Linux内核 eBPF基础: 探索USDT探针
Posted rtoax
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux内核 eBPF基础: 探索USDT探针相关的知识,希望对你有一定的参考价值。
目录
perf_event profiling vs. eBPF profiling
perf-tools (a wrapper of ftrace and perf_event)
Register USDT probe via ftrace(under the hood, ftrace+uprobe)
Register USDT probe via bcc(under the hood, eBPF+uprobe)
Adopt USDT probe to interpreter or JIT based languages runtime
How does DTrace works with USDT
DTrace USDT sample running on Solaris(DTrace) and Linux(via Systemtap)
Compile executable with "–with-dtrace" option
https://leezhenghui.github.io/linux/2019/03/05/exploring-usdt-on-linux.html
Motivation
Improve the observability and traceability of system software has become an important objective for building large complex infrastructure software. Minimizing the system overhead caused by monitoring is challenging but rewarding, as it can greatly help on the performance analysis and troubleshooting on production environment. On Linux, some well-known tracing tools like strace and ltrace can be used to tell what system calls are being made and what dynamic library calls are being made, these information are useful but still limited, also, turning on these kinds of tools will introduce an significant performance impact, this make them not very suitable for problem debugging or monitoring on the production environment.
So what is the proper way to allow programmer declare and embed the trace points into userland application, as long as instrument these trace points with an appropriate low-overhead probe during runtime, people can get the expected information about what application is doing. The USDT(Userland Statically Defined Tracing) provided by DTrace under BSD/Solaris is a successful technical reference implementation to empower this kind of feature to us. Unfortunately, for a long time, Linux did not provide out-of-box USDT probe due to insufficient support of kernel and frontend. However, in the last several years, with the continuous enhancement of kernel envent sources(e.g: uprobe) and eBPF, as well as the frontend tools such as bcc/bpftrace being implemented based on eBPF, USDT finally comes to Linux application. In this post, I will start with the Linux Tracing system concepts introductions, and then explore how USDT works in Linux.
Before we dig into USDT with more details, let's take a step back to have a look at the big picture of tracing in Linux.
THANKS to Brendan Gregg's Blog providing so much wonderful articles to help learning the knowledges in this interesting field.
Tracing System
Broadly speaking, a tracing system in linux consist of three layers: front-end, tracing framework and event sources.
Overview
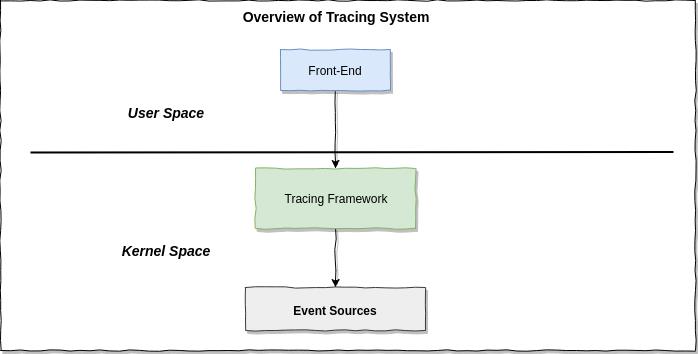
The event sources are where the tracing data comes from, tracing framework running in the kernel which responsible for data collection, counting, if it support in-kernel programmatically tracer(e.g: eBPF), it also perform the aggregation, sumarries and statistic in the efficent way. The tracing frontend tools provide user interface to communicate with tracing framework, do the statistic, sumaries and aggregation in sampling-with-post-processing-tracer(if it have) and do the result visualization to end user.
Terminology术语
-
ProfilingProfiling is aimed to take samples of trace events.
-
TracingTracing records every trace events.
-
ProbeAn instrumentation point in software or hardware, that generates events that can execute aggregation/summaries/statistics programs.
-
Static tracingHard-coded instrumentation points in code. Since these are fixed, they may be provided as part of a stable API, and documented.
-
Dynamic tracingAlso known as dynamic instrumentation, this is a technology that can instrument any software event, such as function calls and returns, by live modification of instruction text. Target software usually does not need special capabilities to support dynamic tracing, other than a symbol table that frontend can read. Since this instruments all software text, it is not considered a stable API, and the target functions may not be documented outside of their source code.
Evoluction of Linux Tracing
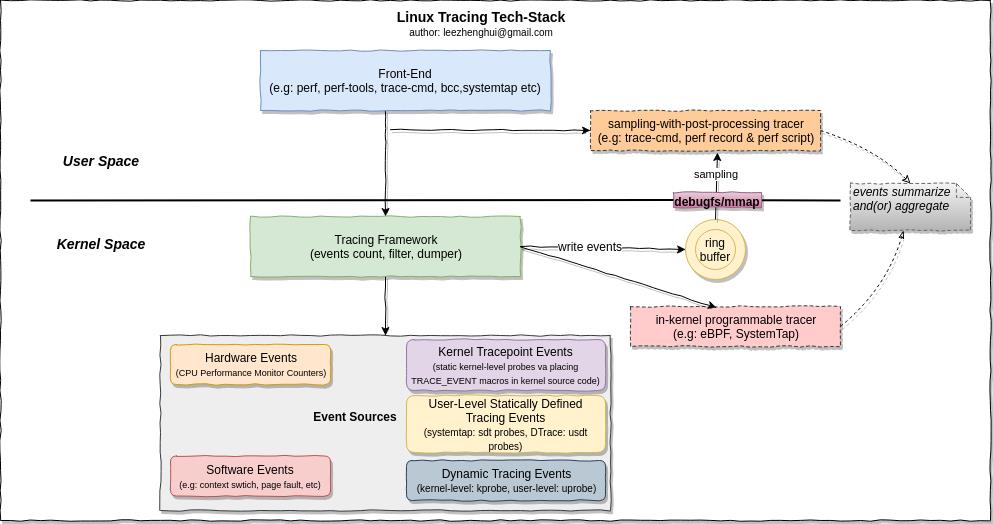
Linux Tracing Technical Stack
Event Sources
-
tracepoints (kernel static tracing)
A Linux kernel technology for providing static tracing.
-
kprobes (Kernel Dynamic tracing)
A Linux kernel technology for providing dynamic tracing of kernel functions.
Briefly, the kprobe work following below steps:
- User write kprobe handler in a kernel module, and install the kernel module to a running kernel
- Register the probes, after the probes are registered, the addresses at which they are active contain the breakpoint instruction (int3 on x86).
- As soon as execution reaches a probed address the int3 instruction is executed, causing the control to reach the breakpoint handler do_int3() in arch/i386/kernel/traps.c. do_int3() is called through an interrupt gate therefore interrupts are disabled when control reaches there. This handler notifies KProbes that a breakpoint occurred; KProbes checks if the breakpoint was set by the registration function of KProbes. If no probe is present at the address at which the probe was hit it simply returns 0. Otherwise the registered probe function is called.
Please refer to lwn doc An introduction to KProbes for more details.
