AI 算法是如何改变智能风控的 | 文末赠书
Posted AI科技大本营
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AI 算法是如何改变智能风控的 | 文末赠书相关的知识,希望对你有一定的参考价值。


来源 | 现代金融风险管理
作者 | 祝世虎 成学军
头图 | 下载于 ICphoto
在金融科技的浪潮下,金融机构纷纷启动了智能风控体系的建设,但是金融机构的关注点多在于业务规模、科技系统等硬实力的建设,而忽略了算法能力、智能风控文化等软实力的建设。
本文聚焦智能风控的“算法能力”的建设,用通俗的语言“漫话算法”,首先讲解算法的逻辑、笔者对算法的理解、算法在智能风控领域的应用经验,而后讲解如何在实战中通过场景因素、数据因素、算力因素来选择合适的算法。
本文结构如下:
1. 第一部分,在智能风控体系建设的这个后浪追逐前浪的过程中,和算法能力建设相关的四个笔者个人观点:
(1) 观点一:后浪要重视数据及算法能力的建设,避免落入“后发劣势陷阱”。
(2) 观点二:前浪不能安于现状而固步自封,避免陷入“建模套路化”。
(3) 观点三:智能风控领域模型算法的发展三阶段为“专家评分卡——>逻辑回归(高维逻辑回归)——>集成学习、深度学习”。
(4) 观点四:算法的选择,要根据“场景需求”对症下药,根据“数据基础”量体裁衣,根据“科技算力”量力而为,“理性”选择算法。
2. 第二部分,人工智能的发展与算法的进化。主要介绍人工智能的发展背景以及在金融领域中的应用。
3. 第三部分,人工智能算法在智能风控领域的经验与思考。先介绍了如何根据场景、数据、算力选择合适的算法,而后根据笔者经验总结出人工智能算法在智能风控领域的发展趋势。
(1) 趋势1:深度学习算法将会被广泛采用。
(2) 趋势2:多模态数据将会被广泛应用。
(3) 趋势3:图数据库与图深度网络将会大规模落地。
(4) 趋势4:联邦学习将会大规模落地。
(5) 趋势5:自动化建模平台将会升级为模型风险管理平台。
(6) 趋势6:算法的可解释性将会被逐步重视。
4. 第四部分,算法工程师必备算法知识与文献推荐。笔者按照算法领域热度与应用领域热度挑选了一些常用算法,并分别介绍了算法的原理以及在智能风控领域的应用经验。
(1) 图学习算法、经验及应用
(2) 联邦学习算法、经验及应用
(3) 集成学习算法、经验及应用
(4) 自动化机器学习算法、经验及应用
(5) 因子分解机算法、经验及应用
(6) 结构化数据深度学习算法、经验及应用
(7) 概率预测算法、经验及应用
(8) 迁移学习/元学习算法、经验及应用
(9) 半监督学习算法、经验及应用
(10)强化学习算法、经验及应用
(11)运筹优化算法、经验及应用
(12)运筹优化算法、经验及应用

关于智能风控领域算法的四个观点
在金融科技的浪潮下,金融机构纷纷启动了智能风控体系的建设,在这个后浪追逐前浪的浪潮中,笔者明显感觉无论是前浪还是后浪,均对算法人才的培养及算法能力的建设不够重视。
这将导致两个误区:一是,后浪盲目地模仿前浪,照猫画虎而陷入了“后发劣势陷阱”;二是,前浪安于现状而固步自封,算法能力迟滞不前,陷入“建模套路化”。算法能力的建设则是走出上述误区的关键环节之一。(一)观点一:后浪要避免“后发劣势陷阱”,重视数据及算法能力的建设
笔者提及的“后发劣势陷阱”主要体现在,后浪由于缺乏业务的实践经验,对智能风控体系建设的要点理解并不充分,所以在学习前浪的过程中,仅仅模仿前浪表面的、容易实现的、容易出成果的部分,而选择性地忽略了那些需要花时间、下苦功的基础工作。
比较明显的“后发劣势陷阱”是,后浪一蜂窝地照猫画虎进行IT系统的产品采购这个相对简单的事情,而忽略了基础数据、科技整合、算法能力等:
在数据基础方面:要“俯首甘为孺子牛”,做大量的、耗时间的数据工作,以实现模型效能的提升;
在科技整合方面:要“横眉冷对千夫指”,做革命性的、颠覆性的科技系统和科技流程的改造,进而实现对业务的敏捷支持;
在算法能力方面:要“甘做幕后英雄”,逐步建立算法研究能力,进而“随风潜入夜,润物细无声”地实现智能风控对业务的完美支持。
后浪要重视数据及算法能力的建设,避免“金玉其外,败絮其中”,这样才能行长致远,才能将金融科技真正打造为核心竞争力。
(二)观点二:前浪不能安于现状而固步自封,对于变化最快的算法领域要做到与时俱进,同时避免“建模套路化”
“建模套路化”的现象指的是,一些金融机构在业务实践中,用“一套数据、一套算法、一套流程”应对几乎所有业务场景和风控场景。
笔者认为,在场景金融中,场景方的流量分发模型与金融机构的流量准入模型,二者之间是“既合作,又对抗”的关系,所以,套路化的模型,会使得金融机构的风控流于形式,无法有效地对“流量”进行实质甄别。
(三)观点三:智能风控领域模型算法的发展三阶段为“专家评分卡——>逻辑回归(高维逻辑回归)——>集成学习、深度学习”
人工智能算法在风险评估领域的发展可以分为三个阶段:
第一阶段,规则驱动,多采用专家打分卡算法;
第二阶段,规则+数据驱动,多采用逻辑回归与高维逻辑回归算法;
第三阶段,大数据驱动,多采用集成学习与深度学习算法。

(四)观点四:算法的选择,要根据“场景需求”对症下药,根据“数据基础”量体裁衣,根据“科技算力”量力而为,“理性”选择算法
如何根据场景、数据、算力这些因素“理性”选择算法,是本文第三章重点说明的问题。在这里主要强调另外一点,理性选择算法的另一个障碍——算法工程师的主观倾向。
笔者自认为是一个“理性的感性人”,每次根据场景、数据、算力这些因素“理性”选择算法后,总有一些莫名的忧伤,总结起来就是如下三点:对集成学习的依赖、对深度学习的偏爱、对专家规则的无奈。
对于高维逻辑回归、集成学习的依赖
毋庸置疑,高维逻辑回归和集成学习这两类算法各方面相对均衡,是目前智能风控领域算法的第一梯队。
对于深度学习的偏爱
笔者对深度学习算法研究已久,日久生情,每次理性使用高维逻辑回归和集成学习建模以后,便会感慨道:“曾经有一个模型任务放在我面前,我没有选择深度学习算法,等我建完模型的时候才后悔莫及,人世间最痛苦的事莫过于此。如果上天能够给我一个再来一次的机会,我想对深度学习说三个字:我选你。如果非要在这个算法上加上一个期限,我希望是一万年!”
