由浅入深,探索前端下载,妈妈再也不用担心我不会下载了(文件下载,图片下载,截屏下载)
Posted MmM豆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了由浅入深,探索前端下载,妈妈再也不用担心我不会下载了(文件下载,图片下载,截屏下载)相关的知识,希望对你有一定的参考价值。
一、下载方式
一般来说,前端下载,一般分为利用浏览器下载,和a标签触发下载
1.浏览器下载
有时候我们会发现一张图片的路径如果直接输入在浏览器地址栏中就会直接触发下载
例如下面图片
http://webond.tpddns.cn:8823/facility/tempImage.json?path=upload/196afac1-3e44-47df-910b-8783a9807f00.png
但有些图片放入浏览器的地址栏却并没有触发下载,而是在也浏览器中出现图片预览效果
例如:
https://img-blog.csdnimg.cn/2021052711301061.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21hcmVuZHU=,size_16,color_FFFFFF,t_70
探求其原因,我们分别查看了2者了请求头
发现能触发下载的图片请求头存在该属性Content-Disposition: attachment
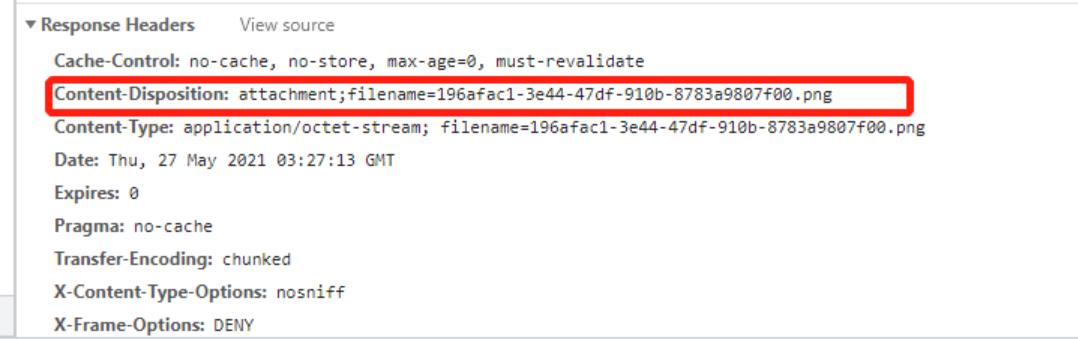
浏览器下载,本质其实是后端在返回的响应头中添加
Content-Disposition:attachment; filename=’下载的文件名‘
那么只要是在浏览器地址栏中访问就能直接触发下载,
我们常用form表单,将下载的url在一个iframe中打开,来触发下载
2.a标签触发下载
对于上述这种存在下载头的url,使用a标签也能触发下载,(同样也是通过浏览器下载,如果没有下载头,a标签会预览该图片)
<a herf='url' download='下载的文件名' />
a标签触发下载,一种是上面的带下载头的,还有2种 dataUrl(base64), 和 blobUrl(流),这2种也能直接触发下载,也是用来实现纯前端下载的方式,如前端构建excel,截屏等,然后转换成blobUrl实现下载,对于base64想必大多数人都有疑惑,
什么是base64
基于64个可打印字符来表示二进制数据,在HTTP环境下传递较长的标识信息
简单说就是一串有内容的编码,例如在html中,使用base64的图片,将不会加载请求,因为这串编码就是这张图片,弊端就是浏览器也不会缓存这张图片,因为不是远程加载 的图片
如下:上传文件并转换为base64
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<input type="file" id='fileId'>
</body>
<script>
// 上传图片转换成base64
let upDOM = document.getElementById('fileId')
upDOM.addEventListener('change', (e) => {
console.log(e)
console.log(upDOM.files[0])
var reader = new FileReader();
reader.readAsDataURL(upDOM.files[0]);
reader.onload = function (ie) {
var Base64Val = this.result;
console.log('Base64')
console.log(Base64Val)
}
})
</script>
</html>
通过上述例子,大家可以发现base64很长,所以当图片过大时,使用base64来下载,就会下载失败,因为超出了get的长度限制,所以,大部分情况下,不会直接使用base64,而是进一步转换为blobUrl文件流
// base64转换为blob流
function convertBase64UrlToBlob(base64) {
var parts = base64.dataURL.split(";base64,");
var contentType = parts[0].split(":")[1];
var raw = window.atob(parts[1]);
var rawLength = raw.length;
var uInt8Array = new Uint8Array(rawLength);
for (var i = 0; i < rawLength; i++) {
uInt8Array[i] = raw.charCodeAt(i);
}
return new Blob([uInt8Array], {
type: contentType
});
}
var blob = convertBase64UrlToBlob (base64)
