python文不如字之开篇之作PILtkinterpygame和CMD命令行实战演示字符字符集字符编码知识
Posted dhjabc_1
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python文不如字之开篇之作PILtkinterpygame和CMD命令行实战演示字符字符集字符编码知识相关的知识,希望对你有一定的参考价值。
【文不如字之开篇之作】字符、字符集、字符编码基础知识宣贯篇
字符集和字符编码 —— 每个软件开发人员应该无条件掌握的知识!
一、基础知识
(一)字符
字符指类字形单位或符号,包括中文、字母、数字、运算符号、标点符号和其他符号,以及一些功能性符号。
字符是电子计算机或无线电通信中字母、数字、符号的统称,其是数据结构中最小的数据存取单位,通常由8个二进制位(一个字节)来表示一个字符。
字符是计算机中经常用到的二进制编码形式,也是计算机中最常用到的信息形式。
(二)字符集
字符集(Charset):是一个系统支持的所有抽象字符的集合。字符是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。
(三)字符编码
字符编码(Character Encoding):是一套法则,使用该法则能够对自然语言的字符的一个集合(如字母表或音节表),与其他东西的一个集合(如号码或电脉冲)进行配对。即在符号集合与数字系统之间建立对应关系,它是信息处理的一项基本技术。通常人们用符号集合(一般情况下就是文字)来表达信息。而以计算机为基础的信息处理系统则是利用元件(硬件)不同状态的组合来存储和处理信息的。元件不同状态的组合能代表数字系统的数字,因此字符编码就是将符号转换为计算机可以接受的数字系统的数,称为数字代码。
在 ASCII 编码中,一个英文字母字符存储需要1个字节。
在 GB 2312 编码或 GBK编码中,一个汉字字符存储需要2个字节。
在UTF-8编码中,一个英文字母字符存储需要1个字节,一个汉字字符储存需要3到4个字节。
在UTF-16编码中,一个英文字母字符或一个汉字字符存储都需要2个字节。
在UTF-32编码中,世界上任何字符的存储都需要4个字节。
(四)字符集和字符编码的关系
字符集是书写系统字母与符号的集合,而字符编码则是将字符映射为一特定的字节或字节序列,是一种规则。通常特定的字符集采用特定的编码方式(即一种字符集对应一种字符编码(例如:ASCII、ios-8859-1、GB2312、GBK,都是即表示了字符集又表示了对应的字符编码,但Unicode不是,它采用现代的模型)),因此基本上可以将两者视为同义词。
二、常用字符集和字符编码
常见字符集名称:
ASCII字符集、GB2312字符集、BIG5字符集、GB18030字符集、Unicode字符集等。
计算机要准确的处理各种字符集文字,需要进行字符编码,以便计算机能够识别和存储各种文字。
(一)ASCII字符集&编码
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统。它主要用于显示现代英语,而其扩展版本EASCII则可以勉强显示其他西欧语言。它是现今最通用的单字节编码系统(但是有被Unicode追上的迹象),并等同于国际标准ISO/IEC 646。
ASCII字符集:主要包括控制字符(回车键、退格、换行键等);可显示字符(英文大小写字符、阿拉伯数字和西文符号)。
ASCII编码:将ASCII字符集转换为计算机可以接受的数字系统的数的规则。使用7位(bits)表示一个字符,共128字符;但是7位编码的字符集只能支持128个字符,为了表示更多的欧洲常用字符对ASCII进行了扩展,ASCII扩展字符集使用8位(bits)表示一个字符,共256字符。
(二)GBXXXX字符集&编码
1、GB2312
