周末请看:2万字!JVM核心知识总结,赠送18连环炮
Posted Java后端技术全栈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了周末请看:2万字!JVM核心知识总结,赠送18连环炮相关的知识,希望对你有一定的参考价值。
关注“Java后端技术全栈”
回复“000”获取大量电子书
作为java开发人员,JVM是必备的,今天,我把JVM的核心知识点进行了一个总结,画了一张思维导图。
图展开太了,需要的加我微信tj20120622,我私发给你
下面用一个18问来开头,先自己试试这18问,你能回答多数问?
送给你 JVM 的 18 问
1.JDK、JRE、JVM有什么关系?
2.java是怎么编译的?
3.编译成的class文件后,JVM是如何加载class的?
4.类加载机制是什么?
5.类加载器有哪些?
6.如何自定义类加载器?
7.双亲委派模型是什么?
8.双亲委派模型为什么安全?
9.如何破坏?
10.破坏双亲委派模型的经典案例?
11.运行时数据库区每个区域是干啥的?
12.怎么判断一个对象为垃圾对象?
13.垃圾回收算法有哪些?
14.每个算法的利弊?
15.实现垃圾算法的垃圾收集器有哪些?
16.JVM性能调优参数熟悉哪些?
17.熟悉哪些性能调优工具?
18.关于JVM相关调优经历吗,有的话说说你的看法?
.....
个人认为上面这18问,就难倒很多人。如果你觉得自己没问题,那就没必要看此文了。出门右拐看更高级更牛逼的O(∩_∩)O哈哈~。
反之,建议踏踏实实的学习,每一篇文章老田都是用心写出来的,真心的希望对你有所帮助。
趁年轻,加油!不吃学习的苦,必吃生活的苦!
认识JDK、JVM、JRE
什么是JVM
JVM 全称 Java Virtual Machine(Java 虚拟机) ,也就是我们耳熟能详的 Java 虚拟机。它能识别 .class后缀的文件,并且能够解析它的指令,最终调用操作系统上的函数,完成我们想要的操作。
JDK认识
Java Development Kit (JDK) 是Sun公司(已被Oracle收购)针对Java开发员的软件开发工具包。自从Java推出以来,JDK已经成为使用最广泛的Java SDK(Software development kit)。
什么是JRE
JRE全程Java Runtime Environment,是运行基于Java语言编写的程序所不可缺少的运行环境。也是通过它,Java的开发者才得以将自己开发的程序发布到用户手中,让用户使用。
JDK、JVM、JRE关系
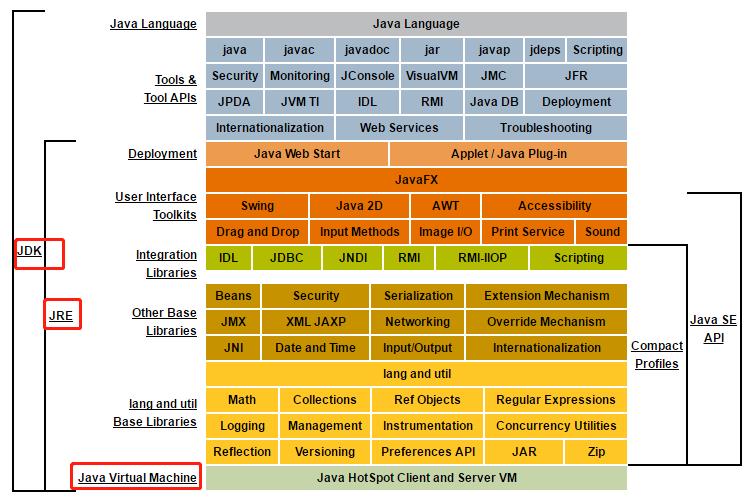
从图中可以得知:
范围关系:JDK>JRE>JVM
编译
从java源文件到class文件的整个流程为:
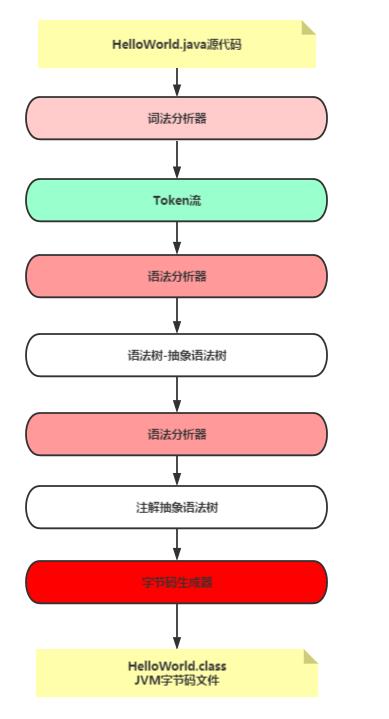
总结以下四步:
1、词法分析
读取源代码,一个字节一个字节的读取,找出其中我们定义好的关键字(如Java中的if、else、for、while等关键词,识别哪些if是合法的关键词,哪些不是),这就是词法分析器进行词法分析的过程,其结果是从源代码中找出规范化的Token流。
2、语法分析
通过语法分析器对词法分析后Token流进行语法分析,这一步检查这些关键字组合再一次是否符合Java语言规范(如在if后面是不是紧跟着一个布尔判断表达式),词法分析的结果是形成一个符合Java语言规范的抽象语法树。
3、语义分析
通过语义分析器进行语义分析。语音分析主要是将一些难懂的、复杂的语法转化成更加简单的语法,结果形成最简单的语法(如将foreach转换成for循环 ,好有注解等),最后形成一个注解过后的抽象语法树,这个语法树更为接近目标语言的语法规则。
4、生成字节码
通过字节码生产器生成字节码,根据经过注解的语法抽象树生成字节码,也就是将一个数据结构转化为另一个数据结构。最后生成我们想要的.class文件。
类加载
如何查找class文件并导入到JVM中
(1)通过一个类的全限定名获取定义此类的二进制字节流
(2)将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构
(3)在Java堆中生成一个代表这个类的java.lang.Class对象,作为对方法区中这些数据的访问入口
获取class文件有哪些方式
.class文件也是需要查找的,以下是查找.class文件的常用方式:
-
从本地文件系统中加载.class文件 -
从jar包中或者war包中加载.class文件 -
通过网络或者从数据库中加载.class文件 -
把一个Java源文件动态编译,并加载
加载进来后就,系统为这个.class文件生成一个对应的Class对象。
生成Class对象的有哪些方式
1.对象获取:调用person类的父类方法getClaass();
2.类名获取,每个类型(包括基本类型和引用)都有一个静态属性,class。
3.Class类的静态方法获取。forName("字符串的类名")写全名,要带包名。 (包名.类名)
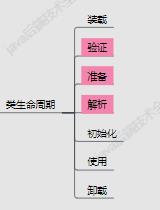
类加载机制
类加载机制分为三步:
[Loading]装载:其实就是我们上面查找class文件并导入到JVM中。
[Linking] 连接:就是对整个class内容进行一系列的校验、为一些变量进行数据准备、把字节码中符号进行解析等操作。
[Initializing]初始化:创建我们使用的对象;User user=new User();
其中连接又分三个步骤:验证、准备、解析。
连接
验证
首先肯定是要保证被加载类的正确性,也就是做一些.class文件人的校验罢了;
-
文件格式验证
-
元数据验证
-
字节码验证
-
符号引用验证
准备
为类的静态变量分配内存空间,并将其初始化为默认值。
比如说User.java中有个变量int a;
public class InitialDemo {
static int a = 10;
public static void main(String[] args) {
System.out.println(a);
}
}
在这个阶段,会对这些static修饰的变量进行赋值,附一个初始值,这里就是给
int a =0;
因为int类型的初始值就是0;如果是String类型,那么初始值就是null。
解析
换言之,把符号引用变成直接引用。
符号引用
符号引用以一组符号来描述所引用的目标,符号可以是任何形式的字面量,只要使用时能够无歧义的定位到目标即可。
例如,在Class文件中通过javap命令能查看,它以
CONSTANT_Class_info、
CONSTANT_Fieldref_info、
CONSTANT_Methodref_info等类型的常量出现。
符号引用与虚拟机的内存布局无关,引用的目标并不一定加载到内存中。在Java中,一个java类将会编译成一个class文件。
各种虚拟机实现的内存布局可能有所不同,但是它们能接受的符号引用都是一致的,因为符号引用的字面量形式明确定义在Java虚拟机规范的Class文件格式中。
直接引用
直接引用可以是以下三种场景:
(1)直接指向目标的指针(比如,指向“类型”【Class对象】、类变量、类方法的直接引用可能是指向方法区的指针)
(2)相对偏移量(比如,指向实例变量、实例方法的直接引用都是偏移量)
(3)一个能间接定位到目标的句柄
直接引用是和虚拟机的布局相关的,同一个符号引用在不同的虚拟机实例上翻译出来的直接引用一般不会相同。
如果有了直接引用,那引用的目标必定已经被加载入内存中了。
类加载器
在装载(Load)阶段,通过类的全限定名获取其定义的二进制字节流,需要借助类装载 器完成,顾名思义,就是用来装载Class文件的。
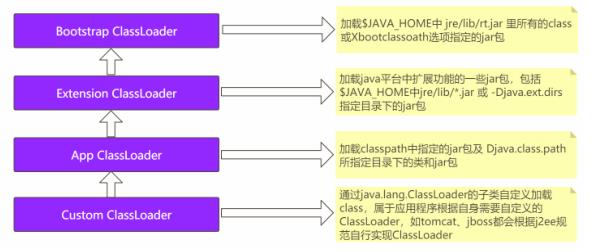
类装载器分类
Bootstrap ClassLoader
负责加载$JAVA_HOME中 jre/lib/rt.jar里所有的class或Xbootclassoath选项指定的jar包。由C++实现,不是ClassLoader子类。
Extension ClassLoader
负责加载Java平台中扩展功能的一些jar包,包括$JAVA_HOME中jre/lib/*.jar或 -Djava.ext.dirs指定目录下的jar包。
App ClassLoader
负责加载classpath中指定的jar包及 Djava.class.path所指定目录下的类和jar包。
Custom ClassLoader
通过java.lang.ClassLoader的子类自定义加载class,属于应用程序根据自身需要自定义的ClassLoader,如tomcat、jboss都会根据j2ee规范自行实现ClassLoader。
图解类加载
加载原则
检查某个类是否已经加载:顺序是自底向上,从Custom ClassLoader到BootStrap ClassLoader逐层检
查,只要某个Classloader已加载,就视为已加载此类,保证此类只所有ClassLoader加载一次。
加载的顺序:先查找是否已经加载过,当没有被加载过,则加载的顺序是自顶向下,也就是由上层来逐层尝试加载此类。
java.lang.ClassLoader中很重要的三个方法:
-
loadClass方法
-
findClass方法
-
defineClass方法
loadClass方法
public Class<?> loadClass(String name) throws ClassNotFoundException {
return loadClass(name, false);
}
protected Class<?> loadClass(String name, boolean resolve) throws ClassNotFoundException{
//使用了同步锁,保证不出现重复加载
synchronized (getClassLoadingLock(name)) {
// 首先检查自己是否已经加载过
Class<?> c = findLoadedClass(name);
//没找到
if (c == null) {
long t0 = System.nanoTime();
try {
//有父类
if (parent != null) {
//让父类去加载
c = parent.loadClass(name, false);
} else {
//如果没有父类,则委托给启动加载器去加载
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// ClassNotFoundException thrown if class not found
// from the non-null parent class loader
}
if (c == null) {
// If still not found, then invoke findClass in order
// to find the class.
