RelationTrack解读
Posted 周先森爱吃素
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了RelationTrack解读相关的知识,希望对你有一定的参考价值。
MOT领域的一个新的SOTA方法,在FairMOT的基础上提出了特征图解耦和全局信息下的ReID Embedding的学习,前者和CSTrack思路类似,后者则采用了Deformable DETR里的deformable attention配合Transformer Encoder来捕获和目标相关的全图信息增强ReID的表示能力。
简介
现有的多目标跟踪方法为了速度通常会将检测和ReID任务统一为一个网络来完成,然而这两个任务需要的是不同的特征,这也是之前很多方法提到的任务冲突问题。为了缓解这个问题,论文作者设计了Global Context Disentangling(GCD)模块来对骨干网络提取到的特征解耦为任务指定的特征。此外,作者还发现,此前的方法在使用ReID特征为主的关联中,只考虑了检测框的局部信息而忽视了全局语义相关性的考虑。对此,作者设计了Guided Transformer Encoder(GTE)模块来学习更好的全局感知的ReID特征,这个模块不是密集相关性的而是捕获query节点和少量的自适应关键样本位置之间的相关性信息。因此非常高效。实验表明,由GCD和GTE构成的跟踪框架RelationTrack在MOT16和MOT17上均达到SOTA表现,在MOT20上更是超过此前的所有方法。
-
论文标题
RelationTrack: Relation-aware Multiple Object Tracking with Decoupled Representation
-
论文地址
http://arxiv.org/abs/2105.04322
-
论文源码
暂未开源
介绍
目前主流的多目标跟踪方法主要包含两个子模型,即用于目标定位的检测模型和用于轨迹连接的ReID模型。分开训练检测和ReID两个模型可以在精度上获得较好的表现,然而推理速度较慢,很难达到实时跟踪的效果。一个较好的解决方案就是JDE首先提出的在一个网络中联合训练检测和ReID的思路。
遗憾的是,直接将这两个任务放到一个网络中联合优化造成了精度大幅度的下降,这是因为这两个任务存在严重的优化矛盾。对检测分支而言,它期望同类目标之间的相似度尽量高,也就是网络能够最大化不同类目标之间的距离;但是,对ReID分支而言,它则希望最大化不同实例之间的距离(对行人跟踪而言这些不同实例是同类别的)。它们不一致的优化目标阻碍了当前的MOT框架向更高效的形式发展。
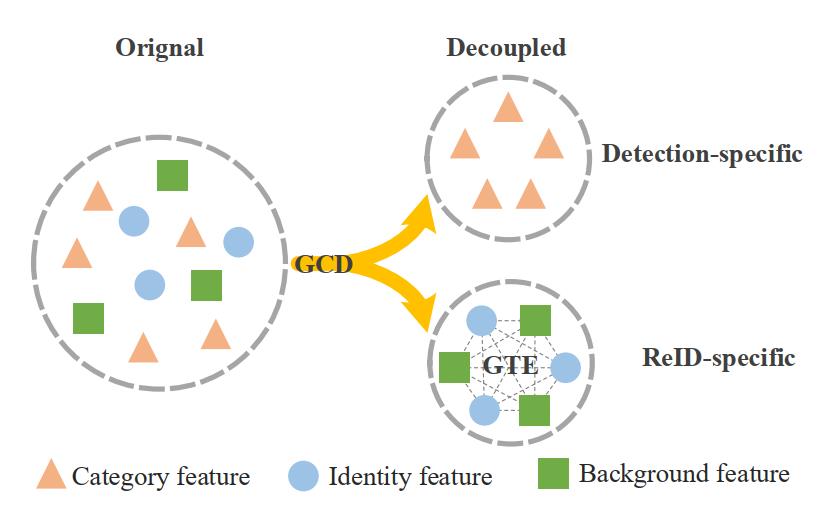
为了缓解这个矛盾,作者设计了一个特征解耦模块称为Global Context Disentangling (GCD),它将特征图解耦为检测任务指定和ReID任务指定的特征表示,如上图所示。这个模块的设计下文再阐述,不过经过实验验证,这个模块带来了1-2个点的收益,可见它对解决任务冲突是很有效的。