- uprobes (user-level Dynamic tracing)
A Linux kernel technology for providing dynamic tracing of user-level functions. Linux uprobes allows to dynamically instrument user applications, injecting programmable breakpoints at arbitrary instructions.
Please refer to Linux uprobe: User-Level Dynamic Tracing for more detailed introductions about Linux uprobe.
- USDT/SDT
User Statically-Defined Tracing: static tracing points for user-level software. Some applications support USDT.
From gdbdoc
GDB supports SDT probes in the code. SDT stands for Statically Defined Tracing, and the probes are designed to have a tiny runtime code and data footprint, and no dynamic relocations. Currently, the following types of probes are supported on ELF-compatible systems:
- SystemTap (http://sourceware.org/systemtap/) SDT probes. SystemTap probes are usable from assembly, C and C++ languages5.
- DTrace (http://oss.oracle.com/projects/DTrace) USDT probes. DTrace probes are usable from C and C++ languages.
DTrace has long provided a C API for defining the DTrace-equivalent of USDT probes through the DTRACE_PROBE macro. The Linux tracing ecosystem developers decided to stay source-compatible with that API, so any DTRACE_PROBE macros are automatically converted to USDT probes! Adding probes to your own code is possible with SystemTap's API and the collection of DTRACE_PROBE() macros. USDT probes can help you troubleshoot your applications in production with minimal run-time overhead.
Tracing Frameworks
In-tree
ftrace

From Choosing a Linux Tracer by Brendan Gregg
ftrace a kernel hacker's best friend. It's built into the kernel, and can consume tracepoints, kprobes, and uprobes, and provides a few capabilities: event tracing, with optional filters and arguments; event counting and timing, summarized in-kernel; and function-flow walking. See ftrace.txt from the kernel source for examples. It's controlled via /sys, and is intended for a single root user (although you could hack multi-user support using buffer instances). Its interface can be fiddly at times, but it's quite hackable, and there are front ends: Steven Rostedt, the main ftrace author, has created trace-cmd, and I've created the perf-tools collection. My biggest gripe is that it isn't programmable, so you can't, for example, save and fetch timestamps, calculate latency, and then store it as a histogram. You'll need to dump events to user-level, and post-process, at some cost. It may become programmable via eBPF.
By lwn doc Debugging the kernel using Ftrace
One of the most powerful tracers of Ftrace is the function tracer. It uses the -pg option of gcc to have every function in the kernel call a special function "mcount()". That function must be implemented in assembly because the call does not follow the normal C ABI. When CONFIG_DYNAMIC_FTRACE is configured the call is converted to a NOP at boot time to keep the system running at 100% performance. During compilation the mcount() call-sites are recorded. That list is used at boot time to convert those sites to NOPs. Since NOPs are pretty useless for tracing, the list is saved to convert the call-sites back into trace calls when the function (or function graph) tracer is enabled.
Please refer to ftrace-kernel-hooks-2014 for more introdction on ftrace.
perf_event

From Choosing a Linux Tracer by Brendan Gregg
perf_events is the main tracing tool for Linux users, its source is in the Linux kernel, and is usually added via a linux-tools-common package. Aka "perf", after its front end, which is typically used to trace & dump to a file (perf.data), which it does relatively efficiently (dynamic buffering), and then post-processeses that later. It can do most of what ftrace can. It can't do function-flow walking, and is a bit less hackable (as it has better safety/error checking). But it can do profiling (sampling), CPU performance counters, user-level stack translation, and can consume debuginfo for line tracing with local variables. It also supports multiple concurrent users. As with ftrace, it isn't kernel programmable yet, until perhaps eBPF support (patches have been proposed). If there's one tracer I'd recommend people learn, it'd be perf, as it can solve a ton of issues, and is relatively safe.
Event sources supported by perf_event
(Image credit: Brendan Gregg's Blog - perf Examples)

eBPF
From Choosing a Linux Tracer by Brendan Gregg
The extended Berkeley Packet Filter is an in-kernel virtual machine that can run programs on events, efficiently (JIT). Enhancements to BPF (Berkeley Packet Filter) which were added to the Linux 4.x series kernels, allowing BPF to do much more than just filtering packets. These enhancements allow custom analysis programs to be executed on Linux dynamic tracing, static tracing, and profiling events. It's likely to eventually provide in-kernel programming for ftrace and perf_events, and to enhance other tracers.
Here’s how eBPF works briefly.
- You write an “eBPF program” (often in C, or likely you use a tool that generates that program for you).
- You ask the kernel to attach that probe to a kprobe/uprobe/tracepoint/USDT-probe
- Your program writes out data to an eBPF map / ftrace / perf buffer
-
You have your precious precious data!

For its use with tracing, BPF provides the programmable capabilities to the existing tracing frameworks: kprobes, uprobes, and tracepoints.
Below diagram show us the event sources supported by eBPF:
(Image credit: Brendan Gregg's Blog - Linux Extended BPF (eBPF) Tracing Tools)

(Image credit: [OpenResty slides by Yichun Zhang (@agentzh) - Tracing and Troubleshooting NGINX, OpenResty, and Their Backends)

Please refer to LWN doc - A thorough introduction to eBPF and pdf-eBPF for more details about eBPF
perf_event profiling vs. eBPF profiling
Compare original perf_event profiling and eBPF based profiling, the sandboxed virtual machine provided by eBPF which allow us to implement an in-kernel programmable tracer, we do not need to dump the event data into a disk for a offline analysis, therefore reduce the data transition between kernel and userspace.

