectTls() 方法连接 TLS ,如果使用的 HTTP 版本为 HTTP/2.0 的话,则开始 HTTP/2.0 请求。
8. HTTPS 连接建立机制
在看 connectTls() 方法的实现前,我们先来看一些 HTTPS 相关的基础知识,如果你已经了解的话,可以跳过这一段直接从 8.2 小节看起。
8.1 HTTPS 基础知识
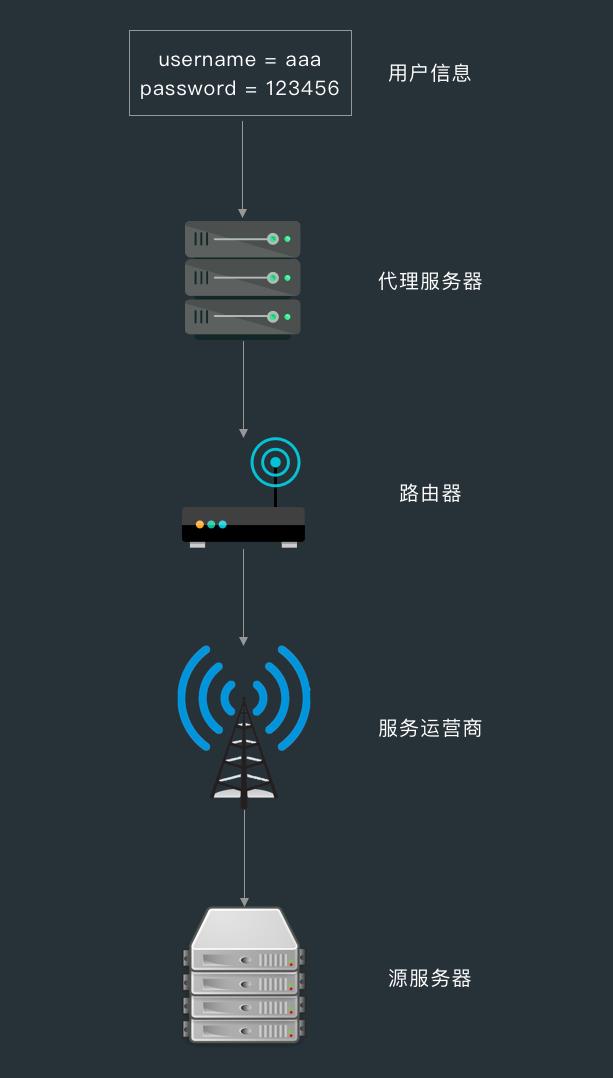
在 HTTP 模式下,搜索或访问请求以明文信息传输,经过代理服务器、路由器、WiFi 热点、服务运营商等中间人通路,形成了“中间人”获取数据、篡改数据的可能。
但是从 HTTP 升级到 HTTPS,并不是让 Web 服务器支持 HTTPS 协议这么简单,还要考虑 CDN、负载均衡、反向代理等服务器、考虑在哪种设备上部署证书与私钥,涉及网络架构和应用架构的变化。
8.1.1 中间人攻击
接下来我们来看下什么是中间人攻击,中间人攻击分为被动攻击和主动攻击两种。
中间人就是在客户端和服务器通信之间有个无形的黑手,而对于客户端和服务器来说,根本没有意识到中间人的存在,也没有办法进行防御。
1. 被动攻击
是对着手机设备越来越流行,而移动流量的资费又很贵,很多用户会选择使用 WiFi 联网,尤其是在户外,用户想方设法使用免费的 WiFI 。
很多攻击者会提供一些免费的 WiFi,一旦连接上恶意的 WiFI 网络,用户将毫无隐私。提供 WiFI 网络的攻击者可以截获所有的 HTTP 流量,而 HTTP 流量是明文的,攻击者可以知道用户的密码、银行卡信息以及浏览习惯,不用进行任何分析就能获取用户隐私,而用户并不知道自己的信息已经泄露,这种攻击方式也叫被动攻击。
2. 主动攻击
很多用户浏览某个网页时,经常会发现页面上弹出一个广告,而这个广告和访问的网页毫无关系,这种攻击主要是 ISP(互联网服务提供商,Internet Service Provider)发送的攻击,用户根本无法防护。