此外,作者发现,此前的方法通常利用局部信息来跟踪目标,然而,实际上,目标和周围目标以及背景之间的关系对于跟踪任务是非常重要的。为了捕获这种长程依赖,使用全局注意力是一个解决方案,但是全局注意力需要逐像素之间计算相关性以构成注意力图,这在计算上是代价极为昂贵的,也严重阻碍了实时MOT任务的进行。作者又发现,其实并不是所有的像素都对query node(查询节点)有影响的,因此只需要考虑和少数关键样本之间的关系可能是更好的选择,基于这个假设,作者使用deformable attention(源于Defomable DETR)来捕获上下文关系。相比于全局注意力,deformable attention是非常轻量的,计算复杂度从 O ( n 2 ) O\\left(n^{2}\\right) O(n2)降低到了 O ( n ) O\\left(n\\right) O(n)。而且,相比于基于图的受限邻域信息收集,deformable attention可以自适应选择整个图像上合适的关键样本来计算相关性。
接着,考虑到Transformer强大的建模能力,作者将deformable attention和Transformer Encoder进行了组合形成了Guided Transformer Encoder (GTE)模块,它使得MOT任务可以在全局感受野范围内捕获逐像素的相关性。
为了证明RelationTrack的效果,作者在MOT多个benchmark数据集上进行了实验,在IDF1上超越了此前的SOTA方法FairMOT3个点(MOT16)和2.4个点(MOT17)。
RelationTrack
问题描述
RelationTrack旨在完成目标检测和基于ReID的轨迹关联任务,由三个部分组成,分别是检测器 ϕ ( ⋅ ) \\phi(\\cdot) ϕ(⋅)、ReID特征提取器 ψ ( ⋅ ) \\psi(\\cdot) ψ(⋅)以及关联器 φ ( ⋅ ) \\varphi(\\cdot) φ(⋅),它们分别负责目标的定位、目标的特征提取以及轨迹的生成。
形式上,输入图像 I t ∈ R H × W × C I_{t} \\in \\mathbb{R}^{H \\times W \\times C} It∈RH×W×C,不妨记 ϕ ( I t ) \\phi\\left(I_{t}\\right) ϕ(It)和 ψ ( I t ) \\psi\\left(I_{t}\\right) ψ(It)为 b t b_{t} bt和 e t e_{t} et,显然可以知道 b t ∈ R k × 4 b_{t} \\in \\mathbb{R}^{k \\times 4} bt∈Rk×4且 e t ∈ R k × D e_{t} \\in \\mathbb{R}^{k \\times D} et∈Rk×D。上面的 H H H、 W W W和 C C C分别表示输入图像的高、宽和通道数, k k k、 t t t和 D D D则表示检测到的目标数、图像的帧索引以及ReID embedding向量的维度。 b t b_t bt和 e t e_t et分别指的是目标的边框坐标和相应的ReID特征向量。在完成检测和特征向量的提取之后, φ ( ⋅ ) \\varphi(\\cdot) φ(⋅)基于 e t e_t et对不同帧的 b t b_t bt进行关联从而生成轨迹,目前的主流思路是只要检测和ReID足够准,使用一个简单的关联器即可,如匈牙利算法。
整体框架
下面的这个图就是RelationTrack的整体框架,总的来看分为五部分,分别是特征提取、特征解耦、ReID表示学习以及最后的数据关联,整个框架都是针对单帧进行处理的。首先,图像送入backbone中得到特征图,随后GCD模块将这个特征图解耦为两个特征图,分别为检测信息和ReID信息,检测分支通过检测信息进行类似于CenterNet的目标定位而GTE模块则负责生成判别性的目标特征表示。最后,有了目标框和对应的特征表示,就可以通过匈牙利算法进行关联从而得到最终的跟踪轨迹了。