long t1 = System.nanoTime();
// 如果都没有找到,则通过自定义实现的findClass去查找并加载
c = findClass(name);
// this is the defining class loader; record the stats
sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
sun.misc.PerfCounter.getFindClasses().increment();
}
}
//是否需要在加载时进行解析
if (resolve) {
resolveClass(c);
}
return c;
}
}
正如loadClass方法所展示的,当类加载请求到来时,先从缓存中查找该类对象,如果存在直接返回,如果不存在则交给该类加载去的父加载器去加载,倘若没有父加载则交给顶级启动类加载器去加载,最后倘若仍没有找到,则使用findClass()方法去加载(关于findClass()稍后会进一步介绍)。从loadClass实现也可以知道如果不想重新定义加载类的规则,也没有复杂的逻辑,只想在运行时加载自己指定的类,那么我们可以直接使用this.getClass().getClassLoder.loadClass("className"),这样就可以直接调用ClassLoader的loadClass方法获取到class对象。
findClass方法
protected Class<?> findClass(String name) throws ClassNotFoundException {
throw new ClassNotFoundException(name);
}
在JDK1.2之前,在自定义类加载时,总会去继承ClassLoader类并重写loadClass方法,从而实现自定义的类加载类,但是在JDK1.2之后已不再建议用户去覆盖loadClass()方法,而是建议把自定义的类加载逻辑写在findClass()方法中,从前面的分析可知,findClass()方法是在loadClass()方法中被调用的,当loadClass()方法中父加载器加载失败后,则会调用自己的findClass()方法来完成类加载,这样就可以保证自定义的类加载器也符合双亲委托模式。
需要注意的是ClassLoader类中并没有实现findClass()方法的具体代码逻辑,取而代之的是抛出ClassNotFoundException异常,
同时应该知道的是findClass方法通常是和defineClass方法一起使用的。
defineClass方法
protected final Class<?> defineClass(String name, byte[] b, int off, int len,
ProtectionDomain protectionDomain) throws ClassFormatError{
protectionDomain = preDefineClass(name, protectionDomain);
String source = defineClassSourceLocation(protectionDomain);
Class<?> c = defineClass1(name, b, off, len, protectionDomain, source);
postDefineClass(c, protectionDomain);
return c;
}
defineClass()方法是用来将byte字节流解析成JVM能够识别的Class对象。通过这个方法不仅能够通过class文件实例化class对象,也可以通过其他方式实例化class对象,如通过网络接收一个类的字节码,然后转换为byte字节流创建对应的Class对象 。
如何自定义类加载器
用户根据需求自己定义的。需要继承自ClassLoader,重写方法findClass()。
如果想要编写自己的类加载器,只需要两步:
-
继承ClassLoader类 -
覆盖findClass(String className)方法
ClassLoader超类的loadClass方法用于将类的加载操作委托给其父类加载器去进行,只有当该类尚未加载并且父类加载器也无法加载该类时,才调用findClass方法。
如果要实现该方法,必须做到以下几点:
1.为来自本地文件系统或者其他来源的类加载其字节码。
2.调用ClassLoader超类的defineClass方法,向虚拟机提供字节码。
双亲委派模型
什么是双亲委派模型
如果一个类加载器在接到加载类的请求时,先查找是否已经加载过,如果没有被加载过,它首先不会自己尝试去加载这个类,而是把这个请求任务委托给父类加载器去完成,依次递归,如果父类加载器可以完成类加载任务,就成功返回;只有父类加载器无法完成此加载任务时,才自己去加载。
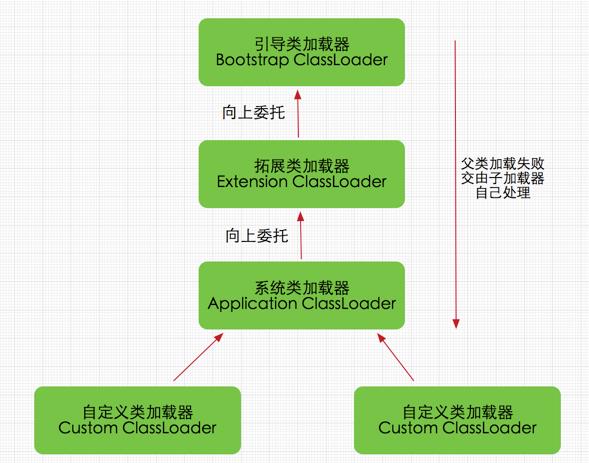
双亲委派模型有什么好处?
Java类随着加载它的类加载器一起具备了一种带有优先级的层次关系。
比如,Java中的Object类,它存放在rt.jar之中,无论哪一个类加载器要加载这个类,最终都是委派给处于模型最顶端的启动类加载器进行加载,因此Object在各种类加载环境中都是同一个类。
如果不采用双亲委派模型,那么由各个类加载器自己取加载的话,那么系统中会存在多种不同的Object类。
打破双亲委派模型的案例
tomcat
tomcat 通过 war 包进行应用的发布,它其实是违反了双亲委派机制原则的。简单看一下 tomcat 类加载器的层次结构。
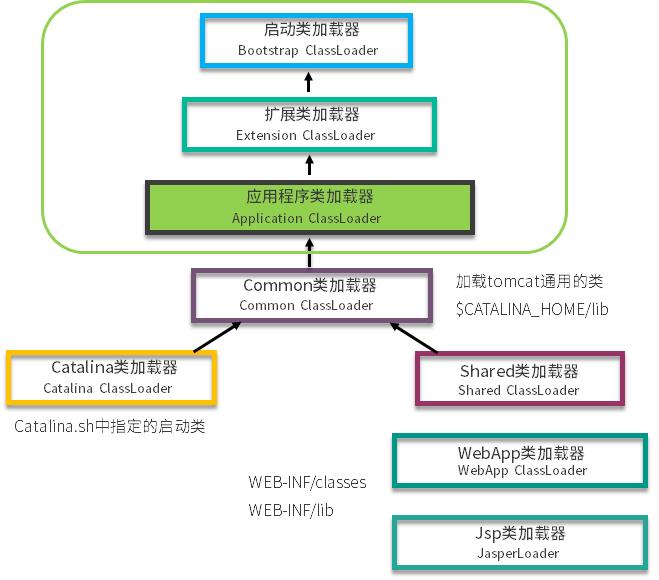
对于一些需要加载的非基础类,会由一个叫作 WebAppClassLoader 的类加载器优先加载。等它加载不到的时候,再交给上层的 ClassLoader 进行加载。这个加载器用来隔绝不同应用的 .class 文件,比如你的两个应用,可能会依赖同一个第三方的不同版本,它们是相互没有影响的。
如何在同一个 JVM 里,运行着不兼容的两个版本,当然是需要自定义加载器才能完成的事。
那么 tomcat 是怎么打破双亲委派机制的呢?可以看图中的 WebAppClassLoader,它加载自己目录下的 .class 文件,并不会传递给父类的加载器。但是,它却可以使用 SharedClassLoader 所加载的类,实现了共享和分离的功能。
但是你自己写一个 ArrayList,放在应用目录里,tomcat 依然不会加载。它只是自定义的加载器顺序不同,但对于顶层来说,还是一样的。
OSGi
OSGi 曾经非常流行,Eclipse 就使用 OSGi 作为插件系统的基础。OSGi 是服务平台的规范,旨在用于需要长运行时间、动态更新和对运行环境破坏最小的系统。
OSGi 规范定义了很多关于包生命周期,以及基础架构和绑定包的交互方式。这些规则,通过使用特殊 Java 类加载器来强制执行,比较霸道。
比如,在一般 Java 应用程序中,classpath 中的所有类都对所有其他类可见,这是毋庸置疑的。但是,OSGi 类加载器基于 OSGi 规范和每个绑定包的 manifest.mf 文件中指定的选项,来限制这些类的交互,这就让编程风格变得非常的怪异。但我们不难想象,这种与直觉相违背的加载方式,肯定是由专用的类加载器来实现的。
随着 jigsaw 的发展(旨在为 Java SE 平台设计、实现一个标准的模块系统),我个人认为,现在的 OSGi,意义已经不是很大了。OSGi 是一个庞大的话题,你只需要知道,有这么一个复杂的东西,实现了模块化,每个模块可以独立安装、启动、停止、卸载,就可以了。
SPI
Java 中有一个 SPI 机制,全称是 Service Provider Interface,是 Java 提供的一套用来被第三方实现或者扩展的 API,它可以用来启用框架扩展和替换组件。
后面会专门针对这个写一篇文章,这里就不细说了。
双亲委派模型为什么安全?