GB2312是中华人民共和国国家汉字信息交换用编码,全称《信息交换用汉字编码字符集——*本集》,由国家标准总局发布,1981年5月1日实施,通行于大陆。新加坡等地也使用此编码。GB2312收录简化汉字及符号、字母、日文假名等共7445个图形字符,其中汉字占6763个。GB2312 规定“对任意一个图形字符都采用两个字节表示,每个字节均采用七位编码表示”,习惯上称第一个字节为“高字节”,第二个字节为“低字节”。
GB2312的编码范围为2121H-777EH,与ASCII有重叠,通行方法是将GB码两个字节的最高位置1以示区别。
2、GBK
GB2312 仅收汉字 6763 个,这大大少于现有汉字,随着时间推移及汉字文化的不断延伸推广,有些原来很少用的字,现在变成了常用字,未收入 GB2312-80,这使得表示、存储、输入、处理都非常不方便,而且这种表示没有统一标准。
为了解决这些问题,以及配合UNICODE的实施,全国信息技术化技术委员会于1995年12月1日《汉字内码扩展规范》。
GBK向下与GB2312 完全兼容,向上支持ISO 10646 国际标准,在前者向后者过渡过程中起到的承上启下的作用。
GBK亦采用双字节表示,即不论中、英文字符均使用双字节来表示,为了区分中文,将其最高位都设定成1,总体编码范围为8140-FEFE之间,首字节在81-FE 之间,尾字节在40-FE 之间,剔除 XX7F 一条线。
GBK 共收入21886个汉字和图形符号,包括:
GB2312中的全部汉字、非汉字符号;
BIG5中的全部汉字; 与ISO
10646相应的国家标准GB13000中的其它 CJK 汉字,以上合计20902个汉字;
其它汉字、部首、符号,共计984个;
3、GB18030
GB18030 是最新的汉字编码字符集的国家标准,向下兼容 GBK 和 GB2312 标准。GB18030 编码是一二四字节变长编码。一字节部分从 0x0~0x7F 与 ASCII 编码兼容。二字节部分,首字节从 0x81~0xFE,尾字节从 0x40~0x7E以及 0x80~0xFE,与GBK标准*本兼容。四字节部分,第一字节从 0x81~0xFE,第二字节从 0x30~0x39,第三和第四字节的范围和前两个字节分别相同。四字节部分覆盖了从 0x0080 开始, 除去二字节部分已经覆盖的所有 Unicode 3.1码位。
GB18030编码在码位空间上做到了与Unicode标准一一对应,这一点与UTF-8编码类似。
(三)Unicode字符集&UTF编码
当计算机传到世界各个国家时,为了适合当地语言和字符,设计和实现类似GB232/GBK/GB18030/BIG5的编码方案。这样各搞一套,在本地使用没有问题,一旦出现在网络中,由于不兼容,互相访问就出现了乱码现象。
为了解决这个问题,一个伟大的创想产生了——Unicode。Unicode编码系统为表达任意语言的任意字符而设计。
它使用4字节的数字来表达每个字母、符号,或者表意文字(ideograph)。 每个数字代表唯一的至少在某种语言中使用的符号。
每个字符对应一个数字,每个数字对应一个字符。即不存在二义性。不再需要记录"模式"了。
在计算机科学领域中,Unicode(统一码、万国码、单一码、标准万国码)是业界的一种标准,它可以使电脑得以体现世界上数十种文字的系统。Unicode 是基于通用字符集(Universal Character Set)的标准来发展,Unicode 就已经包含了超过十万个字符、一组可用以作为视觉参考的代码图表、一套编码方法与一组标准字符编码、一套包含了上标字、下标字等字符特性的枚举等。
Unicode 组织(The Unicode Consortium)是由一个非营利性的机构所运作,并主导 Unicode 的后续发展,其目标在于:将既有的字符编码方案以Unicode 编码方案来加以取代,特别是既有的方案在多语环境下,皆仅有有限的空间以及不兼容的问题。
