Kylin实践—— Kylin架构介绍
Posted 扫地增
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kylin实践—— Kylin架构介绍相关的知识,希望对你有一定的参考价值。
kylin的概念
现在我们重新来看kylin的概念:
Apache Kylin™是一个开源的分布式分析引擎,提供Hadoop/Spark之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay公司开发并贡献到apche开源社区成为顶级项目的,他也是第一个主要由中国人参与开发的顶级apche项目。它能在亚秒内查询巨大的Hive表。分布式分析引擎:说明kylin是可以搭建集群,支持大规模的查询服务。多维分析:这里我们可以知道kylin就是OLAP引擎中MOLAP多维数据分析引擎分析。这里主要理解
亚秒级查询,亚秒级不是比秒更小的意思是没有达到秒级的意思,仅次于秒级,但是不如秒。简单举例比如1GHz/1.2s就是亚秒级,而1GHz/s就是秒级。虽然是这样但是也足够快了,这是因为什么呢?
当然是因为MOLAP多维分析引擎的Cube数据存储方式决定数据需要进行预计算,其实在我们可以体会到Kylin也以空间来换时间这样一中方式来换取的数据查询速度的提升。
Kylin的架构
下面我们来看Kylin的架构:
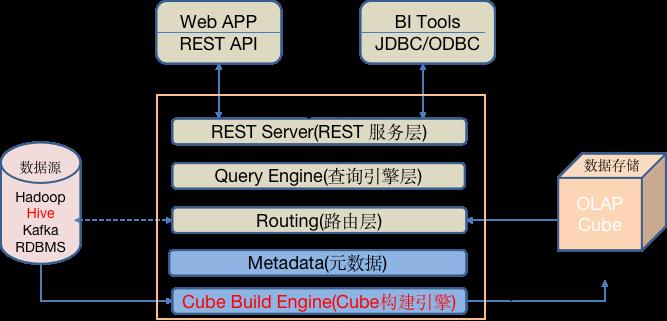
首先,我们来看
kylin支持的数据源有Hadoop、HIve、Kafka、RDBMS。从此支持的数据源来看kylin是可以对接Hive中的数仓的,当然,当前kylin仅支持按照星型模型搭建的数仓。在
星型数仓中,我们把需求要分析的维度的和度量在Kylin中定义好,这样Kylin就能把所有的维度组合都计算出来,并将数据存储到Cube中,在Kylin中Cube存储使用的是HBase。这其实就是之后要讲述的Cube设计中的一部分。
Kylin为什么使用HBase存储Cube
那么问题来了
Kylin为什么使用HBase存储Cube呢?其实,主要的原因是HBase是列式存储数据库,大家都知道列式存储查询快,从HBase底层物理存储结构来说其实HBase的<k,v>存储,更像是一个多维的map。我们知道Kylin正是适合对多维数据进行分析的。
所以说Kylin在做数据查询时是在HBase中查询的。
那大家就会产生疑问了HBase的数据查询十分不友好,动不动就scan就put,还要有良好的rowkey设计理念,实现起来十分的麻烦,为啥要用HBase,而且大多数人都不会,我用个kylin还要学HBase代价也太大了,显然我不服啊!难道我以后写的查询的时候要使用HBase的查询方式吗,想必心中此时有一万只羊驼奔腾而过。。。。
其实在这里Kylin给我们解决了这个问题,其实,kylin提供了一个Query Engine查询引擎层将HBase的查询在做了封装,虽然将数据存储到HBase中,但是我们查询的时候使用大家熟悉SQL就可以实现查询,相当于把HBase放在底层仅仅做存储,另一方面,Kylin将rowkey设计也比较好,使得我们查询起来非常快。
Kylin整体架构:
其实
Kylin架构,是分两层的,其中REST Server(REST服务层)和Query Engine(查询引擎层)作为上面一层,Metadata(元数据)和Cube Build Engine(Cube构建引擎)作为下面一层。
Cube Build Engine多维数据集构建引擎
- 首先,我们先来看下面一层主要是
Cube Build Engine多维数据集构建引擎将hive表中的数据各个维度组合预计算出来存储到HBase的Cube中。当Cube构建完成以后会有很多的元数据就存储在Metadata中,这些元数据可以在HBase中的表查询到,由此可见Metadata(元数据)将Cube的元数据也存储在了HBase中。由此我们可以知道下面的一层主要是负责预计算的
