SiamMOT解读
Posted 周先森爱吃素
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SiamMOT解读相关的知识,希望对你有一定的参考价值。
SiamMOT解读
AWS的一篇新的MOT工作,将孪生跟踪器引入多目标跟踪中进行运动建模并获得了SOTA表现。
简介
通过引入一个基于区域的孪生多目标跟踪网络,设计了一个新的online多目标跟踪框架,名为SiamMOT。SiamMOT包含一个运动模型来估计两帧之间目标的移动从而关联两帧上检测到的目标。为了探索运动建模如何影响其跟踪能力,作者提出了孪生跟踪器的两种变体,一种隐式建模运动,另一种显式建模运动。在三个MOT数据集上进行实验,作者证明了运动建模对于多目标跟踪的重要性并验证了SiamMOT达到SOTA的能力。而且,SiamMOT是非常高效的,它可以在单个GPU上720P视频上达到17的FPS。
-
论文标题
SiamMOT: Siamese Multi-Object Tracking
-
论文地址
http://arxiv.org/abs/2105.11595
-
论文源码
https://github.com/amazon-research/siam-mot
介绍
多目标跟踪(Multiple Object Tracking,MOT)任务指的是检测出每一帧上的所有目标并跨帧在时间上将其关联起来形成轨迹。早期的一些工作将数据关联视为TBD范式下的图优化问题,在这类方法中一个节点代表一个检测框而一条边则编码两个节点链接到一起的可能性(或者说相似度)。实际上,这些方法往往采用视觉线索和运动线索的组合来表示一个节点,这通常需要比较大的计算量。而且,他们通常会构建一个很大的离线图,基于这个图做求解并不容易,这就限制了这类方法在实时跟踪上的可能性。
最近,online方法开始兴起,它们在实时跟踪场景中更受欢迎。它们更加关注于改进相邻帧上的关联而不是基于较多帧构建离线图进行关联。Tracktor等方法的诞生将online MOT的研究推向了一个新的高峰,使得这个领域的研究如火如荼了起来。
这篇论文中,作者探索了以SORT为基础的一系列online多目标跟踪方法中运动建模的重要性。在SORT中,一个更好的运动模型是提高跟踪精度的关键,原始的SORT中采用基于简单几何特征的卡尔曼滤波进行运动建模,而最近的一些SOTA方法学习一个深度网络来基于视觉和几何特征进行位移预测,这极大地提高了SORT的精度。
作者利用基于区域的孪生多目标跟踪网络来进行运动建模的探索,称其为SiamMOT。作者组合了一个基于区域的检测网络(Faster R-CNN)和两个思路源于孪生单目标跟踪的运动模型(分别是隐式运动模型(IMM)和显式运动模型(EMM))。不同于CenterTrack基于点的特征进行隐式的目标运动预测,SiamMOT使用基于区域的特征并且开发了显式的模板匹配策略来估计模板的运动,这在一些挑战性的场景下更加具有鲁棒性,比如高速运动的场景下。
作者还通过额外的消融实验证明目标级别的运动建模对鲁棒多目标跟踪至关重要,特别是在一些挑战性场景下。而且,实验表明,SiamMOT的运动模型可以有效提高跟踪的性能,尤其是当相机高速运动或者行人的姿态变化较大时。