前面谈到双亲委派机制是为了安全而设计的,但是为什么就安全了呢?举个例子,ClassLoader加载的class文件来源很多,比如编译器编译生成的class、或者网络下载的字节码。
而一些来源的class文件是不可靠的,比如我可以自定义一个java.lang.Integer类来覆盖jdk中默认的Integer类,例如下面这样:
package java.lang;
/**
* @author 田维常
* @version 1.0
* @date 2020/11/7 21:18
*/
public class Integer {
public Integer(int value) {
System.exit(0);
}
public static void main(String[] args) {
Integer i = new Integer(1);
System.err.println(i);
}
}
初始化这个Integer的构造器是会退出JVM,破坏应用程序的正常进行,如果使用双亲委派机制的话,该Integer类永远不会被调用,以为委托BootStrapClassLoader加载后会加载JDK中的Integer类而不会加载自定义的这个,运行main方法,程序并没有执行System.exit(0);
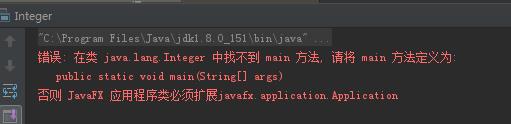
这里使用的是rt.jar里的Integer,并没有使用我们自定义的Integer类,这个案例和前面的能不能自定义一个String类完全一样,这样就保证了安全性。
运行数据区
运行时数据区的五个模块
[1. The pc Register]程序计数器/寄存器
[2. Java Virtual Machine Stacks]Java虚拟机栈
[3. Heap]堆
[4. Method Area] 方法区
[5. Native Method Stacks]本地方法栈
什么是方法区
方法区是用于存储类结构信息的地方,线程共享,包括常量池、静态变量、构造函数等类型信息,类型信息是由类加载器在类加载时从类.class文件中提取出来的。
官网的介绍;
https://docs.oracle.com/javase/specs/jvms/se8/html/jvms-2.html#jvms-2.5.1

从上面的介绍中,我们大致可以得出以下结论:
-
方法区是各个线程共享的内存区域,在虚拟机启动时创建,生命周期和JVM生命周期一样。 -
用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。 -
虽然Java虚拟机规范把方法区描述为堆的一个逻辑部分,但是它却又一个别名叫做Non-Heap(非堆),目 的是与Java堆区分开来。 -
当方法区无法满足内存分配需求时,将抛出OOM=OutOfMemoryError异常。
用一段代码来加深印象:
/**
* @author 老田
* @version 1.0
* @date 2020/11/5 12:55
*/
public class User {
private static String a = "";
private static final int b = 10;
}
User.class类信息,以及静态变量a,常量b等信息是存放在方法区的。方法区的实现通常有两种:JDK8前的永久代,以及JDK8后的元空间。
什么是寄存器?
The pc Register 也有的翻译为pc寄存器。下面是官网对寄存器的解释,做了一个简要的翻译。
The Java Virtual Machine can support many threads of execution at once (JLS §17).
Java虚拟机支持多线程并发
Each Java Virtual Machine thread has its own pc (program counter) register.
每个Java虚拟机线程都拥有一个寄存器
At any point, each Java Virtual Machine thread is executing the code of a single method, namely the current method (§2.6) for that thread.
在任何时候,每个Java虚拟机线程都在执行单个方法的代码,即该线程的当前方法
If that method is not native, the pc register contains the address of the Java Virtual Machine instruction currently being executed.
如果线程正在执行Java方法,则计数器记录的是正在执行的虚拟机字节码指令的地址;
If the method currently being executed by the thread is native, the value of the Java Virtual Machine's pc register is undefined.
如果正在执行的是Native方法,则这个计数器为空。
The Java Virtual Machine's pc register is wide enough to hold a returnAddress or a native pointer on the specific platform.
Java虚拟机的pc寄存器足够宽,可以容纳特定平台上的返回地址或本机指针。
实际上,程序计数器占用的内存空间很小,由于Java虚拟机的多线程是通过线程轮流切换,并分配处理器执行时间的方式来实现的,在任意时刻,一个处理器只会执行一条线程中的指令。因此,为了线程切换后能够恢复到正确的执行位置,每条线程需要有一个独立的程序计数器(线程私有)。
我们都知道一个JVM进程中有多个线程在执行,而线程中的内容是否能够拥有执行权,是根据CPU调度来的。
假如线程A正在执行到某个地方,突然失去了CPU的执行权,切换到线程B了,然后当线程A再获得CPU执行权的时候,怎么能继续执行呢?
这就是需要在线程中维护一个变量,记录线程执行到的位置,记录本次已经执行到哪一行代码了,当CPU切换回来时候,再从这里继续执行。
什么是堆?
堆是Java虚拟机所管理内存中最大的一块,在虚拟机启动时创建,被所有线程共享。Java对象实例以及数组基本上都在堆上分配。官网介绍:
The Java Virtual Machine has a heap that is shared among all Java Virtual Machine threads.
JVM中的所有线程共享这个堆。
The heap is the run-time data area from which memory for all class instances and arrays is allocated.
所有的Java对象实例以及数组都在堆上分配。
The heap is created on virtual machine start-up
在虚拟机启动时创建
在前面类加载阶段我们已经聊过了,在Java堆中生成一个代表这个类的java.lang.Class对象,作为对方法区中这些数据的访问入口。
堆在JDK1.7和JDK1.8的变化
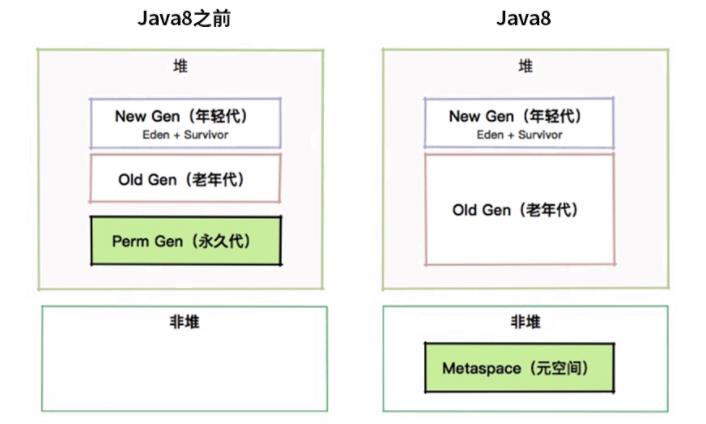
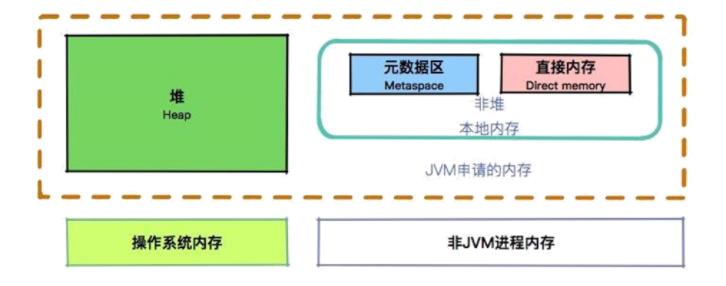
大家都知道,JVM 在运行时,会从操作系统申请大块的堆内内存,进行数据的存储。但是,堆外内存也就是申请后操作系统剩余的内存,也会有部分受到 JVM 的控制。比较典型的就是一些 native 关键词修饰的方法,以及对内存的申请和处理。
在 JVM中,堆被划分成两个不同的区域:新生代 ( Young)、老年代 ( Old)。
新生代 ( Young ) 又被划分为三个区域:Eden区、From Survivor区、To Survivor区。
注意:很多的文章或者书籍里也称From Survivor区为S0区,To Survivor区为S1区。
这样划分的目的是为了使JVM能够更好的管理堆内存中的对象,包括内存的分配以及回收。
根据之前对于Heap的介绍可以知道,一般对象和数组的创建会在堆中分配内存空间,关键是堆中有这么多区 域,那一个对象的创建到底在哪个区域呢?