Out-of-tree
SystemTap
From Brendan Gregg's Blog - Choosing a Linux Tracer
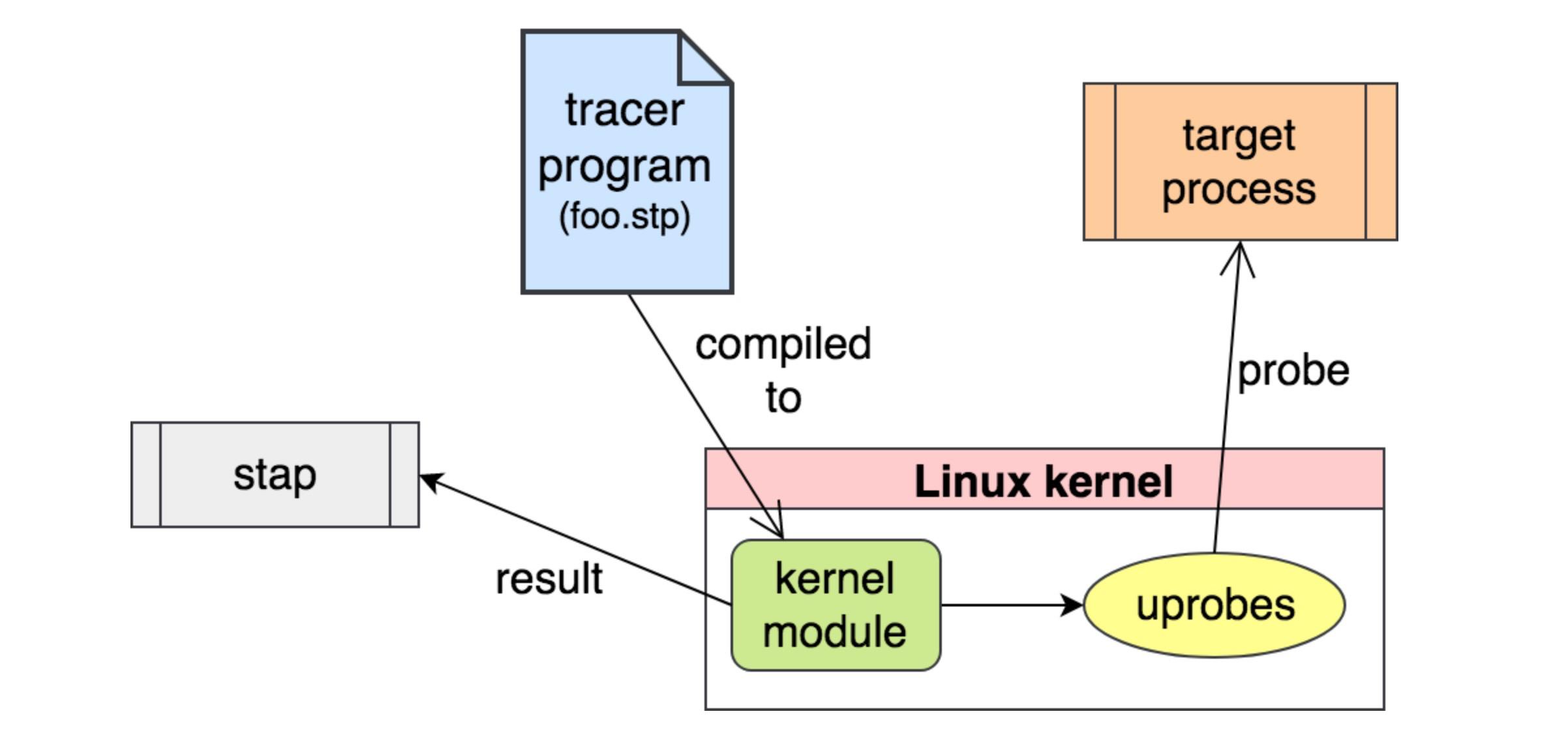
SystemTap is the most powerful tracer. It can do everything: profiling, tracepoints, kprobes, uprobes (which came from SystemTap), USDT, in-kernel programming, etc. It compiles programs into kernel modules and loads them – an approach which is tricky to get safe.
SystemTap supports: * tracepoints * kprobes * uprobes * USDT. e.g: the basic steps for tracing a kprobe is as below:
From Julia Evans's Blog - Linux tracing systems & how they fit together
You decide you want to trace a kprobe
You write a “systemtap program” & compile it into a kernel module
That kernel module, when inserted, creates kprobes that call code from your kernel module when triggered (it calls register_kprobe)
You kernel modules prints output to userspace (using relayfs or something)
(Image credit: [Yichun Zhang (@agentzh) - dynamic tracing)

(Image credit: [OpenResty slides by Yichun Zhang (@agentzh) - Tracing and Troubleshooting NGINX, OpenResty, and Their Backends)
LTTng
From Brendan Gregg's Blog - Choosing a Linux Tracer
LTTng has optimized event collection, which outperforms other tracers, and also supports numerous event types, including USDT. It is developed out of tree. The core of it is very simple: write events to a tracing buffer, via a small and fixed set of instructions. This helps make it safe and fast. The downside is that there's no easy way to do in-kernel programming.
ktap
From Brendan Gregg's Blog - Choosing a Linux Tracer
ktap was a really promising tracer, which used an in-kernel lua virtual machine for processing, and worked fine without debuginfo and on embedded devices. It made it into staging, and for a moment looked like it would win the trace race on Linux. Then eBPF began kernel integration, and ktap integration was postponed until it could use eBPF instead of its own VM
dtrace4linux
From Brendan Gregg's Blog - Choosing a Linux Tracer
dtrace4linux is mostly one man's part-time effort (Paul Fox) to port Sun DTrace to Linux. It's impressive, and some providers work, but it's some ways from complete, and is more of an experimental tool (unsafe)
Oracle Linux DTrace
From Brendan Gregg's Blog - Choosing a Linux Tracer
Oracle Linux DTrace is a serious effort to bring DTrace to Linux, specifically Oracle Linux. Various releases over the years have shown steady progress. The developers have even spoken about improving the DTrace test suite, which shows a promising attitude to the project. Many useful providers have already been completed: syscall, profile, sdt, proc, sched, and USDT. I'm still waiting for fbt (function boundary tracing, for kernel dynamic tracing), which will be awesome on the Linux kernel. Its ultimate success will hinge on whether it's enough to tempt people to run Oracle Linux (and pay for support). Another catch is that it may not be entirely open source: the kernel components are, but I've yet to see the user-level code.
DTrace
(Image credit: [OpenResty slides by Yichun Zhang (@agentzh) - Tracing and Troubleshooting NGINX, OpenResty, and Their Backends)

sysdig
From Brendan Gregg's Blog - Choosing a Linux Tracer
sysdig is a new tracer that can operate on syscall events with tcpdump-like syntax, and lua post processing. It's impressive, and it's great to see innovation in the system tracing space. Its limitations are that it is syscalls only at the moment, and, that it dumps all events to user-level for post processing. You can do a lot with syscalls, although I'd like to see it support tracepoints, kprobes, and uprobes. I'd also like to see it support eBPF, for in-kernel summaries. The sysdig developers are currently adding container support. Watch this space.
Tracing Frontends
ftrace
ftrace use a virtual file sysatem - /sys/kernel/debug/tracing as the user interface.
perf (for perf_event only)
perf is a function for performance monitoring that exists in Linux . Also called perf_event. Tools for user space named perf have also been developed, and if you simply say perf, you probably point to this tool. For a bit confusing, here we will write perf_event as the kernel 's function.
trace-cmd (for ftrace only)
It is a frontend for ftrace, you can use it to collect and display ftrace data
Please refer to good article ftrace: trace your kernel functions for more details.
