精通springcloud:分布式日志记录和跟踪使用,ELK Stack集中日志
Posted jinggege795
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了精通springcloud:分布式日志记录和跟踪使用,ELK Stack集中日志相关的知识,希望对你有一定的参考价值。
使用ELK Stack集中日志
ELK是3个开源工具—Elasticsearch. Logstash 和Kibana的首字母缩写,它也被称为弹性堆栈(Elastic Stack)。该系统的核心是Elasticsearch,这是一个基于另一个用Java编写的开源项目Apache Lucene的搜索引擎。该库特别适用于需要跨平台环境中的全文搜索的应用程序。Elasticsearch 流行的主要原因是它的性能。当然,它还具有其他一些优点,如可伸缩性、灵活性和易于集成,因为它可以提供基于JSON的RESTful API来搜索已存储的数据。它有一个庞大的网络讨论社区和许多用例,但对我们来说最有趣的是它能够存储和搜索应用程序生成的日志。记录日志是在ELK Stack中包含Logstash的主要原因。
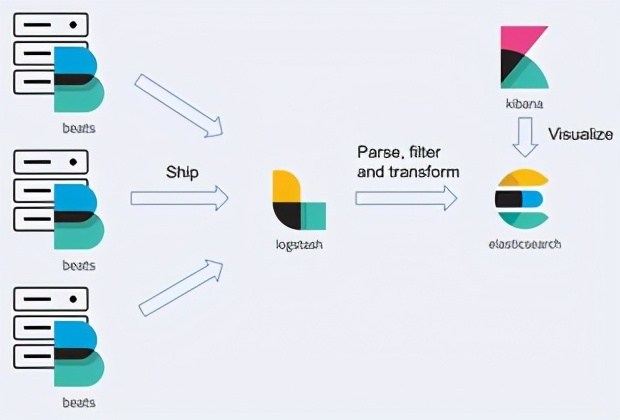
这个开源数据处理管道允许开发人员收集、处理和输入数据到Elaticsearch。Logstash支持许多从外部源提取事件的输入。有趣的是它有很多输出,而Elasticsearch只是其中之一。例如,它可以将事件写入Apache Kafka、 RabbitMQ 或MongoDB,它可以将指标数据写入InfuxDB或Graphite。 它不仅可以接收数据并将数据转发到目的地,还可以动态解析和转换数据。Kibana是ELK Stack的最后一个元素。它是Elasticsearch的开源数据可视化插件。它允许开发人员可视化、探索和发现Elasticsearch中的数据。开发人员可以通过创建搜索查询轻松显示和过滤从应用程序收集到的所有日志。在此基础上,开发人员还可以将数据导出为PDF或CSV格式以提供报告。
在机器上设置ELK堆栈
在尝试将任何8志从应用程序发送到Logstash 之前,开发人员必须在本地计算机上配置ELK Stack。 最合适的运行方式是通过Docker 容器。堆栈中的所有产品都可用作Docker镜像。有一个专门的Docker注册表由Elastic Stack的供应商托管。有关已发布镜像和标签的完整列表,请访问www. docker.elastic.co查找。所有这些都将使用centos:7作为基本镜像。我们将从Elasticsearch实例开始。可以使用以下命令启动它的开发。
docker run -d --name es -P 9200:9200 -P 9300:9300 - e
"discovery. type=single- node"
docker . elastic . co/elasticsearch/elasticsearch:6.1.1
在开发模式下运行Elasticsearch 是最方便的运行方式,因为我们不必提供任何其他配置。如果要在生产模式下启动它,则需要将vm.max_ map _count Linux 内核设置为至少262144。修改它的过程因操作系统平台而异。对于带有Docker Toolbox的Windows系统来说,必须通过docker-machine设置。
docker -machine ssh
sudo sysctl -w vm.max. map count- 262144
下一步是使用Logstash 运行容器。除了使用Logstash启动容器之外,开发人员还应该定义输入和输出。输出很明显,就是Elasticsearch, 现在可以在默认的Docker机器地址192.168.99.100下使用它。作为输入,我们定义了简单的TCP插件lgstash-input-tcp.它与我们的示例应用程序中用作日志记录追加器的LogstahTcpSocketAppender兼容。我们的微服务中的所有日志都将以JSON格式发送。所以,现在为该插件设置json编解码器非常重要。每个微服务都将使用其名称和micro前缀(显然这是为了表示它是微服务)在Elasticsearch中编制索引。以下是Logstash配置文件logstash.conf.
