编写环境二python库scipy.stats各种分布函数生成以及随机数生成泊松分布正态分布等
Posted 汀、
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了编写环境二python库scipy.stats各种分布函数生成以及随机数生成泊松分布正态分布等相关的知识,希望对你有一定的参考价值。
平时我们在编写代码是会经常用到一些随机数,而这些随机数服从一定的概率分布。
1.泊松分布、正态分布等生成方法
1.1常见分布:

stats连续型随机变量的公共方法:
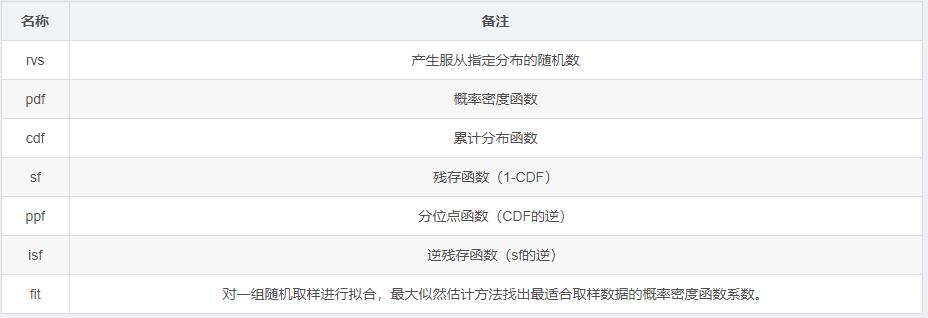
*离散分布的简单方法大多数与连续分布很类似,但是pdf被更换为密度函数pmf。
1.2 生成服从指定分布的随机数
norm.rvs通过loc和scale参数可以指定随机变量的偏移和缩放参数,这里对应的是正态分布的期望和标准差。size得到随机数数组的形状参数。(也可以使用np.random.normal(loc=0.0, scale=1.0, size=None))
import numpy as np
import scipy.stats as st
st.norm.rvs(loc = 0,scale = 0.1,size =10)
st.norm.rvs(loc = 3,scale = 10,size=(2,2))
#结果
array([[-13.26078265, 0.88411923],[ 5.14734849, 17.94093177]])
array([ 0.12259875, 0.07001414, 0.11296181, -0.00630321, -0.04377487,
0.00474487, -0.00728678, 0.03860256, 0.06701367, 0.03797084])1.3 求概率密度函数指定点的函数值
stats.norm.pdf正态分布概率密度函数。
st.norm.pdf(0,loc = 0,scale = 1)
st.norm.pdf(np.arange(3),loc = 0,scale = 1)
#结果
0.3989422804014327
array([ 0.39894228, 0.24197072, 0.05399097])
1.4 求累计分布函数指定点的函数值
stats.norm.cdf正态分布累计概率密度函数
st.norm.cdf(0,loc=3,scale=1)
st.norm.cdf(0,0,1)
#结果:
0.0013498980316300933
0.51.5 累计分布函数的逆函数
stats.norm.ppf正态分布的累计分布函数的逆函数,即下分位点。
z05 = st.norm.ppf(0.05)
print(z05)
st.norm.cdf(z05)
#结果
-1.6448536269514729
0.049999999999999975
2. 泊松分布
2.1 泊松分布问题:
假设我每天喝水的次数服从泊松分布,并且经统计平均每天我会喝8杯水
请问:
1、我明天喝7杯水概率?
2、我明天喝9杯水以下的概率?