perf-tools (a wrapper of ftrace and perf_event)
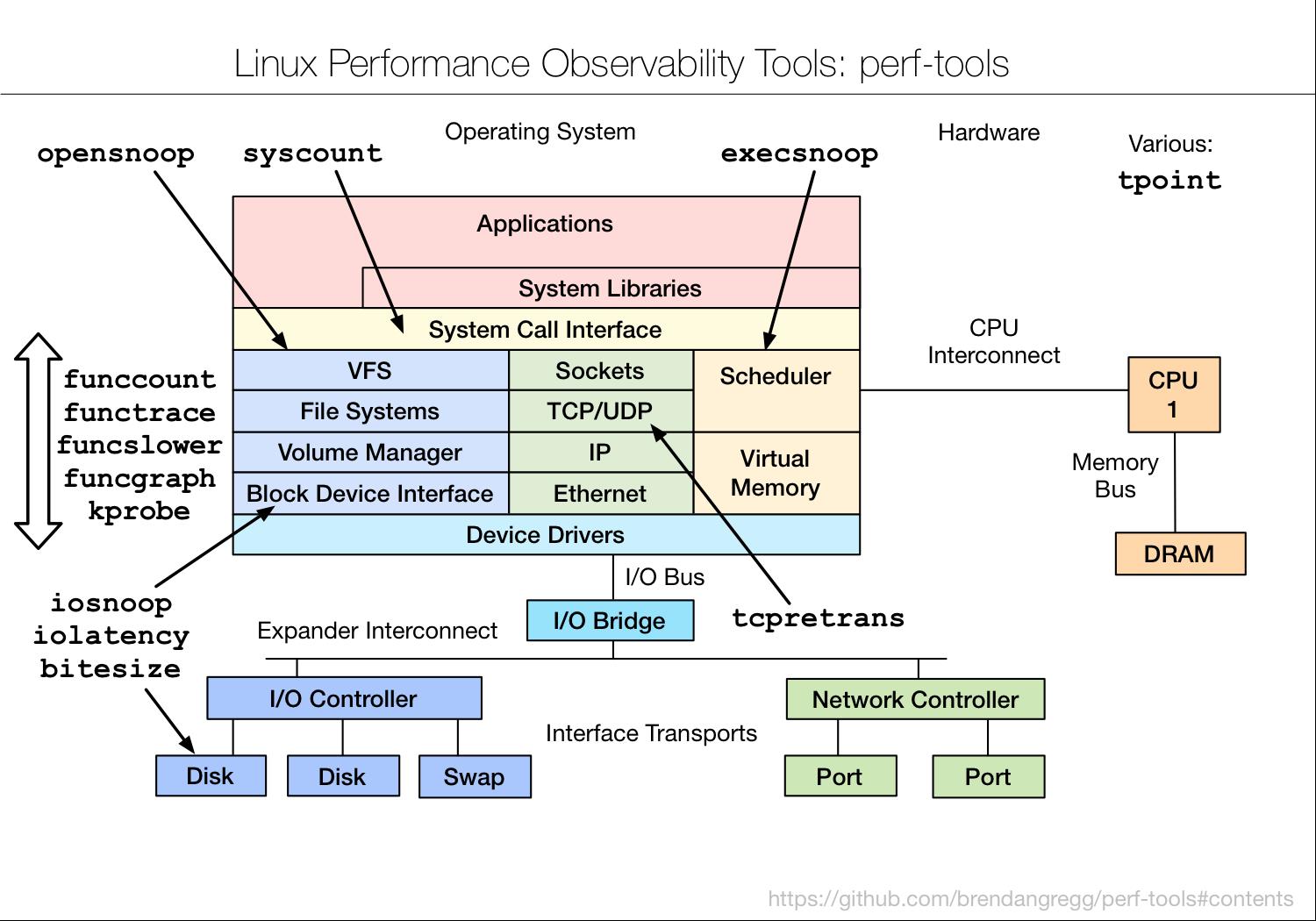
| Deps | Feature | Comments |
|---|---|---|
| ftrace | iosnoop | trace disk I/O with details including latency |
| iolatency | summarize disk I/O latency as a histogram | |
| execsnoop | trace process exec() with command line argument details | |
| opensnoop | trace open() syscalls showing filenames | |
| killsnoop | trace kill() signals showing process and signal details | |
| fs/cachestat | basic cache hit/miss statistics for the Linux page cache | |
| net/tcpretrans | show TCP retransmits, with address and other details | |
| system/tpoint | trace a given tracepoint | |
| kernel/funccount | count kernel function calls, matching a string with wildcards | |
| kernel/functrace | trace kernel function calls, matching a string with wildcards | |
| kernel/funcslower | trace kernel functions slower than a threshold | |
| kernel/funcgraph | trace a graph of kernel function calls, showing children and times | |
| kernel/kprobe | dynamically trace a kernel function call or its return, with variables | |
| user/uprobe | dynamically trace a user-level function call or its return, with variables | |
| *user/usdt | It is just a PoC sample script which being used in article, not been included in the toolkit, usdt(ftrace) | |
| tools/reset-ftrace | reset ftrace state if needed | |
| perf_events | misc/perf-stat-hist | power-of aggregations for tracepoint variables |
| syscount | count syscalls by syscall or process | |
| disk/bitesize | histogram summary of disk I/O size |
bcc (eBPF-based)
From bcc
bccis a toolkit for creating efficient kernel tracing and manipulation programs, and includes several useful tools and examples. It makes use of extended BPF (Berkeley Packet Filters), formally known as eBPF, a new feature that was first added to Linux 3.15. Much of what bcc uses requires Linux 4.1 and above. bcc makes BPF programs easier to write, with kernel instrumentation in C (and includes a C wrapper around LLVM), and front-ends in Python and lua. It is suited for many tasks, including performance analysis and network traffic control.


-
The straightforward way for USDT implementation is based on uprobe approach. see below for the solution disscusion:
From bcc github issue-327
on the iovisor call today (11am PST biweekly) we briefly discussed that there were at least 3 ways to do USDT probes. This way, using uprobes, is the most obvious and immediate solution, and we should go ahead with it. But later on (much later on) we might investigate other approaches in addition or instead of, including LD_PRELOAD so that tracing can be user-mode to user-mode, reducing overhead. These other approaches should greatly reduce the overhead of memleak too.
Events:
From bcc reference guide
- kprobes
- kretprobes
- Tracepoints
- uprobes
- uretprobes
- USDT probes
- Raw Tracepoints
- system call tracepoints
USDT probes:
From bcc reference guide
These are User Statically-Defined Tracing (USDT) probes, which may be placed in some applications or libraries to provide a user-level equivalent of tracepoints. The primary BPF method provided for USDT support method is enable_probe(). USDT probes are instrumented by declaring a normal function in C, then associating it as a USDT probe in Python via USDT.enable_probe().
Arguments can be read via: bpf_usdt_readarg(index, ctx, &addr)
bpftrace
From github High-level tracing language for Linux eBPF
BPFtrace is a high-level tracing language for Linux enhanced Berkeley Packet Filter (eBPF) available in recent Linux kernels (4.x). BPFtrace uses LLVM as a backend to compile scripts to BPF-bytecode and makes use of BCC for interacting with the Linux BPF system, as well as existing Linux tracing capabilities: kernel dynamic tracing (kprobes), user-level dynamic tracing (uprobes), and tracepoints. The BPFtrace language is inspired by awk and C, and predecessor tracers such as DTrace and SystemTap.