input {
tcp {
port => 5000
codec => j son
output {
elasticsearch (
hosts -> ["http://192 .168.99.100: 9200"]
index => "micro-g {appName}"
}
}
以下是运行Logstash并在端口5000.上公开它的命令。它还会将具有上述设置的文件复制到容器并覆盖Logstash配置文件的默认位置。
docker run -d --name logstash -P 5000:5000 -V -/logstash ,conf :/config-
dir/logstash. conf docker . elastic。
co/1ogstash/1ogstash-os:6.1.1一f/config- dir/logs tash. conf
最后,开发人员可以运行堆栈的最后一个元素Kibana. 默认情况下,它将在端口5601上公开,并连接到端口9200上可用的Elasticsearch API,以便能够从那里加载数据。
docker run -d --name kibana -e
"ELASTICSEARCH URI http://192.168.99.100:9200" -P 5601:5601
docker.elastic. co/kibana/kibana:6.1.1
如果开发人员想在Windows系统的Docker机器上运行所有Elastic Stack产品,则可能需要将Linux虚拟映像的默认RAM内存增加到最小2GB。启动所有容器之后,开发人员最终可以访问hp:/92.68.9.100:5601下的Kibana仪表板,然后继续将应用程序与Logstash集成。
将应用程序与ELK Stack集成
通过Logstash将Java应用程序与ELK Stack集成的方法有很多种。其中一种方法涉及使用Filebeat, 它是本地文件的日志数据发送器。此方法需要为Logstash 实例配置的beats( logstash-input-beat)输入,这实际上是默认选项。开发人员还应该在服务器计算机上安装并启动Filebeat守护程序。它负责将日志传递给Logstash.
就个人而言,笔者更喜欢基于Logback和专用追加器的配置。它似乎比使用Filebeat代理更简单。除了必须部署其他服务外,Filebeat 还要求我们使用解析表达式,如Grok过滤器。使用Logback追加器时,不需要任何日志发送程序。这个追加器在项目LogstashJSON编码器中可用。开发人员可以通过在logback -spring.xml文件中声明netlogstash.logback.
appender.LogstashSocketAppender appender来为自己的应用程序启用它。我们还将讨论使用消息代理将数据发送到Logstash的替代方法。在我们即将讨论的示例中,将演示如何使用SpringAMQPAppender将日志事件发布到RabbitMQ交换消息。
在这种情况下,Logstash 将订阅该消息并使用已发布的消息。
1.使用LogstashTCPAppender
库logstash-logback-encoder可以提供3种类型的追加器一UDP、TCP和异步(Async)。TCP追加器是最常用的。值得一提的是,TCP追加器是异步的,所有的编码和通信都被委托给-一个线程。 除了追加器之外,该库还提供了一些编码器和布局,使开发人员能够以JSON格式记录日志。因为Spring Boot默认包含一个Logback 库,以及springoo-tarterweb,所以我们只需要为Maven的pom.xml 添加一个依赖项即可。
<dependency>
<groupId>net .logstash. logback</groupId>
<artifactId> logstash-logback-encoder</artifactId>
<version>4.11</version>
</ dependency>
下一步是在Logback配置文件中使用LogstashTCPAppender类定义追加器。每个TCP追加器都要求开发人员配置编码器。可以在LogstashEncoder和
LoggingEventCompositelsonEncoder之间做出选择。
LoggingEventCompositeJsonEncoder 可以为开发人员提供更大的灵活性。它由一个或多个映射到JSON输出的JSON提供程序组成。默认情况下,如果没有配置JSON提供程序,那么它不会按LogstashTCPAppender的方式工作。它默认包含若干个标准字段,如时间戳、版本、日志程序名称和堆栈跟踪等。此外,它还会添加来自映射诊断上下文(Mapped Diagnostic Context, MDC)的所有条目和上下文,当然,开发人员也可以通过将includeMde或includeContext属性中的一个设置为false来禁用它。
<appender name- "STASH"
class="net .logstash. logback. appender。LogstashTcpSocketAppender">
<destination>192.168.99.100:5000</destination>
