让我们用 SQL 开发一个图形数据库吧!
Posted 不剪发的Tony老师
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了让我们用 SQL 开发一个图形数据库吧!相关的知识,希望对你有一定的参考价值。

大家好!我是只谈技术不剪发的 Tony 老师。
图形数据库(Graph Database)是 NoSQL 数据库的一种,使用图结构来存储、表示、处理和查询数据。图是节点(Node)或者顶点(Vertice)和连接(Link)或者边缘(Edge)的集合。节点代表了一个实体(人、物体等),连接代表了两个节点之间的联系(好友、爱好等)。图形数据库非常适合社交关系分析、金融欺诈检测、知识图谱等领域,Neo4j 是著名的图形数据库。
除了使用专门的图形数据库之外,如今主流的关系型数据库都提供了 JSON 文档存储功能以及通用表表达式(WITH 子句)的支持。我们完全可以基于这些功能实现一个简单的图形数据库,同时可以使用 SQL 语句对图形进行操作和查询。
如果你觉得这篇文章有用,欢迎关注❤️、评论📝、点赞👍!
设计表结构
图要由两个结构组成:节点和边缘。
节点代表了一个实体对象,例如人、地点、事物等。节点可以拥有属性,例如人的姓名、性别等。一个节点对应了关系型数据库中的一行数据或者文档数据库中的一个文档。
边缘代表了两个对象之间的关系,例如某人住在某地。边缘也可以拥有属性,例如何时开始住在某地。一个边缘对应了关系型数据库中的一个外键记录或者文档数据库中的一个链接 id。
基于图的结构,我们可以在关系型数据库中创建两个表:node 和 edge。它们的 ERD 如下图所示:
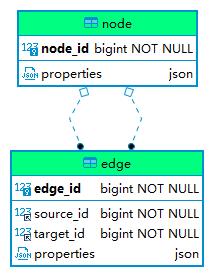
创建以上表结构的 SQL 脚本如下(mysql 语法):
-- MySQL
CREATE TABLE IF NOT EXISTS node (
node_id BIGINT NOT NULL AUTO_INCREMENT PRIMARY KEY,
properties JSON
);
CREATE TABLE IF NOT EXISTS edge (
edge_id BIGINT NOT NULL AUTO_INCREMENT PRIMARY KEY,
source_id BIGINT NOT NULL,
target_id BIGINT NOT NULL,
properties JSON,
FOREIGN KEY(source_id) REFERENCES node(node_id),
FOREIGN KEY(target_id) REFERENCES node(node_id)
);
CREATE INDEX idx_edge_source_id ON edge(source_id);
CREATE INDEX idx_edge_target_id ON edge(target_id);
对于节点表 node,我们创建了一个自增主键 node_id,以及一个存储节点属性的 JSON 字段 properties。对于边缘表 edge,我们创建了一个自增主键 edge_id,表示关系起点的字段 source_id 和表示关系终点的字段 target_id,以及一个存储关系属性的 JSON 字段 properties。
同时,为了数据操作和提高查询性能,我们创建了两个索引 idx_edge_source_id 和 idx_edge_target_id。
📝完整的表结构和查询脚本可以从 GitHub 或者 CODE CHINA 下载。除了 MySQL 之外,我们还提供了 Oracle、Microsoft SQL Server、PostgreSQL 以及 SQLite 版本。
实现图查询
插入数据
接下来我们使用 SQL 语句插入一些测试数据,首先插入几个节点:
INSERT INTO node(properties) VALUES('{"Label":"Person", "Name":"张三", "Age": 22}');
INSERT INTO node(properties) VALUES('{"Label":"Person", "Name":"李四", "Age": 30}');
INSERT INTO node(properties) VALUES('{"Label":"Person", "Name":"王五", "Age": 28}');
以上语句插入了 3 个节点,它们的 Label 都是 Person,拥有姓名和年龄属性。
然后我们再建立一些关系:
INSERT INTO edge(source_id, target_id, properties)
VALUES((SELECT node_id FROM node WHERE json_value(properties, '$.Name')='张三'),
(SELECT node_id FROM node WHERE json_value(properties, '$.Name')='李四'), '{"Label":"关注", "Degree": 80}');
INSERT INTO edge(source_id, target_id, properties)
VALUES((SELECT node_id FROM node WHERE json_value(properties, '$.Name')='李四'),
(SELECT node_id FROM node WHERE json_value(properties, '$.Name')='王五'), '{"Label":"关注", "Degree": 90}');
INSERT INTO edge(source_id, target_id, properties)
