云计算期末速成大法
Posted JintuZheng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了云计算期末速成大法相关的知识,希望对你有一定的参考价值。
笔记仅自用,杠勿cue我
1. 绪论
-
4V特征:Volume(规模大),Variety(种类杂),Velocity(变化快),Value(价值密度小)
-
从抽样到全样,从精确到非精确,从因果到关联
大数据的计算允许解在一定范围区间近似,由于数据异构多源多噪声,目标是寻找关联趋势的宏观特征
需要有:数据采集,管理,分析,可视化。
-
云计算的七个特点:超大规模,虚拟化,可靠,通用,伸缩,按需服务,廉价
-
云计算服务的分类:
【1】将软件作为服务:(针对应用的某些功能进行封装服务)Saas
【2】将平台作为服务(对资源抽象层次更进一步)Paas
【3】将基础设施作为服务(将硬件设施资源封装作为服务)Iaas -
虚拟化技术:
服务器虚拟化,存储虚拟化,网络虚拟化
【1】服务器虚拟化:将多个物理机虚拟成逻辑上的服务器。比如:网格技术
【2】存储虚拟化:分布的异构存储设备统一成一个或者多个存储池
【3】在底层物理网络和网络用户之间增加一个抽象层
(安全)
半虚拟化技术可以弥补虚拟化带来的性能损失
2. 数据采集
-
数据获取,数据集成,数据预处理
-
多源数据采集:有价值的数据最大化,无价值的数据最小化,和现实对象的偏差最小化,也需要做到:可靠性,时效性
-
数据预处理:
清理:缺失值处理,清理噪声
集成:传统集成和跨界集成
变换:规范化,平滑,概化
归约:降维
数据质量:准确,完整,一致 -
Pull-Base的意思是由集中式或者分布式的代理主动获取,Push-Based由源或者第三方推向数据汇聚点
-
数据收集:物理信息传感器,数据设备的日志文件,网络上的爬虫,众包和群智感知(所谓众包的意思是:每个人贡献一点,比如我们的报百科,wiki之类的),指导和协调群体的行为
-
数据离散化技术:我们希望处理的数据是离散化的,离散化的数据便于分析,因此,我们需要使用:等距,等频,优化离散的方法来对数据进行离散化。
等距:连续数据的取值范围分为n等分,等频:将观察点数量分为n等分。优化离散的意思是自变量和因变量一起观察,比如某个切分点导致连续数据发生突变的点则取样
-
数据集成:把不同源的信息集成,分为传统数据集成和跨界数据集成
数据集成就是将不同的数据源存放到同一个数据储存中(如数据仓库),从而方便后续的数据挖掘工作。比如我们有多个数据源,有文本文件,Excel文件,mysql数据表,为了方便数据的统计分析,我们需要把他们存放到同一个容器中,可以是数据库也可以是文本文件,这样一个过程我们就叫数据集成。传统数据集成和跨界数据集成的区别在于跨界数据集成是知识抽取而不是模式映射
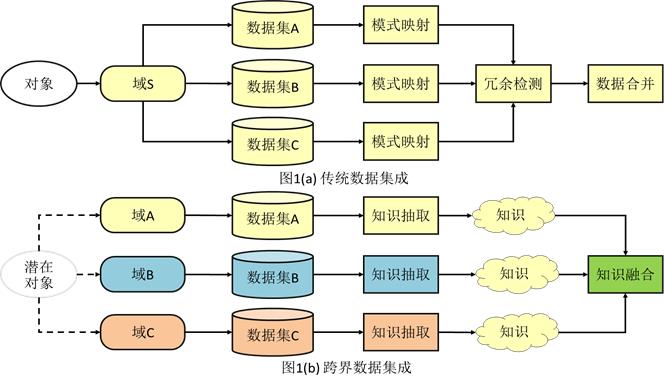
- 传统数据集成的主要目的是数据共享,定义为一个三元组
