高性能 JavaScriptの笔记-- 时代变了
Posted 空城机
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了高性能 JavaScriptの笔记-- 时代变了相关的知识,希望对你有一定的参考价值。
字符串
字符串连接会导致令人惊讶的性能问题
字符串拼接方法
| 方法 | 示例 | 说明 |
|---|---|---|
| The + operator | str = “a” + “b” + “c” | 加 |
| The += operator | str = “a” ; str += “b” ; str += “c” | 加等 |
| array.join() | str = [“a”, “b”, “c”].join() | 数组变字符串 |
| string.concat() | str = “a” ; str = str.concat(“b”, “c”) | concat连接方法 |
当连接少量字符串时,这些方法运行速度都很快。
加(+)和加等(+=)
常用 += 操作:
var str = ''
str += 'one' + 'two'
操作经历步骤:
- 在内存中创建一个临时字符串
- 连接后的字符串“onetwo”被赋值给该临时字符串
- 临时字符串与str当前值连接
- 结果赋值给str
操作优化 (时代变了,这操作居然没有优化):
str = str + 'one' + 'two'
这样可以避免产生临时字符串,但是这样的效率真的高吗?
实际测试发现书上内容错误
我实际循环多次操作后,发现str += “one” + "two"速度更快,是我使用的测试代码不准确吗?
纸上得来终觉浅,知此事要躬行

测试代码:
(function () {
var str = '';
console.time('str += "one" + "two"')
for (var i = 0; i < 10000000; i++) {
str += 'one' + 'two';
}
console.timeEnd('str += "one" + "two"')
})();
(function () {
var atr = '';
console.time('atr = atr + "one" + "two"')
for (var i = 0; i < 10000000; i++) {
atr = atr + 'one' + 'two';
}
console.timeEnd('atr = atr + "one" + "two"')
})()
chrome浏览器:

IE浏览器:
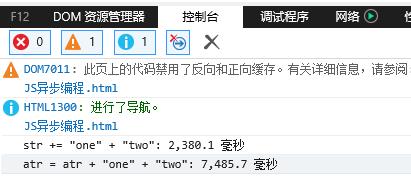
火狐浏览器:
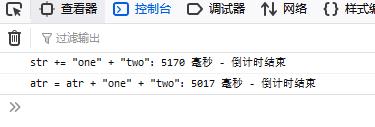
有关加(+)和加等(+=)效率测试
代码:
(function () {
var atr = '';
console.time("atr = atr + 'one'")
for (var i = 0; i < 10000000; i++) {
atr = atr + 'one';
}
console.timeEnd("atr = atr + 'one'")
})();
(function () {
var str = '';
console.time("str += 'one'")
for (var i = 0; i < 10000000; i++) {
str += 'one' ;
}
console.timeEnd("str += 'one'")
})();
chrome浏览器:
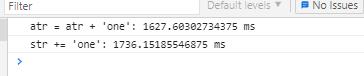
Firefox火狐:

如果循环次数量极大,在火狐浏览器中, +=操作符的性能会远远优于 +操作符
Array.join()
数组项合并,书上的内容和我实际测试似乎又不太一样

在我测试时,发现一个有1000000个’one’字符串组成的[ ‘one’, ‘one’, … ]的数组使用join合并,远比 +操作符 运算1000000个’one’效率更高
测试代码:
(function () {
var atr = '';
console.time("atr = atr + 'one'")
for (var i = 0; i < 1000000; i++) {
atr = atr + 'one';
}
console.timeEnd("atr = atr + 'one'")
})();
(function () {
var str = '', arr = [];
console.time("arr.join")
for(var i = 0; i < 1000000; i++){
arr.push('one');
}
str = arr.join("");
console.timeEnd("arr.join")
})();
chrome浏览器:
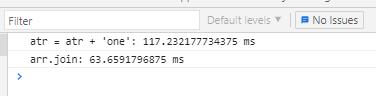
火狐浏览器:

