MySQL存储去重操作(爬虫)
Posted J哥。
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL存储去重操作(爬虫)相关的知识,希望对你有一定的参考价值。
mysql数据库安装:
下载地址:https://dev.mysql.com/downloads/windows/installer/5.7.0.html
MySQL连接数据库:
db = pymysql.connect(host="127.0.0.1",port=3306,user="root",password="root",database="csdn_crawler",charset='utf8')
host:以后在连接外网服务器的时候,就要改成外网服务器的ip地址。
port:在外网一般会更换端口号,不会为3306,这是为了安全考虑。
user:连接的用户,一般在生产环境中会单独分配一个账号给你,而不是使用root用户。
password:这个用户的密码。
database:要连接操作的数据库名。
charset:设置为utf8这样就能操作中文了。
Python学习网络爬虫主要分3个大的版块:抓取,分析,存储
一 更新数据
1 简单方法
1.1 代码
import pymysql
db = pymysql.connect(host='localhost', user='root', password='123456', port=3306, db='spiders')
cursor = db.cursor()
sql = 'UPDATE students SET age = %s WHERE name = %s'
try:
cursor.execute(sql, (25, 'Bob'))
db.commit()
except:
db.rollback()
db.close()1.2 结果
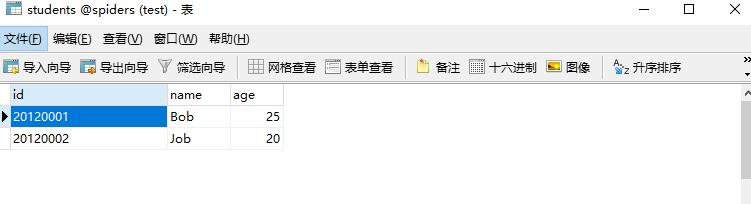 1.3 说明
1.3 说明
这里同样用占位符的方式构造SQL,然后执行execute()方法,传入元组形式的参数,同样执行commit()方法执行操作。如果要做简单的数据更新的话,完全可以使用此方法。
2 优化方法
2.1 点睛
在实际的数据抓取过程中,大部分情况下需要插入数据,但是我们关心的是会不会出现重复数据,如果出现了,我们希望更新数据而不是重复保存一次。另外,就像前面所说的动态构造SQL的问题,所以这里可以再实现一种去重的方法,如果数据存在,则更新数据;如果数据不存在,则插入数据。另外,这种做法支持灵活的字典传值。
2.2 代码
data = {
'id': '20120001',
'name': 'Bob',
'age': 21
}
table = 'students'
keys = ', '.join(data.keys())
values = ', '.join(['%s'] * len(data))
import pymysql
db = pymysql.connect(host='localhost', user='root', password='123456', port=3306, db='spiders')
cursor = db.cursor()
sql = 'INSERT INTO {table}({keys}) VALUES ({values}) ON DUPLICATE KEY UPDATE'.format(table=table, keys=keys,
values=values)
update = ','.join([" {key} = %s".format(key=key) for key in data])
sql += update
try:
if cursor.execute(sql, tuple(data.values()) * 2):
print('Successful')
db.commit()
except:
print('Failed')
db.rollback()
db.close()2.3 结果
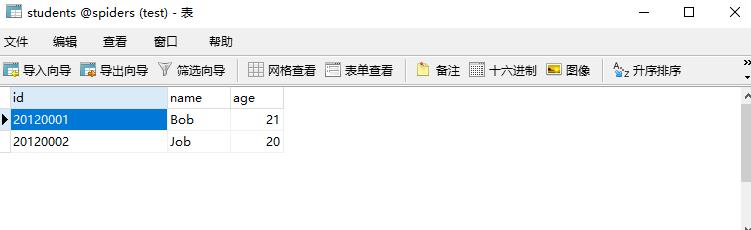 2.4 说明
2.4 说明
这里构造的SQL语句其实是插入语句,但是我们在后面加了ON DUPLICATE KEY UPDATE。这行代码的意思是如果主键已经存在,就执行更新操作。比如,我们传入的数据id仍然为20120001,但是年龄有所变化,由20变成了21,此时这条数据不会被插入,而是直接更新id为20120001的数据。完整的SQL构造出来是这样的:
INSERT INTO students(id, name, age) VALUES (%s, %s, %s) ON DUPLICATE KEY UPDATE id = %s, name = %s, age = %s这里就变成了6个%s。所以在后面的execute()方法的第二个参数元组就需要乘以2变成原来的2倍。
如此一来,我们就可以实现主键不存在便插入数据,存在则更新数据的功能了。
二 删除数据
1 代码
import pymysql