1、Unicode
Unicode是国际组织制定的可以容纳世界上所有文字和符号的字符编码方案。Unicode用数字0-0x10FFFF来映射这些字符,最多可以容纳1114112个字符。Unicode只是一个符号集, 它只规定了符号的二进制代码, 却没有规定这个二进制代码应该如何存储。比如UTF-8、UTF-16、UTF-32都是Unicode编码的实现方式,不过UTF-8是使用最多的实现。
Unicode是字符集,UTF-32/ UTF-16/ UTF-8是三种字符编码方案。
2、UTF-8
UTF-8 :UTF-8 中的代码单元由 8 位组成;在 UTF-8
中,因为代码单元较小的缘故,每个代码点常常被映射到多个代码单元。代码点将被映射到一个、两个、三个或四个代码单元;
UTF-8:被定义为将代码点编码为1至4个字节,具体取决于代码点数值中有效位的数量。
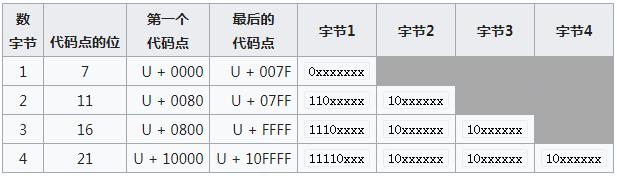
前128个字符(US-ASCII)需要一个字节。接下来的1,920个字符需要两个字节进行编码,其中涵盖了几乎所有拉丁字母字母的其余部分,还包括希腊语,西里尔语,科普特语,亚美尼亚语,希伯来语,阿拉伯语,叙利亚语,塔那那语和N’Ko字母以及组合变音词马克。剩余基本多语言平面中的字符需要三个字节,其中几乎包含所有常用字符,包括大多数字符中文,日文和韩文字符。Unicode的其他平面中的字符需要四个字节,其中包括不常见的CJK字符,各种历史脚本,数学符号和表情符号(象形符号)。
注意:虽然说utf是为了使用更少的空间而使用的,但那只是相对于unicode编码来说,如果已经知道是汉字,则使用GB2312/GBK无疑是 最节省的。不过另一方面,值得说明的是,虽然utf编码对汉字使用3个字节,但即使对于汉字网页,utf编码也会比unicode编码节省,因为网页中包 含了很多的英文字符。
3、UTF-16
UTF-16 :UTF-16 中的代码单元由 16 位组成;UTF-16 的代码单元大小是 8 位代码单元的两倍。所以,标量值小于 U+10000 的代码点被编码到单个代码单元中;
4、UTF-32
UTF-32:UTF-32 中的代码单元由 32 位组成; UTF-32 中使用的 32 位代码单元足够大,每个代码点都可编码为单个代码单元;
(四)GBK编码和UTF-8编码关系
目前国内一些发行的WEB开源框架,都提供这两种编码格式。
不过既然UTF-8是世界通用的,支持全世界的字符编码;为什么还有人选择使用GBK这种主要为针对中文的编码格式?
中文领域GBK比UTF-8存储小
GBK是字节结构定长的编码;每个字符占用两个字节的编码,并收录了基本能接触到的所有中文字,和其他部分字符的扩充。
UTF-8可变多字节编码;多数中文字符都会占用不小于两个字节的编码。
所以如果软件不考虑兼容国外字符的话,使用GBK会减少代码传输和代码存储。
(五)简单小结
1、ASCII用于表示英文字符,是用7位表示的,能表示128个字符;其扩展使用8位表示,表示256个字符;
2、GB2312简体中文的编码格式,只支持6763个常用汉字;
3、GBK是GB2312*础上扩容后兼容GB2312的标准,包含全部中文字符,支持简体中文及繁体中文;
4、GBK通用性比UTF8差,不过UTF8占用的数据库比GBK大; GB2312、GBK到GB18030都属于双字节字符集 (DBCS);
5、从ASCII、GB2312、GBK到GB18030,这些编码方法是向下兼容的,即同一个字符在这些方案中总是有相同的编码,后面的标准支持更多的字符。在这些编码中,英文和中文可以统一地处理。区分中文编码的方法是高字节的最高位不为0;
三、字符的相关属性

这个字体为:宋体,颜色为:黑色,大小为:166px。
(一)字体