IE浏览器:
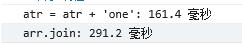
时代变了

时代好像变了,经过测试,大量循环测试后发现,通过数组转字符串Array.join的方式是最快一些的, 单纯的 +号操作速度居然和concat慢的差不多
不知道是否是浏览器引擎做了优化,还是Array.join()已经提升了性能
如果各位不愿意相信,也可以自己去测试一下
如果觉得我的测试代码不正确,可以马上告诉我,因为我也在怀疑当中
(function () {
let str = '';
console.time("+号操作")
for (let i = 0; i < 1000000; i++) {
str = str + 'one';
}
console.timeEnd("+号操作")
})();
(function () {
let str = '';
console.time("+=操作符")
for (let i = 0; i < 1000000; i++) {
str += 'one';
}
console.timeEnd("+=操作符")
})();
(function () {
let str = '', arr = [];
for(let i = 0; i < 1000000; i++){
arr.push('one');
}
console.time("Arr.join")
str = arr.join("");
console.timeEnd("Arr.join")
})();
(function () {
let str = '';
console.time("Concat")
for(let i = 0; i < 1000000; i++){
str = str.concat('one')
}
console.timeEnd("Concat")
})();
正则表达式
这里介绍一下正则表达式手册:https://gitee.com/thinkyoung/learn_regex
当然这份手册不是原装,不过也是比较全面了
正则表达式工作原理
处理步骤:
-
编译
- 创建了一个正则表达式对象,浏览器会验证表达式,然后转化成一个原生代码程序。
- 如果把正则对象赋值给一个变量,可以避免重复执行这一步骤
-
设置起始位置
- 当正则类进入使用状态,首先确定目标字符串搜索起始位置。这是由字符串的起始字符或者正则表达式的lastIndex属性指定
- 如果尝试匹配失败,从下面的第四步返回,起始位置会变成最后一次匹配的下一个字符上
-
匹配每个正则表达式字元
- 从上面第二步知道正则表达式的起始位置后,可以逐个检查文本和正则表达式模式
- 当一个特定的字元匹配失败,正则表达式会试着回溯到之前尝试匹配的位置上,然后尝试其他可能的路径
-
匹配成功或失败
- 如果在字符串当前位置发现一个完全匹配的字段,宣布匹配成功
- 如果所有可能的路径都没有匹配到,正则表达式引擎返回第二步,从下一个字符开始尝试
- 如果字符串所有字符都经历这个过程,还没成功,宣布匹配失败
分支和回溯处理过程
例子:
let str = "hello people, happy life";
let reg = /h(ello|appy) life/g;
console.log(str.match(reg))
匹配结果自然是:
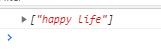
分析一下:
正则表达式reg的目标:为了匹配字符串中 “hello life” 或者 “happy life”
开始匹配:
- 首先查找 h 字母 。 字符串str 首字母就是h, 很幸运lucky
- 接下来 (ello|appy) 特征标群 语句 给你两个选择分支,查找"ello" 或者 “appy” 。 遵循从左往右的原则,查找当前 h之后是否有ello, 存在, 匹配到了 hello , 幸运
- 匹配ello后的空格,也是存在的,下一步匹配一下 “life”, 啊 ,不存在,目标字符串str中 “hello “之后是"people”,所以此路不通,赶紧回溯之前的选择分支,查找"appy”
- 当前首字母h后不是"appy",那这个选择分支也失败了,从头再来吧!
- 从字符串第二个字母继续查找h, 终于在","逗号后找到了第二个h字母
- 依旧是两个选择分支"ello" 或者 “appy”, "ello"查找失败, 回溯到分支选择 ,发现"appy"匹配成功,得到“happy”
- 空格匹配成功,匹配后面的"life",d=( ̄▽ ̄*)b 很好,匹配成功了,正则得到了结果“happy life”
提高正则表达式效率
因为正则表达式性能受目标字符串影响会产生较大差异,因此没有简单的方法可以测试正则表达式性能
只能笼统的把《高性能javascript》书上的方法说一下:
-
避免回溯失控
- 回溯失控主要发生在正则表达式本应快速匹配的地方,因为某些特殊字符串匹配动作导致运行缓慢甚至崩溃。
- 避免方案:使相邻的字元互斥,避免嵌套量词对同一字符串的相同部分多次匹配,通过重复利用预查的原子组去除不必要的回溯
-
关注如何让匹配更快失败
- 正则表达式慢的原因通常是匹配失败的过程慢,减少匹配失败次数的回溯次数
-
以简单、必需的字元开始
- 最理想的情况是,一个正则表达式的起始标记应当尽可能快速地测试并排除明显不匹配的位置
-
使用量词模式,使它们后面的字元互斥
-
减少分支数量,缩小分支范围
分支使用竖线 | 可以通过使用字符集和选项组件来减少对分支的需求替换前 替换后 cat|bat [cb]at red|read rea?d red|raw r(?:ed|aw) (.|\\r|\\n) [\\s\\S] -
使用非捕获组
-
只捕获感兴趣的文本以减少后处理
-
暴露必需的字元
-
使用合适的量词
-
把正则表达式赋值给变量并重用它们
-
将复杂的正则表达式拆分为简单的片段(化繁为简)
以上是关于高性能 JavaScriptの笔记-- 时代变了的主要内容,如果未能解决你的问题,请参考以下文章