<GSM>,G是全局模式,S是数据源模式,M是全局模式和数据源模式之间的映射。 - 模式匹配:是标识两个数据对象是语义相关的过程
- 数据映射:是两个不同的数据模型之间的转换过程。
- 语义翻译:使用语义信息将一个数据模型的数据转换成另外一个数据模型
- 跨界数据集成的方法:基于阶段,基于特征(关联),基于语义的数据融合(相似性,概率,迁移学习)
- 数据变换:
- 标准化(0-1标准化,Z-Score标准化)
- 归一化
- 数据平滑(分箱回归,聚类)
3. 数据管理
- 分布式文件系统:两类,一类是面向以大文件,块数据读写为特点的数据分析业务,HDFS。一类是主要服务于通用文件系统需求并支持标准的可移植操作系统接口,GlusterFs。因此Gluster存储节点对等,无数据中心,HDFS是有元数据中心的。
- HDFS不适合 低延迟的数据访问,无法高效存储大量小文件,不支持多用户写入和任意修改文件。适合大文件,集群动态扩展,能有效保证数据一致性,数据吞吐量大。遵循主从架构,HDFS的块默认64MB,文件被分成多个块,按照块作为存储单位,NameNode存储元数据,元数据存储保存到内存中,保存文件,block,daatanode之间的映射关系。DataNode存储文件内容,文件内容保存在磁盘中,维护Block id 和datanode本地文件的映射关系。FSimage用于维护文件系统树以及文件树中所有文件和文件夹的元数据;Edit Log记录的是针对文件的创建删除重命名等操作信息。NameNode在启动的时候,会把FsImage中的内容加载到内存中,再执行EditLog中的各项操作,完成内存中的元数据和实际的同步,一旦内存完成文件系统元数据的映射就会创建一个新的Fsimage和空的EditLog文件。为什么我们需要EditLog,因为我们的FsImage往往都是非常大的,如果我们所有的更新操作都要对FsImage进行操作的化就会导致系统运行非常缓慢,可以理解为EditLog相当于FsImage的一个操作预备缓冲区。但是当EditLog变的非常大的时候,我们就需要启动安全模式,此时就不同对EditLog进行写操作了,因此我们有SecondaryNameNode,他就是HDFS元数据的备份,SecondaryNameNode相当于维护一个元数据的备份。SecondaryNameNode会定期和NameNode进行通信,所以,我们通常说他完成的任务是对FsImage和EditLog进行合并,完成合并之后SNN就会把新的FsImage发送到PrimaryNN上,用新的edit.new 替换掉EditLog。
- 分布式文件系统的对比:
| 特性 | HDFS | Ceph | GlusterFS |
|---|---|---|---|
| 元数据服务器 | 单个 | 多个 | 无 |
| POSXI可移植操作系统接口 | 不完全 | 兼容 | 兼容 |
| 文件分割 | 64MB块 | RAID0 | 不支持分块 |
| 网络 | TCP/IP | ALL | ALL |
| 元数据 | 元数据服务器管理全部元数据 | 元数据服务器管理少量元数据 | 客户端管理全部元数据 |