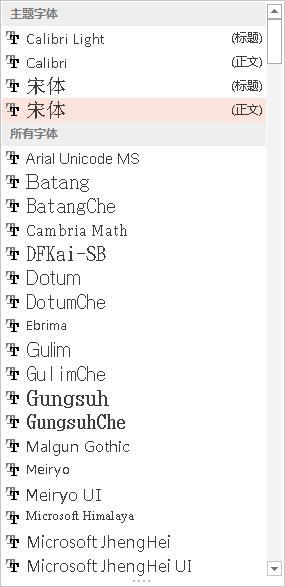
ppt里面有很多的字体,从列表中可以看出,我们在使用中可以使用默认字体,也可以自己下载ttf文件安装新的字体
(二)颜色
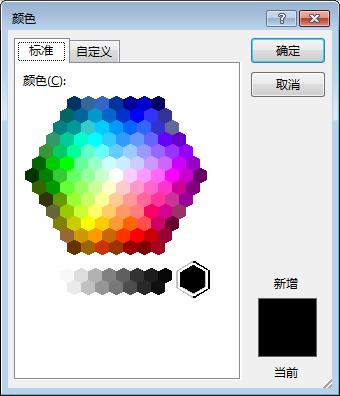
颜色框里有各种颜色,可以使用RGB模式、也可以使用HLR模式等等。
而且在代码中可以通过随机数生成需要的颜色、或者自定义想要的颜色。
(三)大小
可以自定义字体大小、一般用的比较多的都是10-30px的字体大小。
好的,上面介绍了基础知识,那么下面开始进入代码环节,欢迎继续往下看。
四、pygame库中处理字符
(一)get_fonts函数
pygame中有一个方法叫做get_fonts(),该方法的返回值是一个列表,列表存储的是系统中所有的字体文件名称。
通过这段代码输出系统中所有字体文件的名称
import pygame
font_list = pygame.font.get_fonts()
print(len(font_list))
print(font_list)
输出结果如下:

可以看到有200多种默认字体可以选择。
(二)查找字体
import pygame
font_list = pygame.font.get_fonts()
print(len(font_list))
print(font_list)
# 查找字体位置
print(font_list.index('microsoftjhengheimicrosoftjhengheiui'))
print(font_list.index('simsun'))
输出结果如下:
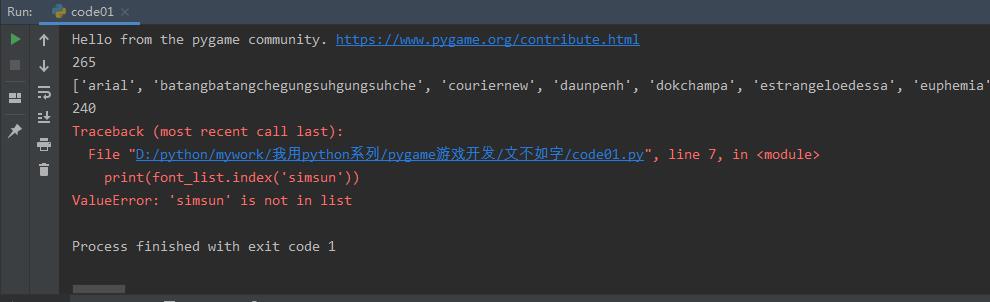
可以看到:microsoftjhengheimicrosoftjhengheiui这个微软简体,为默认字体,可以显示中文,而另外一个字体simsum则不是默认字体,所以无法查询到。
这里使用的是list列表查找字符串元素的方法index来定位位置。
(三)SysFont函数
使用系统自带的字体: my_font = pygame.font.SysFont("arial", 16)
(四)Font函数
使用自定义的字体: my_font = pygame.font.Font("simsun.ttf", 16)
第一个参数是字体名,第二个自然就是大小.
(五)render函数
text_surface = my_font.render("hello python", True, (0,0,0), (255, 255, 255))
第一个参数是写的文字;
第二个参数是个布尔值,以为这是否开启抗锯齿,就是说True的话字体会比较平滑,不过相应的速度有一点点影响;
第三个参数是字体的颜色;
第四个是背景色,如果你想没有背景色(也就是透明),那么可以不加这第四个参数。
(六)显示中文
如何显示中文, 首先你得用一个可以使用中文的字体,宋体、黑体什么的,或者你直接用中文TTF文件,然后文字使用unicode,即u”中文的文字”这种。
(七)字符显示过程
创建了一个font对象,你就可以使用render方法来写字了,然后就能blit到屏幕上
实现一个简单案例:
import sys, pygame
import os
import random
import time
pygame.init() # 初始化pygame类
screen = pygame.display.set_mode((600, 600)) # 设置窗口大小
pygame.display.set_caption('python系列之文不如字') # 设置窗口标题
tick = pygame.time.Clock()
fps = 10 # 设置刷新率,数字越大刷新率越高