用户访问网站时肯定经过 ISP ,ISP 为了获取广告费等目的,在响应中插入一段 HTML 代码,就导致了该攻击的产生,这种攻击称为主动攻击,也就是攻击者知道攻击的存在。
更严重的是 ISP 或攻击者在页面插入一些恶意的 javascript 脚本,脚本一旦在客户端运行,可能会产生更恶劣的后果,比如 XSS 攻击(跨站脚本攻击,Cross Site Scripting)。
8.1.2 握手层与加密层
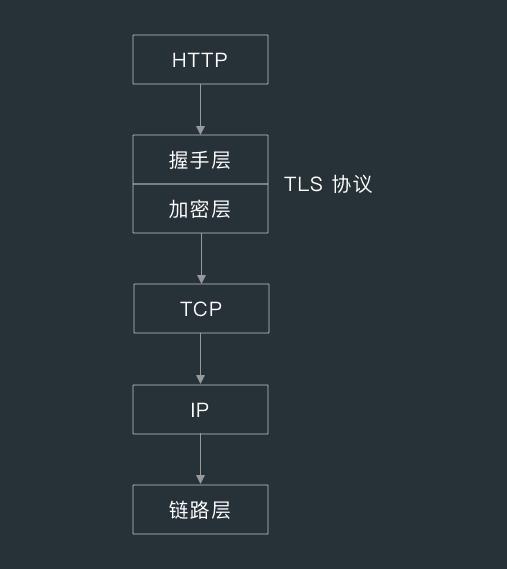
HTTPS(TLS/SSL协议)设计得很巧妙,主要由握手层和加密层两层组成,握手层在加密层的上层,提供加密所需要的信息(密钥块)。
对于一个 HTTPS 请求来说,HTTP 消息在没有完成握手前,是不会传递给加密层的,一旦握手层处理完毕,最终应用层所有的 HTTP 消息都会交给密钥层进行加密。
1. 握手层
客户端与服务器端交换一些信息,比如协议版本号、随机数、密码套件(密码学算法组合)等,经过协商,服务器确定本次连接使用的密码套件,该密码套件必须双方都认可。
客户端通过服务器发送的证书确认身份后,双方开始密钥协商,最终双方协商出预备主密钥、主密钥、密钥块,有了密钥块,代表后续的应用层数据可以进行机密性和完整性保护了,接下来由加密层处理。
2. 加密层
加密层有了握手层提供的密钥块,就可以进行机密性和完整性保护了,加密层相对来说逻辑比较简单明了,而握手层在完成握手前,客户端和服务器需要经过多个来回才能握手完成,这也是 TLS/SSL 协议缓慢的原因。
下面分别是使用 RSA 密码套件和 DHE_RSA 密码套件的 TLS 协议流程图。
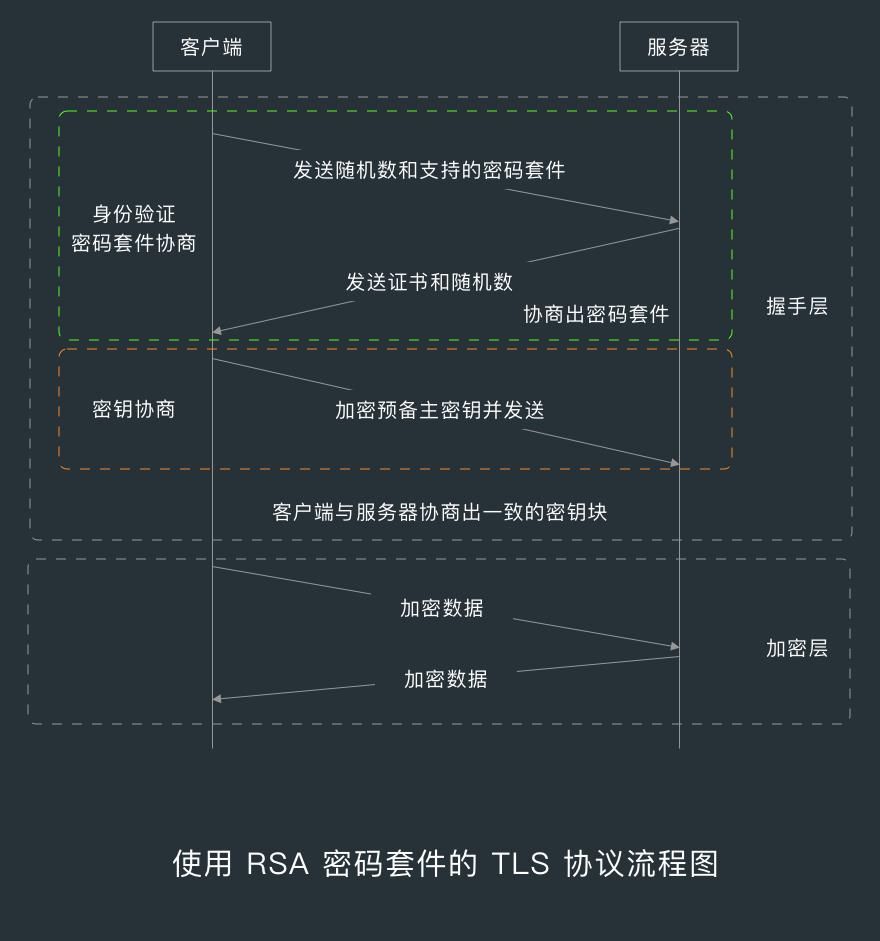
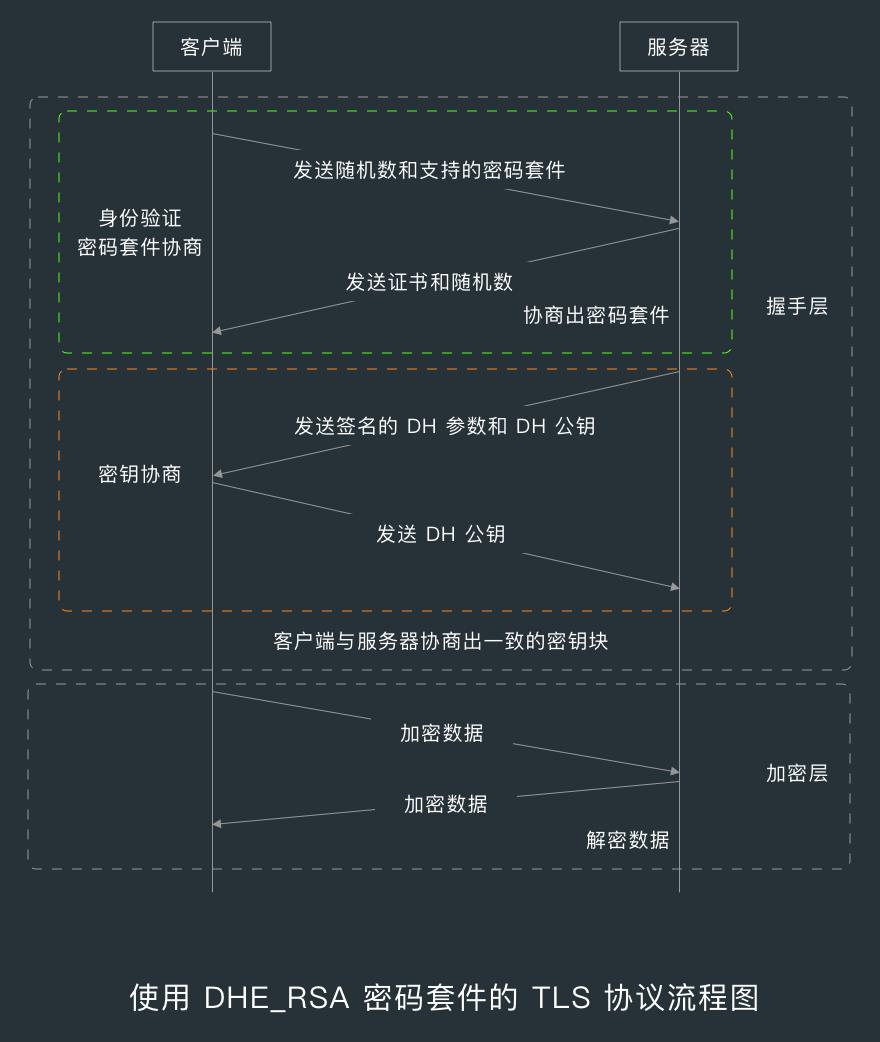
8.1.3 握手
握手指的是客户端和服务器端互相传数据前要互相协商,达成一致后才能进行数据的加密和完整性处理,认证和密码套件协商握手的关键步骤和概念。
