用python搞网络爬虫开发,你把握住了吗?(系列文章建议收藏)
Posted 通信汪的美好生活
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用python搞网络爬虫开发,你把握住了吗?(系列文章建议收藏)相关的知识,希望对你有一定的参考价值。
目录
(4)从URL队列中读取新的URL,并爬取该网页,同时从新的网页中获取新的URL地址,重复上述的爬取过程
前言
之前发过一个系列《Python语法学的咋样了,确定不看看这100道习题?》链接如下代码段中所示,python语法不太好的可以先练练这些题在看基于python的一些简单应用。
https://blog.csdn.net/qq_45049500/article/details/117365950?spm=1001.2014.3001.5501那么我这个系列要写什么呢:
| 一、网络爬虫概述 | 1、网络爬虫概述 |
| 2、网络爬虫的分类 | |
| 3、网络爬虫的基本原理 | |
| 二、网络开发的常用技术 | 1、python的网络请求 |
| 2、对请求headers的处理 | |
| 3、网络超时 | |
| 4、代理服务 | |
| 5、html解析 | |
| 三、网络爬虫开发常用的框架 | 1、Scrapy爬虫框架 |
| 2、Crawiey爬虫框架 | |
| 3、PySpider爬虫框架 |
网络爬虫,可以按照指定的规则(一些常见的网络爬虫算法)自动浏览或爬取网络中的信息,通过python可以轻松地编写爬虫程序或者脚本。这个系列就介绍通过python实现网络爬虫的一些基本知识和常用技术,有些专有名词对于小白来说可能不太友好,会通过具体的例子去解释这些专有名词是干什么的。
网络爬虫概述
你可能经常听别人说python爬虫特别好,可以特别快的获取大量信息或数据,那么这个爬虫的工作流程都有那几步那?
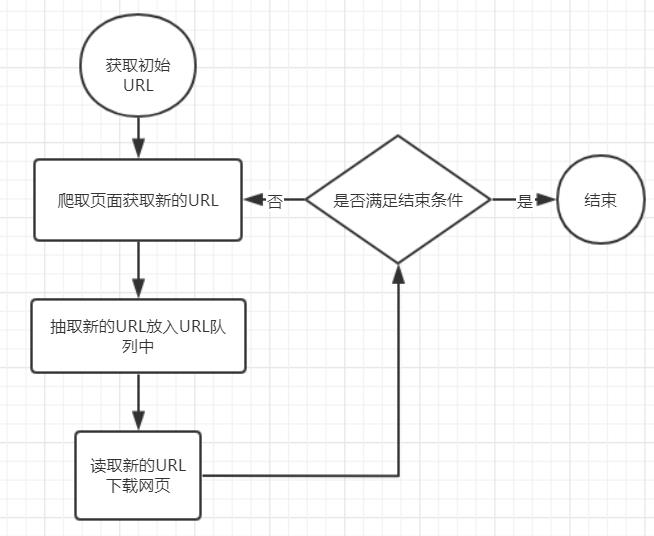
爬虫基本工作流程
(1)获取初始的URL
做什么事情都是这样,首先要明确自己要爬什么,这个URL地址是用户自己制定的初始爬取的页面,比如你要爬csdn,其网址如下。
""" 最简单的爬虫例子,使用的python自带的库,不用安装新库"""
import urllib.request
response=urllib.request.urlopen("https://blog.csdn.net/")#url就是括住的这些东西
print(html)
(2)爬取对应URL地址的网页时,获取新的URL地址。
上面的代码里面只爬了一个网页,我们可以把所有待爬取的URL放到一个数组或列表里面,然后就可以不断的爬取了。
(3)将新的URL地址放入URL队列里面。
(4)从URL队列中读取新的URL,并爬取该网页,同时从新的网页中获取新的URL地址,重复上述的爬取过程
有点懵对吗,我解释一下,一个网页是由特别多东西组成的,URL也是其中之一,也可以是我们爬取的内容,我们爬网页时也可以把网页内的URL作为我们下一次要爬取的内容。
(5)设置结束的条件
如果没有设置停止条件,爬虫会一直爬取下去,直到无法获取新的URL地址才会自动停止。设置了停止条件后,爬虫将会在满足停止条件是结束爬取。
结尾
下次聊一下网络爬虫的分类和网络爬虫的基本原理,知识的学习是一个过程,把握一个东西不在于你见过,而在于你做过。
以上是关于用python搞网络爬虫开发,你把握住了吗?(系列文章建议收藏)的主要内容,如果未能解决你的问题,请参考以下文章