From github bpftrace reference doc
Supported probes:
- kprobe - kernel function start
- kretprobe - kernel function return
- uprobe - user-level function start
- uretprobe - user-level function return
- tracepoint - kernel static tracepoints
- usdt - user-level static tracepoints
- profile - timed sampling
- interval - timed output
- software - kernel software events
- hardware - processor-level events
USDT probes:
From github bpftrace reference doc
Syntax:
usdt:binary_path:probe_name
usdt:binary_path:[probe_namespace]:probe_name
usdt:library_path:probe_name
usdt:library_path:[probe_namespace]:probe_name > usdt: Static Tracing, User-Level Arguments
e.g:
bpftrace -e 'usdt:/root/tick:loop { printf("%s: %d\\n", str(arg0), arg1); }'
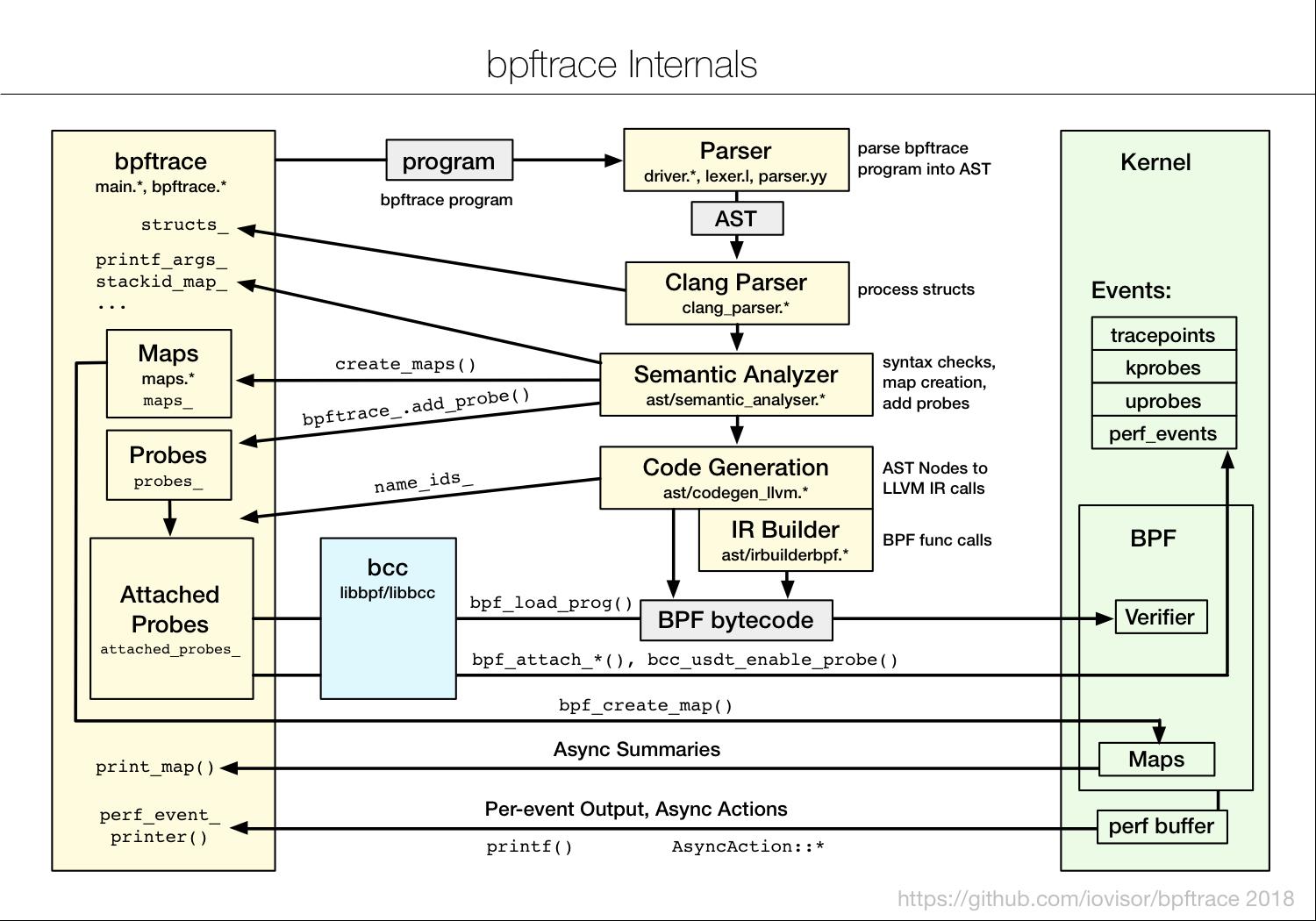
From github High-level tracing language for Linux eBPF
bpftrace employs various techniques for efficiency, minimizing the instrumentation overhead. Summary statistics are stored in kernel BPF maps, which are asynchronously copied from kernel to user-space, only when needed. Other data, and asynchronous actions, are passed from kernel to user-space via the perf output buffer.
As Brendan mentioned in his blog - Linux Extended BPF (eBPF) Tracing Tools
bpftrace is ideal for ad hoc instrumentation with powerful custom one-liners and short scripts, whereas bcc is ideal for complex tools and daemons.
Please refer to Brendan Gregg's Blog- dtrace-for-linux-2018 for a detailed instruction about bpftrace.
USDT
From dtrace blog
USDT (Userland Statically Defined Tracing) is the mechanism by which application developers embed DTrace probes directly into an application. This allows users to trace semantically meaningful operations like “request-start”, rather than having to know which function implements the operation. More importantly, since USDT probes are part of the source code, scripts that use them continue working even as the underlying software evolves and the implementing functions are renamed and deleted.
From LWN doc
The origins of USDT probes can be found in Sun's DTrace utility. While DTrace can't claim to have invented static tracepoints (various implementations are described in the "related work" section of the original DTrace paper), it certainly made them much more popular. With the emergence of DTrace, many applications began adding USDT probes to important functions to aid with tracing and diagnosing run-time behavior. Given that, it's perhaps not surprising that these probes are usually enabled (as part of configuring the build) with the –enable-dtrace switch.
Inside USDT

-
In authoring time, Using macro
DTRACE_PROBE()to delcare a USDT trace point at appropriate souce code location -
During compilation, the source code with USDT trace point will be translated into a
nopinstruction, in the meanwhile, the USDT metadata will be stored in the ELF's.note.stapstdsection. -
When register a probe, USDT tool(usually implemented based on
uprobeunder the hood) will read the ELF.note.stapstdsection, and instrument the instruction fromnoptobreakpoint(int3on x86). In such way, whenever control reaches the marker, the interrupt handler for int3 is called, and by turn the uprobe and attached eBPF program get called in kernel to process the events. If the USDT probe associated with semaphores, the front-ends need to incrementing the semaphore’s location via poking /proc/$PID/mem to enable the probe. -
After deregister the probe, USDT will instrument the instruction from
breakpointback tonop, no event get generated anymore, in the meanwhile, decrementing the semaphore's location to detach the current probe.