-
NoSQL数据库:Not only SQL,针对管理KV,文档,图等类型数据上的针对多种类型数据类型存储和访问特点而专门设计的数据库管理系统。KV数据库:Redis,Oracle,列族数据库HBase,文档数据库MongoDb,图数据库:Neo4J。
KV数据适用于内容缓存,用于高访问负载,查找速度飞快,数据无结构化,列族数据库做分布式的文件系统,查找速度也很快,文档数据库要求不严格表结构可以改变。
-
Mongodb是一款分布式的文档数据库,针对弱一致性要求的应用设计。

6. 列族数据库:
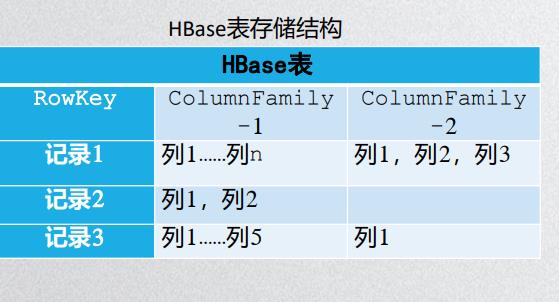
4. 数据分析
-
描述性分析:均值,中位数,方差,标准差,偏度,峰度。
方差和标准差都是表示数据的波动程度,肯定是越小越好咯
-
回归分析(探究多个变量之间的线性相关性)
-
基于机器学习的数据分析(非监督和监督学习)
【1】聚类就是非监督(Kmeans)
【2】分类监督(决策树,KNN) -
特征规约:数据和特征,模型和算法,最大程度从原始数据当中提取特征以供算法和模型使用。比如网页文本,通过特征选择之后,变成关键词向量。图像像素进行特征提取之后,数据变得更加简单化。(区分选择和提取的差别)
数据规约的原因:
- 分析过程中数据的维度和样本规模对复杂度影响严重,进行特征规约可以减少存储量和处理效率
- 维度小,可以对数据进行画像,分析他的结构,找出他的异常
- 对未来进行知识提取有帮助 -
互信息量:计算两个对象的相互性

-
卡方检验,用来检验两个变量独立性(出分析计算)
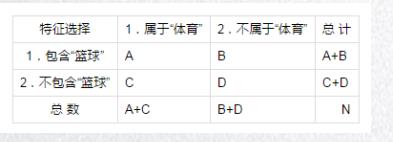
一个卡方检验的例子:我们需要统计顾客化妆和性别之间的关系。
| 男 | 女 | 总数 | |
|---|---|---|---|
| 化妆 | 15 | 95 | 110 |
| 不化妆 | 85 | 5 | 90 |
| 总数 | 100 | 100 |
我们先计算期望值:
| 男 | 女 | 总数 | |
|---|---|---|---|
| 化妆 | 15(期望:55) | 95(期望:55) | 110 |
| 不化妆 | 85(期望:45) | 5(期望:45) | 90 |
| 总数 | 100 | 100 |
计算:
x
2
=
(
95
−
55
)
2
55
+
(
15
−
55
)
2
55
+
(
85
−
45
)
2
45
+
(
5
−
45
)
2
45
=
129.3
x^2 = \\frac{(95-55)^2}{55}+\\frac{(15-55)^2}{55}+\\frac{(85-45)^2}{45}+\\frac{(5-45)^2}{45}=129.3
x2=55(95−55)2+55(15−55)2+45(85−45)2+45(5−45)2=129.3
然后计算自由度: V = ( R O W S − 1 ) ∗ ( C O L S − 1 ) = 1 V=(ROWS-1)*(COLS-1)=1 V=(ROWS−1)∗(COLS−1)=1,然后去查表