db = pymysql.connect(host='localhost', user='root', password='123456', port=3306, db='spiders')
cursor = db.cursor()
table = 'students'
condition = 'age > 20'
sql = 'DELETE FROM {table} WHERE {condition}'.format(table=table, condition=condition)
try:
cursor.execute(sql)
db.commit()
except:
db.rollback()
db.close()2 结果

三 查询数据
1 简单方法
1.1 代码
import pymysql
db = pymysql.connect(host='localhost', user='root', password='123456', port=3306, db='spiders')
cursor = db.cursor()
sql = 'SELECT * FROM students WHERE age >= 20'
try:
cursor.execute(sql)
print('Count:', cursor.rowcount)
one = cursor.fetchone()
print('One:', one)
results = cursor.fetchall()
print('Results:', results)
print('Results Type:', type(results))
for row in results:
print(row)
except:
print('Error')1.2 结果
E:\\WebSpider\\venv\\Scripts\\python.exe E:/WebSpider/5_2_1.py
Count: 4
One: ('20120001', 'Ann', 24)
Results: (('20120002', 'Job', 20), ('20120003', 'cakin', 28), ('20120004', 'Jim', 25))
Results Type: <class 'tuple'>
('20120002', 'Job', 20)
('20120003', 'cakin', 28)
('20120004', 'Jim', 25)1.3 说明
这里我们构造了一条SQL语句,将年龄20岁及以上的学生查询出来,然后将其传给execute()方法。注意,这里不再需要db的commit()方法。接着,调用cursor的rowcount属性获取查询结果的条数,当前示例中是4条。
然后我们调用了fetchone()方法,这个方法可以获取结果的第一条数据,返回结果是元组形式,元组的元素顺序跟字段一一对应,即第一个元素就是第一个字段id,第二个元素就是第二个字段name,以此类推。随后,我们又调用了fetchall()方法,它可以得到结果的所有数据。然后将其结果和类型打印出来,它是二重元组,每个元素都是一条记录,我们将其遍历输出出来。
但是这里需要注意一个问题,这里显示的是3条数据而不是4条,fetchall()方法不是获取所有数据吗?这是因为它的内部实现有一个偏移指针用来指向查询结果,最开始偏移指针指向第一条数据,取一次之后,指针偏移到下一条数据,这样再取的话,就会取到下一条数据了。我们最初调用了一次fetchone()方法,这样结果的偏移指针就指向下一条数据,fetchall()方法返回的是偏移指针指向的数据一直到结束的所有数据,所以该方法获取的结果就只剩3个了。
2 优化方法
2.1 点睛
推荐使用while循环加fetchone()方法来获取所有数据,而不是用fetchall()全部一起获取出来。fetchall()会将结果以元组形式全部返回,如果数据量很大,那么占用的开销会非常高。
2.2 代码
import pymysql
db = pymysql.connect(host='localhost', user='root', password='123456', port=3306, db='spiders')
cursor = db.cursor()
sql = 'SELECT * FROM students WHERE age >= 20'
try:
cursor.execute(sql)
print('Count:', cursor.rowcount)
row = cursor.fetchone()
while row:
print('Row:', row)
row = cursor.fetchone()
except:
print('Error')2.3 结果
E:\\WebSpider\\venv\\Scripts\\python.exe E:/WebSpider/5_2_1.py
Count: 4
Row: ('20120001', 'Ann', 24)
Row: ('20120002', 'Job', 20)
Row: ('20120003', 'cakin', 28)
Row: ('20120004', 'Jim', 25)
以上是关于MySQL存储去重操作(爬虫)的主要内容,如果未能解决你的问题,请参考以下文章