<encode r
class="net. logstash. logback. encoder . Loggi ngEventCompositeJsonEncoder ">
<providers>
<mdc />
<context />
<logLevel />
<loggerName />
<pattern>
<pattern>
"appName": "order- service”
</pattern>
</pattern>
sthreadName />
<message />
<logstashMarkers />
<stackTrace />
</providers>
</encoder>
</appender>
现在再回来看一看我们的示例系统。开发人员仍然可以在同一个Git 存储库( htp:/ithb com/piomin/sample- spring-cloud-comm.git)和feign. with. discovery分支(
http:/ithb.co/pioin/saople-spring-cloudo comm/ree/feign. with _discovery) 找到该示例。笔者已根据第9.1节“微服务的最佳8志记录实践”中提出的建议在源代码中添加了一些日志记录条目。以下是order-service服务中POST方法的当前版本。笔者已经通过从rgsg4fjLoggeFactory调用getLogger方法将SLF4J上的Logback用作日志记录程序。
@PostMapping
public Order prepare (8RequestBody Order order): throws
JaonProcess ingException {
int price一0;
List<Product> products =
productClient. findByIds (order .getProductIds();
LOGGER. info ("Products found: 1",mapper . writeValueAsString (products));
Customer customer 一
customerClient. findByIdWithAccounts (order. getCustomerId());
LOGGER. info ("Customer found: (}", mapper . writeValueAsString (customer));
for (Product product : products)
price +- product .getPrice();
final int priceDiscounted = priceDiscount (price, customer) ;
LOGGER. info ("Discounted price: ()”,
mapper .writeValueAsString (Collect ions. singletonMap ("price",
priceDiscounted))) :
Optional<Account> account = cus tomer .getAccounts() .stream() .filter(a - >
(a.getBalance() > priceDiscounted)) .findFirsto ;
if (account. isPresent() {
order.setAccountId (account.get() .getId()) :
order . setStatus (Orde rStatus。ACCEPTED) ;
order .setPrice (priceDiscounted) ;LOGGER. info ("Account found: { ”,
mapper .writevalueAsString (account.get))) :
F else
order.setStatus (OrderStatus。REJECTED) ;
LOGGER. info("Account not found: { F”,
mapper.writeValueAsstring (customer。getAccounts())) ;
}
return repository.add (order) ;
}
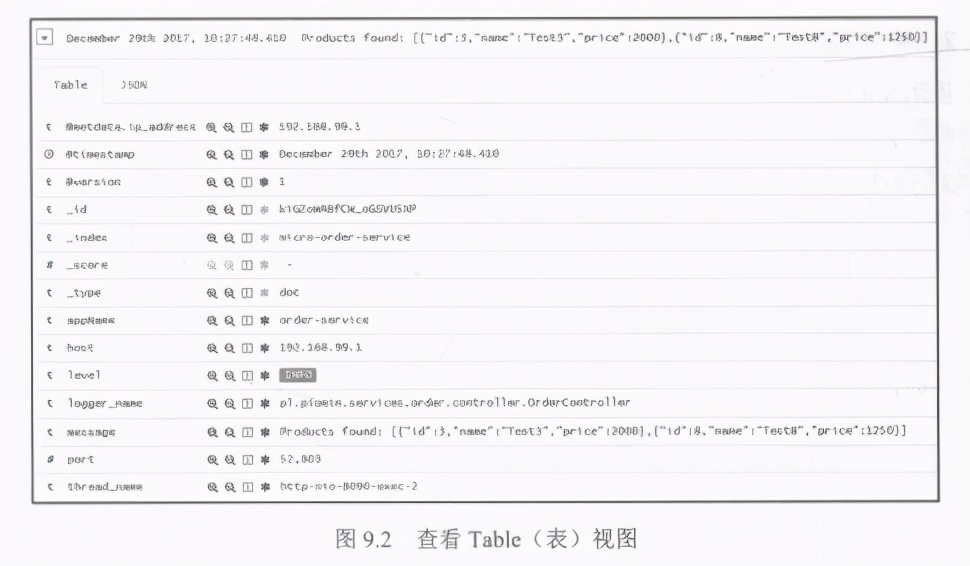
现在来看一看如图9.1所示的Kibana仪表板。它可以在htp://92. 168.99.100:5601处获得。在该仪表板中可以轻松发现和分析应用程序日志。在页面左侧的菜单中可以选择所需的索引名称(在图9.1的屏幕截图中标记为1)。日志统计信息显示在时间线图(标记为2).上。可以通过单击具体条或选择一组条来缩小搜索参数所采用的时间。给定时间段内的所有日志都显示在图表下方的面板上(标记为3)。

可以扩展每个条目以查看其详细信息。在详细的Table (表)视图中,我们可以看到诸如Elasticsearch索引(_ index) 的名称以及微服务的级别或名称(appName) 。大多数这些字段都已经通过
LoggingEventCompositeJsonEncoder设置。我们只定义了一个特定于应用程序的字段appName,如图9.2所示。