var blobUrl= URL.createObjectURL(blob);
自定义下载文件名
一般情况下,下载的文件名字为后端定义好的文件名,或者是服务器存储的文件名,前端如果要修改,可以利用a标签的download 属性,自己定义下载的文件名,
<a herf='url' download='下载的文件名' />
但要注意一点,能使用download修改名字,要么是同源,要么只能是dataUrl 和bolbUrl,否则无法修改下载的名字
二、实战下载
1.文件下载
一般类似exsel这类下载文件,是需要给后台提交数据来下载的,一般也为post接口,对于这样的下载,
第一种方式使用表单提交 后台也需要接受的是formdata数据
如果页面有现有的表单
没有就用js创建一个隐形的form来提交表单
第二种方式还是使用ajax 后台接收正常的json即可
使用ajax是无法直接下载的,请求成功后,后台会返回一个文件流
看见会是这样的乱码但没什么影响的
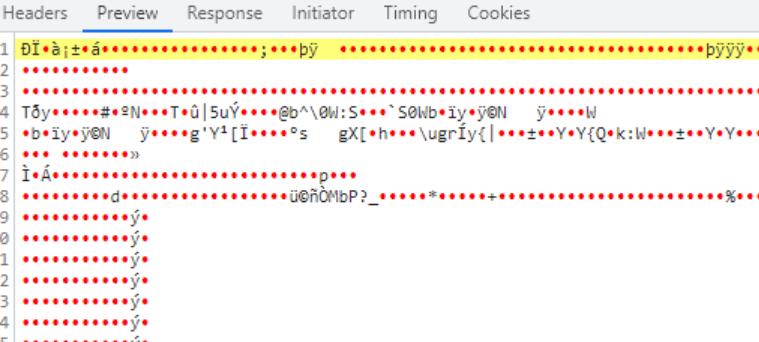
request 为引入的封装好的axios
下面有几个点需要注意
1.是要定义响应的type ,responseType: “arraybuffer”,告诉服务器需要返回一个buffer,不然下载下来很可能 是乱码
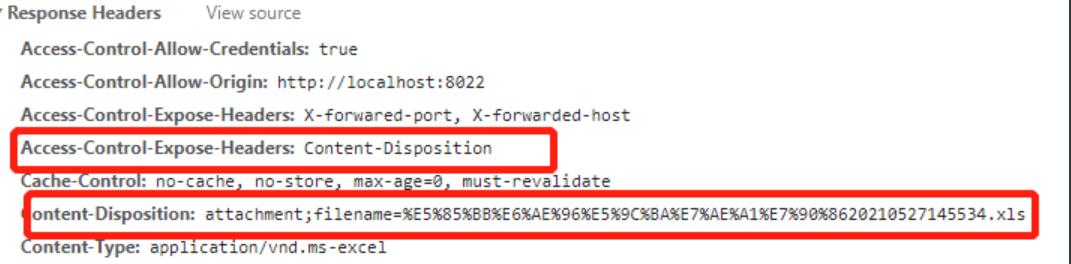
2.我们需要在返回的header把名字取下来,
const fileName = res.headers['content-disposition'].split('=')[1]
//有时候,后端定义的fileName,无效,下载下来还是服务器存储的名字
但是会发现明明header里面有就是取不到Content-Disposcition,
这个是响应头Access-Control-Expose-Headers规定的可以暴露给外部的header
默认情况下,只有七种 simple response headers (简单响应首部)可以暴露给外部:
如果想要让客户端可以访问到其他的首部信息,可以将它们在 Access-Control-Expose-Headers 里面列出来。
所以后端只需要配置
response.setHeader("Access-Control-Expose-Headers","Content-Disposcition")
function exportFile(url,data){
request({
//告诉服务器需要返回一个buffer,不然下载下来很可能 是乱码
responseType: "arraybuffer",
url: url,
method: 'post',
data: data
}).then(res=>{
const content = res.data
//转换成blob对象
const blob = new Blob([content],{ type: 'application/vnd.ms-excel;charset=utf-8' })
//获取文件名字
const fileName = res.headers['content-disposition'].split('=')[1]
const elink = document.createElement('a')
elink.download = decodeURI(fileName)
elink.style.display = 'none'
console.log(res);
//生成blobUrl
elink.href = URL.createObjectURL(blob)
document.body.appendChild(elink)
elink.click()
URL.revokeObjectURL(elink.href) // 释放URL 对象
document.body.removeChild(elink)
})
}
2.图片下载
如果是图片流,下载方式同上
但大多数时候,是使用一个url来下载
a href="http://webond.tpddns.cn:8823/facility/tempImage.json?path=upload/196afac1-3e44-47df-910b-8783a9807f00.png" download="修改的名字.png">点击</a>
上面提到过 需要后端设置下载头才能触发,但是因为不是同源无法修改名字

但如果想自定义名字,同时也不需要后端设置下载头呢
这个时候我们就需要利用cavas转换一下,
tips注意 cavas,必须要跨越的图片,否则画出来就是空白,同时后台需要设置跨越 指定域名或者*,不然会报跨越的错误,同时图片也无法加载

img.crossOrigin = "Anonymous"; //设置图片跨越,没有跨越cavas会被污染无法画出
// 转换为base64
function convertUrlToBase64(url) {
return new Promise(function (resolve, reject) {
