打怪升级之小白的大数据之旅(六十四)<Hive旅程第五站:DML基本操作>
Posted GaryLea
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了打怪升级之小白的大数据之旅(六十四)<Hive旅程第五站:DML基本操作>相关的知识,希望对你有一定的参考价值。
打怪升级之小白的大数据之旅(六十四)
Hive旅程第五站:DML基本操作
上次回顾
上一章,我们学习了Hive的DDL操作,学会如何操作数据库、数据表后,本章我们就要开始学习如何将数据导入到表中,如何将数据从表中导出
DML操作
我将数据的查询单独抽出到下一章,因为查询是hive的核心内容,本章的DML主要就是数据的导入和导出
数据导入
向表中装载数据
语法格式
load data [local] inpath '数据的path' [overwrite] into table test [partition (partcol1=val1,…)];
参数说明:
-
load data:表示加载数据
-
local:表示从本地加载数据到hive表;否则从HDFS加载数据到hive表
-
inpath:表示加载数据的路径
-
overwrite:表示覆盖表中已有数据,否则表示追加
-
into table:表示加载到哪张表
-
test:表示具体的表
-
partition:表示上传到指定分区
示例: -
测试数据,创建两个测试文件用于测试
vim /opt/module/hive/dbdata/test/test3.txt 1 hello 2 java 3 hadoop 4 hivevim /opt/module/hive/dbdata/test/test4.txt 1111 aaaa 2222 bbbb 3333 dddd -
创建表并导入数据
-- 创建两张表,分别用于本地和hdfs加载数据 create table test4(id int, name string) row format delimited fields terminated by '\\t'; create table test5(id int, name string) row format delimited fields terminated by '\\t';
直接加载本地文件到hive test4表中
-- 加载本地文件到test4表中
load data local inpath "/opt/module/hive/dbdata/test/test3.txt" into table test4;
- HDFS中显示如下:
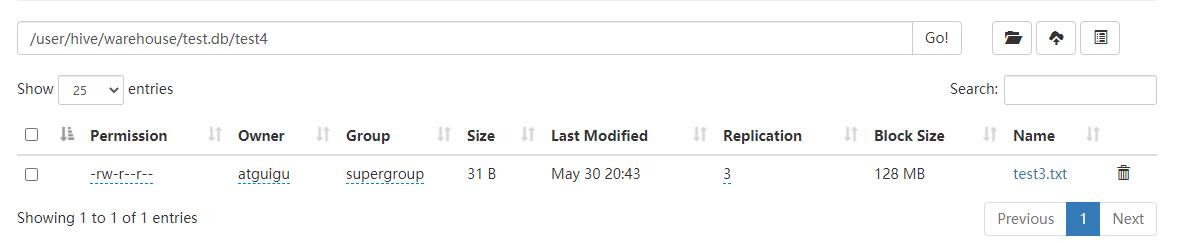
上传文件到HDFS,并加载HDFS中的文件到test5表中
-- 将test4.txt文件上传到HDFS根目录中
hadoop fs -put "/opt/module/hive/dbdata/test/test4.txt" /
-- 直接将test3.txt文件上传到test5表中
hadoop fs -put "/opt/module/hive/dbdata/test/test3.txt" /
-- 加载刚刚上传的根目录中的test4.txt文件到test5表中
load data inpath '/user/hadoopuser/test4.txt' into table test5
-- 查看数据