对于专家规则的无奈
对于专家规则,不是爱也不是恨,而是无奈。“唉!要是数据充分,谁还用专家规则啊!”但是,话说回来,这种无奈的感觉并不是因为专家规则的效果不好,事实上,在某些数据基础或者某些特定场景下,专家规则效果还可以,但是专家规则的主要缺陷是“无法自动更新”!业务在变化,风险在变化,专家模型原地不动,这些固化的规则就可能由“助力业务发展”变为“阻碍业务发展”。
所以,每次我用专家规则建模后,也会感慨道:“曾经有一个模型任务放在我面前,我选择了专家规则,等我建完模型的时候才后悔莫及,人世间最痛苦的事莫过于此。如果上天能够给我一个再来一次的机会,我觉得我会再看一眼数据基础,如果还是选择专家规则,我会给这份无奈加上一个期限——半年后重检!”半年后,看看半年中业务积累的数据情况,然后打开月光宝盒,在月光下大喊“般若波罗蜜”……

人工智能的发展与算法的进化
作为第一批人工智能的博士,毕业十年后,曾经多次感慨人工智能的发展:“十年前人工智能只在书本里,现在人工智能都在资本里;十年前我只能用人工智能来写作业,现在人们都在用人工智能来创业!”十年间,人工智能的发展实在是太快了!这个发展主要体现在算法、应用两个方面。
(一)人工智能发展的背景
1. 人工智能、机器学习、深度学习的概念辨析
(1) 人工智能(Artificial Intelligence)
“人工智能”一词最初是在1956年Dartmouth学会上提出的,希望用计算机来构造复杂的、拥有与人类智慧同样本质特性的机器。最初的人工智能技术主要包括:机器人、语言识别、图像识别、自然语言处理和专家系统等。但随着理论和技术日益发展,目前人工智能的五大主流技术为:生物特征识别、机器学习、自然语言处理、计算机视觉、知识图谱。
(2) 机器学习(Machine Learning)
机器学习是一种实现人工智能的方法。与传统的为解决特定任务、流程固定的算法不同,机器学习是用大量的数据来“训练”,通过各种算法从数据中学习如何完成任务。从学习方法的角度,机器学习算法可以分为监督学习(分类问题)、无监督学习(聚类问题)、半监督学习、集成学习、深度学习和强化学习。
(3) 深度学习(Deep Learning)
深度学习是一种实现机器学习的技术。严格地说,深度学习算法属于机器学习算法的一个子类,是一种基于神经网络的算法。最初的深度学习算法,由于当时训练数据量不足、计算能力落后,因此最终的效果不尽如人意。但随着数据和算力的飞速发展,再加上一些特有的算法相继被提出(如残差网络),深度学习的效果脱颖而出,因此越来越多的人将其看作一种“单独的”方法。
(4) 人工智能、机器学习、深度学习三者的关系:
机器学习是一种实现人工智能的方法,深度学习是一种实现机器学习的技术,这三者的关系并不是“哈尔滨红肠”的级联关系,而是“俄罗斯套娃”的包含关系,如图所示:

看到这张图,有人可能会产生一个误解“机器学习的终点是深度学习”,对此,笔者的回答是:技术无终点。在我们每一个人工智能研究者的心里,都应该牢牢铭记这句话:
Yoshua Bengio:“Science is NOT a battle, it is a collaboration. We all build on each other's ideas. Science is an act of love, not war. Love for the beauty in the world that surrounds us and love to share and build something together. That makes science a highly satisfying activity, emotionally speaking。”这句话的主旨是:科学不是战争而是合作,任何学科的发展就是同行之间互相切磋学习。机器学习也是这样,博采众长才能引领风骚。
2. 人工智能的主流算法与研究热点
人工智能传统的算法包括决策树、聚类、贝叶斯分类、支持向量机、EM、Adaboost等。但是,随着理论和技术的日益发展,目前主流的人工智能算法包括如下:
图学习算法
联邦学习算法
集成学习算法
因子分解机算法
自动化机器学习算法
结构化数据深度学习算法
概率预测算法
迁移学习/元学习算法
半监督学习算法
强化学习算法
运筹优化算法
在金融领域对于人工智能的投入不断加大的趋势下,可以预见,人工智能会不断渗透金融领域中的更多业务,并且由辅助人工转为价值创造。有研究人员统计了人工智能金融的研究热点排序如下:
金融文本发掘(Financial Text Mining)
算法交易(Algorithmic Trading)
风险估计(Risk Assessment)
情感分析(Financial Sentiment Analysis)
投资组合管理(Portfolio Management)
欺诈检测(Fraud Detection)
(二)人工智能在金融领域的应用
1. 人工智能在金融领域的应用简析

2. 人工智能在金融领域发展的驱动因素
人工智能在金融领域的飞速发展,主要有以下几个驱动因素:
(1) 监管的政策倡导
政策方面,在“科技向善”的前提下,鼓励人工智能、大数据等新技术的落地实践,支持金融与科技的深度融合。
(2) 金融机构的认可
金融机构认可人工智能的技术价值,金融业务创新越来越依赖于大数据和人工智能技术,金融科技水平正在成为金融企业的核心竞争力。
(3) 基础算法的发展
人工智能领域汇集了一大批顶尖的研究人员,从理论方面推动着算法能力、数据能力、科技算力的不断提升。算法基础理论的进步,推动了人工智能在金融领域的应用实践。
(4) 大数据的扩域融合
金融数据与其他跨域数据的融合,不仅使得金融机构的营销与风控模型更准确,同时也催生出更多基于场景的金融产品,使得行业之间的交叉更加深入,从而带来更多的商业价值与社会效益。
(5) 黑产手段的升级