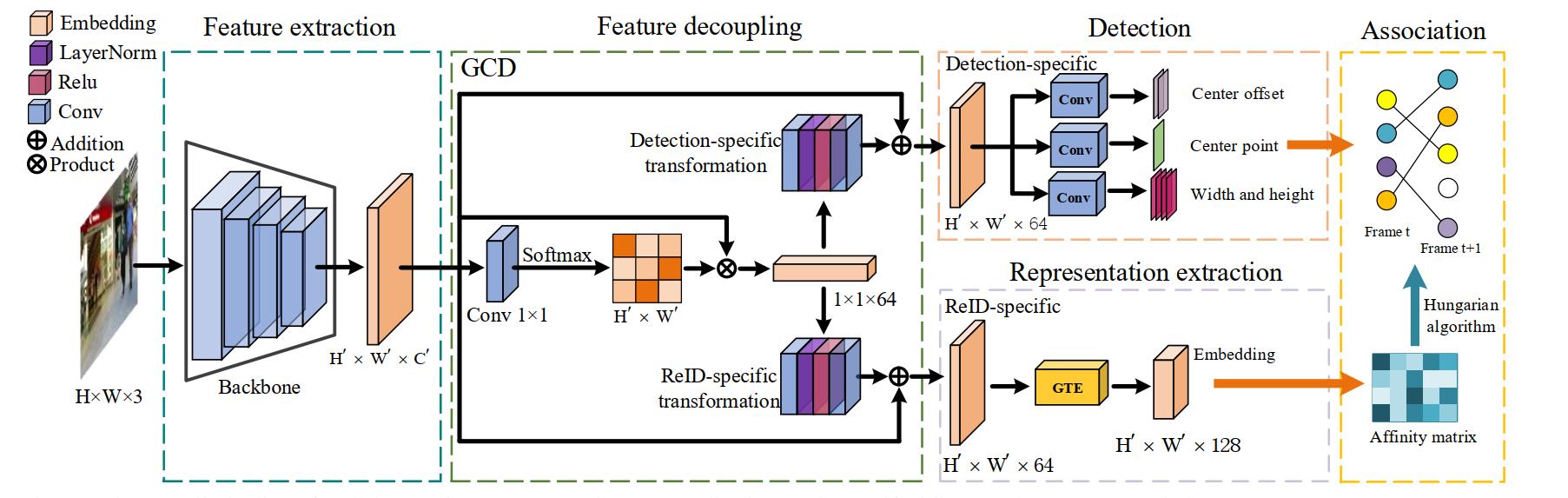
GCD
在上面的整体框架了解后,我们来看看GCD(Global Context Disentangling)模块具体是如何实现特征图解耦的。实际上,GCD分为两个阶段进行,首先是全局上下文向量的生成然后利用这个向量去解耦输入特征图,它的流程其实就是上图的中间部分。
记 x = { x i } i = 1 N p x=\\left\\{x_{i}\\right\\}_{i=1}^{N_{p}} x={xi}i=1Np为输入的特征图(就是backbone得到的,一般是64通道的),这里的 N p N_p Np表示像素数目即 H ′ × W ′ H^{\\prime} \\times W^{\\prime} H′×W′, H ′ H^{\\prime} H′和 W ′ W^{\\prime} W′分别表示特征图的高和宽。首先,第一个阶段先是计算全局上下文特征向量,可以用下面的式子表示,这里的 W k W_k Wk表示的是一个可学习的线性变换,文中采用1x1卷积实现。这个过程其实是一个空间注意力图的形成。
z = ∑ j = 1 N p exp ( W k x j ) ∑ m = 1 N p exp ( W k x m ) x j z=\\sum_{j=1}^{N_{p}} \\frac{\\exp \\left(W_{k} x_{j}\\right)}{\\sum_{m=1}^{N_{p}} \\exp \\left(W_{k} x_{m}\\right)} x_{j} z=j=1∑Np∑m=1Npexp(Wkxm)exp(Wkxj)xj
不过,作者这里似乎没有刻意提及利用这个注意力图更新原始输入在进行通道注意力得到一个特征向量,这个向量才是后续两个转换层的输入。(个人理解)
接着,进入第二个阶段,两个转换层(对应上图中间部分的上下对称的两个结构,由卷积、LayerNorm、ReLU和卷积构成),它将上一个阶段的输出 z z z结构成两个任务指定的特征向量,将这个向量和原始的特征图broadcast之后相加则可以获得检测任务特定的embedding d = { d i } i = 1 N p d=\\left\\{d_{i}\\right\\}_{i=1}^{N_{p}} d={di}i=1Np和ReID任务指定的 r = { r i } i = 1 N p r=\\left\\{r_{i}\\right\\}_{i=1}^{N_{p}} r={ri}i=1Np。这个过程可以通过下面的式子描述,其中的 W d 1 , W d 2 , W e 1 W_{d 1}, W_{d 2}, W_{e 1} Wd1,Wd2,We1 and W e 2 W_{e 2} We2均表示可学习的参数矩阵, ReL U ( ⋅ ) \\operatorname{ReL} U(\\cdot) ReLU(⋅)和 Ψ ln ( ⋅ ) \\Psi_{\\ln }(\\cdot) Ψln(⋅)表示线性修正单元和层标准化操作。
d
i
=
x
i
+
W
d
2
R
e
L
U
(
Ψ
l
n
(
W
d
1
z
)
)
r
i
=
x
i
+
W
r
2
R
e
L
U
(
以上是关于RelationTrack解读的主要内容,如果未能解决你的问题,请参考以下文章