select * from test5;
- 上传test4.txt到根目录时:

- 上传test3.txt到test5表后:
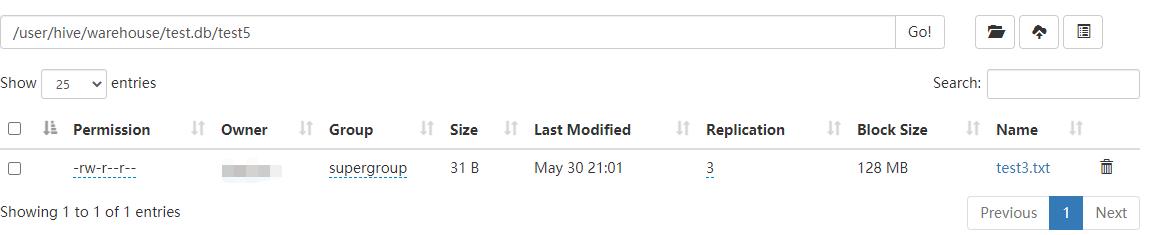
- 加载test4.txt到表中后,此时先不加载test3.txt数据
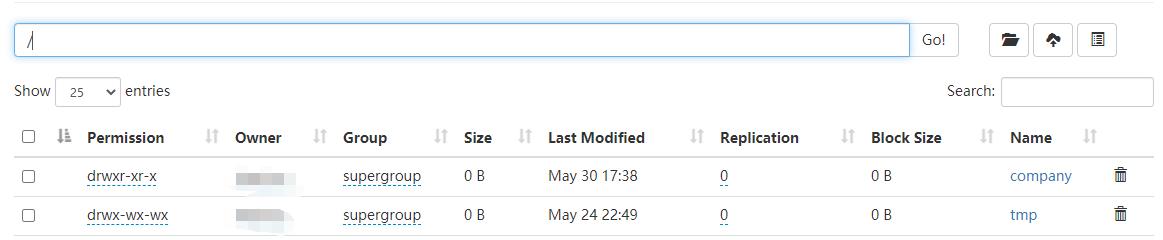
- 我们可以发现,存储在根目录中的test4.txt文件不见了,它自动存储到了test5表中
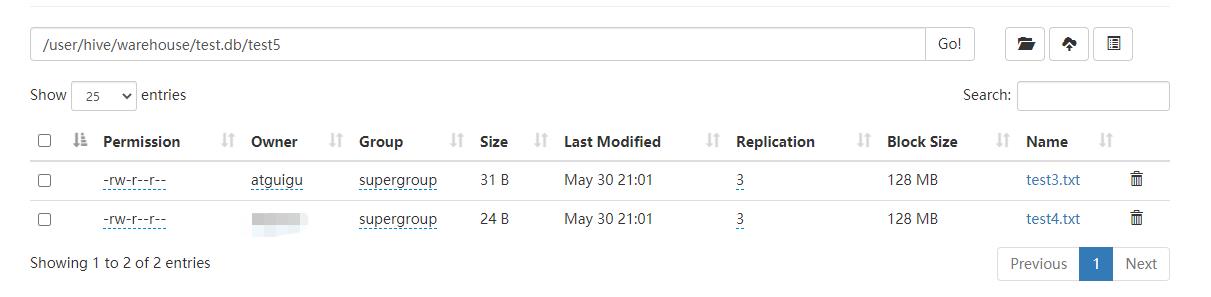
- 我们使用select * 查看,发现没有load 加载的test3.txt数据同样可以显示出来
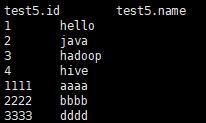
加载数据覆盖表中已有的数据
-- 再次上传test4.txt 文件到hdfs中,然后对test4表中数据进行覆盖
load data inpath '/user/hadoopuser/test4.txt' overwrite into table test4;
- 这几种上传的区别:
- 本地加载数据无需上传数据到hdfs中,直接load后,数据就会保存到hdfs中
- 使用hdfs上传后,不使用overwrite的时候,会有两种情况
- 如果上传到非表的路径下,那么它无法读取到数据,必须load,当load后,它会将该数据的路径修改到表中
- 如果上传到表的路径下,那么它可以读取到上传的数据
- 使用overwrite后,原数据会直接被覆盖掉
通过查询语句向表中插入数据
- 创建一张表
create table test6(id int, name string) row format delimited fields terminated by '\\t';
基本模式插入数据
insert into table test6 values(1,'wangwu'),(2,'zhaoliu');
根据查询结果插入数据
insert into table test6
select id, name from test5 where id = 1;
insert overwrite table test6
select id, name from test5 where id < 3;
注意:
- insert into:以追加数据的方式插入到表或分区,原有数据不会删除
- insert overwrite:会覆盖表中已存在的数据
查询语句中创建表并装载数据
根据查询结果创建表(查询结果会直接添加到新创建的表中)
create table if not exists test7
as select id, name from test5;
创建表时通过Location指定加载数据路径
- 在hdfs中创建一个文件夹,并上传数据到该文件夹中
hadoop fs -mkdir /test8 hadoop fs -put "/opt/module/hive/dbdata/test/test4.txt" /test8 - 创建表,并指定数据在hdfs上的位置
create external table if not exists test8 (id int, name string) row format delimited fields terminated by '\\t' location '/test8';