Prerequsites先决条件(e.g: Ubuntu)
Ubuntu
ubuntu@ubuntu-xenial:~$ uname -a
Linux ubuntu-xenial 4.10.17-custom #1 SMP Sat Jul 22 14:41:19 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux
ubuntu@ubuntu-xenial:~$ lsb_release -a
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 16.04.2 LTS
Release: 16.04
Codename: xenial
sudo apt-get install systemtap-sdt-dev
Actually the only thing we can obtain from systemtap-std-dev is
- sys/sdt.h
- dtrace command wrapper (only if you need Semaphore feature)
all of these things can help us genarate expected elf file with markers, that is, generate
nopinstruction in the place where uprobe module can instrument a breakpoint instruction(int3 on x86) when registering a probe, and node section in elf to list these marker locations.
The source code used by this practices:
The compiled executable:
Sample w/o Semaphore support
hello-usdt.c
#include "sys/sdt.h"
int main() {
DTRACE_PROBE("hello_usdt", "enter");
int reval = 0;
DTRACE_PROBE1("hello_usdt", "exit", reval);
}
gcc ./hello-usdt.c -o ./hello-usdt
vagrant@ubuntu-bionic:~/labs/hello-usdt$ readelf -n ./hello-usdt
Displaying notes found in: .note.ABI-tag
Owner Data size Description
GNU 0x00000010 NT_GNU_ABI_TAG (ABI version tag)
OS: Linux, ABI: 3.2.0
Displaying notes found in: .note.gnu.build-id
Owner Data size Description
GNU 0x00000014 NT_GNU_BUILD_ID (unique build ID bitstring)
Build ID: e8dcb23707b00c3cd0df7dcb7afd8ce728b6fa5c
Displaying notes found in: .note.stapsdt
Owner Data size Description
stapsdt 0x0000002e NT_STAPSDT (SystemTap probe descriptors)
Provider: "hello_usdt"
Name: "enter"
Location: 0x00000000000005fe, Base: 0x0000000000000694, Semaphore: 0x0000000000000000
Arguments:
stapsdt 0x00000038 NT_STAPSDT (SystemTap probe descriptors)
Provider: "hello_usdt"
Name: "exit"
Location: 0x0000000000000606, Base: 0x0000000000000694, Semaphore: 0x0000000000000000
Arguments: -4@-4(%rbp)
Sample w/ Semaphore support
USDT probe can use a semaphore for the implementation of is-enabled: a feature from DTrace where the tracer can inform the target process that a particular event is being traced. The target process can then choose to do some more expensive processing, usually fetching and formatting arguments for a USDT probe.
tp_provider.d
provider hello_semaphore_usdt {
probe enter();
probe exit(int exit_code);
}
dtrace -G -s tp_provider.d -o tp_provider.o
dtrace -h -s tp_provider.d -o tp_provider.h
tp_provider.h
/* Generated by the Systemtap dtrace wrapper */
#define _SDT_HAS_SEMAPHORES 1
#define STAP_HAS_SEMAPHORES 1 /* deprecated */
#include <sys/sdt.h>
/* HELLO_SEMAPHORE_USDT_ENTER ( ) */
#if defined STAP_SDT_V1
#define HELLO_SEMAPHORE_USDT_ENTER_ENABLED() __builtin_expect (enter_semaphore, 0)
#define hello_semaphore_usdt_enter_semaphore enter_semaphore
#else
#define HELLO_SEMAPHORE_USDT_ENTER_ENABLED() __builtin_expect (hello_semaphore_usdt_enter_semaphore, 0)
#endif
__extension__ extern unsigned short hello_semaphore_usdt_enter_semaphore __attribute__ ((unused)) __attribute__ ((section (".probes")));
#define HELLO_SEMAPHORE_USDT_ENTER() \\
DTRACE_PROBE (hello_semaphore_usdt, enter)
/* HELLO_SEMAPHORE_USDT_EXIT ( int exit_code ) */
#if defined STAP_SDT_V1
#define HELLO_SEMAPHORE_USDT_EXIT_ENABLED() __builtin_expect (exit_semaphore, 0)
#define hello_semaphore_usdt_exit_semaphore exit_semaphore
#else
#define HELLO_SEMAPHORE_USDT_EXIT_ENABLED() __builtin_expect (hello_semaphore_usdt_exit_semaphore, 0)
#endif
__extension__ extern unsigned short hello_semaphore_usdt_exit_semaphore __attribute__ ((unused)) __attribute__ ((section (".probes")));
#define HELLO_SEMAPHORE_USDT_EXIT(arg1) \\
DTRACE_PROBE1 (hello_semaphore_usdt, exit, arg1)
hello-semaphore-usdt.c
#include "tp_provider.h"
int main() {
if (HELLO_SEMAPHORE_USDT_ENTER_ENABLED()) {
HELLO_SEMAPHORE_USDT_ENTER();
}
int reval = 0;
if (HELLO_SEMAPHORE_USDT_EXIT_ENABLED()) {
HELLO_SEMAPHORE_USDT_EXIT(reval);
}
}
gcc -c ./hello-semaphore-usdt.c
gcc -o ./hello-semaphore-usdt ./hello-semaphore-usdt.o ./tp_provider.o
vagrant@ubuntu-bionic:~/labs/hello-semaphore-usdt$ readelf -n ./hello-semaphore-usdt
Displaying notes found in: .note.ABI-tag
Owner Data size Description
GNU 0x00000010 NT_GNU_ABI_TAG (ABI version tag)
OS: Linux, ABI: 3.2.0
Displaying notes found in: .note.gnu.build-id
Owner Data size Description
GNU 0x00000014 NT_GNU_BUILD_ID (unique build ID bitstring)
Build ID: 323fff32c4a2dd7301a9e3470adcf15ed2fc85bc
Displaying notes found in: .note.stapsdt
Owner Data size Description
stapsdt 0x00000034 NT_STAPSDT (SystemTap probe descriptors)
Provider: hello_semaphore_usdt
Name: enter
Location: 0x000000000000060d, Base: 0x00000000000006c4, Semaphore: 0x0000000000201010
Arguments:
stapsdt 0x0000003e NT_STAPSDT (SystemTap probe descriptors)
Provider: hello_semaphore_usdt
Name: exit
Location: 0x0000000000000624, Base: 0x00000000000006c4, Semaphore: 0x0000000000201012
Arguments: -4@-4(%rbp)
Register USDT probe via ftrace(under the hood, ftrace+uprobe)
USDT probes are static tracing markers placed in an executable or library. The probes are just nop instructions emitted by the compiler, whose locations are recorded in the notes section of the ELF binary. Tracing apps can instrument these locations and retrieve probe arguments. Specifically, uprobes (which BPF already supports) can be used to instrument the traced location.