VALUES((SELECT node_id FROM node WHERE json_value(properties, '$.Name')='张三'),
(SELECT node_id FROM node WHERE json_value(properties, '$.Name')='王五'), '{"Label":"关注", "Degree": 60}');
其中,json_value 是 MySQL 提供的 JSON 函数,用于提取 JSON 文档中的元素。
以上测试数据建立的关系图如下所示:
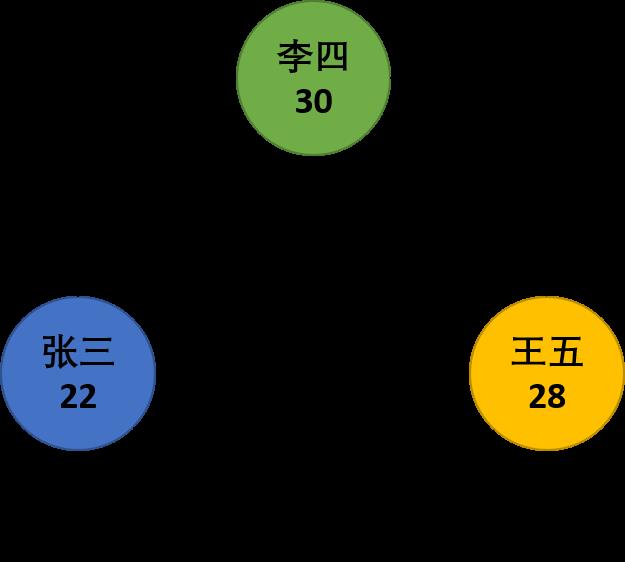
对于节点和边缘的查询和普通表类似,例如:
SELECT properties FROM node WHERE json_value(properties, '$.Name')='张三';
properties |
--------------------------------------------+
{"Age": 22, "Name": "张三", "Label": "Person"}|
SELECT * FROM edge WHERE source_id = 1 AND target_id = 2;
edge_id|source_id|target_id|properties |
-------+---------+---------+-----------------------------+
1| 1| 2|{"Label": "关注", "Degree": 80}|
图的遍历
我们从节点“张三”出发,遍历所有的节点:
WITH RECURSIVE traverse(id, relation, hops) AS (
SELECT node_id, cast(json_value(properties, '$.Name') AS CHAR(100)), 0
FROM node
WHERE json_value(properties, '$.Name')='张三'
UNION ALL
SELECT target_id, CONCAT(relation,'->',json_value(n.properties, '$.Name')), hops + 1
FROM edge e
JOIN traverse t ON e.source_id = t.id
JOIN node n ON e.target_id = n.node_id
)
SELECT id, relation, hops
FROM traverse;
id|relation |hops|
--+---------------+----+
1|张三 | 0|
2|张三->李四 | 1|
3|张三->王五 | 1|
3|张三->李四->王五| 2|
首先,我们定义了一个递归形式的通用表表达式 traverse,它由两部分组成,使用 UNION ALL 进行组合。第一个 SELECT 语句返回了起点“张三”,第二个 SELECT 语句引用了 traverse 自身,通过不停的迭代返回所有连接的节点。字段 hops 代表了节点之间的跳跃次数。最后的 SELECT 语句返回了全部的节点信息。
从遍历的结果可以看出,MySQL 默认采用的是广度优先搜索方法。如果想要实现深度优先搜索,可以使用 ORDER BY 排序:
WITH RECURSIVE traverse(id, relation, hops) AS (
SELECT node_id, cast(json_value(properties, '$.Name') AS CHAR(100)), 0
FROM node
WHERE json_value(properties, '$.Name')='张三'
UNION ALL
SELECT target_id, CONCAT(relation,'->',json_value(n.properties, '$.Name')), hops + 1
FROM edge e
JOIN traverse t ON e.source_id = t.id
JOIN node n ON e.target_id = n.node_id
)
SELECT id, relation, hops
FROM traverse
ORDER BY relation;
id|relation |hops|
--+---------------+----+
1|张三 | 0|
2|张三->李四 | 1|
3|张三->李四->王五| 2|
3|张三->王五 | 1|
最短距离
基于以上图的遍历,我们可以很容易地找出两个节点之间的最短距离。例如,以下语句可以找出“张三”和“王五”之间的最短距离:
WITH RECURSIVE traverse(id, relation, hops) AS (
SELECT node_id, cast(json_value(properties, '$.Name') AS CHAR(100)), 0
FROM node
WHERE json_value(properties, '$.Name')='张三'
UNION ALL
SELECT target_id, CONCAT(relation,'->',json_value(n.properties, '$.Name')), hops + 1
FROM edge e
JOIN traverse t ON e.source_id = t.id
JOIN node n ON e.target_id = n.node_id
)
SELECT id, relation, hops
FROM traverse
JOIN node ON id = node_id