fcclock = pygame.time.Clock()
while True:
for event in pygame.event.get():
if event.type == pygame.QUIT or event.type == pygame.K_F1:
pygame.quit()
sys.exit()
screen.fill((0, 0, 0)) # 设置背景为白色
info = pygame.font.SysFont("arial", 25)
info_fmt = info.render("祝我们健康快乐", True, (255, 255, 255))
screen.blit(info_fmt, (100, 250))
fcclock.tick(fps)
pygame.display.flip() # 刷新窗口
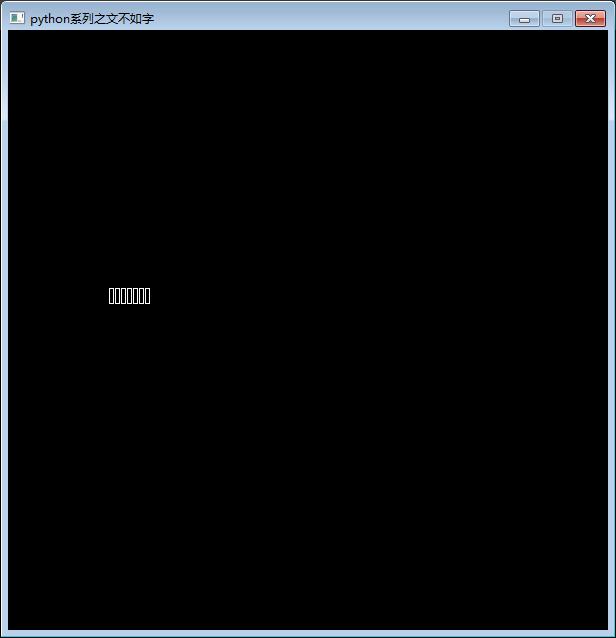
显示结果乱码了,无法正常显示中文字符
(八)解决中文乱码问题
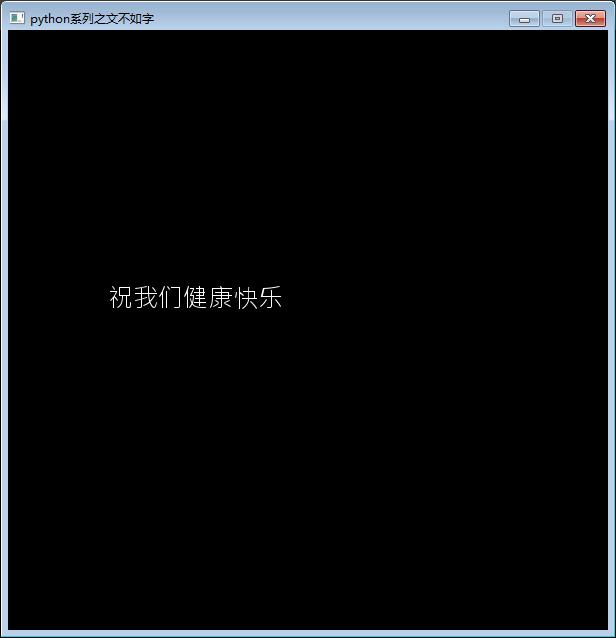
使用能显示中文的默认字库,如这里选择microsoftjhengheimicrosoftjhengheiui这个微软简体。
修改为:
info = pygame.font.SysFont("microsoftjhengheimicrosoftjhengheiui", 25)
显示效果如下:
(九)使用Font函数构建字符
import sys, pygame
import os
import random
import time
pygame.init() # 初始化pygame类
screen = pygame.display.set_mode((600, 600)) # 设置窗口大小
pygame.display.set_caption('python系列之文不如字') # 设置窗口标题
tick = pygame.time.Clock()
fps = 10 # 设置刷新率,数字越大刷新率越高
fcclock = pygame.time.Clock()
while True:
for event in pygame.event.get():
if event.type == pygame.QUIT or event.type == pygame.K_F1:
pygame.quit()
sys.exit()
screen.fill((0, 0, 0)) # 设置背景为白色
font1 = pygame.font.Font(r'C:\\Windows\\Fonts\\simsun.ttc', 32)
info_fmt = font1.render("祝我们健康快乐", True, (255, 255, 255))
print(font1.size("祝我们健康快乐"))
# screen.blit(info_fmt, (100, 250))
fcclock.tick(fps)
pygame.display.flip() # 刷新窗口
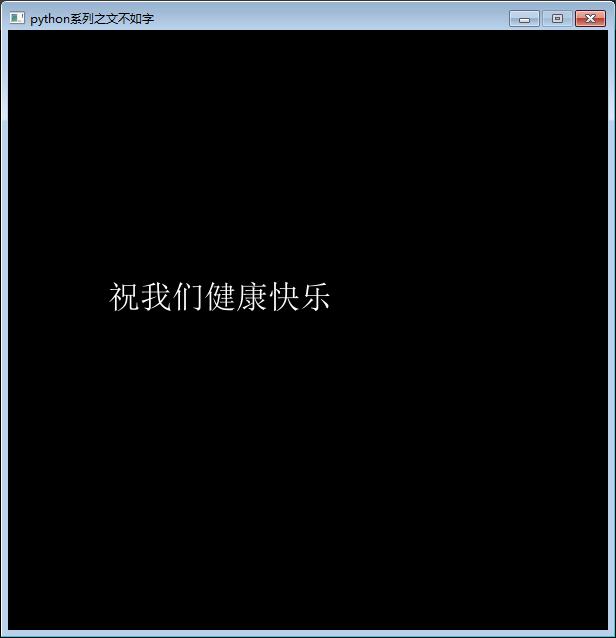
(十)Font对象的其他方法
| 方法名称 | 方法说明 |
|---|---|
| pygame.font.Font.size() | 确定多大的空间用于表示文本 |
| pygame.font.Font.set_underline() | 控制文本是否用下划线渲染 |
| pygame.font.Font.get_underline() | 检查文本是否绘制下划线 |
| pygame.font.Font.set_bold() | 启动粗体字渲染 |
| pygame.font.Font.get_bold() | 检查文本是否使用粗体渲染 |
| pygame.font.Font.set_italic() | 启动斜体字渲染 |