-
On target app side: comipler puts a
nopin the location which use macro and also records the info to elf metadata -
On the tracer side: read the elf and instrument the location via uprobes
-
before run uprobe, we disas the programming as below:
ubuntu@ubuntu-xenial:~/labs/hello-usdt$ gdb ./tick GNU gdb (Ubuntu 7.11.1-0ubuntu1~16.04) 7.11.1 Copyright (C) 2016 Free Software Foundation, Inc. License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html> This is free software: you are free to change and redistribute it. There is NO WARRANTY, to the extent permitted by law. Type "show copying" and "show warranty" for details. This GDB was configured as "x86_64-linux-gnu". Type "show configuration" for configuration details. For bug reporting instructions, please see: <http://www.gnu.org/software/gdb/bugs/>. Find the GDB manual and other documentation resources online at: <http://www.gnu.org/software/gdb/documentation/>. For help, type "help". Type "apropos word" to search for commands related to "word"... Reading symbols from ./tick...done. (gdb) disas main Dump of assembler code for function main: 0x0000000000400566 <+0>: push %rbp 0x0000000000400567 <+1>: mov %rsp,%rbp 0x000000000040056a <+4>: sub $0x20,%rsp 0x000000000040056e <+8>: mov %edi,-0x14(%rbp) 0x0000000000400571 <+11>: mov %rsi,-0x20(%rbp) 0x0000000000400575 <+15>: addl $0x1,-0x4(%rbp) 0x0000000000400579 <+19>: nop 0x000000000040057a <+20>: movzwl 0x200ac1(%rip),%eax # 0x601042 <tick_loop2_semaphore> 0x0000000000400581 <+27>: movzwl %ax,%eax 0x0000000000400584 <+30>: test %rax,%rax 0x0000000000400587 <+33>: je 0x40058a <main+36> 0x0000000000400589 <+35>: nop 0x000000000040058a <+36>: mov -0x4(%rbp),%eax 0x000000000040058d <+39>: mov %eax,%esi 0x000000000040058f <+41>: mov $0x400644,%edi 0x0000000000400594 <+46>: mov $0x0,%eax 0x0000000000400599 <+51>: callq 0x400430 <printf@plt> 0x000000000040059e <+56>: mov $0x5,%edi 0x00000000004005a3 <+61>: callq 0x400450 <sleep@plt> 0x00000000004005a8 <+66>: jmp 0x400575 <main+15> End of assembler dump. (gdb) -
Use objdump or /proc/PID/maps to get the
loadaddress:ubuntu@ubuntu-xenial:~/labs/hello-usdt$ objdump -x ./tick | more ./tick: file format elf64-x86-64 ./tick architecture: i386:x86-64, flags 0x00000112: EXEC_P, HAS_SYMS, D_PAGED start address 0x0000000000400470 Program Header: PHDR off 0x0000000000000040 vaddr 0x0000000000400040 paddr 0x0000000000400040 align 2**3 filesz 0x00000000000001f8 memsz 0x00000000000001f8 flags r-x INTERP off 0x0000000000000238 vaddr 0x0000000000400238 paddr 0x0000000000400238 align 2**0 filesz 0x000000000000001c memsz 0x000000000000001c flags r-- LOAD off 0x0000000000000000 vaddr 0x0000000000400000 paddr 0x0000000000400000 align 2**21 filesz 0x00000000000007a4 memsz 0x00000000000007a4 flags r-x LOAD off 0x0000000000000e10 vaddr 0x0000000000600e10 paddr 0x0000000000600e10 align 2**21 So the `0x0000000000400000` is the load address
The uprobes documentation, uprobetracer.txt, gets this from /proc/PID/maps, however, that technique requires a running process.
-
Get USDT point address
ubuntu@ubuntu-xenial:~/labs/hello-usdt$ readelf -n ./tick Displaying notes found at file offset 0x00000254 with length 0x00000020: Owner Data size Description GNU 0x00000010 NT_GNU_ABI_TAG (ABI version tag) OS: Linux, ABI: 2.6.32 Displaying notes found at file offset 0x00000274 with length 0x00000024: Owner Data size Description GNU 0x00000014 NT_GNU_BUILD_ID (unique build ID bitstring) Build ID: c53d0a44bcfd8bdbce49b926858564a0b473120a Displaying notes found at file offset 0x00001078 with length 0x00000088: Owner Data size Description stapsdt 0x0000002f NT_STAPSDT (SystemTap probe descriptors) Provider: tick Name: loop1 Location: 0x0000000000400579, Base: 0x000000000040064c, Semaphore: 0x0000000000601040 Arguments: -4@-4(%rbp) stapsdt 0x0000002f NT_STAPSDT (SystemTap probe descriptors) Provider: tick Name: loop2 Location: 0x0000000000400589, Base: 0x000000000040064c, Semaphore: 0x0000000000601042 Arguments: -4@-4(%rbp) so we can see the loop1 location is `0x0000000000400579` and loop2 location is `0x0000000000400589` -
Tracking the loop1
sudo /home/ubuntu/perf-tools/bin/uprobe "p:/home/ubuntu/labs/hello-usdt/tick:0x579" -
Check the disas main result:
file:///home/lizh/Desktop/usdt.html ubuntu@ubuntu-xenial:~/labs/hello-usdt$ sudo gdb -p 2581 GNU gdb (Ubuntu 7.11.1-0ubuntu1~16.04) 7.11.1 Copyright (C) 2016 Free Software Foundation, Inc. License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html> This is free software: you are free to change and redistribute it. There is NO WARRANTY, to the extent permitted by law. Type "show copying" and "show warranty" for details. This GDB was configured as "x86_64-linux-gnu". Type "show configuration" for configuration details. For bug reporting instructions, please see: <http://www.gnu.org/software/gdb/bugs/>. Find the GDB manual and other documentation resources online at: <http://www.gnu.org/software/gdb/documentation/>. For help, type "help". Type "apropos word" to search for commands related to "word". Attaching to process 2581 Reading symbols from /home/ubuntu/labs/hello-usdt/tick...done. Reading symbols from /lib/x86_64-linux-gnu/libc.so.6...Reading symbols from /usr/lib/debug//lib/x86_64-linux-gnu/libc-2.23.so...done. done. Reading symbols from /lib64/ld-linux-x86-64.so.2...Reading symbols from /usr/lib/debug//lib/x86_64-linux-gnu/ld-2.23.so...done. done. 0x00007f7cec5de2f0 in __nanosleep_nocancel () at ../sysdeps/unix/syscall-template.S:84 84 ../sysdeps/unix/syscall-template.S: No such file or directory. (gdb) disas main Dump of assembler code for function main: 0x0000000000400566 <+0>: push %rbp 0x0000000000400567 <+1>: mov %rsp,%rbp 0x000000000040056a <+4>: sub $0x20,%rsp 0x000000000040056e <+8>: mov %edi,-0x14(%rbp) 0x0000000000400571 <+11>: mov %rsi,-0x20(%rbp) 0x0000000000400575 <+15>: addl $0x1,-0x4(%rbp) 0x0000000000400579 <+19>: int3 0x000000000040057a <+20>: movzwl 0x200ac1(%rip),%eax # 0x601042 <tick_loop2_semaphore> 0x0000000000400581 <+27>: movzwl %ax,%eax 0x0000000000400584 <+30>: test %rax,%rax 0x0000000000400587 <+33>: je 0x40058a <main+36> 0x0000000000400589 <+35>: nop 0x000000000040058a <+36>: mov -0x4(%rbp),%eax 0x000000000040058d <+39>: mov %eax,%esi 0x000000000040058f <+41>: mov $0x400644,%edi 0x0000000000400594 <+46>: mov $0x0,%eax 0x0000000000400599 <+51>: callq 0x400430 <printf@plt> 0x000000000040059e <+56>: mov $0x5,%edi 0x00000000004005a3 <+61>: callq 0x400450 <sleep@plt> 0x00000000004005a8 <+66>: jmp 0x400575 <main+15> End of assembler dump. -