卡方统计和计算互信息量是两种特征选择的办法,但无论是卡方校验还是互信息量都是属于贪心方法,没有考虑到被选择的特征和待选特征的之间相关性
- 特征提取:主成分分析
我们需要使用正交变换将一组可能存在相关性的变量转换成一组线性不相关的变量(这组变量叫做主成分)(可能出计算题)
例题:假设有以下二维数据: 行代表了样例,列代表特征,这里有10个样例,每个样例两个特征。可以这样认为,有10篇文档,x是10篇文档中“learn”出现的TF-IDF,y是10篇文档中“study”出现的TF-IDF。
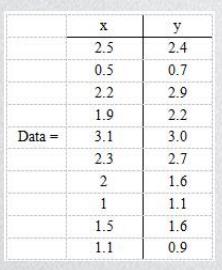
解题步骤:首先分别去求x和y的平均值,然后将所有的样例都进去平均值,得到这样一个表:
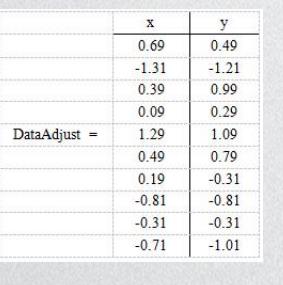
然后,求特征协方差矩阵
然后求协方差的特征值和特征向量,然后将特征值按照从大到小的顺序排序,然后选择其中最大的k个作为列向量组成特征向量矩阵。

然后得到的特征值有两个,选择最大的那个,对应的特征向量是[-.677,-.735]
- 信息增益和信息增益比
信息增益表示的是得知特征X使得Y不确定性减少的程度,信息增益: g ( D , A ) = H ( D ) − H ( D ∣ A ) g(D,A)=H(D)-H(D|A) g(D,A)=H(D)−H(D∣A)
假设𝐴1,𝐴2,𝐴3和𝐴4分别表示例题1中的四个特征,即年龄、有工作、有房和信贷情况。分别计算各特征在数据集𝐷的信息增益即可,即求𝑔(𝐷, 𝐴1),𝑔(𝐷, 𝐴2),𝑔(𝐷, 𝐴3) 和𝑔(𝐷, 𝐴4)。
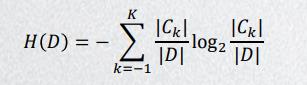
经验熵
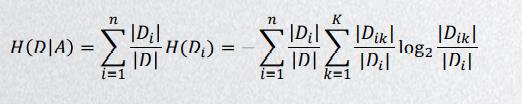
经验条件熵
𝑔(𝐷, 𝐴1)=0.083,𝑔(𝐷, 𝐴2)= 0.3224,𝑔(𝐷, 𝐴3)= 0.420,𝑔(𝐷, 𝐴4)= 0.363。
即,在信贷审批方面,特征信息增益:有房 > 信贷情况 > 有工作 > 年龄
由于信息增益随着训练集的大小而变化,因此,我们需要使用信息增益比来纠正这个问题:
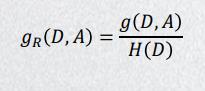
- 决策树的生成
例题1:右边的表是15个数据样本的贷款申请训练集,数据特征包括4个:年龄(老中青)、是否有工作、是否有房、信贷情况(一般、好、非常好)。希望通过所给的训练数据,学习一个贷款申请和审批的决策树,用来对未来的贷款申请(测试数据)进行分类(将其分为“是”和“否”两类)
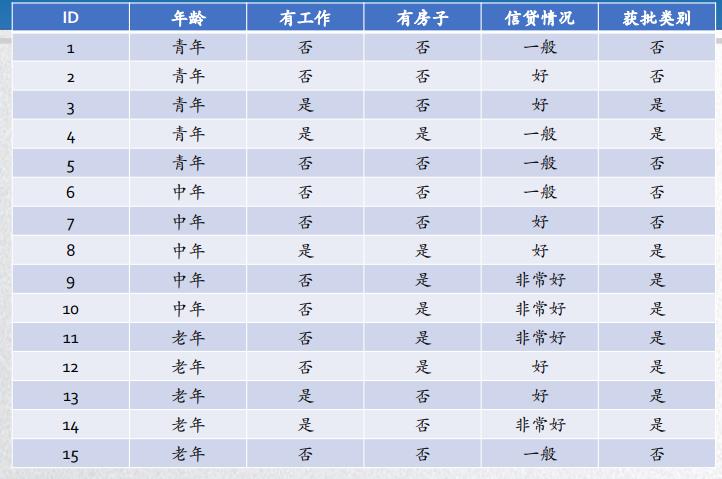
(算法伪代码需要记住!)
def Gen_tree(samples, at_list):
N = Node() # 创建结点N
if samples all in same_Class:
return N # 如果samples都在同一个类C 则返回N作为叶结点,以类C标记,程序结束
if at_list.size == None:
return N #如果attribute_list为空,则返回N作为叶结点,标记为samples中最普通的类
test_at = max_info(at_list) # 选择at_list中具有最高信息增益的属性test_at;
N = test_at # 标记结点N为test_attribute
for vi in test_at.options:
N.branch(condition = 'test_at=vi').grow()
# 对于test_at中的每一个已知值vi,由结点N生长出一个条件为test_at=ai的分枝
si = find_from_samples(samples, test_at = vi)#设si是samples中test_attribute=ai的样本的集合,如果 si为空则加上一个树叶,标记为samples中最普通的类,否则加上一个由Gen_tree(si,at_list)返回的结点
if si == None:
N.branch(condition = 'test_at=vi').end()
else:
Gen_tree(si, at_list.remove(test_at))
-
图的基本要素:点和边,使用邻接矩阵和邻接表来表示图,计算图的中心性和相似性
时空效率:
邻接矩阵的空间复杂度是O(V^2),节点个数的平方
时间复杂度,O(E)E是边数,最优的是O(V+E)空间复杂度
链表查询的时间的复杂度是线性的,哈希表查询的时间复杂度是O(1),红黑树查询时间的复杂度是O(logV)
5. 数据可视化
-
常用的高维数据可视化技术:散点图矩阵,平行坐标,降维投影图,雷达图
-
散点图矩阵:相邻散点图共享一个数据维度,特征提取根据相似性聚类。平行坐标:每个坐标轴表示一个维度,单条折线表示具体数据项。降维投影图能捕捉非线性数据结构。雷达图m条半径表示m维空间,点表示数据想,映射到二维空间的位置由弹簧引力模型决定。
-
散点图矩阵:
【1】直观,保留各个维度的数值信息,交互性可以看到维度之间的关系
【2】可拓展性差,不支持太多的维度节点链接图:
【1】层次数据的拓扑结构,认知层次结构数据
【2】空间利用率低降维投影图:
【1】保持原有数据的维度,结果直观
【2】不能表示复杂结构维度小于10:降维投影图,星型坐标,散点矩阵,平行坐标
维度10-100:降维投影图,平行坐标
大于100:降维投影图
高维数据可视化:解决 :人无法直观想象高维数据分布情况、人不善于同时处理多维度信息
网络数据可视化:解决计算布局耗时,视觉混淆的问题
层次结构数据可视化:直观清晰地表达层次数据地拓扑结构,可视化形式符合用户对于层次结构数据的认知(显示映射)空间利用率高(隐式映射)
时空数据可视化、文本可视化、高拓展可视化技术
6. 数据安全
- 数据加密技术:
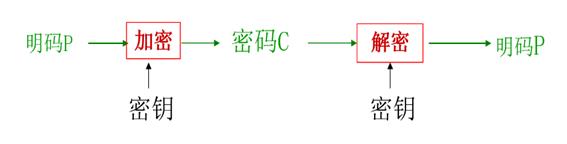