目前各类金融场景中的欺诈行为逐步呈现出金融欺诈产业化、犯罪组织职业化、作案目标精准化、欺诈活动移动化、欺诈场景多样化等特征。这种“魔高一尺、道高一丈”的激烈对抗,更加促进了算法技术的发展。

人工智能算法在智能风控领域的经验与思考
(一)智能风控领域的算法选择经验
人工智能算法在金融领域的应用,需要场景、数据、算法、算力的有机结合,要做到:根据场景需求对症下药,根据数据量体裁衣,根据算力量力而为。
1. 由“场景需求”到“算法要求”
场景和业务的需求就是模型的产出,直接决定了模型的算法。由“场景需求”到“算法要求”分为两步:
第一步,先根据场景业务的特点,归纳出场景需求;
第二步,由场景需求抽象成算法因素。
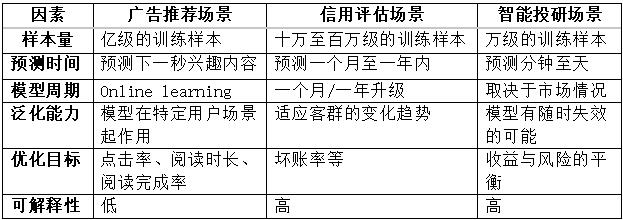
常用的算法因素一般包含如下:样本量、预测时间、模型周期、泛化能力、优化目标、可解释性等。
为了更好地理解场景对算法选择的影响,笔者以广告推荐场景、信用评估场景、智能投研场景举例说明如下:
2. 由“数据禀赋”到“特征工程”
智能风控领域的主流模型均依赖于特征工程,其数据源主要包括:征信报告、资产状况、基本信息、多头借贷、运营商数据、地理信息、设备信息等。通过对上述数据源进行特征工程,可以提取统计量特征、离散化特征、时间序列特征、组合特征等。笔者在大学军训的时候,教官常说“铁打的营盘,流水的兵”,笔者提及特征工程的经常套用这句话提出“流水的数据、铁打的特征”,数据是流动的,不稳定的,容易受污染的,而特征则是相对稳定的,只有特征的稳定才能保证模型输出的稳定。
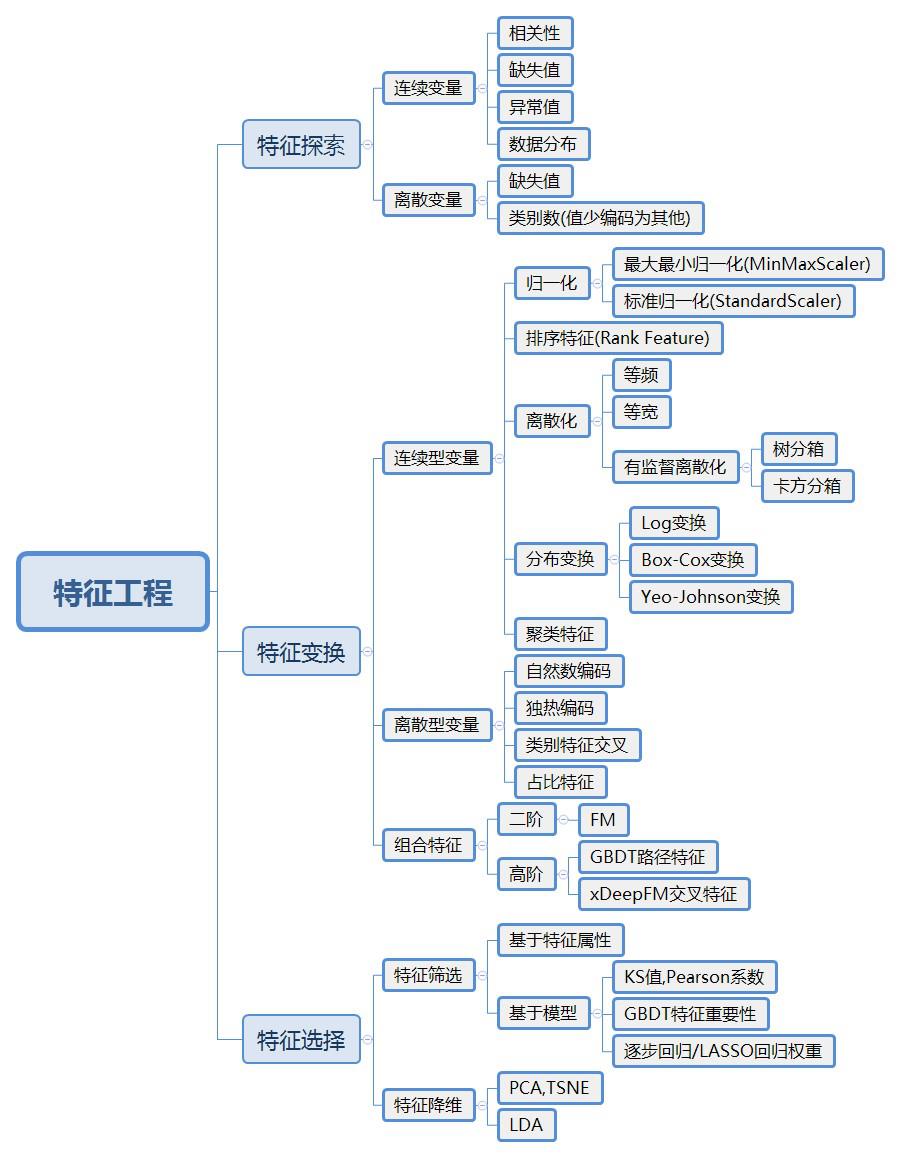
(1) 特征工程的基本流程
笔者在工作中总结了一套通用的特征处理技巧,并经常戏称为“把大象放在冰箱里统共分三步”,大象就越是庞大的数据体系,冰箱就是实用的特征库。
第一步:特征探索,从数据角度优先排除无效的特征;
第二步:特征变换,将特征转换为模型更容易识别的形式,并进行升维;
第三步:特征选择,从业务的角度选择有效的特征。
(2) 特征工程的经验分享
在实践中,笔者有一些经验可以与读者分享:
经验建议1:关注数据缺失特征
笔者要提醒,千万别把数据缺失认为是数据质量问题,这种缺失本身也是一种特征。所以,在实践中要关注原始数据的缺失是否具有业务含义,并据此构造相应的缺失值特征。例如,笔者在衍生二代征信变量的时候,构造“客户特征缺失数量”作为一个特征,就这个简单的缺失值统计数量都可以有效改善模型效果,更何况其他更有实际意义的数据缺失。
经验建议2:关注时间差特征
时间差特征值得深入挖掘,时间差特征主要指客户两次行为之间的时间差,可以是最近一次消费(取现/还款)距今时长,一段时间内最大单笔交易与最小单笔交易的时间差等。笔者在开发贷中模型的时候,通过数据挖掘,发现最近一次消费(取现/还款)距今时长的变量与客户是否违约具有较高的相关性。
经验建议3:关注离散变量与连续变量的聚合特征
要关注离散变量与连续变量的聚合特征。例如,笔者在开发贷款违约模型过程中,将分类变量(职业/卡类型/贷款类型)等对数值变量(贷款金额/消费金额)进行聚合汇总,构造了不同职业/业务类型的贷款金额的均值/方差/最大值/最小值的统计量,该类特征的使用有效地提升了模型的效果。
经验建议4:关注外部数据的使用
一些外部数据是金融数据的有效补充,特别是反欺诈和二次营销类的外部数据,对于金融机构的模型效果贡献度很高。
3. 算法选择经验总结
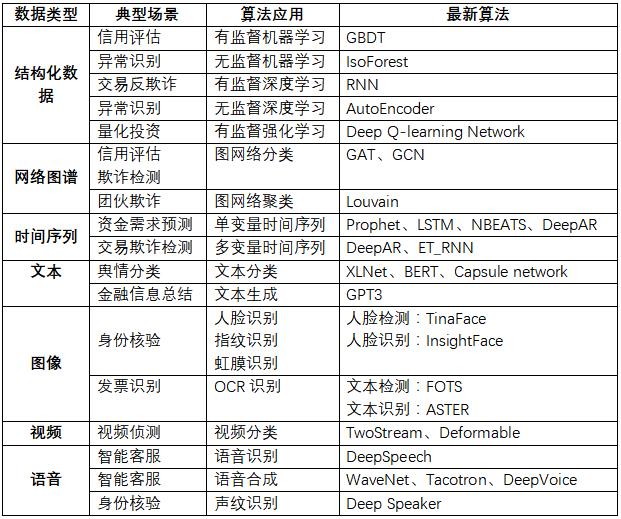
(1) 基于数据类型的算法选择
金融领域的数据特点就是“多源异构”,其数据类型主要有:时间序列数据、网络图谱数据、结构化数据、文本数据、图像数据、视频数据、语音数据。下面根据笔者实践,给出了针对不同的数据类型,选择算法的经验,如下表所示:
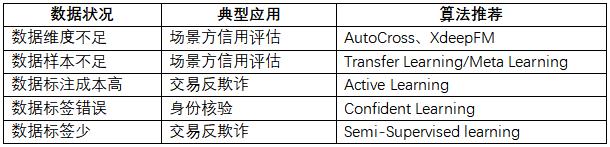
(2) 基于数据状况的算法选择
在实际工作中,经常会遇到样本不足(尤其是黑样本)、数据维度不足、人工标注成本高、标签少、标签错误等情况。面对这些数据的“状况”,选择合适的算法,可以做到事半功倍。下面根据笔者实践,给出了针对不同的数据状况,选择不同算法的经验,如下表所示。
(3) 关于数据,基于经验的算法选择
笔者在智能风控方面的算法实践,总结如下经验:
经验建议5:对于结构化数据
当连续特征数量大于离散特征数量时,建议优先采用集成学习。
当离散特征数量大于连续特征数量时,集成学习与深度学习效果相当。
当离散特征多(如大量ID类特征)时,建议优先选择深度学习。
经验建议6:对于时间序列数据
对于纯时间序列,“时序特征+集成学习”的效果一般优于深度学习。
对于高维稀疏时间序列,深度学习与集成学习各有千秋。
经验建议7:对于图数据
对于关联关系要求高的应用场景,例如图反欺诈场景等,建议特征作为节点采用GNN模型训练。
对于关联关系要求低的应用场景,例如图关系特征辅助信用评估等,建议直接学习节点的Vector,然后编码到原始特征中采用集成学习训练。
4. 建模方法论的经验总结
在建模的方法论上,笔者也有一些心得体会可以和读者分享,以期批评指正。
经验建议8:关于数据质量
数据是模型的根基,如果数据质量存在严重缺陷,后期很难通过算法来进行弥补,所以在建模前,要关注数据质量,准确评估数据质量对于模型的影响。
经验建议9:关于专家经验与专家规则
专家经验与专家规则的主要缺陷是无法自我更新,但是在“规则有效期”内,专家经验实际上是很好的“标尺”,所以要根据这些标尺对算法进行一定程度的纠偏。
经验建议10:关于模型迭代与算法创新
创新是算法的生命力,迭代是模型的生命力,但是做这两件事情之前,首先要确定一个“及格线”。对于算法创新,首先要保证经典算法(及格线)是有效的;对于模型迭代,首先要选好基线模型(及格线)。
(二)人工智能算法在智能风控领域的发展趋势
笔者结合工作经验抛砖引玉,思考了人工智能算法在智能风控领域的发展方向。
1. 趋势1:深度学习算法将会被广泛采用
