特征工程之特征选择----嵌入法(Embed)
Posted iostreamzl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了特征工程之特征选择----嵌入法(Embed)相关的知识,希望对你有一定的参考价值。
文章目录
前言
前面的(1)、(2)、(3)篇文章,我们讲了过滤法的使用。过滤法是依据我们的阈值过滤数据,再将数据导入模型。这里我们将一个新的方法----嵌入法
嵌入法概述
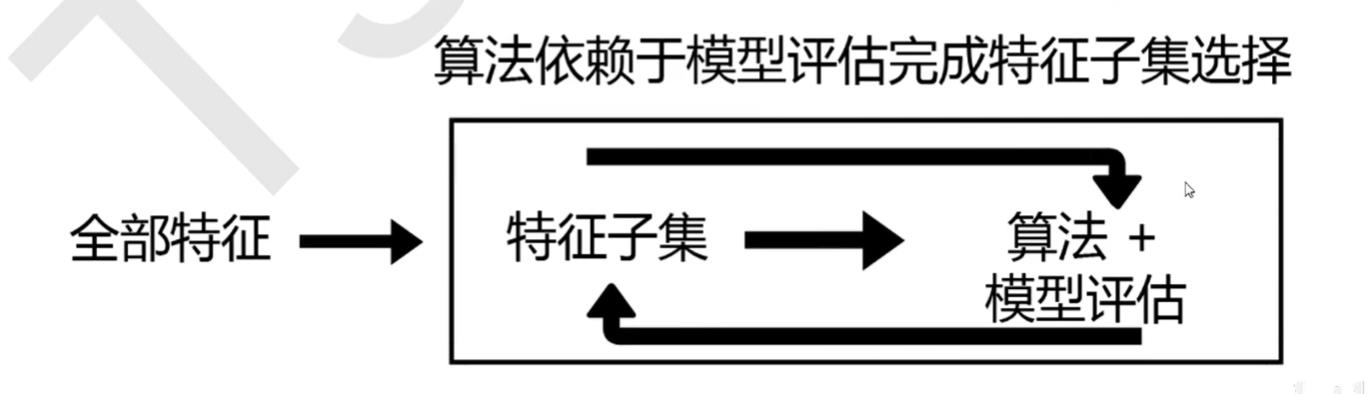
嵌入法是一种让算法自己决定使用哪些特征的方法,即特征选择和模型训练同时进行。
在使用嵌入法时,我们先使用某些机器学习的算法或模型进行训练,得到各个特征的权值系数(0-1之间)。
这些权值系数往往代表了特征对模型的贡献或者说重要性。
比如决策树的feature_importance_属性。可以列出每个特征对决策树建立的贡献,我们可以基于这种贡献的评估,找出对模型建立更加有用的特征
因此相比于过滤法,嵌入法的结果会更加精确到模型的效用本身,对提高模型效果有更好的作用
由于嵌入法考虑特征对模型的重要性,一些无关的特征(需要相关性过滤的特征)和一些区分度不大的特征(需要方差过滤的特征),都会因为缺乏对模型的贡献而被删除掉
可以说嵌入法是过滤法的进阶版
嵌入法的缺点
过滤法中使用的统计量可以使用统计知识和常识来查找范围(如p值应当低于显著性水平0.05),而嵌入法中使用的权值系数却没有这样的范围可找
我们可以说,权值系数为0的特征对模型丝毫没有作用,但当大量特征都对模型有贡献且贡献不一时,我们就很难去界定一个有效的临界值。这种情况下,模型权值系数就是我们的超参数,我们或许需要学习曲线,或者根据模型本身的某些性质去判断这个超参数的最佳值究竟应该是多少。
另外,嵌入法引入了算法来挑选特征,并且每次挑选都会使用全部特征,
因此其计算速度也会和应用的算法有很大的关系。如果采用计算量很大,计算缓慢的算法,比如KNN,嵌入法本身也会非常耗时耗力。并且,在选择完毕之后,我们还是需要自己来评估模型。
SelectFromModel简述
sklearn中的嵌入法模块位于feature_selection下
from sklearn.feature_selection import SelectFromModel
SelectFromModel是一个元变换器,可以与任何再拟合后具有coef_,feature_importances_属性
或参数中可选惩罚项的评估器一起使用
比如随机森林和树模型具有feature_importances_属性。逻辑回归带有l1和l2惩罚项,线性支持向量机也有l2惩罚项
对于有feature_importances_的模型来说,如果重要性低于提供的阈值,则认为这些特征不重要,并且被移除。feature_importances_的取值再0-1之间,如果设置的阈值很小,比如0.0001就可以删除那些对模型基本没有贡献的特征。如果设置的阈值比较大,就会删除掉很多有用的特征
SelectFromModel重要参数
- estimator:使用的模型评估器,只要是有coef_,feature_importances_属性和l1, l2惩罚项的模型都可以,一定是实例化后的模型对象
- threshold:特征重要性的阈值,低于这个值都会被删除
- max_features:再阈值设定下,要选择的最大特征数,要禁用阈值,并且仅根据max_features来选择,则需要设置threshold=-np.inf
示例
这里使用的还是kaggle的digit-recognizer数据集,原数据下载地址,快捷下载。
导入相关的库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestClassifier # 随机森林分类器
from sklearn.model_selection import cross_val_score # 交叉验证