var img = new Image();
//设置图片跨越,没有跨越cavas会被污染无法画出
img.crossOrigin = "Anonymous";
img.src = url;
img.onload = function () {
var canvas = document.createElement("canvas");
canvas.width = img.width;
canvas.height = img.height;
var ctx = canvas.getContext("2d");
ctx.drawImage(img, 0, 0, img.width, img.height);
var ext = img.src
.substring(img.src.lastIndexOf(".") + 1)
.toLowerCase();
//转换为base64
var dataURL = canvas.toDataURL("image/" + ext);
var base64 = {
dataURL: dataURL,
type: "image/" + ext,
ext: ext
};
resolve(base64);
};
});
}
// base64转换为blob流
function convertBase64UrlToBlob(base64) {
var parts = base64.dataURL.split(";base64,");
var contentType = parts[0].split(":")[1];
var raw = window.atob(parts[1]);
var rawLength = raw.length;
var uInt8Array = new Uint8Array(rawLength);
for (var i = 0; i < rawLength; i++) {
uInt8Array[i] = raw.charCodeAt(i);
}
return new Blob([uInt8Array], {
type: contentType
});
}
// 判断浏览器
function myBrowser() {
var userAgent = navigator.userAgent; //取得浏览器的userAgent字符串
if (userAgent.indexOf("OPR") > -1) {
return "Opera";
} //判断是否Opera浏览器 OPR/43.0.2442.991
if (userAgent.indexOf("Firefox") > -1) {
return "FF";
} //判断是否Firefox浏览器 Firefox/51.0
if (userAgent.indexOf("Trident") > -1) {
return "IE";
} //判断是否IE浏览器 Trident/7.0; rv:11.0
if (userAgent.indexOf("Edge") > -1) {
return "Edge";
} //判断是否Edge浏览器 Edge/14.14393
if (userAgent.indexOf("Chrome") > -1) {
return "Chrome";
} // Chrome/56.0.2924.87
if (userAgent.indexOf("Safari") > -1) {
return "Safari";
} //判断是否Safari浏览器 AppleWebKit/534.57.2 Version/5.1.7 Safari/534.57.2
}
下载图片
var url = 'https://img-blog.csdnimg.cn/2021052711301061.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21hcmVuZHU=,size_16,color_FFFFFF,t_70'
var that = this
var fileName = '自定义的名字'
convertUrlToBase64(url).then(function (base64) {
console.log(base64);
// 图片转为base64
return
var blob = that.convertBase64UrlToBlob(base64); // 转为blob对象
// 下载
if (that.myBrowser() == "IE") {
window.navigator.msSaveBlob(blob, fileName + ".png");
} else if (that.myBrowser() == "FF") {
window.location.href = url;
} else {
var a = document.createElement("a");
a.download = fileName;