(1) 随着数据的丰富与算力的不断提升,深度学习模型的优势逐步体现。
随着数据的丰富与算力的不断提升,传统的评分卡模型在大数据风控能力上的缺陷逐渐显露出来。与此同时,基于DeepFM类与基于Transformer类的深度学习算法在智能风控领域的优势也不断显示出来。DeepFM类的模型从广告推荐领域迁移而来,由于其在自动化特征组合与客户ID类数据的优势,在用户行为欺诈领域发挥越来越重要的作用;而最新的Transformer类模型的发展,平衡了深度学习模型表征能力强与可解释性差的特点,在智能风控领域也得到了越来越多的关注和应用。
(2) 深度学习模型对于用户行为表征能力强,既可以实现自动化特征组合,又可以对用户的行为进行精准、细致的刻画。
一方面,深度学习模型通过特征表征、元素点积、注意力机制等技术,实现自动化的特征组合。另一方面,通过RNN等模型在用户行为的序列建模,对用户的行为序列进行更加细致准确的刻画。Tencent、FeedZai等公司均利用RNN类模型进行交易反欺诈与信用评估,该模型因为省去了特征处理环节,大大提高了模型效率,且模型精准度更高。
(3) 深度学习模型对于数据的可扩展性好,在无标注数据、标注不准确数据、增量数据、不同分布数据、小样本数据等场景的建模,相比其他算法有独特的优势。
在无标注数据、标注不准确数据、增量数据、不同分布数据、小样本数据下,传统算法的效果大打折扣,而深度学习模型通过神经网络的结构设计与损失函数的优化,支持元学习、迁移学习、在线学习、半监督学习、持续学习等模型的场景应用,可探索性与可配置性都很强。
当建模样本不足时,可以采用Transfer Learning或者Meta Learning的方式进行模型设计;
当样本标注成本高时,可以采用Active Learning的方式进行样本建模;
当样本标签有错误时,可以通过Learning With Noisy Label的方式进行模型训练;
当只有部分样本有标签,可以采用Semi-supervised learning的方式进行建模。
2. 趋势2:多模态数据将会被广泛应用
算法的发展与数据的发展“东成西就”,数据成就了算法,算法也促进了数据。深度学习算法的发展,也将会有效推动多模态数据在风控领域的应用。
从算法上看,传统的风控模型一般从用户的信贷记录上识别客户风险,深度学习模型可以从多模态的数据中挖掘隐藏的风险信息。
从数据上看,图像、语音、文本、图等不同属性的数据作为结构化数据的有效补充,能够有效地将信贷记录上未察觉的风险识别出来。
所以,可以预见多模态数据将会在风控领域发挥越来越大的价值。
3. 趋势3:图数据库与图深度网络将会大规模落地。
(1) 网络图谱以颠覆性的“关系视角”来解决反欺诈问题
网络图谱用“事物间关系属性”来代替“事物本身的属性”,来表征事物的特征。
从这个颠覆性的视角,使得网络图谱在识别团伙欺诈、线上反欺诈领域发挥着重要的作用。例如,相对金融机构熟悉的线下反欺诈,线上反欺诈主要针对团伙欺诈行为,团伙欺诈行为的主要特征是:“羊”的还款意愿不取决于“羊的本身属性”,而是取决于“羊和羊头之间的关系属性”,这恰恰是网络图谱的视角。
(2) 网络图谱衍生图特征在风控领域的深度应用
网络图谱衍生图特征分为三类:
基于专家经验的网络图特征:这类特征通常具有可解释性,是通过业务经验构造网络节点与边的属性特征,用于后续风险预测模型的特征输入。
基于机器学习的网络图特征:这类特征通常是不可解释的,是通过矩阵分解或者随机游走等图表示方法,将图网络刻画出的用户/企业风险水平进行结构化向量表达,用于下游不同场景下风险模型的特征输入。
端到端的风险预测模型:这种方法融合结构化特征属性,通过图神经网络算法直接训练风险预测模型。
第一种应用由于可解释性强,业务应用便捷,目前已在众多金融机构落地。第二第三种应用由于建模过程更复杂,目前只集中在互联网大厂应用,笔者认为随着金融机构对于智能的认知与应用不断加深,未来也会逐渐被金融机构接受并应用。
(3) 网络图谱将成为金融机构“新的数据源”
笔者在原始数据特征上建立了一套评分体系,随后逐步尝试将这套评分体系构建在网络图谱特征上,发现两者效果具有一定的可比性。并且,随着图谱构建算法和方法论的进步,网络图谱能够基于有限的数据源挖掘出更多的内部关系,相当于形成了新的“关系数据源”。
4. 趋势4:联邦学习将会大规模落地
首先我们要有一个认识:数据是生产资料、模型算法形成生产力、联邦学习本质上是一种生产关系,它能够充分地调动数据生产资料,并集成模型算法而形成生产力。
联邦学习在保护数据隐私前提下,让数据和算力留在本地,并在此基础上进行联合模型训练的计算框架。在金融领域,保护隐私和数据安全是一个永久的话题。联邦学习在保护隐私和数据安全的前提下,带动了场景生态和金融生态跨领域、企业级的数据合作,催生了联合建模的新业态和新模式,在未来将会大规模落地实施。
5. 趋势5:自动化建模平台将会升级为模型风险管理平台
笔者前文提到了“后发劣势陷阱”中,后浪一蜂窝地照猫画虎进行IT系统的产品采购这个相对简单的事情,而忽略了基础数据、科技整合、算法能力等。目前的状况是,大部分的金融机构均采购了自动化的建模平台,那么如何用好这个平台,可以总结为:一个核心问题,两个应用感受,三个发展趋势。
(1) 一个核心问题:责任划分。
自动化建模产出的模型,如果用这个模型放的贷款出现不良,那么谁来负责任?所以,这个平台必须嵌入银行的模型风险管理流程,才能有明确的责任划分。
(2) 两个应用感受:
笔者曾经使用过自动化机器学习平台进行建模,在实践中内心感受如下:
感受1:这个平台是在解一道数学题,而不是在做风控;
感受2:这个平台会不会形成一种新的“建模套路化”。
(3) 三个发展趋势:
趋势1:在数据清洗、特征工程等领域将会发挥重要作用。
根据笔者经验,一个模型的流程,通常会把60–80%的时间用在数据清洗和特征工程上,用于微调算法的时间不足5%,并且数据清洗和特征工程这两个环节可以“套路化”。
趋势2:自动化机器学习算法可以作为有效挑战者用于模型验证。