| pygame.font.Font.metrics() | 获取字符串参数每个字符的参数 |
| pygame.font.Font.get_italic() | 检查文本是否使用斜体渲染 |
| pygame.font.Font.get_linesize() | 获取字体文本的行高 |
| pygame.font.Font.get_height() | 获取字体的高度 |
| pygame.font.Font.get_ascent() | 获取字体顶端到基准线的距离 |
| pygame.font.Font.get_descent() | 获取字体底端到基准线的距离 |
import sys, pygame
import os
import random
import time
pygame.init() # 初始化pygame类
screen = pygame.display.set_mode((300, 300)) # 设置窗口大小
pygame.display.set_caption('python系列之文不如字') # 设置窗口标题
tick = pygame.time.Clock()
fps = 10 # 设置刷新率,数字越大刷新率越高
fcclock = pygame.time.Clock()
while True:
for event in pygame.event.get():
if event.type == pygame.QUIT or event.type == pygame.K_F1:
pygame.quit()
sys.exit()
screen.fill((224, 224, 224)) # 设置背景为白色
font1 = pygame.font.Font(r'C:\\Windows\\Fonts\\禹卫书法行书简体.ttf', 32)
font1.set_bold(True)
font1.set_underline(True)
info_fmt = font1.render(u'祝我们健康快乐', True, (255, 0, 128))
print(font1.get_bold())
screen.blit(info_fmt, (0, 100))
fcclock.tick(fps)
pygame.display.flip() # 刷新窗口
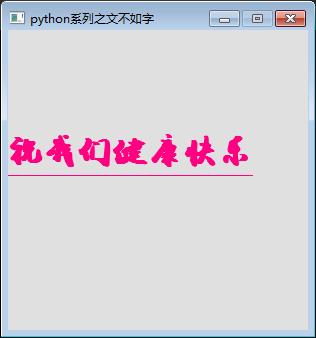
(十一)save成图片
import sys, pygame
import os
import random
import time
pygame.init() # 初始化pygame类
screen = pygame.display.set_mode((300, 300)) # 设置窗口大小
pygame.display.set_caption('python系列之文不如字') # 设置窗口标题
screen.fill((224, 224, 224)) # 设置背景为白色
font1 = pygame.font.Font(r'C:\\Windows\\Fonts\\禹卫书法行书简体.ttf', 32)
font1.set_bold(True)
font1.set_underline(True)
info_fmt = font1.render(u'祝我们健康快乐', True, (255, 0, 128))
screen.blit(info_fmt, (0, 100))
pygame.image.save(screen, 'font.png')
输出结果

五、PIL库中处理字符
绘制文字和绘制图形是一样的。
(一)英文输出
函数draw.text(xy, text, fill)
xy:起点坐标
text:绘制的文本
fill:填充色。"red"、"blue"...