对象创建所在区域
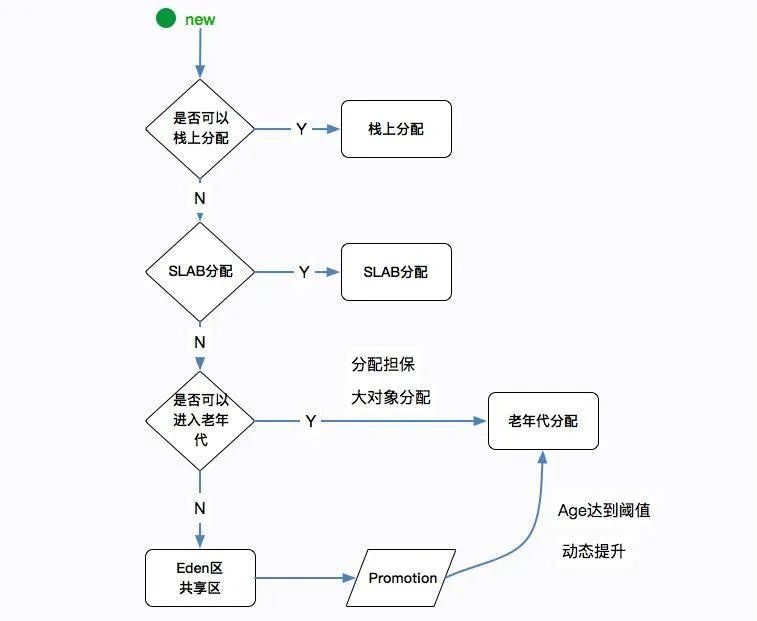
一般情况下,新创建的对象都会被分配到Eden区(朝生夕死),一些特殊的大的对象会直接分配到Old区。
比如有对象A,B,C等创建在Eden区,但是Eden区的内存空间肯定有限,比如有100M,假如已经使用了
100M或者达到一个设定的临界值,这时候就需要对Eden内存空间进行清理,即垃圾收集(Garbage Collect),
这样的GC我们称之为Minor GC,Minor GC指得是Young区的GC。
经过GC之后,有些对象就会被清理掉,有些对象可能还存活着,对于存活着的对象需要将其复制到Survivor
区,然后再清空Eden区中的这些对象。
TLAB的全称是 Thread Local Allocation Buffer,JVM默认给每个线程开辟一个 buffer 区域,用来加速对象分配。这个 buffer 就放在 Eden 区中。
这个道理和 Java 语言中的ThreadLocal类似,避免了对公共区的操作,以及一些锁竞争。
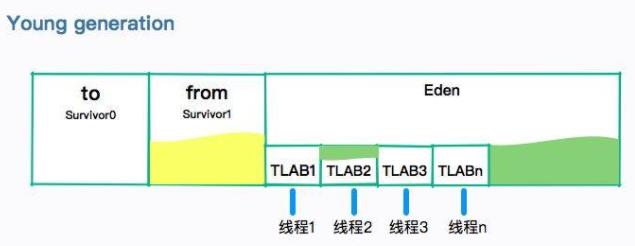
对象的分配优先在TLAB上 分配,但 TLAB通常都很小,所以对象相对比较大的时候,会在 Eden 区的共享区域进行分配。
TLAB是一种优化技术,类似的优化还有对象的栈上分配(这可以引出逃逸分析的话题,默认开启)。这属于非常细节的优化,不做过多介绍,但偶尔面试也会被问到。
Survivor区详解
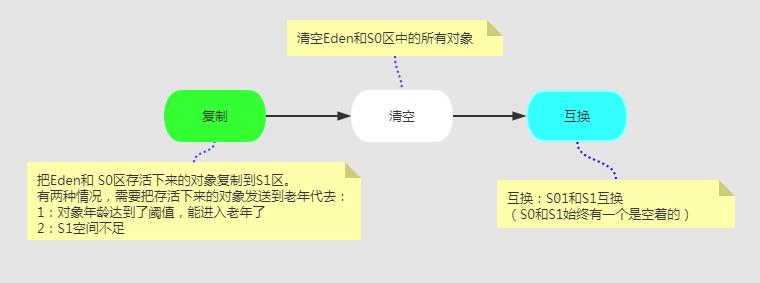
由图解可以看出,Survivor区分为两块S0和S1,也可以叫做From和To。在同一个时间点上,S0和S1只能有一个区有数据,另外一个是空的。
接着上面的GC来说,比如一开始只有Eden区和From中有对象,To中是空的。
此时进行一次GC操作,From区中对象的年龄就会+1,我们知道Eden区中所有存活的对象会被复制到To区,From区中还能存活的对象会有两个去处。
若对象年龄达到之前设置好的年龄阈值(默认年龄为15岁,可以自行设置参数‐XX:+MaxTenuringThreshold),此时对象会被移动到Old区, 如果Eden区和From区 没有达到阈值的对象会被复制到To区。
此时Eden区和From区已经被清空(被GC的对象肯定没了,没有被GC的对象都有了各自的去处)。
这时候From和To交换角色,之前的From变成了To,之前的To变成了From。也就是说无论如何都要保证名为To的Survivor区域是空的。
Minor GC会一直重复这样的过程,知道To区被填满,然后会将所有对象复制到老年代中。
Old区
从上面的分析可以看出,一般Old区都是年龄比较大的对象,或者相对超过了某个阈值(-XX:PretenureSizeThreshold,默认为15,表示全部进Eden区)的对象。在Old区也会有GC的操作,Old区的GC我们称作为Major GC。
什么是虚拟机栈?
Java虚拟机栈,是线程私有。
每一个线程拥有一个虚拟机栈,每一个栈包含n个栈帧,每个栈帧对应一次一个放调用,
每个栈帧里包含:局部变量表、操作数栈、动态链接、方法出口。
官网介绍
Each Java Virtual Machine thread has a private Java Virtual Machine stack, created at the same time as the thread.
一个线程的创建也就同事创建一个java虚拟机栈
A Java Virtual Machine stack stores frames (§2.6).
Java虚拟机堆栈存储帧
The memory for a Java Virtual Machine stack does not need to be contiguous.
Java虚拟机堆栈的内存不需要是连续的。
看一段代码
public class JavaStackDemo {
private void checkParam(String passWd, String userName) {
// TODO: 2020/11/6 用户名和密码校验
}
private void getUserName(String passWd, String userName) {
checkParam(passWd, userName);
}
private void login(String passWd, String userName) {
getUserName(passWd, userName);
}
public static void main(String[] args) {
//这里是演示代码,希望大家能结合自己平时写的代码理解,那样会更爽
//你就不再死记硬背了
JavaStackDemo javaStackDemo = new JavaStackDemo();
javaStackDemo.login("老田", "111111");
}
}
启动main方法就是启动了一个线程,JVM中会对应给这个线程创建一个栈。
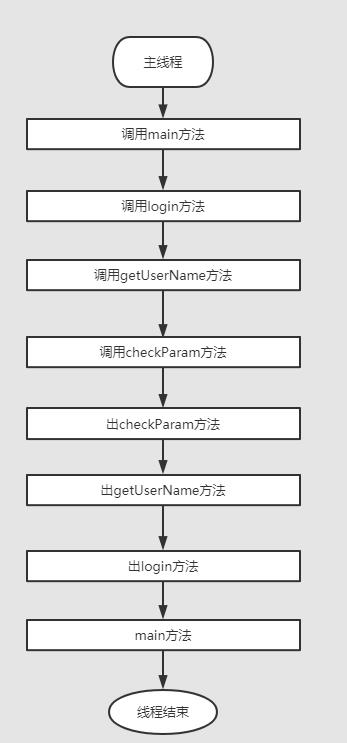
从这个调用过程很容易发现是个先进后出的结构,刚好栈的结构就是这样的。java虚拟机栈就是这么设计的:
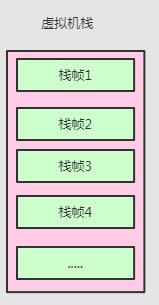
每个栈帧表示一个方法的调用:进入方法表示栈帧入栈,栈帧出栈表示方法调用结束。
多线程的话就是这样了:
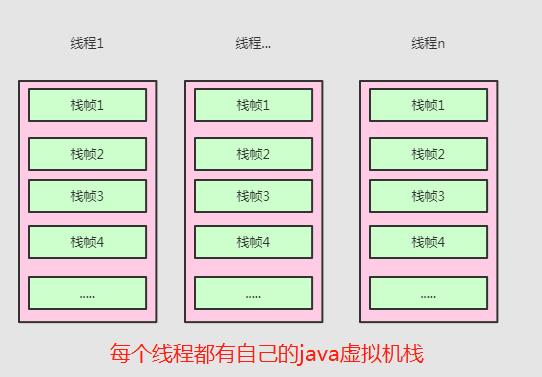
从上面这个图大家会不会觉得这个栈有问题?其实也是有问题的,比如说看下面这段代码
/**
* TODO
*
* @author 田维常
* @version 1.0
* @date 2020/11/6 9:05
*/
public class JavaStackDemo {
public static void main(String[] args) {
JavaStackDemo javaStackDemo = new JavaStackDemo();
javaStackDemo.test();
}
//循环调用test方法
private void test(){
test();
}
}
调用过程如下图:
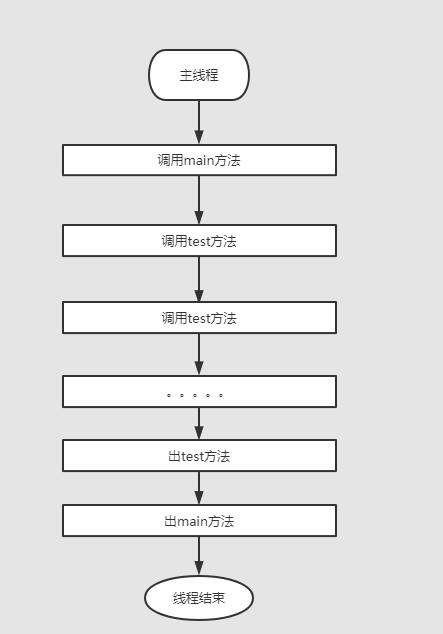
是不是觉得很无语,调用方法就往栈里加入一个栈帧,这么下去,这个栈得需要多深才能放下,死循环和无限递归呢,岂不是栈里需要无限深度吗?
Java虚拟机栈大小肯定是有限的,所以就会导致一个大家都听说过的栈溢出。
运行上面的代码:
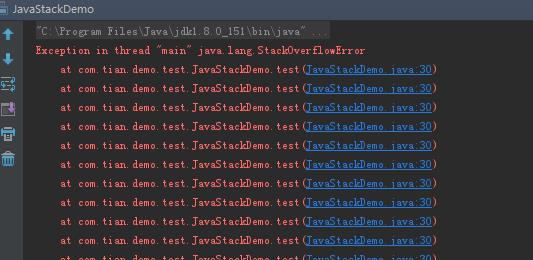
如何设置Java虚拟机栈的大小呢?