这里大家注意一下,数据一定要创建一个文件夹,并且文件夹中的文件(数据) 格式要一致,不然会报错
Import数据指定Hive表中
Import数据指定Hive表中
- 因为export导出的数据里面包含了元数据,因此import要导入的表不可以存在,否则报错
- 先用export导出后,再将数据导入
import table test9 from '/user/hive/warehouse/export/export1';
数据导出
- 数据导出实际上就是使用insert写出到指定的路径中
- 使用Insert操作后的文件名称是一个序列号
- 数据导出的时候,必须使用参数overwrite,不能使用insert into
Insert导出
将查询的结果导出到本地,我在测试数据文件夹下创建一个专门存放导出数据的文件夹export, 路径指定后,它会根据路径创建一个文件夹
insert overwrite local directory '/opt/module/hive/dbdata/export/test8
select * from test8;
将查询的结果格式化导出到本地
insert overwrite local directory '/opt/module/hive/dbdata/export/test8'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t'
select * from test5;
将查询的结果导出到HDFS上(没有local)
insert overwrite directory '
/export/test8'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t'
select * from test5;
Hadoop命令导出数据
使用 get 命令直接从hadoop上拉取数据
hadoop fs -get /user/hive/warehouse/test.db/test5/test4.txt
/opt/module/hive/dbdata/export/export1.txt;
Hive Shell命令导出数据
hive -e 'select * from test.test6;' > /opt/module/hive/dbdata/export/export2.txt;
Export导出数据到HDFS上
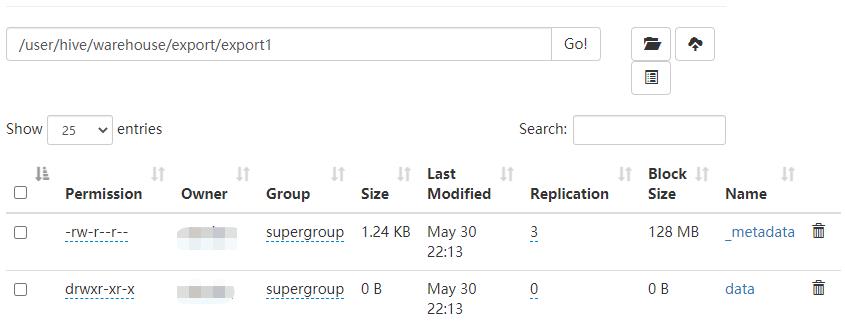
导出的数据包含两个文件,一个是存储数据本身的dada文件夹,一个是存储元数据信息的_metadata
export table test.test8 to '/user/hive/warehouse/export/export1';
- export和import主要用于两个Hadoop平台集群之间Hive表迁移,不能直接导出的本地
Sqoop导出
这个导出方式我会专门进行讲解,它一个用于将hive数据导出到数据库中的工具
总结
本章的DML基本操作就介绍到这里,下一章开始就是hive的重点了,不论是查询还是分区表、分桶表,函数,都是我们日常工作中必不可少的能力,所以大家学习完后面的知识,要经常练习我Hive开篇中的那个练习题
以上是关于打怪升级之小白的大数据之旅(六十四)<Hive旅程第五站:DML基本操作>的主要内容,如果未能解决你的问题,请参考以下文章