WHERE json_value(properties, '$.Name')='王五'
ORDER BY hops
LIMIT 1;
id|relation |hops|
--+-----------+----+
3|张三->王五 | 1|
索引优化
我们使用 EXPLAIN 命令查看一下最短距离搜索语句的执行计划:
EXPLAIN
WITH RECURSIVE traverse(id, relation, hops) AS (
SELECT node_id, cast(json_value(properties, '$.Name') AS CHAR(100)), 0
FROM node
WHERE json_value(properties, '$.Name')='张三'
UNION ALL
SELECT target_id, CONCAT(relation,'->',json_value(n.properties, '$.Name')), hops + 1
FROM edge e
JOIN traverse t ON e.source_id = t.id
JOIN node n ON e.target_id = n.node_id
)
SELECT id, relation, hops
FROM traverse
JOIN node ON id = node_id
WHERE json_value(properties, '$.Name')='王五'
ORDER BY hops
LIMIT 1;
id|select_type|table |partitions|type |possible_keys |key |key_len|ref |rows|filtered|Extra |
--+-----------+----------+----------+------+-------------------------------------+------------------+-------+----------------+----+--------+------------------------------------------+
1|PRIMARY |<derived2>| |ALL | | | | | 6| 100.0|Using temporary; Using filesort |
1|PRIMARY |node | |ALL |PRIMARY | | | | 3| 50.0|Using where; Using join buffer (hash join)|
2|DERIVED |node | |ALL | | | | | 3| 100.0|Using where |
3|UNION |t | |ALL | | | | | 3| 100.0|Recursive; Using where |
3|UNION |e | |ref |idx_edge_source_id,idx_edge_target_id|idx_edge_source_id|8 |t.id | 1| 100.0| |
3|UNION |n | |eq_ref|PRIMARY |PRIMARY |8 |hrdb.e.target_id| 1| 100.0| |
由于 node 表的 properties 字段中的 Name 元素缺少合适的索引,查询使用了大量的全表扫描,如果图中的节点数量很多时性能比较差。对此,我们可以使用数据库的函数索引为 JSON 文档中的节点数据创建索引,从而提高访问性能。例如:
CREATE INDEX idx_node_name ON node ( (json_value(properties, '$.Name')) );
执行以上命令创建索引之后,我们再次查看执行计划:
id|select_type|table |partitions|type |possible_keys |key |key_len|ref |rows|filtered|Extra |
--+-----------+----------+----------+------+-------------------------------------+-------------+-------+-----------------+----+--------+------------------------------------------+
1|PRIMARY |node | |ref |PRIMARY,idx_node_name |idx_node_name|2051 |const | 1| 100.0|Using temporary; Using filesort |
1|PRIMARY |<derived2>| |ref |<auto_key0> |<auto_key0> |9 |hrdb.node.node_id| 2| 100.0| |
2|DERIVED |node | |ref |idx_node_name |idx_node_name|2051 |const | 1| 100.0| |
3|UNION |t | |ALL | | | | | 2| 100.0|Recursive |
3|UNION |e | |ALL |idx_edge_source_id,idx_edge_target_id| | | | 2| 50.0|Using where; Using join buffer (hash join)|
3|UNION |n | |eq_ref|PRIMARY |PRIMARY |8 |hrdb.e.target_id | 1| 100.0| |
以上是关于让我们用 SQL 开发一个图形数据库吧!的主要内容,如果未能解决你的问题,请参考以下文章