自动化机器学习算法是一个公平的尺子,可以作为有效挑战者成为模型验证的“基准线”,以节约模型验证的工作量。
趋势3:自动化建模平台将会升级为模型风险管理平台。
关于模型风险的重要性,可以参见笔者的另一篇万字长文《银行模型风险管理体系的构建与实践》。模型风险管理平台是一个流程平台,将自动化建模平台嵌入流程,明确责任;并且将数据处理、特征工程、模型验证等可以自动化的环节均纳入其中,有效提升建模整体的敏捷性。
6. 趋势6:算法的可解释性将会被逐步重视
风控领域对模型解释性的要求高于其他领域,尤其在欺诈拒绝或者命中黑名单时,最好是能给出一定的解释。而机器学习(深度学习)模型在该方面的缺陷也恰好限制了其在风控领域的应用,对于可解释性的研究将会是智能风控领域的研究热点。
但是,辩证地看问题,笔者的个人观点是这样的:虽然可解释性在金融领域很重要,但不要一味追求可解释性,智能的本质就是利用算法从数据中发掘出那些被埋没的信息。

算法工程师必备算法知识与经验分享
笔者在本章总结了一些金融领域的常用算法、笔者的经验分享以及进一步自学的参考文献,如下图所示。

(一) 图学习算法、经验及应用
1. 图学习算法介绍
提到图学习,笔者很喜欢达摩院2020年十大科技趋势预测白皮书里提到的一段关于图网络的描述:“大规模图神经网络被认为是推动认知智能发展强有力的推理方法。图神经网络将深度神经网络从处理传统非结构化数据(如图像、语音和文本序列)推广到更高层次的结构化数据(如图结构)。大规模的图数据可以表达丰富和蕴含逻辑关系的人类常识和专家规则,图节点定义了可理解的符号化知识,不规则图拓扑结构表达了图节点之间的依赖、从属、逻辑规则等推理关系。以保险和金融风险评估为例,一个完备的 AI 系统不仅需要基于个人的履历、行为习惯、健康程度等进行分析处理,还需要通过其亲友、同事、同学之间的来往数据和相互评价进一步进行信用评估和推断。基于图结构的学习系统能够利用用户之间、用户与产品之间的交互,做出非常准确的因果和关联推理。”
数学领域有一个著名的理论,叫六度空间理论,你和任何一个陌生人之间所间隔的人不会超过六个,这充分说明了关系的重要性。图网络提供了数据的通用表示,基本万事万物的联系均可以使用“节点+关系”来表示,同时,大量的现实问题都可以作为图上的一组计算任务来处理。图数据可以说是一种最契合业务的数据表达形式。
从最近几年的顶会情况来看,图神经网络在学术界已经掀起了新的热潮,也会迎来工业界更多的关注。DeepMind关于深度学习的未来曾经提到“生物学里先天因素和后天因素是共同发挥作用的,我们认为‘人工构造’和‘端到端’学习也不是只能从中选择其一,我们主张结合两者的优点,从它们的互补优势中受益”。
笔者认为,图神经网络既利用了丰富的人工构造的属性特征信息,又利用了复杂的网络结构信息,充分实现人工构造和端到端学习的统一。从图中,可以进行多层关系推理。传统的CNN,RNN等深度神经网络只能处理欧式空间的数据,对于非欧式空间的图数据无法有效表征,图学习算法正是针对非欧式空间的图数据进行学习。
按照网络知识本身,图学习算法可以分为网络表示学习算法与图神经网络算法两个分支:
网络表示学习算法(GraphEmbedding)希望得到节点的有效表征应用于下游任务,整个模型的输出是顶点或边的向量化表示,不涉及上层业务的关联,是通用的表征,典型算法如DeepWalk、LINE算法。
图神经网络算法(GraphNetwork)则是对特定的任务进行网络学习,是端到端的训练,是具体的表征,典型算法如GCN、GAT算法。
2. 图学习算法经验
传统的客户建模认为客户与客户之间是独立的,但是风控场景存在大量复杂的关系,包括交易关系、转账关系、亲属关系等,这使得个体属性不仅与自身的特性相关,还与其发生交互的个体有关。笔者结合实践经验,给出一些算法建议供参考:
GBDT与GNN的结合
GBDT与GNN的结合有三种方式,一是GBDT的输出作为GNN的特征输入,二是GNN的输出作为GBDT的特征输入,三是GBDT与GNN的联合训练。第三种方式由于统一了任务本身,因此模型效果更好。Catboost作者发表了一篇文章《Boost Then Convolve: Gradient Boosting meets graph neural networks》讲的就是第三种方式的算法理论,最后比较其他的方法如GBDT这种浅层的机器学习模型,证明联合训练的效果是比较突出的。
图网络与时间序列的结合
无论是风控领域、营销领域还是投资领域,时序图网络的作用越来越重要,如何高效地构建亿节点级别规模网络,实现相关领域知识图谱融合以及关键节点辨识、推理和控制,达到风险预警及防范,是值得研究的领域。
金融图网络算法设计
图网络大多与场景直接相关,一个电商场景的图和社交网络的图在数据构成与上层模型计算层面均有本质不同,只有针对业务属性进行算法的改进,才能真正解决业务的痛点。研究人员针对金融图网络数据设计了一些专用金融图网络算法,如HACUD、MAHINDER、AMG等图网络算法。笔者认为,该类算法值得模型人员学习、研究并应用。
不同类型边的处理
正如前文所言,风控场景存在大量复杂的关系,包括转账交易等资金往来关系,父母配偶等亲属关系、朋友同事等社会关系,以及代办人等中介关系等。目前大部分图算法在进行计算时,权重参数是基于节点属性特征的,而不考虑边类型的影响。这要求我们进行落地实践时,不能简单的“拿来主义”,而要在场景分析、基础网络关系设计、算法分析设计等的基础上,形成富有针对性的解决方案。
图的分布式计算能力
不管是头部互联网公司、还是金融机构,均服务大量客户,由此构建的客户关系网络可以达到数10亿个节点、数100亿条边的规模。这要求必须重点考虑大规模图的计算能力,甚至优先于考虑算法本身的设计。将合适的图神经网络算法与大规模计算能力相结合,方可孵化出好的模型。
3. 经典资料(个人推荐)
【1】图网络学习: http://cse.msu.edu/~mayao4/dlg_book/