泊松分布的概率函数为:
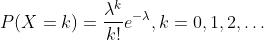
累积概率分布函数为:
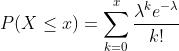
均值方差:泊松分布的均值和方差都是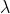 。(上述问题一:
。(上述问题一: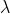 =8,k=7)
=8,k=7)
from scipy import stats
p = stats.poisson.pmf(7, 8)
print("喝7杯水概率:",p)
p = stats.poisson.cdf(9, 8)
print("喝9杯水以下的概率:",p)
#结果:
喝7杯水概率: 0.13958653195059664
喝9杯水以下的概率: 0.7166242587270112.2 泊松概率及累积概率分布(以上面例子为例):
from scipy import stats
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']#用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False#用来正常显示负号
X=range(0,16)
Y=[]
for k in X:
p = stats.poisson.pmf(k, 8)
Y.append(p)
plt.bar(X, Y, color="red")
plt.xlabel("次数")
plt.ylabel("概率")
plt.title("喝水次数和概率")
plt.show()
可以看出,在均值8附近,概率最大,均值两边概率呈递减状态
2.3 随机数生成:
生成服从=8的泊松分布随机数14个:
from scipy import stats
# 设置random_state时,每次生成的随机数一样--任意数字
#不设置或为None时,多次生成的随机数不一样
sample = stats.poisson.rvs(mu=8, size=14, random_state=None)
print(sample)
#结果
[ 9 5 9 4 8 12 9 7 12 9 10 7 3 6]2.4 泊松分布概率密度函数和累计概率绘图
import numpy as np
import scipy.stats as stats
import matplotlib.pyplot as plt
import matplotlib.style as style
# 绘图配置
style.use('seaborn-bright')
plt.rcParams['figure.figsize'] = (15, 8)
plt.figure(dpi=120)
# 一段时间内发生的次数
data = np.arange(50)
# PMF 绘制泊松分布的概率密度函数
plt.plot(data, stats.poisson.pmf(data, mu=5), label='pmf(mu=5)')
plt.bar(data, stats.poisson.pmf(data, mu=5), alpha=.5)
# CDF 累积概率密度
plt.plot(data, stats.poisson.cdf(data, mu=5), label='cdf(mu=5)')
# PMF 绘制泊松分布的概率密度函数
plt.plot(data, stats.poisson.pmf(data, mu=15), label='pmf(mu=15)')
plt.bar(data, stats.poisson.pmf(data, mu=15), alpha=.5)
# CDF 累积概率密度
plt.plot(data, stats.poisson.cdf(data, mu=15), label='cdf(mu=15)')
# PMF 绘制泊松分布的概率密度函数
plt.plot(data, stats.poisson.pmf(data, mu=30), label='pmf(mu=30)')
plt.bar(data, stats.poisson.pmf(data, mu=30), alpha=.5)
# CDF 累积概率密度
plt.plot(data, stats.poisson.cdf(data, mu=30), label='cdf(mu=30)')
plt.legend(loc='upper left')
plt.title('poisson')
plt.show()
print('p(x<8)时的概率:{}'.format(stats.poisson.cdf(k=8, mu=15)))
print('p(8<x<20)时的概率:{}'.format(stats.poisson.cdf(k=20, mu=15) - stats.poisson.cdf(k=8, mu=15)))
当λ=15时,得出的概率值:
p(x<8)时的概率:0.037446493479672875
p(8<x<20)时的概率:0.8795825964888668
3.伯努利分布
3.1伯努利概率分布
伯努利分布:伯努利试验单次随机试验,只有"成功(值为1)"或"失败(值为0)"这两种结果,又名两点分布或者0-1分布。
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['SimHei']#中文雅黑字体
plt.rcParams['axes.unicode_minus']=False #显示负号X=np.arange(0,2,1)#[0,1)
p=0.7#库里投三分命中率
pList=stats.bernoulli.pmf(X,p)#在离散分布中,请将pmf改为pdf
print(pList)
plt.plot(X,pList,marker='o',linestyle='None')
'''
vlines用于绘制竖直线(vertical lines),
参数说明:vline(x坐标值,y坐标最小值,y坐标最大值)
我们传入的X是一个数组,是给数组中的每个x坐标值绘制直线,
数值线y坐标最小值是0,y坐标最大值是对应的pList中的值'''
plt.vlines(X,(0,0),pList)
plt.xlabel('随机变量:库里投篮1次')
plt.ylabel('概率')
plt.title('伯努利分布:p=%.2f'% p)
plt.show()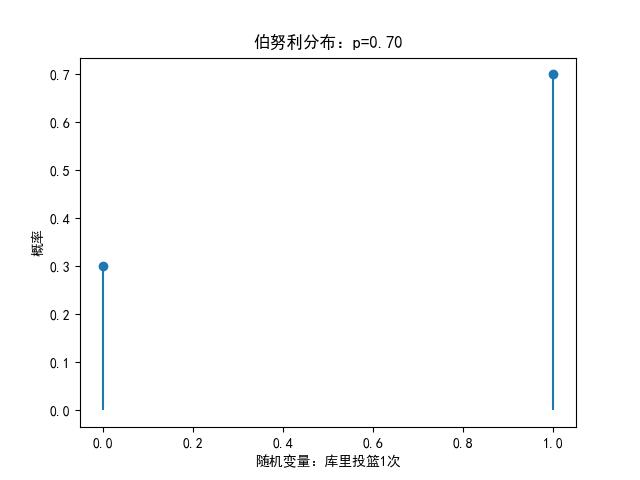
3.2 伯努利分布随机数生成
p=0.7#发生概率
b=stats.bernoulli.rvs(p,random_state=None)#random_state=None每次生成随机
print(b)
以上是关于编写环境二python库scipy.stats各种分布函数生成以及随机数生成泊松分布正态分布等的主要内容,如果未能解决你的问题,请参考以下文章
python scipy.stats.powerlaw否定指数