1. 认证
客户端在进行密钥交换前,必须认证服务器的身份,否则就会存在中间人攻击,而服务器实体并不能自己证明自己,所以要通过 CA 机构来认证。
认证的技术解决方案就是签名的数字证书,证书中会说明 CA 机构采用的数字签名算法,客户端获取到证书后,会采用相应的签名算法进行验证,一旦验证通过,则表示客户端成功认证了服务器端的身份。
2. 密码套件协商
密码套件是 TLS/SSL 中最重要的一个概念,理解了密码套件就相当于理解了 TLS/SSL 协议,客户端与服务器端需要协商出双方都认可的密码套件,密码套件决定了本次连接客户端和服务器端采用的加密算法、HMAC 算法、密钥协商算法等各类算法。
密码套件协商的过程类似于客户采购物品的过程,客户(客户端)在向商家(服务器)买东西前要告诉商家自己的需求、预算,商家了解了客户的需求后,根据客户的具体情况给用户推荐商品,只有双方都满意时,交易才能完成。
而对于 TLS/SSl 协议来说,只有协商出密码套件,才能进行下一步的工作。
HTTP 是没有握手过程的,完成一次 HTTP 交互,客户端和服务器端只要一次请求/响应就能完成。
而一次 HTTP 交互,客户端和服务器端要进行多次交互才能完成,交互的过程就是协商,泌乳客户端告诉服务器端其支持的密码套件,服务器端从中选择一个双方都支持的密码套件。
密码套件的构成如下图所示。

8.1.4 加密
与握手层相比,加密层的处理相对简单,握手层协商出加密层需要的算法和算法对应的密钥块,加密层接下进行加密运算和完整性保护。
在 TLS/SSL 协议中,主要有流密码加密模式、分组加密模式、AEAD 模式三种常见的加密模式。
8.1.5 TLS/SSL 握手协议
TLS 记录协议中加密参数(Security Paramters)的值都是 TLS/SSL 握手协议填充完成的,对应的值是由客户端和服务器端共同协商完成的,独一无二。
对于一个完整握手会话,客户端和服务器端要经过几个来回才能协商出加密参数。