from sklearn.feature_selection import SelectFromModel # sklearn的嵌入法模块
%matplotlib inline
数据准备
file_name = "e://anaconda/machine-learning/test1/data/digit-recognizer/train.csv"
df = pd.read_csv(file_name)
X = df.loc[:, df.columns != 'label']
y = df.loc[:, df.columns == 'label'].values.ravel()
X.shape # (42000, 784)
实例化评估器
关于随机森林看这篇文章
rfc = RandomForestClassifier(n_estimators=21, random_state=1)
# 设置random_state保证模型的稳定
经验法设置阈值(不推荐)
设置阈值,获得筛选后的数据
这个方法虽然省事,但是呢毕竟阈值是自己猜想的,很难找到最优的阈值,这里不太推荐这种方法,看看就好了。
sf = SelectFromModel(rfc, threshold=0.005)
X_embeded_005 = sf.fit_transform(X, y)
X_embeded_005.shape
# (42000, 46)
# 筛掉了700多个特征,太夸张了,一看就是阈值设置太大了
# 所以说根据自己的经验设置阈值比较难
模型评估
score_005 = cross_val_score(rfc, X_embeded_005, y, cv=5).mean()
score_005
# 0.8969535142104432
嗯。不出意料果然降低了很多
原数据一共700多个特征,分到每一个特征,那么平均每一个特征重要性0.001左右
这里0.005明显大了好多,筛掉了太多特征了
所以接下来就是画学习曲线了
通过学习曲线找出最佳阈值
获得特征重要性的最大值
max_importance = (rfc.fit(X, y).feature_importances_).max()
max_importance
# 0.01162143838996445,真的是挺小的
关于threshold的大致学习曲线
# 将threshold阈值设置为0-max_importance之间的20个点,初步找出最佳阈值范围,再继续细化
# 这一步比较耗时,大概十几分钟一条学习曲线吧
thresholds = np.linspace(0, max_importance, 20)
rough_scores = []
for i in thresholds :
X_new = SelectFromModel(rfc, threshold=i).fit_transform(X, y)
rough_scores.append(cross_val_score(rfc, X_new, y, cv=5).mean())
plt.figure(figsize=(20, 5))
plt.plot(thresholds, rough_scores)
plt.xticks(thresholds)
plt.show()
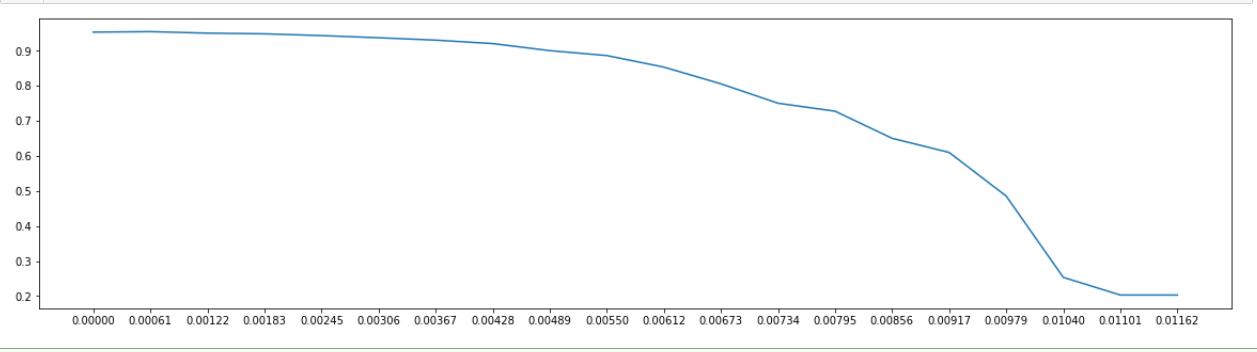
从图中可以看出来,在阈值为0.00183之前,模型表现都是比较稳定的,后面就开始急剧下降了。所以可以知道最优的阈值在0-0.00183之间,接下来就是细化学习曲线,寻找最优阈值了。
max(rough_scores) # 0.9549047543376276
# 前面相关性过滤最大得分0.9547383538977157
# 提高了一点,已经很不错了
#这里大致的学习曲线已经有得分高于过滤法的得分,
#说明有进一步探究阈值的必要
实际上只要是模型表现有接近前面过滤法的模型表现,就有继续探究的必要。
阈值为0.00183时的模型表现