我们可以使用虚拟机参数-Xss 选项来设置线程的最大栈空间,栈的大小直接决定了函数调用的最大可达深度;-Xss size 设置线程堆栈大小(以字节为单位)。附加字母k或K表示KB,m或M表示MB,和g或G表示GB。默认值取决于平台:
-
Linux / x64(64位):1024 KB -
macOS(64位):1024 KB -
Oracle Solaris / x64(64位):1024 KB -
Windows:默认值取决于虚拟内存
下面的示例以不同的单位将线程堆栈大小设置为1024 KB:
-Xss1m (1mb)
-Xss1024k (1024kb)
-Xss1048576
回到上面的话题。
什么是栈帧?
上面提到过,调用方法就生成一个栈帧,然后入栈。
看一段代码
public class JavaStackDemo {
public static void main(String[] args) {
JavaStackDemo javaStackDemo = new JavaStackDemo();
javaStackDemo.getUserType(21);
}
public String getUserType(int age) {
int temp = 18;
if (age < temp) {
return "未成年人";
}
//动态链接
//userService.xx();
return "成年人";
}
}
既然是和方法有关,那么就可以联想到方法里都有些什么
官网介绍
Each frame has its own array of local variables , its own operand stack (§2.6.2), and a reference to the run-time constant pool of the class of the current method.
每个栈帧拥有自己的本地变量。比如上面代码里的
int age、int temp
这些都是本地变量。
每个栈帧都有自己的操作数栈
通过javac编译好JavaStackDemo,然后使用
javap -v JavaStackDemo.class >log.txt
将字节码导入到log.txt中,打开
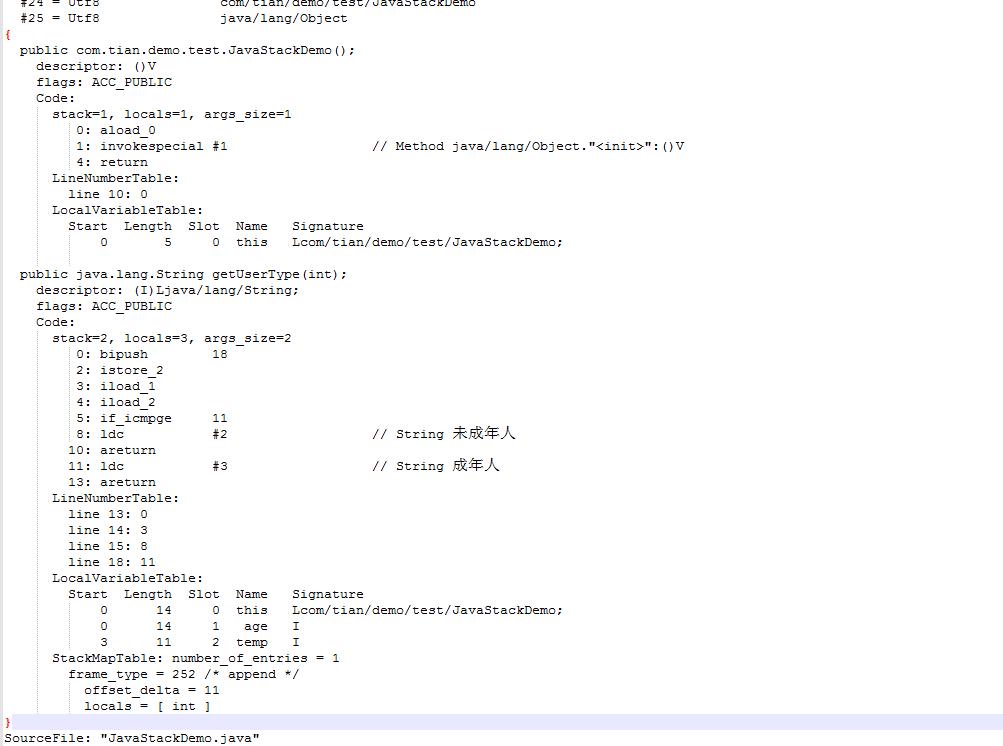
对getUserType方法里面的字节码做一个解释。有时候本地变量通过javap看不到,可以再javac的时候添加一个参数
javac -g:vars XXX.class这样就可以把本地变量表给输出来了。
指令bipush 18 将18压入操作数栈
istore_2 将栈顶int型数值存入第三个本地变量
iload_1 将第二个int型本地变量推送至栈顶
iload_2 将第三个int型本地变量推送至栈顶
if_icmpge 比较栈顶两int型数值大小, 当结果大于等于0时跳转
ldc 将int,float或String型常量值从常量池中推送至栈顶
areturn 从当前方法返回对象引用
官网
https://docs.oracle.com/javase/specs/jvms/se8/html/

这些都是字节码指令。
LocalVariableTable 本地变量表
Start Length Slot Name Signature
0 14 0 this Lcom/tian/demo/test/JavaStackDemo;
0 14 1 age I
3 11 2 temp I
自己this算一个本地变量,入参age算一个本地变量,方法中的临时变量temp也算一个本地变量。
方法出口
return。如果方法不需要返回void的时候,其实方法里是默认会为其加上一个return;
另外方法的返回分两种:
-
正常代码执行完毕然后return。
-
遇到异常结束
栈帧总结
-
方法出口:return或者程序异常
-
局部变量表:保存局部变量
-
操作数栈:保存每次赋值、运算等信息
-
动态链接:相对于C/C++的静态连接而言,静态连接是将所有类加载,不论是否使用到。而动态链接是要用到某各类的时候在加载到内存里。静态连接速度快,动态链接灵活性更高。
什么是本地方法栈?
Native Method Stacks 翻译过来就是本地方法栈,与Java虚拟机栈一样,但这里的栈是针对native修饰的方法的,比如System、Unsafe、Object类中的相关native方法。
public class Object {
//native修饰的方法
private static native void registerNatives();
public final native Class<?> getClass();
public native int hashCode();
protected native Object clone() throws CloneNotSupportedException;
public final native void notify();
//.......
}
public final class System {
//native修饰的方法
private static native void registerNatives();
static {
registerNatives();
}
public static native long currentTimeMillis();
private static native void setIn0(InputStream in);
private static native void setOut0(PrintStream out);
private static native void setErr0(PrintStream err);
//.....
}
public final class Unsafe {
//native修饰的方法
private static native void registerNatives();
public native int getInt(Object var1, long var2);
public native void putInt(Object var1, long var2, int var4);
public native Object getObject(Object var1, long var2);
public native void putObject(Object var1, long var2, Object var4);
public native boolean getBoolean(Object var1, long var2);
//...
}
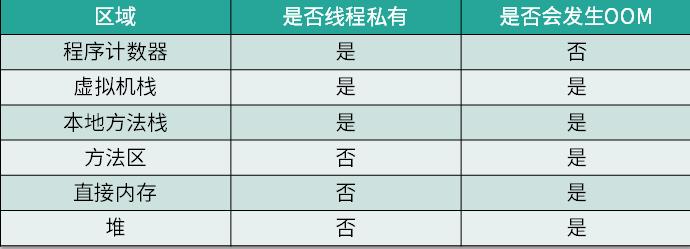
面试常问:JVM运行时区那些和线程有直接的关系和间接的关系,哪些区会发生OOM?
每个区域是否为线程共享,是否会发生OOM
如何判断对象是垃圾对象?
引用计数法
给对象添加一个引用计数器,每当一个地方引用它object时技术加1,引用失去以后就减1,计数为0说明不再引用。
-
优点:实现简单,判定效率高 -
缺点:无法解决对象相互循环引用的问题,对象A中引用了对象B,对象B中引用对象A。
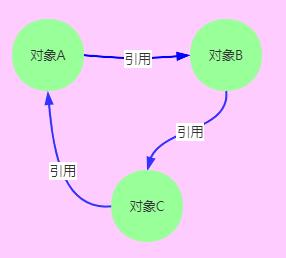
public class A {
public B b;
}
public class B {
public C c;
}
public class C {
public A a;
}
public class Test{
private void test(){
A a = new A();
B b = new B();
C c = new C();
a.b=b;
b.c=c;
c.a=a;
}
}
可达性分析算法
当一个对象到GC Roots没有引用链相连,即就是GC Roots到这个对象不可达时,证明对象不可用。
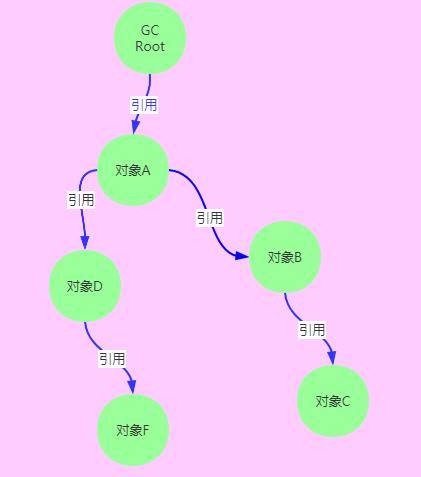
GC Roots种类
-
Java 线程中,当前所有正在被调用的方法的引用类型参数、局部变量、临时值等。也就是与我们栈帧相关的各种引用。
-
所有当前被加载的 Java 类。
-
Java 类的引用类型静态变量。
-
运行时常量池里的引用类型常量(String 或 Class 类型)。
-
JVM 内部数据结构的一些引用,比如 sun.jvm.hotspot.memory.Universe 类。
-
用于同步的监控对象,比如调用了对象的 wait() 方法。
public class Test{
private void test(C c){
A a = new A();
B b = new B();
a.b=b;
//这里的a/b/c都是GC Root;
}
}
对象的引用类型有哪些?