与加密参数关联最大的就是密码套件,客户端与服务器端会列举出支持的密码套件,然后选择一个双方都支持的密码套件,基于密码套件协商出所有的加密参数,加密参数中最重要的是主密钥(master secret)。
在讲解流程前,有几点要说明。
握手协议由很多子消息构成,对于完整握手来说,客户端与服务器端一般要经过两个来回才会完成握手。
ChangeCipherSpec 不是握手协议的一部分,在理解时可以认为 ChangeCipherSpec 是握手协议的一个子消息。
星号标记( * )表示对应的子消息是否发送,取决于不同的密码套件,比如 RSA 密码套件不会出现 ServerKeyExchange 子消息。
在 HTTPS 中,服务器和客户端都可以提供证书让对方进行身份校验。
下面是完整的 TLS/SSL 握手协议交互流程。
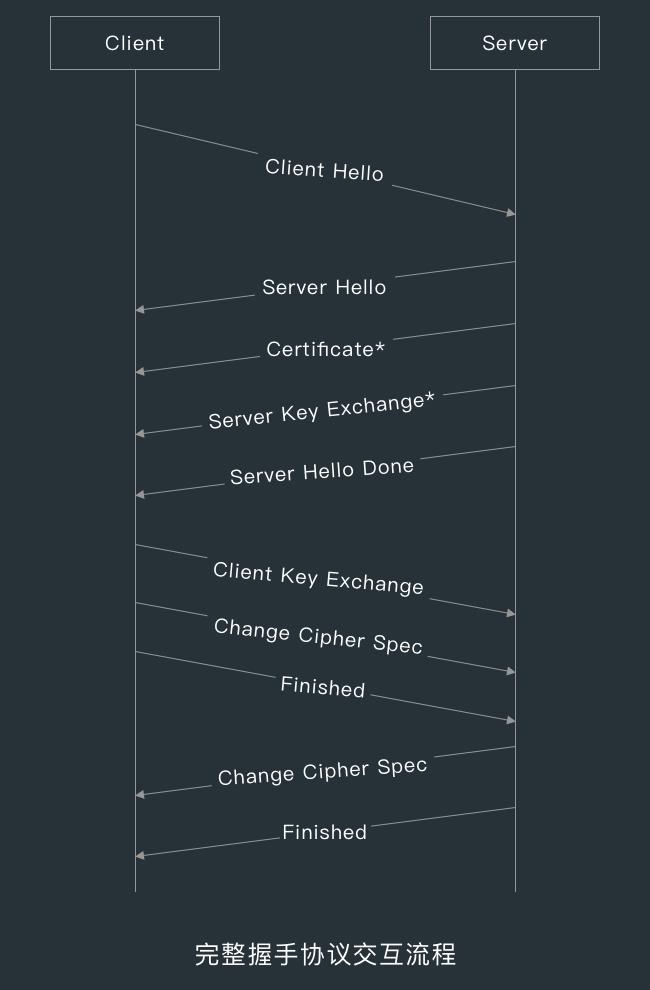
握手协议的主要步骤如下:
互相交互 hello 子消息,该消息交换随机值和支持的密码套件列表,协商出密码套件以及对应的算法,检查会话是否可恢复;
交换证书和密码学信息,允许服务器端与客户端相互校验身份;
交互必要的密码学参数,客户端与服务器端获得一致的预备主密钥;
通过预备主密钥和服务器/客户端的随机值生成主密钥;
握手协议提供加密参数(主要是密码块)给 TLS 记录层协议;
客户端与服务器端校验对方的 Finished 子消息,以避免握手协议的消息被篡改;
8.1.6 扩展
通过扩展,客户端与服务器端可以在不更新 TLS/SSL 协议的基础上获取更多的能力。
在 RFC 5246 文档中,只对扩展定义了一些概念框架和设计规范,具体扩展的详细定义由 RFC 6066 制定,每个扩展由 IANA 统一注册和管理。
扩展的工作方式如下:
- 客户端根据自己的需求发送多个
以上是关于Android 进阶之探索 OkHttp 原理的主要内容,如果未能解决你的问题,请参考以下文章
Android:安卓学习笔记之OkHttp原理的简单理解和使用