...其中绘制文字还有许多其它参数
“”"
使用示例
from PIL import Image, ImageDraw, ImageFont
# 创建一个图像用于绘制文字
im = Image.new("RGB", (300, 300), "white")
drawer = ImageDraw.Draw(im)
# 获取字体对象
imFont = ImageFont.truetype('simkai.ttf', 30)
# 绘制文字时设置字体
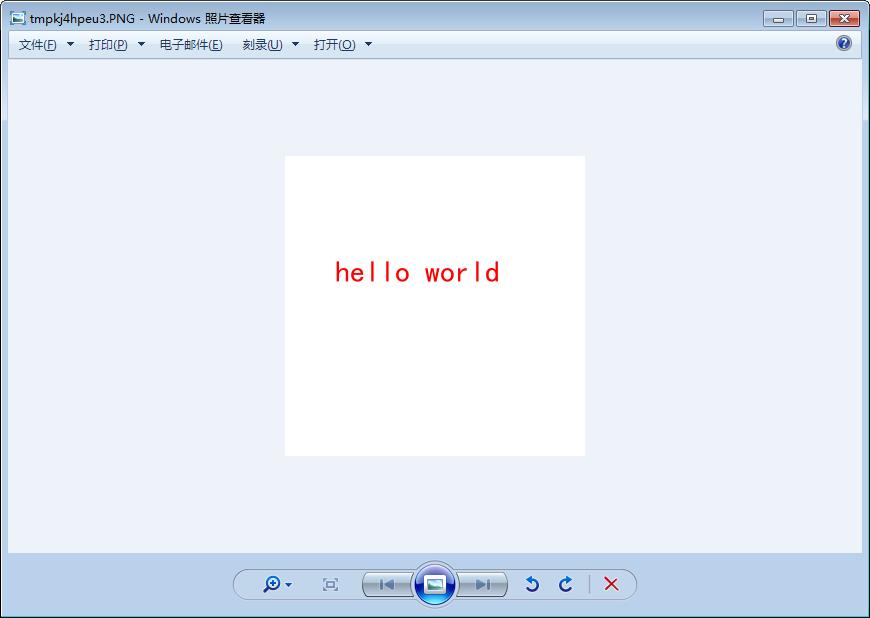
drawer.text((50, 100),text="hello world",font=imFont,fill="red")
im.show()
(二)中文输出
from PIL import Image, ImageDraw, ImageFont
# 创建一个图像用于绘制文字
im = Image.new("RGB", (300, 300), "white")
drawer = ImageDraw.Draw(im)
# 获取字体对象
imFont = ImageFont.truetype('simkai.ttf', 30)
# 绘制文字时设置字体
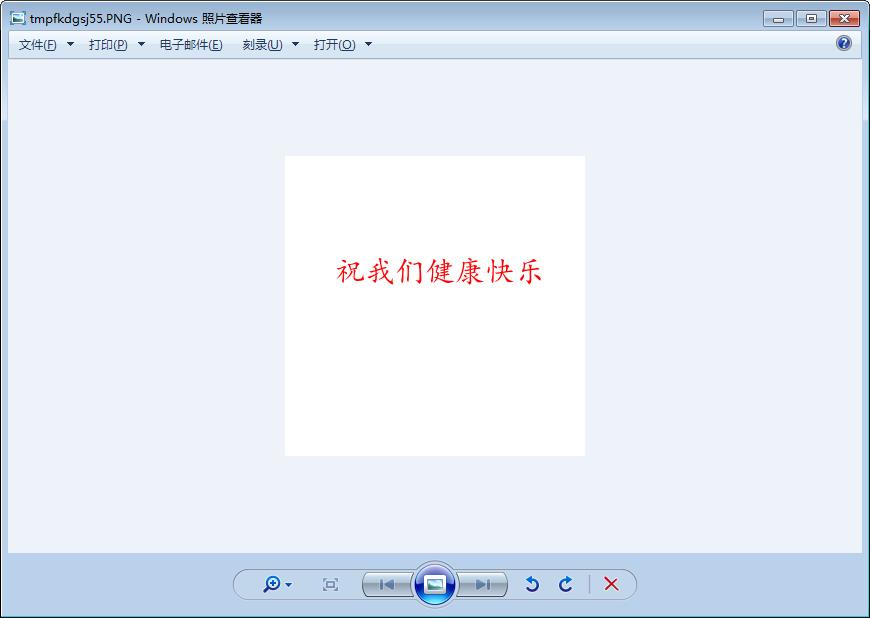
drawer.text((50, 100),text="祝我们健康快乐",font=imFont,fill="red")
im.show()
六、tkinter库中处理字符
Tkinter 是 Python 标准 GUI 库,其最初是为 Tcl(这是一门工具命令语言,而不是某个电视机品牌)设计的,由于其良好的可移植性和灵活性,加上非常容易使用,因此逐渐被移植到很多脚本语言中,包括 Perl、Ruby 和 Python。 本章就来重点介绍Tkinter库。由于它是 Python 自带的 GUI 库,因此无须进行额外的下载安装,只要导入 tkinter 包即可。
(一)标签(Label)的颜色、字体和大小
#导入tkinter库,并设置别名为tk
import tkinter as tk
# 创建Tk对象,Tk代表窗口
root =tk.Tk()
# 设置窗口标题
root.title('入门案例')
# 创建Label对象,第一个参数指定该Label放入root
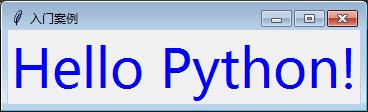
w =tk.Label(root, text="Hello Python!",fg='blue',font=("微软雅黑",40))
# 调用pack进行布局
w.pack()
# 启动主窗口的消息循环
root.mainloop()
通过关键代码实现字符的大小、颜色和字体类型