最后,说明一下,论文中提到的孪生跟踪器和通常所说的孪生网络是不一样的,孪生网络的目的是学习两个实例之间的亲和度函数,而孪生跟踪器则学习一个匹配函数,该函数用于在一个较大的上下文区域内找到一个匹配的检测框。
SiamMOT
SiamMOT是基于Faster R-CNN构建的,Faster R-CNN是一个非常流行的目标检测器,它包含一个区域推荐网络(RPN)和一个基于区域的检测网络。在标准的Faster R-CNN上,SiamMOT添加了一个基于区域的孪生跟踪器来建模实例级别的运动。下图是整个SiamMOT的框架结构,它以两帧图像 I t , I t + δ \\mathbf{I}^{t}, \\mathbf{I}^{t+\\delta} It,It+δ作为输入,并且已有第 t t t帧上的检测框集合 R t = { R 1 t , … R i t , … } \\mathbf{R}^{t}= \\left\\{R_{1}^{t}, \\ldots R_{i}^{t}, \\ldots\\right\\} Rt={R1t,…Rit,…}。在SiamMOT中,检测网络输出第 t + δ t+\\delta t+δ帧的检测结果集 R t + δ \\mathbf{R}^{t+\\delta} Rt+δ,跟踪器则将 R t \\mathbf{R}^{t} Rt传播到 t + δ t+\\delta t+δ帧上以生成预测框集合 R ~ t + δ \\tilde{\\mathbf{R}}^{t+\\delta} R~t+δ。接着, t t t帧上的目标在 t + δ t+\\delta t+δ帧上的预测框和 t + δ t+\\delta t+δ帧上的检测框进行匹配,从而关联起来形成轨迹,这个思路和SORT中是一样的。
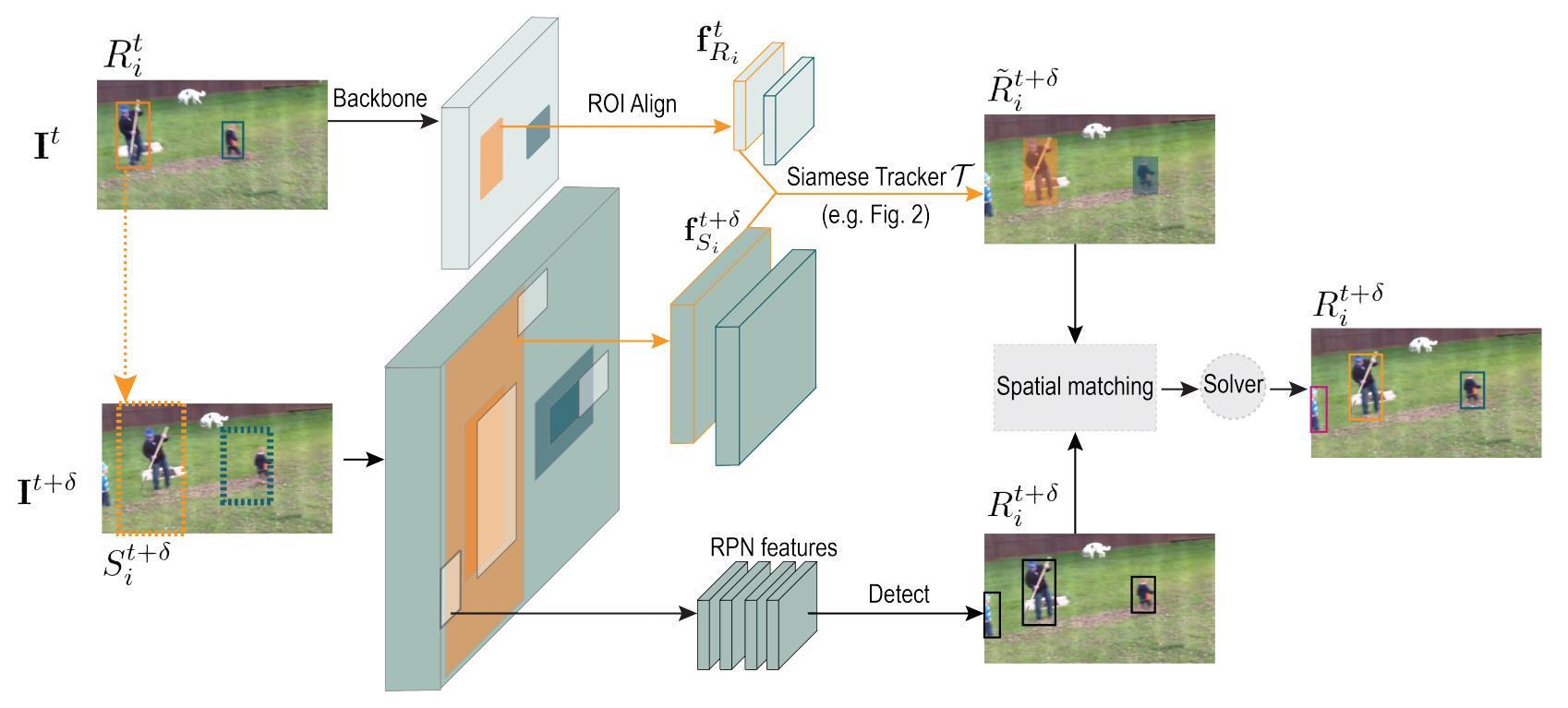
从上面的叙述不难看出来,和SORT相比作者最核心的一个工作实际上是构建了一个更好的运动模型,因此下面我们首先来看看这个孪生跟踪器是如何建模目标的运动的,以及它的两种变种,接着再叙述一下训练和推理的一些细节。
Motion modelling with Siamese tracker
给定第 t t t帧的实例 i i i,孪生跟踪器根据其在 t t t帧中的位置在 t + δ t+\\delta t+δ帧的一个局部窗口范围内搜索对应的实例,形式上表述如下。这里的 T \\mathcal{T} T表示参数为 Θ \\Theta Θ的孪生跟踪器, f R i t \\mathbf{f}_{R_{i}}^{t} fRit则是根据检测框 R i t R_{i}^{t} Rit在 t + δ t+\\delta t+δ帧上获得的搜索区域 S i t + δ S_{i}^{t+\\delta} Sit+δ提取的特征图。而搜索区域 S i t + δ S_{i}^{t+\\delta} Sit+δ的获得则通过按照比例因子 r r r(r>1)来扩展检测框 R i t R_{i}^{t} Rit来获得,拓展前后具有同样的集合中心,如上图中的黄色实线框到黄色虚线框所示。