-
强引用:User user=new User();我们开发中使用最多的对象引用方式。特点:我们平常典型编码Object obj = new Object()中的obj就是强引用。通过关键字new创建的对象所关联的引用就是强引用。当JVM内存空间不足,JVM宁愿抛出OutOfMemoryError运行时错误(OOM),使程序异常终止,也不会靠随意回收具有强引用的“存活”对象来解决内存不足的问题。对于一个普通的对象,如果没有其他的引用关系,只要超过了引用的作用域或者显式地将相应(强)引用赋值为 null,就是可以被垃圾收集的了,具体回收时机还是要看垃圾收集策略。 -
软引用:SoftReference object=new SoftReference(new Object()); 特点:软引用通过SoftReference类实现。软引用的生命周期比强引用短一些。只有当 JVM 认为内存不足时,才会去试图回收软引用指向的对象:即JVM 会确保在抛出 OutOfMemoryError 之前,清理软引用指向的对象。软引用可以和一个引用队列(ReferenceQueue)联合使用,如果软引用所引用的对象被垃圾回收器回收,Java虚拟机就会把这个软引用加入到与之关联的引用队列中。后续,我们可以调用ReferenceQueue的poll()方法来检查是否有它所关心的对象被回收。如果队列为空,将返回一个null,否则该方法返回队列中前面的一个Reference对象。应用场景:软引用通常用来实现内存敏感的缓存。如果还有空闲内存,就可以暂时保留缓存,当内存不足时清理掉,这样就保证了使用缓存的同时,不会耗尽内存。 -
弱引用:WeakReference object=new WeakReference (new Object();ThreadLocal中有使用. 弱引用通过WeakReference类实现。弱引用的生命周期比软引用短。在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。由于垃圾回收器是一个优先级很低的线程,因此不一定会很快回收弱引用的对象。弱引用可以和一个引用队列(ReferenceQueue)联合使用,如果弱引用所引用的对象被垃圾回收,Java虚拟机就会把这个弱引用加入到与之关联的引用队列中。应用场景:弱应用同样可用于内存敏感的缓存。 -
虚引用:几乎没见过使用, ReferenceQueue 、PhantomReference -
缺点:标记和清除效率不高,标记和清除之后会产生大量不连续的内存碎片 -
缺点:对象存活率高时,复制效率会较低,浪费内存。
finalize()方法有什么作用?
这个方法就有点类似,某个人被拍了死刑,但是不一定会死。
即使在可达性分析算法中不可达的对象,也并非一定是“非死不可”的,这时候他们暂时处于“缓刑”阶段,真正宣告一个对象死亡至少要经历两个阶段:
1、如果对象在可达性分析算法中不可达,那么它会被第一次标记并进行一次刷选,刷选的条件是是否需要执行finalize()方法(当对象没有覆盖finalize()或者finalize()方法已经执行过了(对象的此方法只会执行一次)),虚拟机将这两种情况都会视为没有必要执行)。
2、如果这个对象有必要执行finalize()方法会将其放入F-Queue队列中,稍后GC将对F-Queue队列进行第二次标记,如果在重写finalize()方法中将对象自己赋值给某个类变量或者对象的成员变量,那么第二次标记时候就会将它移出“即将回收”的集合。
垃圾回收算法有哪些?
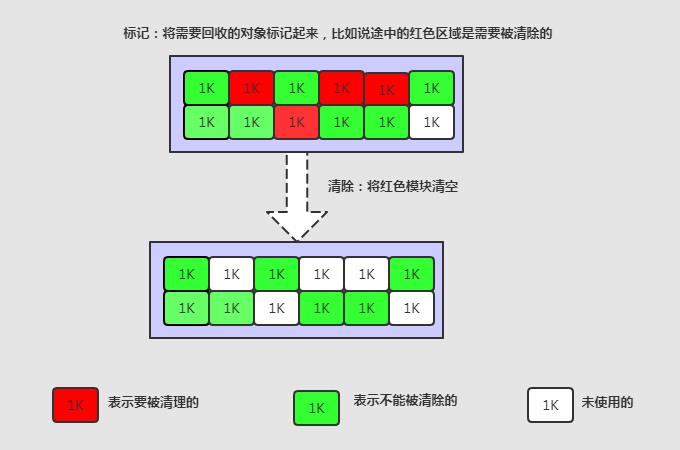
标记-清除
第一步:就是找出活跃的对象。我们反复强调 GC 过程是逆向的, 根据 GC Roots 遍历所有的可达对象,这个过程,就叫作标记。
第二部:除了上面标记出来的对象以外,其余的都清楚掉。
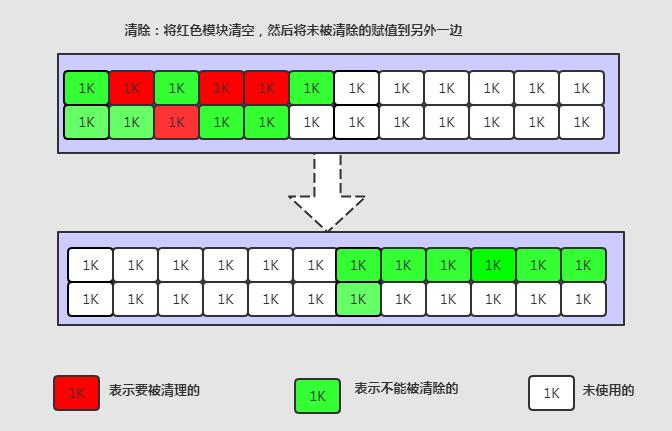
复制
新生代使用,新生代分中Eden:S0:S1= 8:1:1,其中后面的1:1就是用来复制的。
当其中一块内存使用完了,就将还存活的对象复制到另外一块上面,然后把已经使用过的内存空间一次
清除掉。
一般对象分配都是进入新生代的eden区,如果Minor GC还存活则进入S0区,S0和S1不断对象进行复制。对象存活年龄最大默认是15,大对象进来可能因为新生代不存在连续空间,所以会直接接入老年代。任何使用都有新生代的10%是空着的。
标记整理
让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存。
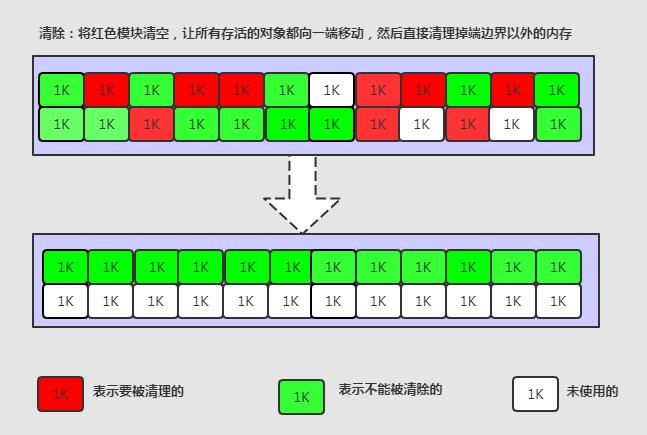
从上面的三个算法来看,其实没有绝对最好的回收算法,只有最适合的算法。
垃圾收集器
垃圾收集器就是垃圾回收算法的实现,下面就来聊聊现目前有哪些垃圾收集器。
新生代有哪些垃圾收集器
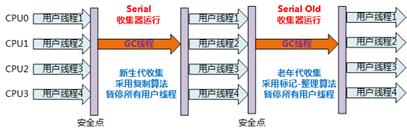
serial
Serial收集器是最基本、发展历史最悠久的收集器,曾经(在JDK1.3.1之前)是虚拟机新生代收集的唯一选择。
它是一种单线程收集器,不仅仅意味着它只会使用一个CPU或者一条收集线程去完成垃圾收集工作,更重要的是其在进行垃圾收集的时候需要暂停其他线程。
优点:简单高效,拥有很高的单线程收集效率
缺点:收集过程需要暂停所有线程
算法:复制算法
应用:Client模式下的默认新生代收集器
收集过程:
ParNew
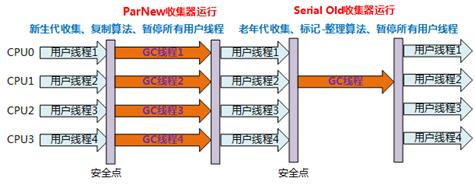
可以把这个收集器理解为Serial收集器的多线程版本。
优点:在多CPU时,比Serial效率高。
缺点:收集过程暂停所有应用程序线程,单CPU时比Serial效率差。
算法:复制算法
应用:运行在Server模式下的虚拟机中首选的新生代收集器
收集过程:
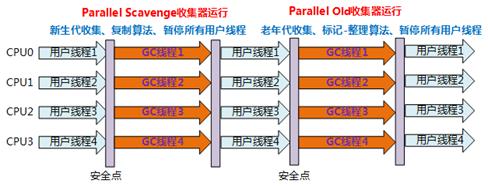
Parallel Scanvenge
Parallel Scavenge收集器是一个新生代收集器,它也是使用复制算法的收集器,又是并行的多线程收集
器,看上去和ParNew一样,但是Parallel Scanvenge更关注 系统的吞吐量 ;
吞吐量 = 运行用户代码的时间 / (运行用户代码的时间 + 垃圾收集时间)
比如虚拟机总共运行了120秒,垃圾收集时间用了1秒,吞吐量=(120-1)/120=99.167%。
若吞吐量越大,意味着垃圾收集的时间越短,则用户代码可以充分利用CPU资源,尽快完成程序的运算任务。
可设置参数:
-XX:MaxGCPauseMillis控制最大的垃圾收集停顿时间,
-XX:GC Time Ratio直接设置吞吐量的大小。
老年代有哪些垃圾收集器
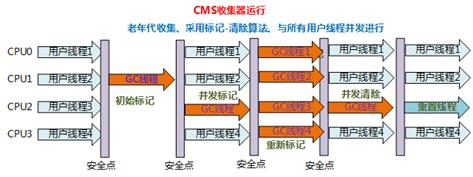
CMS=Concurrent Mark Sweep
特点:最短回收停顿时间,
回收算法:标记-清除
回收步骤:
-
初始标记:标记GC Roots直接关联的对象,速度快 -
并发标记:GC Roots Tracing过程,耗时长,与用户进程并发工作 -
重新标记:修正并发标记期间用户进程运行而产生变化的标记,好事比初始标记长,但是远远小于并发标记 -
表发清除:清除标记的对象
缺点:对CPU资源非常敏感,CPU少于4个时,CMS岁用户程序的影响可能变得很大,有此虚拟机提供了“增量式并发收集器”;无法回收浮动垃圾;采用标记清除算法会产生内存碎片,不过可以通过参数开启内存碎片的合并整理。
收集过程:
serial old
Serial Old收集器是Serial收集器的老年代版本,也是一个单线程收集器,不同的是采用"标记-整理算
法",运行过程和Serial收集器一样。
适用场景:JDK1.5前与Parallel Scanvenge配合使用,作为CMS的后备预案;
收集过程:
Parallel old
Parallel Old收集器是Parallel Scavenge收集器的老年代版本,使用多线程和"标记-整理算法"进行垃圾
回收,吞吐量优先;
回收算法:标记-整理
适用场景:为了替代serial old与Parallel Scanvenge配合使用
收集过程:
G1 收集器