stop tracking, and observe again:
ubuntu@ubuntu-xenial:~/labs/hello-usdt$ sudo gdb -p 2581 GNU gdb (Ubuntu 7.11.1-0ubuntu1~16.04) 7.11.1 Copyright (C) 2016 Free Software Foundation, Inc. License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html> This is free software: you are free to change and redistribute it. There is NO WARRANTY, to the extent permitted by law. Type "show copying" and "show warranty" for details. This GDB was configured as "x86_64-linux-gnu". Type "show configuration" for configuration details. For bug reporting instructions, please see: <http://www.gnu.org/software/gdb/bugs/>. Find the GDB manual and other documentation resources online at: <http://www.gnu.org/software/gdb/documentation/>. For help, type "help". Type "apropos word" to search for commands related to "word". Attaching to process 2581 Reading symbols from /home/ubuntu/labs/hello-usdt/tick...done. Reading symbols from /lib/x86_64-linux-gnu/libc.so.6...Reading symbols from /usr/lib/debug//lib/x86_64-linux-gnu/libc-2.23.so...done. done. Reading symbols from /lib64/ld-linux-x86-64.so.2...Reading symbols from /usr/lib/debug//lib/x86_64-linux-gnu/ld-2.23.so...done. done. 0x00007f7cec5de2f0 in __nanosleep_nocancel () at ../sysdeps/unix/syscall-template.S:84 84 ../sysdeps/unix/syscall-template.S: No such file or directory. (gdb) disas main Dump of assembler code for function main: 0x0000000000400566 <+0>: push %rbp 0x0000000000400567 <+1>: mov %rsp,%rbp 0x000000000040056a <+4>: sub $0x20,%rsp 0x000000000040056e <+8>: mov %edi,-0x14(%rbp) 0x0000000000400571 <+11>: mov %rsi,-0x20(%rbp) 0x0000000000400575 <+15>: addl $0x1,-0x4(%rbp) 0x0000000000400579 <+19>: nop 0x000000000040057a <+20>: movzwl 0x200ac1(%rip),%eax # 0x601042 <tick_loop2_semaphore> 0x0000000000400581 <+27>: movzwl %ax,%eax 0x0000000000400584 <+30>: test %rax,%rax 0x0000000000400587 <+33>: je 0x40058a <main+36> 0x0000000000400589 <+35>: nop 0x000000000040058a <+36>: mov -0x4(%rbp),%eax 0x000000000040058d <+39>: mov %eax,%esi 0x000000000040058f <+41>: mov $0x400644,%edi 0x0000000000400594 <+46>: mov $0x0,%eax 0x0000000000400599 <+51>: callq 0x400430 <printf@plt> 0x000000000040059e <+56>: mov $0x5,%edi 0x00000000004005a3 <+61>: callq 0x400450 <sleep@plt> 0x00000000004005a8 <+66>: jmp 0x400575 <main+15> End of assembler dump.Actually, the better way to do the USDT probe is via bcc or bpftrace frontend tools. I still would like to demonstrate it with a ftrace here, because the hacking steps can show us with more information which can greatly help us understand how USDT works inside. If you are interested in this, please refer to blogs hacking-linux-usdt-ftrace and linux-ftrace-uprobe for more details.
Register USDT probe via bcc(under the hood, eBPF+uprobe)
-
Use bcc tool for the tracking
sudo /usr/share/bcc/tools/trace -p 2581 "u:/home/ubuntu/labs/hello-usdt/tick:loop1" -
The disas main is below:
ubuntu@ubuntu-xenial:~/labs/hello-usdt$ sudo gdb -p 2581 GNU gdb (Ubuntu 7.11.1-0ubuntu1~16.04) 7.11.1 Copyright (C) 2016 Free Software Foundation, Inc. License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html> This is free software: you are free to change and redistribute it. There is NO WARRANTY, to the extent permitted by law. Type "show copying" and "show warranty" for details. This GDB was configured as "x86_64-linux-gnu". Type "show configuration" for configuration details. For bug reporting instructions, please see: <http://www.gnu.org/software/gdb/bugs/>. Find the GDB manual and other documentation resources online at: <http://www.gnu.org/software/gdb/documentation/>. For help, type "help". Type "apropos word" to search for commands related to "word". Attaching to process 2581 Reading symbols from /home/ubuntu/labs/hello-usdt/tick...done. Reading symbols from /lib/x86_64-linux-gnu/libc.so.6...Reading symbols from /usr/lib/debug//lib/x86_64-linux-gnu/libc-2.23.so...done. done. Reading symbols from /lib64/ld-linux-x86-64.so.2...Reading symbols from /usr/lib/debug//lib/x86_64-linux-gnu/ld-2.23.so...done. done. 0x00007f7cec5de2f0 in __nanosleep_nocancel () at ../sysdeps/unix/syscall-template.S:84 84 ../sysdeps/unix/syscall-template.S: No such file or directory. (gdb) disas main Dump of assembler code for function main: 0x0000000000400566 <+0>: push %rbp 0x0000000000400567 <+1>: mov %rsp,%rbp 0x000000000040056a <+4>: sub $0x20,%rsp 0x000000000040056e <+8>: mov %edi,-0x14(%rbp) 0x0000000000400571 <+11>: mov %rsi,-0x20(%rbp) 0x0000000000400575 <+15>: addl $0x1,-0x4(%rbp) 0x0000000000400579 <+19>: int3 0x000000000040057a <+20>: movzwl 0x200ac1(%rip),%eax # 0x601042 <tick_loop2_semaphore> 0x0000000000400581 <+27>: movzwl %ax,%eax 0x0000000000400584 <+30>: test %rax,%rax 0x0000000000400587 <+33>: je 0x40058a <main+36> 0x0000000000400589 <+35>: nop 0x000000000040058a <+36>: mov -0x4(%rbp),%eax 0x000000000040058d <+39>: mov %e以上是关于Linux内核 eBPF基础: 探索USDT探针的主要内容,如果未能解决你的问题,请参考以下文章