a.href = URL.createObjectURL(blob);
document.body.appendChild(a)
a.click();
URL.revokeObjectURL(a.href) // 释放URL 对象
document.body.removeChild(a)
}
});
将上面几个代码和在一起就是完整的转换下载
3.截屏下载(解决HTML2cavas截屏空白问题)
有些时候,我们需要对图片进行处理拼接等,这个时候需要用到截屏,我们可以使用插件html2cavas,来做到截屏效果
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<script src="https://cdn.bootcdn.net/ajax/libs/html2canvas/0.5.0-beta4/html2canvas.js"></script>
<style>
#content {
background: red;
display: flex;
justify-content: center;
align-items: center;
width: 500px;
height: 500px;
}
#capture{
margin-left: 20px;
width: 500px;
height: 500px;
}
div{
float: left;
}
img {
width: 90%;
height: auto;
}
</style>
</head>
<body>
<div id="content">
<img src="https://img-blog.csdnimg.cn/2021052711301061.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21hcmVuZHU=,size_16,color_FFFFFF,t_70"
alt="">
</div>
<div id="capture">
<p>截屏的图</p>
</div>
<button onclick="capture()">截屏</button>
</body>
</html>
<script>
function capture(data) {
const el = document.getElementById('content')
html2canvas(el).then(canvas => {
const imgUrl = canvas.toDataURL("image/png"); // 获取生成的图片的url
console.log('imgUrl');
console.log(imgUrl);
var img = new Image();
img.src = imgUrl;
document.getElementById('capture').appendChild(img)
})
}
</script>
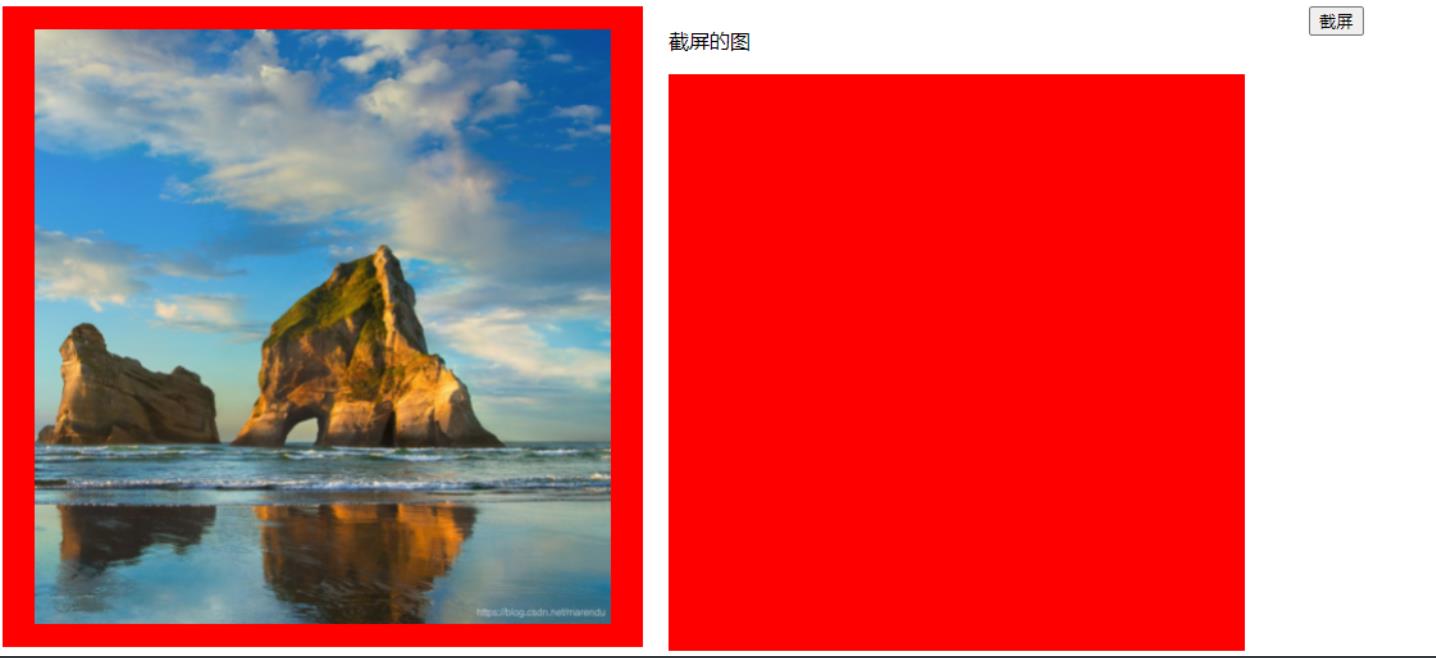
但是发现并没有把图片截取下来,原因就是上面说的图片没跨域无法在cavas上展现
我们需要3点配置,
1.图片上设置跨域crossorigin=“anonymous”
<img crossorigin="anonymous" src=''/>
2.html2cavas 跨域useCORS:true
html2canvas(el,{useCORS:true})
3.后台配置跨域头

<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<script src="https://cdn.bootcdn.net/ajax/libs/html2canvas/0.5.0-beta4/html2canvas.js"></script>
<style>
#content {
background: red;
display: flex;
justify-content: center;
align-items: center;
width: 500px;
height: 500px;
}
#capture {
margin-left: 20px;
width: 500px;
height: 500px;
}
div {
float: left;
}
img {
width: 90%;
height: auto;
}
</style>
</head>
<body>
<div id="content">
<!-- crossorigin="anonymous" 配置图片跨域 -->
<img crossorigin="anonymous" src="https://img-blog.csdnimg.cn/2021052711301061.png?x-oss-process=image/watermark,type_ZmFuZ以上是关于由浅入深,探索前端下载,妈妈再也不用担心我不会下载了(文件下载,图片下载,截屏下载)的主要内容,如果未能解决你的问题,请参考以下文章