w =tk.Label(root, text="Hello Python!",fg='blue',font=("微软雅黑",40))
输出效果:
(二)entry文本框显示
from tkinter import *
root =Tk()
root.title("tk文本框演示")
root.geometry('400x200')
text =Text(root, height=12, width=60,
foreground='darkgray',
font=('微软雅黑',36),
spacing2=8,# 设置行间距
spacing3=12)# 设置段间距
text.pack(fill=BOTH,expand=Y)
root.mainloop()
绘制文字的代码:
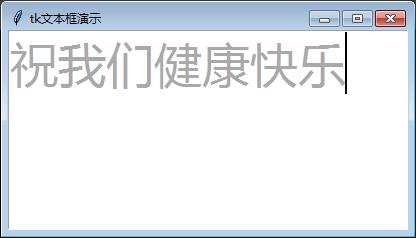
text =Text(root, height=12, width=60,
foreground='darkgray',
font=('微软雅黑',36),
spacing2=8,# 设置行间距
spacing3=12)# 设置段间距
显示效果:
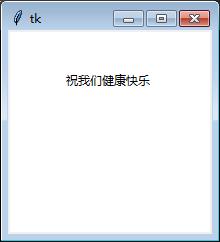
(三)canvas绘制文字
from tkinter import *
def main():
root = Tk()
w = Canvas(
root,
width=200,
height=200,
background="white"
)
w.pack()
w.create_text(100, 50, text='祝我们健康快乐')
mainloop()
if __name__ == '__main__':
main()
绘制文字的代码:
w.create_text(100, 50, text='祝我们健康快乐')
输出效果:
七、CMD命令行中处理字符
(一)实现过程
终端的字符颜色是用转义序列控制的,是文本模式下的系统显示功能,和具体的语言无关。
转义序列是以ESC开头,即用\\033来完成(ESC的ASCII码用十进制表示是27,用八进制表示就是033)。
(二)格式要求
开头部分:\\033[显示方式;前景色;背景色m + 结尾部分:\\033[0m
注意:开头部分的三个参数:显示方式,前景色,背景色是可选参数,可以只写其中的某一个;另外由于表示三个参数不同含义的数值都是唯一的没有重复的,所以三个参数的书写先后顺序没有固定要求,系统都能识别;但是,建议按照默认的格式规范书写。
对于结尾部分,其
以上是关于python文不如字之开篇之作PILtkinterpygame和CMD命令行实战演示字符字符集字符编码知识的主要内容,如果未能解决你的问题,请参考以下文章