【2】图网络论文: https://github.com/thunlp/GNNPapers
【3】BTC: Ivanov, Sergei, and Liudmila Prokhorenkova. Boost then Convolve: Gradient Boosting Meets Graph Neural Networks. arXiv preprint arXiv:2101.08543 (2021).
【4】HACUD: Hu B, Zhang Z, Shi C, et al. Cash-out user detection based on attributed heterogeneous information network with a hierarchical attention mechanism[C]//Proceedings of the AAAI Conference on Artificial Intelligence.2019: 946-953.
【5】MAHINDER: Zhong Q, Liu Y, Ao X, et al. Financial Defaulter Detection on Online Credit Payment via Multi-view Attributed Heterogeneous Information Network[C]//Proceedings of The Web Conference.2020: 785-795.
【6】AMG: Hu B, Zhang Z, Zhou J, et al. Loan Default Analysis with Multiplex Graph Learning[C]//Proceedings of the 29th ACM International Conference on Information & Knowledge Management.2020:2525-2532.
(二) 联邦学习算法、经验及应用
1. 联邦学习算法介绍
数据共享是数据流通和数据产业的重要基础,但数据共享过程中存在数据孤岛问题与数据安全与隐私问题。当前已有的基于云的数据共享方法,存在数据泄露与数据垄断的风险,且数据存储与集中处理的资源与成本过大。因此,有必要探索新的技术解决数据共享中遇到的问题。
联邦学习由Google最先提出,通过分布式机器学习技术解决跨域数据共享与数据共享中隐私泄露风险的问题。联邦学习的研究一部分集中于改进机器学习算法,另一部分集中在密码学技术。
联邦学习的改进算法主要有联邦线性回归、联邦梯度提升树、联邦深度学习等算法。笔者以联邦线性回归举例说明:
首先,A,B两个联邦初始化参数,由第三方生成密钥并向A和B发送公钥。
然后,联邦A,B分别计算各自的子损失函数,拥有Y标签一方汇总误差并分发,生成A与B各自加密的梯度。
最后,第三方将解密后的梯度发至A和B,从而更新A,B各自的参数,如此循环往复,直至满足迭代次数或准确率的要求。
联邦学习的密码学技术包括加密样本对齐和同态加密技术等。加密样本对齐针对不同联邦的同一客户进行关联,该过程一般通过RSA公开密钥密码体制与Hash编码实现。同态加密属于数据层面的信息保护,对于两种不同的处理方式——对密文直接进行处理,与对明文进行处理后再对处理结果加密,该算法可以保证得到相同的结果。
联邦学习按照参与方特性,通常分为三类:
横向联邦学习:用户特征相同,用户不同;
纵向联邦学习:用户特征不同,用户相同;
联邦迁移学习:用户特征不同,用户不同。
(1) 横向联邦学习:
算法定义:参与方数据集具有高度重叠的特征维度,样本重叠较少,将数据集进行横向切分,提取出数据集间特征一致而样本不完全相同的部分作为训练数据。
理解:例如在银行反欺诈场景,单独A银行的欺诈模型和B银行的欺诈模型识别能力有限,为了调高模型的准确性和鲁棒性,在A银行与B银行选取不一样的客户,分别做欺诈预测,在训练过程中对不同来源的模型参数通过云端控制方进行聚合,最终可以得到一个统一的欺诈模型。
(2) 纵向联邦学习:
算法定义:在两个数据集用户重叠较多而特征重叠较少的情况下,选择数据集按照用户相同而用户特征不同的部分数据进行训练。
理解:例如A银行与C互联网公司合作进行建模,A银行存储的是信贷记录数据,而C公司存储的是电商数据,这两部分数据许多是重叠的用户,但用户特征交集较少。纵向联邦学习通过加密将不同特征进行聚合和梯度更新,增强模型能力。
(3) 联邦迁移学习
算法定义:算法在用户特征与用户重叠都很少的情况下,无法对数据切分,只能利用迁移学习来克服数据或者标签不足的情况。
理解:例如一家是A金融机构,一家是境外的D电商,这两家无论数据的针对用户还是数据的特征都没有重叠,这种情况下要进行数据联合建模,需要通过联邦迁移学习来解决单边数据规模小和标签样本小的问题。
2. 联邦学习算法经验
联邦学习算法的实践经验实际上是在联邦学习“技术之外”的经验,比如配套的管理制度、多方科技系统的整合等:
奖惩机制设定:由于各方数据资源分布不均匀,各方对联邦学习的结果贡献度不同,所以在制度上要设计好奖惩机制。
多方工程优化:由于各方科技资源各不相同,联邦学习在各方的工程落地时,会遇到集群配置、网络配置等实际问题,因此工程优化在联邦学习中应该得到充分重视。
3. 经典资料(个人推荐)
【1】联邦学习白皮书:
https://aisp-1251170195.cos.ap-hongkong.myqcloud.com/wp-content/uploads/pdf/%E8%81%94%E9%82%A6%E5%AD%A6%E4%B9%A0%E7%99%BD%E7%9A%AE%E4%B9%A6_v2.0.pdf
【2】联邦学习综述:Kairouz, Peter, et al. "Advances and open problems in federated learning." arXiv preprint arXiv:1912.04977 (2019).