Kibana提供了搜索特定条目的强大功能。开发人员可以仅通过单击所选条目来定义过滤器,以便定义一组搜索条件。在图9.2中,可以看到如何使用传入的HTTP请求过滤掉所有条目。如前文所述,
org.springframework.web.filter.CommonsRequestIL oggingFilter类负责记录这些日志。我们刚刚定义了一个过滤器,其名称等于完全限定的日志记录器类名称。如图9.3所示是笔者的Kibana仪表板屏幕,它显示了仅由CommonsRequestI oggingiter生成的日志。

2.使用AMQP追加器和消息代理
使用SpringAMQP追加器和消息代理的配置比使用简单TCP追加器的方法要稍微复杂一些。首先,开发人员需要在本地计算机上启动消息代理。本书已经在第5章“使用Spring Cloud Config进行分布式配置”中详细介绍了此过程,其中还专门介绍了RabbitMQ, 以便使用Spring Cloud Bus重新加载动态配置。如果开发人员已在本地或作为Docker容器启动了RabitMQ实例,则可以继续进行配置。必须创建-个队列来发布传入事件,然后将其绑定到交换消息( Exchange)。要实现此目的,应该先登录Rabbit管理控制台,然后转到Queues (队列)部分。我们已经创建了一个名为q logstash 的队列,并且使用名称ex. logstash 定义了新的Exchange消息,如图9.4所示。对于所有示例微服务,队列都已经使用路由键值绑定到该Exchange消息。
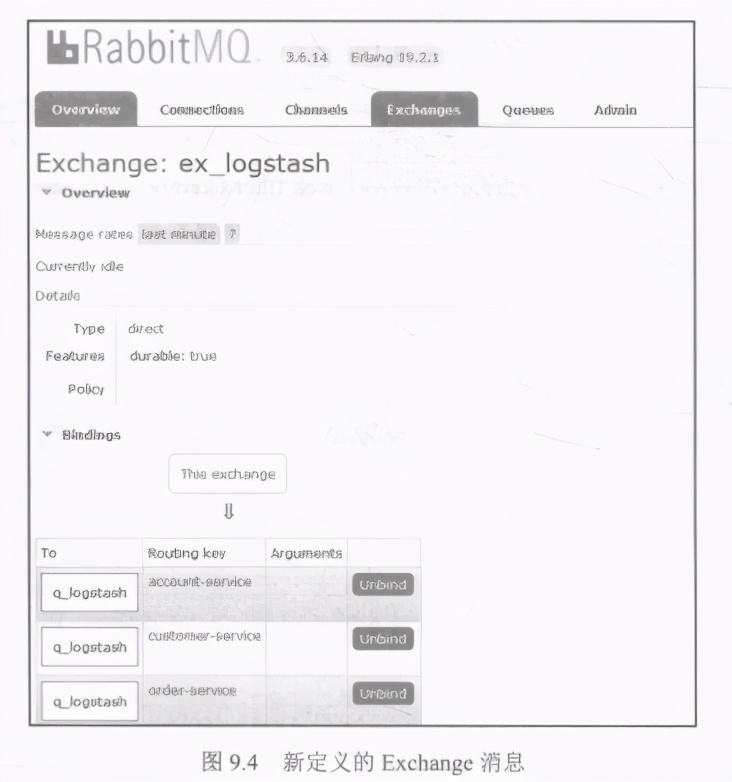
在启动并配置了RabbitMQ的实例之后,即可开始在应用程序端集成。首先,开发人员必须在项目依赖项中包含spring bostarer-amqp,,以提供AMQP客户端和AMQP追加器的实现。
<dependency>
<groupId>org. springframework. boot</groupId>
<arti factId>spring-boot-starter-amqp</arti factId>
</dependency>
然后,唯一要做的就是使用Logback配置文件中的org. springframnework amp.rabit.logback. AmqpAppender类来定义追加器。需要设置的最重要的属性是RabbitMQ网络地址( host和port).已声明的交换消息名称( exchangeName )和路由键值( routingKeyPatterm),该键值必须和已声明交换消息绑定的键值之一匹配。与TCP追加器相比,这种方法的缺点是需要自己准备发送给Logstash的JSON消息。以下是order-service 服务的Logback配置的一个片段。
<appender name- "AMQP"
class="org. springf ramework。amqp. rabbit。1 ogback . AmqpAppender">
<1ayout>
spattern>
"time": "8date{IS086011",
"thread"; "'thread" ,
"level": "号level",
"class": "%logger(36}",
"message":” tmessage"
</pattern>
</layout>
<host>192.168.99.100</host>
<port>5672</port>
<username>guest</username>
<password>guest</password>
<applicat ionId>order-service</applicationId>
<routingKeyPattern>order-service</ routingKeyPattern>
<declareExchange>t rue</ declareExchange>
<exchangeType>direct</exchangeType>
<exchangeName>ex_ logstash</exchangeName>
<generateId>true</generateId>
<charset>UTF- 8</charset>
<durable>true</durable>
<deliveryMode> PERSISTENT</de1 iveryMode>
</ appender>
Logstash可以通过声明rabbitmq (logstash-input-rabitmq) 输入轻松地与RabbitMQ集成。
input {
rabbitmq (
host - "192.168.99.100"
port => 5672
durable -> true
exchange => "ex_ logstash"
output {
elasticsearch {
hosts => ["http://192.168.99.100:9200"}
}
}
本文给大家讲解的内容是是使用ELK Stack集中日志
可以点赞+转发后,下方扫码来获取这套完整的体系资料。感谢大家的支持!

以上是关于精通springcloud:分布式日志记录和跟踪使用,ELK Stack集中日志的主要内容,如果未能解决你的问题,请参考以下文章