# 在0.00183之前都是比较平稳的
# 看看0.00183的时候特留下的特征数目,以及模型得分
sf_00183 = SelectFromModel(rfc, threshold=0.00183)
X_embeded_00183 = sf_00183.fit_transform(X, y)
X_embeded_00183.shape # (42000, 196)
score_00183 = cross_val_score(rfc, X_embeded_00183, y, cv=5).mean()
score_00183
# 0.948642995847911
寻找最优阈值
这里我只进行了一次细化,毕竟跑学习曲线还是比较费时的,跑一次5min左右呢。有兴趣的小伙伴可以多做几次看看结果如何
# 接下来进一步的画学习曲线,找出最好的阈值
# 刚刚的学习曲线可以看到阈值再0.00183之前都很平稳
# 这里再进一步在0-0.00183之间细分20个点,画学习曲线
thresholds = np.linspace(0, 0.00183, 20)
accurate_scores = []
for i in thresholds :
sf = SelectFromModel(rfc, threshold=i)
X_new = sf.fit_transform(X, y)
accurate_scores.append(cross_val_score(rfc, X_new, y, cv=5).mean())
plt.figure(figsize=(20, 5))
plt.plot(thresholds, accurate_scores)
plt.xticks(thresholds)
plt.show()
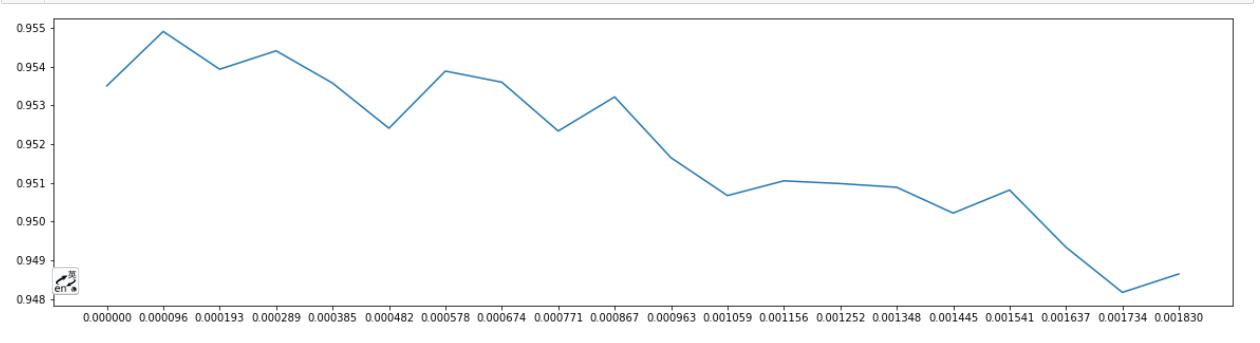
从图中看出阈值为0.000096时模型表现最好
阈值为0.000096时模型表现
X_embeded_000096 = SelectFromModel(rfc, threshold=0.000096).fit_transform(X, y)
X_embeded_000096.shape
# (42000, 451)
# 这里可以反映出前面的过滤法筛出了一些有用的特征
score_000096 = cross_val_score(rfc, X_000096, y, cv=5).mean()
score_000096
# 当前得分:0.9549055080678807
# 粗略学习曲线最好得分:0.9549047543376276
# 过滤法得分:0.9547383538977157
# 模型的效果明显提高了
进一步调参
刚才的随机森林分类器中只有21棵树,这是很小的一片森林,接下来调高树的数量,效果显著
# 接下来让随机森林的n_estimators变大看看
score_000096_n_estimators_101 = cross_val_score(RandomForestClassifier(n_estimators=101, random_state=1),
X_embeded_000096, y, cv=5).mean()
score_000096_n_estimators_101
# 0.9633097415038214
# 21棵树的得分:0.9549055080678807
# 模型果然提高了很多,
想继续探索的可以继续随机森林的画学习曲线来继续了解,不过想想巨耗时间,我就不尝试了,随机森林的调参思路看这篇文章。
总结
在嵌入法下我们很容易就能实现特征选择的目标:减少计算量,提高模型表现。
比起过滤法要思考很多的统计量,嵌入法的确是一种很有效的方法,但是嵌入法运行时间比过滤法慢很多,毕竟嵌入法需要跑模型来选择特征。所以大型的数据,优先过滤法。
下面一篇文章,我们将学习过滤法与嵌入法的结合----包装法
以上是关于特征工程之特征选择----嵌入法(Embed)的主要内容,如果未能解决你的问题,请参考以下文章