G1(Garbage first) 收集器是 jdk1.7 才正式引用的商用收集器,现在已经成为JDK9 默认的收集器。前面几款收集器收集的范围都是新生代或者老年代,G1 进行垃圾收集的范围是整个堆内存,它采用 “ 化整为零 ” 的思路,把整个堆内存划分为多个大小相等的独立区域(Region),在 G1 收集器中还保留着新生代和老年代的概念,它们分别都是一部分 Region,如下图:
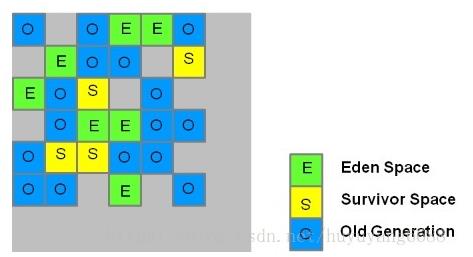
每一个方块就是一个区域,每个区域可能是 Eden、Survivor、老年代,每种区域的数量也不一定。JVM 启动时会自动设置每个区域的大小(1M ~ 32M,必须是 2 的次幂),最多可以设置 2048 个区域(即支持的最大堆内存为 32M*2048 = 64G),假如设置 -Xmx8g -Xms8g,则每个区域大小为 8g/2048=4M。
为了在 GC Roots Tracing 的时候避免扫描全堆,在每个 Region 中,都有一个 Remembered Set 来实时记录该区域内的引用类型数据与其他区域数据的引用关系(在前面的几款分代收集中,新生代、老年代中也有一个 Remembered Set 来实时记录与其他区域的引用关系),在标记时直接参考这些引用关系就可以知道这些对象是否应该被清除,而不用扫描全堆的数据。
G1 收集器可以 “ 建立可预测的停顿时间模型 ”,它维护了一个列表用于记录每个 Region 回收的价值大小(回收后获得的空间大小以及回收所需时间的经验值),这样可以保证 G1 收集器在有限的时间内可以获得最大的回收效率。
如下图所示,G1 收集器收集器收集过程有初始标记、并发标记、最终标记、筛选回收,和 CMS 收集器前几步的收集过程很相似:
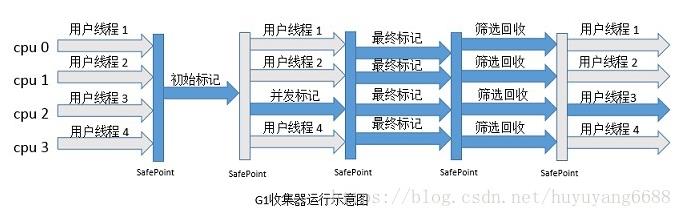
① 初始标记:标记出 GC Roots 直接关联的对象,这个阶段速度较快,需要停止用户线程,单线程执行。
② 并发标记:从 GC Root 开始对堆中的对象进行可达新分析,找出存活对象,这个阶段耗时较长,但可以和用户线程并发执行。
③ 最终标记:修正在并发标记阶段引用户程序执行而产生变动的标记记录。
④ 筛选回收:筛选回收阶段会对各个 Region 的回收价值和成本进行排序,根据用户所期望的 GC 停顿时间来指定回收计划(用最少的时间来回收包含垃圾最多的区域,这就是 Garbage First 的由来——第一时间清理垃圾最多的区块),这里为了提高回收效率,并没有采用和用户线程并发执行的方式,而是停顿用户线程。
适用场景:要求尽可能可控 GC 停顿时间;内存占用较大的应用。可以用 -XX:+UseG1GC 使用 G1 收集器,jdk9 默认使用
ZGC收集器
ZGC有什么特点?
ZGC 是最新的 JDK1.11 版本中提供的高效垃圾回收算法,ZGC 针对大堆内存设计可以支持 TB 级别的堆,ZGC 非常高效,能够做到 10ms 以下的回收停顿时间。
这么快的响应,ZGC 是如何做到的呢?这是由于 ZGC 具有以下特点。
-
第一个:ZGC 使用了着色指针技术,我们知道 64 位平台上,一个指针的可用位是 64 位,ZGC 限制最大支持 4TB 的堆,这样寻址只需要使用 42 位,那么剩下 22 位就可以用来保存额外的信息,着色指针技术就是利用指针的额外信息位,在指针上对对象做着色标记。 -
第二个:使用读屏障,ZGC 使用读屏障来解决 GC 线程和应用线程可能并发修改对象状态的问题,而不是简单粗暴的通过 STW 来进行全局的锁定。使用读屏障只会在单个对象的处理上有概率被减速。 -
第三个:由于读屏障的作用,进行垃圾回收的大部分时候都是不需要 STW 的,因此 ZGC 的大部分时间都是并发处理,也就是 ZGC 的第三个特点。 -
第四个:基于 Region,这与 G1 算法一样,不过虽然也分了 Region,但是并没有进行分代。ZGC 的 Region 不像 G1 那样是固定大小,而是动态地决定 Region 的大小,Region 可以动态创建和销毁。这样可以更好的对大对象进行分配管理。 -
第五个:压缩整理。CMS 算法清理对象时原地回收,会存在内存碎片问题。ZGC 和 G1 一样,也会在回收后对 Region 中的对象进行移动合并,解决了碎片问题。
虽然 ZGC 的大部分时间是并发进行的,但是还会有短暂的停顿。来看一下 ZGC 的回收过程。
ZGC 是如何进行垃圾收集的?
ZGC(Z Garbage Collector)是一款由Oracle公司研发的,以低延迟为首要目标的一款垃圾收集器。它是基于动态Region内存布局,(暂时)不设年龄分代,使用了读屏障、染色指针和内存多重映射等技术来实现可并发的标记-整理算法的收集器。
初始状态时,整个堆空间被划分为大小不等的许多 Region,即图中绿色的方块。
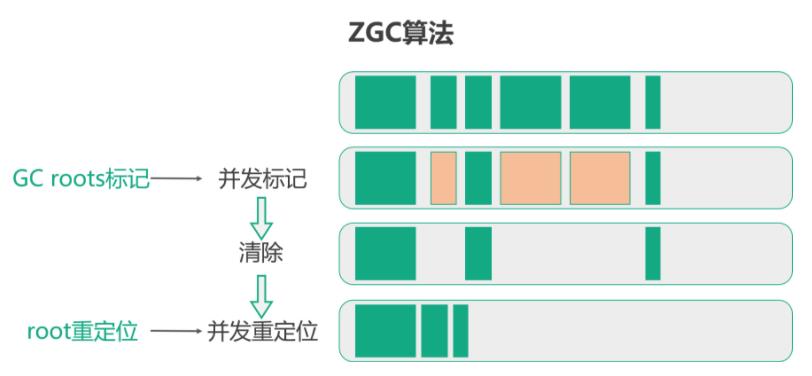
开始进行回收时,ZGC 首先会进行一个短暂的 STW(Stop The world),来进行 roots 标记。这个步骤非常短,因为 roots 的总数通常比较小。
然后就开始进行并发标记,如上图所示,通过对对象指针进行着色来进行标记,结合读屏障解决单个对象的并发问题。其实,这个阶段在最后还是会有一个非常短的 STW 停顿,用来处理一些边缘情况,这个阶段绝大部分时间是并发进行的,所以没有明显标出这个停顿。
下一个是清理阶段,这个阶段会把标记为不在使用的对象进行回收,如上图所示,把橘色的不在使用的对象进行了回收。
最后一个阶段是重定位,重定位就是对 GC 后存活的对象进行移动,来释放大块的内存空间,解决碎片问题。
重定位最开始会有一个短暂的 STW,用来重定位集合中的 root 对象。暂停时间取决于 root 的数量、重定位集与对象的总活动集的比率。
最后是并发重定位,这个过程也是通过读屏障,与应用线程并发进行的。
性能调优
熟悉哪些JVM调优参数
X或者XX开头的都是非转标准化参数:
意思就是说准表化参数不会变,非标准化参数可能在每个JDK版本中有所变化,但是就目前来看X开头的非标准化的参数改变的也是非常少。
格式:-XX:[+-]<name> 表示启用或者禁用name属性。
例子:-XX:+UseG1GC(表示启用G1垃圾收集器)
堆设置
-
-Xms 初始堆大小,ms是memory start的简称 ,等价于-XX:InitialHeapSize
-
-Xmx 最大堆大小,mx是memory max的简称 ,等价于参数-XX:MaxHeapSize
注意:在通常情况下,服务器项目在运行过程中,堆空间会不断的收缩与扩张,势必会造成不必要的系统压力。所以在生产环境中,JVM的Xms和Xmx要设置成一样的,能够避免GC在调整堆大小带来的不必要的压力。
-
-XX:NewSize=n 设置年轻代大小
-
-XX:NewRatio=n 设置年轻代和年老代的比值。如:-XX:NewRatio=3,表示年轻代与年老代比值为1:3,年轻代占整个年轻代年老代和的1/4,默认新生代和老年代的比例=1:2。
-
-XX:SurvivorRatio=n 年轻代中Eden区与两个Survivor区的比值。注意Survivor区有两个,默认是8,表示
Eden:S0:S1=8:1:1
如:-XX:SurvivorRatio=3,表示Eden:Survivor=3:2,一个Survivor区占整个年轻代的1/5。
-
-XX:MaxPermSize=n 设置持久代大小
-
-XX:MetaspaceSize 设置元空间大小
收集器设置
-
-XX:+UseSerialGC 设置串行收集器
-
-XX:+UseParallelGC 设置并行收集器
-
-XX:+UseParalledlOldGC 设置并行年老代收集器
-
-XX:+UseConcMarkSweepGC 设置并发收集器
垃圾回收统计信息
-
-XX:+PrintGC
-
-XX:+PrintGCDetails
-
-XX:+PrintGCTimeStamps
-
-Xloggc:filenameGC日志输出到文件里filename,比如:-Xloggc:/gc.log
并行收集器设置
-
-XX:ParallelGCThreads=n 设置并行收集器收集时使用的CPU数。并行收集线程数。
-
-XX:MaxGCPauseMillis=n 设置并行收集最大暂停时间
-
-XX:GCTimeRatio=n 设置垃圾回收时间占程序运行时间的百分比。公式为1/(1+n)
-
-XX:MaxGCPauseMillis=n设置并行收集最大暂停时间
并发收集器设置
-