【3】收集联邦学习资料:
https://github.com/ZeroWangZY/federated-learning
(三) 集成学习算法、经验及应用
1. 集成学习算法介绍
集成学习算法是目前风控领域主流的机器学习算法,一般也称为GBDT类算法,据此扩展的算法有Xgboost、Lightgbm、Catboost、Snapboost等。
集成学习算法的原理是通过一系列弱分类器构建一个强分类器,其扩展算法Xgboost、Lightgbm、Catboost、Snapboost将Boosting的机理转换为函数的梯度下降问题,用来支持各种不同的损失函数,同时,这些框架在训练性能上做了大量算法优化,从而显著降低计算复杂度。
Xgboost算法采用牛顿法进行损失函数优化,同时增加正则项,缩减系数和采样步骤,提高模型泛化能力。
Lightgbm算法采用稀疏和稠密表示的混合存储方式,并使用OpenNMP进行并行加速。
CatBoost算法针对类别变量采用了特殊处理,并且采用了高效的并行算法加速计算。
Snapboost算法采用异构的弱分类器来优化,弱分类器的选取按照概率质量函数来进行采样。
2. 集成学习算法经验
集成学习算法巧妙地利用树结构,将特征衍生和集成学习这两个环节合二为一。所以客观上“无心插柳柳成荫”实现了两个优势:
一是,实现了特征生成和算法决策的融合,提升了算法的稳定性,保证了算法的效果;
二是,由于特征排序可以并行计算,所以GBDT算法支持分布式数据读取与模型训练,支持GPU高效训练,且可灵活转换为PMML等格式动态部署。
因此,GBDT类算法在智能风控、智能营销、智能投顾等领域均有广泛应用,并且是目前智能风控领域算法的优先选择。
3. 经典资料(个人推荐)
【1】GBDT: Yoav Freund. Boosting a weak learning algorithm by majority. Information and computation, 121(2):256–285, 1995.
【2】Xgboost: Chen, Tianqi, and Carlos Guestrin. Xgboost: A scalable tree boosting system. In KDD, pages 785-794, 2016.
【3】Lightgbm: Ke Guolin, Meng Qi, Finley Thomas, Wang Taifeng, Chen Wei, Ma Weidong, Ye Qiwei, and Liu Tie-Yan.LightGBM: A highly efficient gradient boosting decision tree. In NIPS, pages 3149–3157, 2017.
【4】Catboost:Liudmila Prokhorenkova, Gleb Gusev, Aleksandr Vorobev, Anna Veronika Dorogush, and Andrey Gulin.CatBoost: unbiased boosting with categorical features. In NIPS, pages 6638–6648, 2018.
【5】Snapboost: Parnell, Thomas, et al. SnapBoost: A Heterogeneous Boosting Machine. In NIPS, pages 33, 2020.
(四)因子分解机算法、经验及应用
1. 因子分解机算法介绍
本章提到的因子分解机算法主要指DeepFM类算法及其变式,包括DeepFM、WDL、NFM、AFM、DCN、DIN、DIEN、xDeepFM等各种版本的改进算法。DeepFM的核心在于类别型变量的向量表征与特征间交叉组合,DeepFM算法适合于离散特征较多的场景。
笔者以金融市场为例,尝试解释因子分解机类的算法思路:
向量表征思想(Embedding)
向量表征思想将事件通过模型表征为更高层次的向量抽象表达。举例说明,金融市场的事实、事件是动态的、复杂的,当我们无法对这些事实进行精确表征时,可以依赖于神经网络将事实向量化。
分类处理思想(Wide Deep)
分类处理思想是利用FM与DNN网络分别针对离散型数据与连续型数据进行学习。举例说明,金融市场既有离散型的数据,比如行业分类;又有连续型的数据,比如交易金额。由于数据差异,不同的数据类型需要设计不同的模型结构。
特征交叉思想(Feature Crossing)
特征交叉思想指的是特征的内积或者外积。举例说明,特征有限的情况下,通过特征交叉,自动组合形成新的特征,这样从中可以发现一些新的有效特征。
注意力思想(Attention)
注意力思想是指,针对时间序列与非时间序列有不同的注意力机制。举例说明,在不同市场下,不同的特征重要性不同,让模型自己去学习市场情况,不同市场情况下模型会“注意”不同的特征。
2. 因子分解机算法经验
因子分解机类算法在搜索推荐广告领域发挥着十分重要的作用,在金融领域,对于金融信息的推荐与理财产品的推荐同样可以应用。笔者认为该类模型与集成学习模型相比:
优势1:可以通过批处理支撑大数据训练,不一定需要大数据集群的支撑。
优势2:可以对用户进行细粒度的特征刻画。
另外,在实践方面,笔者有如下经验:
经验1:增加离散特征的比例。离散变量由于可以发挥向量表征的优势,更适合因子分解机类算法进行模型。
经验2:增加客户细粒度的行为数据。由于该模型为深度学习模型,为了保证模型稳定收敛,需要更多的客户行为数据。
3. 经典资料(个人推荐)
【1】深度学习在CTR预估中的应用:
https://zhuanlan.zhihu.com/p/59340370
【2】CTR预估入门及各种模型介绍:
https://www.mayi888.com/archives/54482
【3】深度CTR特征自动组合机制演化简史:
https://zhuanlan.zhihu.com/p/52876883
(五)自动化机器学习算法、经验及应用
1. 自动化机器学习算法介绍
金融机构在建模领域面临着两个问题:一是,许多情况业务人员不懂机器学习,而算法人员数量不足;二是,完整建模流程周期长、成本高。自动化机器学习算法的目标是完全自动化流程的创建,一方面,使得领域专家能快速使用机器学习,另一方面,使得算法工程师快速实现业务应用。
自动化机器学习(AutoML)一直是工业界所关注的机器学习技术,自动化机器学习方法目前研究的热点有自动特征组合与神经网络结构搜索。
(1) 自动特征组合
自动特征组合目的是在有限时间和资源情况下高效地构造出衍生特征。该类方法一般生成大量高阶组合特征,按照优化算法进行有效特征选择,并将选出的新特征与原始特征一起用于模型构建。由于特征的可解释性强,可以明确知道衍生的特征是由原始的哪些特征组合而来,因此适合于风控领域建模。
(2) 神经网络结构搜索(NAS)
神经网络结构搜索目的是在有限时间和资源情况下进行高效的、鲁棒的搜索得到最优的模型。例如,谷歌采用进化算法与强化学习来寻找适宜的神经网络结构,用于视觉分类任务。该类方法主要分为基于强化学习、遗传算法、梯度优化的方法。由于该类方法基于神经网络设计,因此适合于图像识别,文本识别等神经网络结构复杂的任务。
2. 自动化机器学习算法经验
自动特征组合的自动化机器学习算法(SAFE算法、AutoCross算法)可以清晰地知道衍生特征的构造逻辑,在分布式计算上也支持较好,因此更适合于风控场景建模,笔者在具体实践工作中,使用比较多的算法为蚂蚁金服的SAFE算法与第四范式的AutoCross算法。
(1) 笔者对于“SAFE算法”的偏爱