当然,不管是原来的检测框还是拓展后的预测框,获得其特征 f R i t \\mathbf{f}_{R_{i}}^{t} fRit和 f S i t + δ \\mathbf{f}_{S_{i}}^{t+\\delta} fSit+δ的方式都是不受大小影响的RoIAlign层。孪生跟踪器输出的结果有两个,其中 R ~ i t + δ \\tilde{R}_{i}^{t+\\delta} R~it+δ为预测框,而 v i t + δ v_{i}^{t+\\delta} vit+δ则是预测框的可见置信度,若该实例在区域 S i t + δ S_{i}^{t+\\delta} Sit+δ是可见的,那么 T \\mathcal{T} T将会产生一个较高的置信度得分 v i t + ε v_{i}^{t+\\varepsilon} vit+ε,否则得分会较低。
( v i t + δ , R ~ i t + δ ) = T ( f R i t , f S i t + δ ; Θ ) \\left(v_{i}^{t+\\delta}, \\tilde{R}_{i}^{t+\\delta}\\right)=\\mathcal{T}\\left(\\mathbf{f}_{R_{i}}^{t}, \\mathbf{f}_{S_{i}}^{t+\\delta} ; \\Theta\\right) (vit+δ,R~it+δ)=T(fRit,fSit+δ;Θ)
这个公式的建模过程其实和很多孪生单目标跟踪器的思路非常类似,因此在多目标跟踪场景下只需要多次使用上式即可完成每个 R i t ∈ R t R_{i}^{t} \\in \\mathbf{R}^{t} Rit∈Rt的预测。重要的是,SiamMOT允许这些操作并行运行,并且只需要计算一次骨干特征(由于RoIAlign),这大大提高了在线跟踪推理的效率。
作者发现,运动建模对于多目标跟踪任务至关重要,一般在两种情况下 R t R^{t} Rt和 R t + δ R^{t+\\delta} Rt+δ会关联失败,一是 R ~ t + δ \\tilde{R}^{t+\\delta} R~t+δ没有匹配上正确的 R t + δ R^{t+\\delta} Rt+δ,二是对于 t + δ t+\\delta t+δ帧上的行人得到的可见得分 v i t + δ v_{i}^{t+\\delta} vit+δ太低了。
此前的很多工作为了实现 R i t R_{i}^{t} Rit到 R ~ t + δ \\tilde{R}^{t+\\delta} R~t+δ的预测,一般采用将两帧的特征输入网络中,所以它们都是隐式建模实例的运动。然而,很多单目标跟踪的研究表明,在极具挑战性的场景下,细粒度的空间级监督对于显式学习一个鲁棒性的目标匹配函数是非常重要的。因此,作者提出了两种不同的孪生跟踪器,一个是隐式运动模型一个是显式运动模型。
IMM
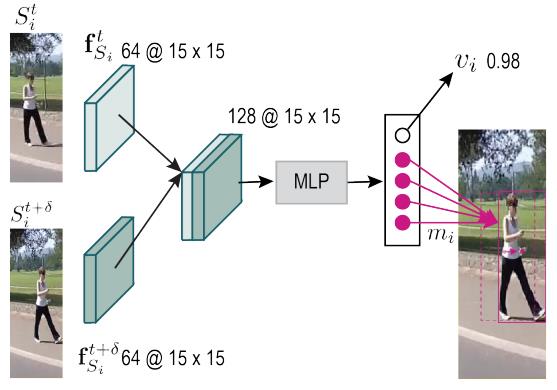
首先来看隐式运动模型(Implicit motion model,IMM),它通过MLP来估计目标两帧间的运动。具体而言,它先将特征 f R i t \\mathbf{f}_{R_{i}}^{t} f以上是关于SiamMOT解读的主要内容,如果未能解决你的问题,请参考以下文章