-XX:+CMSIncrementalMode 设置为增量模式。适用于单CPU情况。
-
-XX:ParallelGCThreads=n 设置并发收集器年轻代收集方式为并行收集时,使用的CPU数。并行收集线程数。
其他
-
-XX:+PrintCommandLineFlags查看当前JVM设置过的相关参数
Dump异常快照
-
-XX:+HeapDumpOnOutOfMemoryError
-
-XX:HeapDumpPath
-Xms10M -Xmx10M -Xmn2M -XX:SurvivorRatio=8 -XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=D:\study\log_hprof\gc.hprof
-
-XX:OnOutOfMemoryError
表示发生OOM后,运行jconsole.exe程序。这里可以不用加“”,因为jconsole.exe路径Program Files含有空格。利用这个参数,我们可以在系统OOM后,自定义一个脚本,可以用来发送邮件告警信息,可以用来重启系统等等。
-XX:OnOutOfMemoryError="C:\Program Files\Java\jdk1.8.0_151\bin\jconsole.exe"
JVM 调优常见目标
JVM 调优目标:使用较小的内存占用来获得较高的吞吐量或者较低的延迟。
程序在上线前的测试或运行中有时会出现一些大大小小的 JVM 问题,比如 cpu load 过高、请求延迟、tps 降低等,甚至出现内存泄漏(每次垃圾收集使用的时间越来越长,垃圾收集频率越来越高,每次垃圾收集清理掉的垃圾数据越来越少)、内存溢出导致系统崩溃,因此需要对 JVM 进行调优,使得程序在正常运行的前提下,获得更高的用户体验和运行效率。
这里有几个比较重要的指标:
-
内存占用:程序正常运行需要的内存大小。 -
延迟:由于垃圾收集而引起的程序停顿时间。 -
吞吐量:用户程序运行时间占用户程序和垃圾收集占用总时间的比值。
当然,和 CAP 原则一样,同时满足一个程序内存占用小、延迟低、高吞吐量是不可能的,程序的目标不同,调优时所考虑的方向也不同,在调优之前,必须要结合实际场景,有明确的的优化目标,找到性能瓶颈,对瓶颈有针对性的优化,最后进行测试,通过各种监控工具确认调优后的结果是否符合目标。
有哪些调优工具?
JPS
用 jps(JVM process Status)可以查看虚拟机启动的所有进程、执行主类的全名、JVM启动参数,比如当执行了 JPSTest 类中的 main 方法后(main 方法持续执行),执行 jps -l可看到下面的JPSTest类的 pid 为 31354,加上 -v 参数还可以看到JVM启动参数。
jstat
用 jstat(JVM Statistics Monitoring Tool)监视虚拟机信息 jstat -gc pid 500 10:每 500 毫秒打印一次 Java 堆状况(各个区的容量、使用容量、gc 时间等信息),打印 10 次。jstat 还可以以其他角度监视各区内存大小、监视类装载信息等,具体可以 google jstat 的详细用法。
jmap
用 jmap(Memory Map for Java)查看堆内存信息 执行 jmap -histo pid 可以打印出当前堆中所有每个类的实例数量和内存占用,如下,class name 是每个类的类名([B 是 byte 类型,[C是 char 类型,[I 是 int 类型),bytes 是这个类的所有示例占用内存大小,instances 是这个类的实例数量。
执行 jmap -dump 可以转储堆内存快照到指定文件,比如执行:
jmap -dump:format=b,file=/data/jvm/dumpfile_jmap.hprof 3361
可以把当前堆内存的快照转储到 dumpfile_jmap.hprof 文件中,然后可以对内存快照进行分析。
jconsole、jvisualvm
利用 jconsole、jvisualvm 分析内存信息(各个区如 Eden、Survivor、Old 等内存变化情况),如果查看的是远程服务器的 JVM,程序启动需要加上如下参数:
"-Dcom.sun.management.jmxremote=true"
"-Djava.rmi.server.hostname=12.34.56.78"
"-Dcom.sun.management.jmxremote.port=18181"
"-Dcom.sun.management.jmxremote.authenticate=false"
"-Dcom.sun.management.jmxremote.ssl=false"
下图是 jconsole 界面,概览选项可以观测堆内存使用量、线程数、类加载数和 CPU 占用率;内存选项可以查看堆中各个区域的内存使用量和左下角的详细描述(内存大小、GC 情况等);线程选项可以查看当前 JVM 加载的线程,查看每个线程的堆栈信息,还可以检测死锁;VM 概要描述了虚拟机的各种详细参数。
第三方工具
MAT、GChisto、GCViewer、JProfiler、arthas、async-profile。
JVM 调优经验总结
JVM 配置方面,一般情况可以先用默认配置(基本的一些初始参数可以保证一般的应用跑的比较稳定了),在测试中根据系统运行状况(会话并发情况、会话时间等),结合 gc 日志、内存监控、使用的垃圾收集器等进行合理的调整,当老年代内存过小时可能引起频繁 Full GC,当内存过大时 Full GC 时间会特别长。
那么 JVM 的配置比如新生代、老年代应该配置多大最合适呢?答案是不一定,调优就是找答案的过程,物理内存一定的情况下,新生代设置越大,老年代就越小,Full GC 频率就越高,但 Full GC 时间越短;相反新生代设置越小,老年代就越大,Full GC 频率就越低,但每次 Full GC 消耗的时间越大。
建议如下:
-Xms 和 -Xmx 的值设置成相等,堆大小默认为 -Xms 指定的大小,默认空闲堆内存小于 40% 时,JVM 会扩大堆到 -Xmx 指定的大小;空闲堆内存大于 70% 时,JVM 会减小堆到 -Xms 指定的大小。如果在 Full GC 后满足不了内存需求会动态调整,这个阶段比较耗费资源。
-
新生代尽量设置大一些,让对象在新生代多存活一段时间,每次 Minor GC 都要尽可能多的收集垃圾对象,防止或延迟对象进入老年代的机会,以减少应用程序发生 Full GC 的频率。 -
老年代如果使用 CMS 收集器,新生代可以不用太大,因为 CMS 的并行收集速度也很快,收集过程比较耗时的并发标记和并发清除阶段都可以与用户线程并发执行。 -
方法区大小的设置,1.6 之前的需要考虑系统运行时动态增加的常量、静态变量等,1.7 只要差不多能装下启动时和后期动态加载的类信息就行。
代码实现方面,性能出现问题比如程序等待、内存泄漏除了 JVM 配置可能存在问题,代码实现上也有很大关系:
-
避免创建过大的对象及数组:过大的对象或数组在新生代没有足够空间容纳时会直接进入老年代,如果是短命的大对象,会提前出发 Full GC。 -
避免同时加载大量数据,如一次从数据库中取出大量数据,或者一次从 Excel 中读取大量记录,可以分批读取,用完尽快清空引用。 -
当集合中有对象的引用,这些对象使用完之后要尽快把集合中的引用清空,这些无用对象尽快回收避免进入老年代。 -
可以在合适的场景(如实现缓存)采用软引用、弱引用,比如用软引用来为 ObjectA 分配实例:SoftReference objectA=new SoftReference (); 在发生内存溢出前,会将 objectA 列入回收范围进行二次回收,如果这次回收还没有足够内存,才会抛出内存溢出的异常。
避免产生死循环,产生死循环后,循环体内可能重复产生大量实例,导致内存空间被迅速占满。
-
尽量避免长时间等待外部资源(数据库、网络、设备资源等)的情况,缩小对象的生命周期,避免进入老年代,如果不能及时返回结果可以适当采用异步处理的方式等。
总结
本文从认识JDK、JRE、JVM,到编译,类加载,初始化,垃圾回收,性能调优。可以算的是把JVM的整个流程给过了一遍。希望对你有所帮助。
我是老田,专门给大家分享技术知识,欢迎加入我的学习小组。
最后,码字不易,望大家给个赞、在看,谢啦老铁!
以上是关于周末请看:2万字!JVM核心知识总结,赠送18连环炮的主要内容,如果未能解决你的问题,请参考以下文章