SAFE算法来自蚂蚁金服,通过多种特征构造方法,经过特征组合排序、特征生成IV值筛选、皮尔逊相关系数冗余特征处理,来实现自动化特征提取的功能。常用的特征构造方法有一元特征、二元特征、群组统计特征:
一元特征:指特征变换生成的特征,如时间特征的小时、日、周粒度的特征算子;
二元特征:指操作算子如+、-、*、/生成的特征;
群组特征:指基于数学统计意义生成的特征,如min、max、std、mean、skew等。
(2) 笔者对于“AutoCross算法”的偏爱
AutoCross算法来自第四范式,通过Beam search方法来产生数据,进行高阶特征组合,然后采用Filed-wise logistic regression 和Successive mini-batch gradient descent方法来进行特征评价,最终得到有效的特征组合用于下游建模任务。
(3) 关注自动化机器学习算法用于数据清洗、特征工程
笔者认为在风控领域,数据清洗、特征工程等流程要得到充分的重视,自动化机器学习算法未来的关注点也应该包括数据清洗和特征工程。
一方面,在一个模型的构建中,通常60–80%的时间用在数据清洗和特征工程上,用于微调算法的时间不足5%。
另一方面,一些任务无法自动化,比如行业特定知识。
(4) 神经网络结构搜索(NAS)可解释性的困扰
在实时性和可解释性要求高的风控场合,笔者认为基于深度学习的自动化机器学习算法若想大规模推广使用,还需要进行必要的“改良”。
3. 经典资料(个人推荐)
【1】SAFE: Shi, Qitao, et al. Safe: Scalable automatic feature engineering framework for industrial tasks. IEEE 36th International Conference on Data Engineering. 2020.
【2】AutoCross: Luo, Yuanfei, et al. Autocross: Automatic feature crossing for tabular data in real-world applications. Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2019.
【3】AutoML综述: Zöller, Marc-André, and Marco F. Huber. Benchmark and survey of automated machine learning frameworks. Journal of Artificial Intelligence Research. 2021.
【4】NAS综述: Elsken, Thomas, Jan Hendrik Metzen, and Frank Hutter. Neural architecture search: A survey. Journal of Machine Learning Research. 2019.
(六)结构化数据深度学习算法、经验及应用
1. 结构化数据深度学习算法介绍
结构化数据区别于图形数据、文本数据、语音数据等非结构化数据,指可用关系型数据库存储的高度结构化的数据。在结构化数据算法这个传统的领域,仍然不断有一些新的深度学习算法涌现出来,这类算法大致可以分为两类:
(1) 仿树型结构网络(Tree-based network)
该类算法使用神经网络模拟树模型的损失函数,代表的是DeepGBM算法。DeepGBM算法来自微软亚洲研究院,通过神经网络来拟合树模型索引的输出,将稀疏类别型特征输入CatNN子网络,将稠密连续型特征输入GBDT2NN子网络,最后将两子网络的输出合并,使用神经网络进行目标学习。
(2) 注意力类算法(Attention-based network)
该类算法通过引入注意力机制来进行网络结构设计,代表的是TabNet算法、 TabTransformer算法、NODE算法等。
TabNet算法:来自谷歌,通过引入注意力机制进行网络结构设计,效果好于其他神经网络和树形模型,并且兼顾可解释性要求,在一些场景下的效果相比Xgboost算法得到了一定的提升。
TabTransformer算法:同样来自谷歌,使用自注意力机制(Self-attention)来处理结构化数据,在半监督任务上显著优于GBDT算法。
NODE算法:来自俄罗斯最大搜索门户公司Yandex,该算法依据图像处理的DenseNet框架进行网络设计,构建基于结构化数据的DenseNet模型。
2. 结构化数据深度学习算法经验
结构化数据深度学习算法几乎适用于目前的所有风控模型与营销模型,该类模型与集成算法模型相比:
优势1:可以通过批处理支撑大数据训练,不需要大数据集群的支撑。对于仅有风险数据集市,而没有风险数据中台的金融机构,这类算法就是对风险数据集市的续命。
优势2:可以灵活定义优化目标,支持半监督、自监督等特定数据场景。
劣势:模型的调参复杂、可解释性较差。
3. 经典资料(个人推荐)
【1】DeepGBM: Guolin Ke, Zhenhui Xu, Jia Zhang, Jiang Bian, and Tie-Yan Liu. Deepgbm: A deep learning framework distilled by gbdt for online prediction tasks. In KDD ’19 Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2019.
【2】TabNet: Sercan O Arik and Tomas Pfister. TabNet: Attentive interpretable tabular learning. arXiv preprint arXiv:1908.07442, 2019.
【3】TabTransformer: Huang X, Khetan A, Cvitkovic M, et al. TabTransformer: Tabular Data Modeling Using Contextual Embeddings[J]. arXiv preprint arXiv:2012.06678, 2020.
【4】NODE: Sergei Popov, Stanislav Morozov, and Artem Babenko. Neural oblivious decision ensembles for deep learning on tabular data. arXiv preprint arXiv:1909.06312, 2019.
(七)概率预测算法、经验及应用
1. 概率预测算法介绍
复杂经济学创始人布莱恩阿瑟说过,不确定性是经济世界的主旋律。今天笔者要讲的正是不确定性。
统计学有两大学派,频率学派与贝叶斯学派。频率学派研究的重点是样本数据的分布,他们认为一个模型存在唯一的真实参数,但是贝叶斯派的观点则大有不同,贝叶斯学派研究的重点是参数的分布,他们认为唯一的参数并不存在,参数只存在一定的概率分布。概率预测算法与贝叶斯学派的思想不谋而合,它试图告诉你,这个世界是不确定性,不要想着去准确预测数据值,而是从分布的角度去看待问题本身,一切皆有可能,只不过可能性不等而已。
概率预测有两个重要的部分,一部分是基于结果的分布预测,另一部分是基于参数的分布预测。基于结果的分布预测先假设预测值的分布,再求解该
以上是关于AI 算法是如何改变智能风控的 | 文末赠书的主要内容,如果未能解决你的问题,请参考以下文章