那么,上边一层是做什么的呢?上面一层主要是REST server(REST 服务层)(我们知道REST其实是Http协议的一种规范)可以使得麒麟可以通过Http请求获取数据,比如我们在APP或者Web页面通过发送get或者post请求(requst),Kylin响应(response)就可以给我们返回想要的结果,当然这个请求里应该要有我们的查询数据的sql。然后通过携带的sql通过Query Engine查询引擎将sql转译为HBase查询指令比如Scan等来操作HBase数据库来获取数据。由此我们也知道了上面一层主要是负责进行数据查询到的。
REST Server(REST服务层)
- 其实,上面介绍的都是在
Kylin底层封装的一些组件,那么下面我们来看Kylin在上面封装了什么呢?由图我们可以知道在上层他封装了两个组件,一个是封装REST API使得用户可以通过Web或者App发送REST请求来查询数据。另一个是封装了JDBC和ODBC连接池使得我们可以在java后台通过JDBC链接来查询数据。
Routing(路由层)
- 这里我们注意到还有一层
Routing(路由层),那么他有什么作用呢?其实,这一层使用在我们在使用Kylin查数据时如果这些数据还没有来得及预计算也就在HBase中还没有该查询的Cube,这时候我们在去HBase中查数据,是不是就没有了呀,`路由层的存在恰恰解决了这样的一个问题,在我们进行数据查询时,路由层会先判断我们要查询的数据的Cube 在HBase中存在不存在,如果存在就去HBase中查询,如果不存在路由层就会将命令输入到hive中,在 hive中进行查询,当然这种情况下数据查询和在hive中查询也没有任何和区别了。
Kylin整个的工作流程:
- 首先,我们把
hive表中的数据指定维度和度量(也就是设计好Cube)- 然后,
Kylin会根据我们提交的星型模型的维度和度量将hive中的所有的维度组合成的一个个Cuboid通过Cube Build Engine(Cube构建引擎)进行预计算并将数据结果保存到HBase中Cube中,同时也会将Metadata保存在HBase中。- 然后,我们用户在查询的时候通过
web页面查询端口、JDBC、ODBC或者BI工具中使用sql通过Query Engine将sql翻译为HBase查询的命令实现数据查询。
Kylin特点
Kylin的主要特点包括支持SQL接口、支持超大规模数据集、亚秒级响应、可伸缩性、高吞吐率、BI工具集成等。
标准SQL接口:Kylin是以标准的SQL作为对外服务的接口。支持超大数据集:Kylin对于大数据的支撑能力可能是目前所有技术中最为领先的。早在2015年eBay的生产环境中就能支持百亿记录的秒级查询,之后在移动的应用场景中又有了千亿记录秒级查询的案例。亚秒级响应:Kylin拥有优异的查询相应速度,这点得益于预计算,很多复杂的计算,比如连接、聚合,在离线的预计算过程中就已经完成,这大大降低了查询时刻所需的计算量,提高了响应速度。可伸缩性和高吞吐率:单节点Kylin可实现每秒70个查询,还可以搭建Kylin的集群。HBase中的数据有多个Region,这多个region可以进行并行的查询,基于此实现了高吞吐BI工具集成,主要是可视化的工具,兼容还不错的。
Kylin可以与现有的BI工具集成,具体包括如下内容。
ODBC:与Tableau、Excel、PowerBI等工具集成
JDBC:与Saiku、BIRT等Java工具集成
RestAPI:与javascript、Web网页集成
Kylin开发团队还贡献了Zepplin的插件,也可以使用Zepplin来访问Kylin服务。
官网所提供的特性:

个人认为官网的说支持实时和雪花模型感觉是吹流弊,一个是延迟秒级不能做到真正的实时,一个是一张事实表的雪花模型不适用于所有的雪花模型情形,下面我们来看Kylin安装启动。
以上是关于Kylin实践—— Kylin架构介绍的主要内容,如果未能解决你的问题,请参考以下文章