- 对称加密算法:
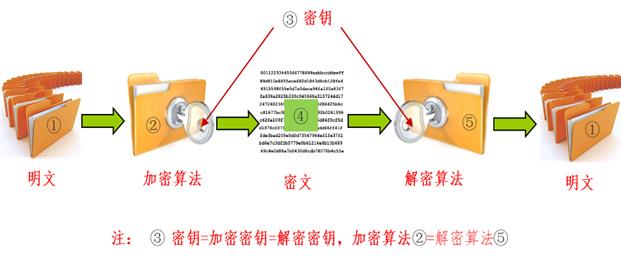
-
非对称加密算法:
非对称加密之所以不对称,指的就是加密用一个密钥,而解密的时候用的是另外一个密钥。
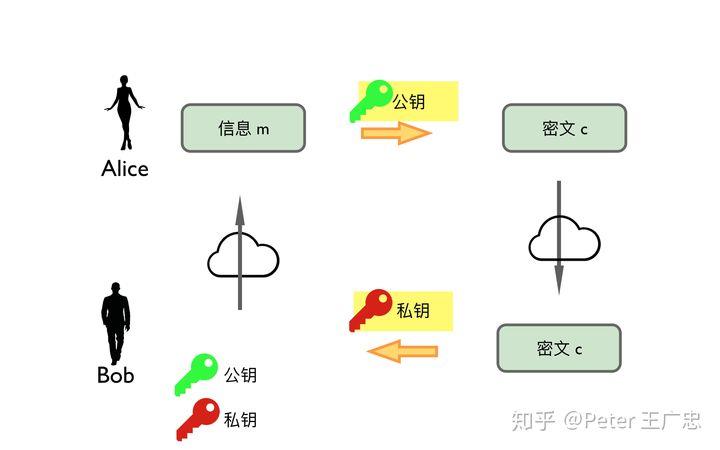
-
做保密和鉴别:
保密的意思就是:公开(公钥)有权加密,无权解密,上帝(私钥)有权解密;鉴别的意思:上帝有权加密,公众有权解密,但是无权加密。
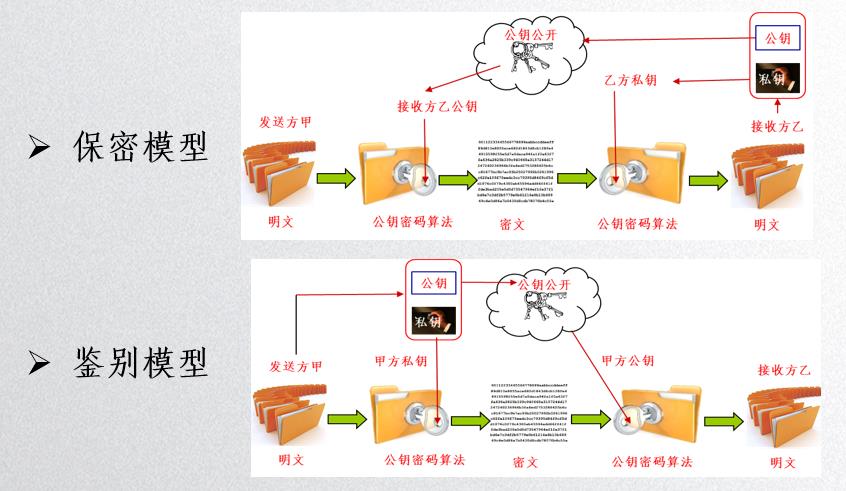
-
数据脱敏:可逆脱敏和不可逆脱敏,还有静态脱敏和动态脱敏。(动态脱敏的客户价值在于对不同身份、不同权限的用户配置实时数据脱敏规则。)
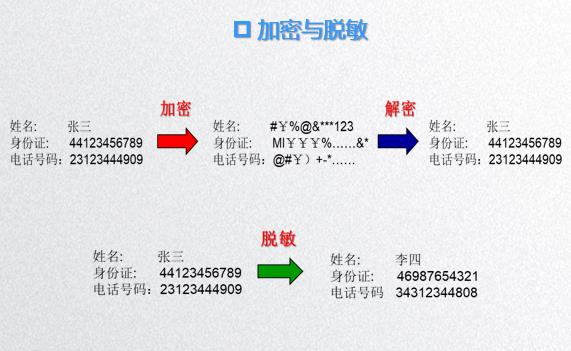
- PKI和PMI:

7. 大数据平台技术
- 常用的大数据处理平台:
- 数据采集系统:Sqoop从传统数据库导入数据,Scrapy并行的爬虫框架,Flume日志采集聚合和传输
- 数据存储系统:HDFS,Swift云存储,Kafka消息系统消息队列
- 计算引擎:MapReduce 批量数据处理,Storm 流式 处理引擎,Giraph并行图处理系统,Spark 通用
- 数据分析工具:Hive和Spark Sql,Spark Steaming流式计算,Graphx图处理
- 其他:Pig是一种编程语言,它简化了Hadoop常见的工作任务,用于描述数据流的语言;Zookeeper 是 Google 的一个开源的实现,是 Hadoop 的分布式机器协调服务组件;Oozie是Hadoop里面的任务调度组件
- Hadoop:做大数据运算的时候,不是把大数据搬到计算程序这里,而是把计算程序分发到各个数据节点上。每个节点只处理本地数据。
- Yarn:将JobTracker的三个功能拆分。
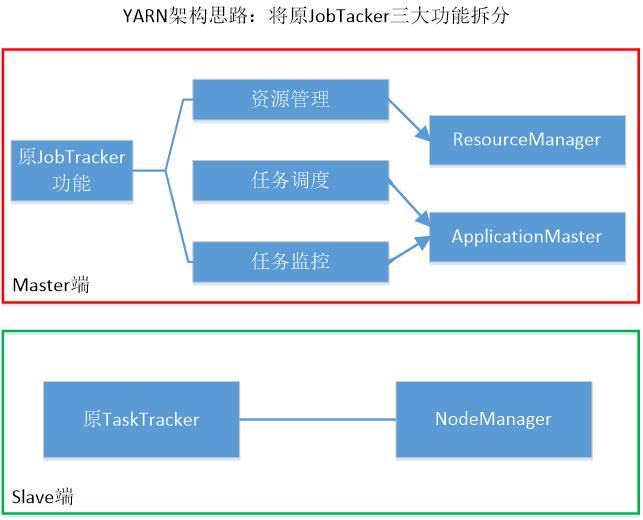
- ResourceManager:处理客户端请求,资源分配和调度,监控NodeManager,启动监控AppMaster
- NodeManager:单个节点上资源管理,处理来自ResourceManager和AppMaster的命令
- AppMaster:为应用程序申请资源,任务调度和容错,分配资源给内部任务
- BSP:(Bulk Synchronous parrallel)
BSP模型块内异步,块间显式同步,由一个Master切条,所有的worker同步执行,模型参数是处理器的数目,处理器的计算速度。
每一个超步包括:
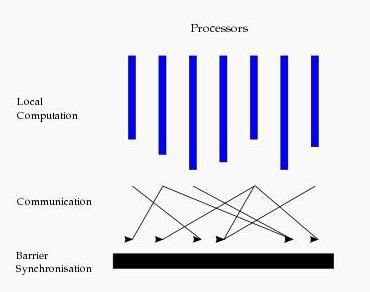
本地局部计算阶段,每个处理器只对存储本地内存中的数据进行本地计算。
全局通信阶段,对任何非本地数据进行操作。
栅栏同步阶段,等待所有通信行为的结束。
所有的超步是一个串行的结构:
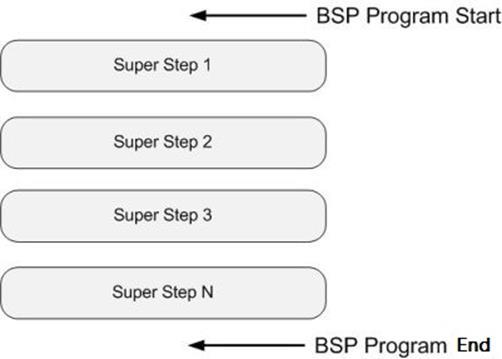
-
流式计算:
统计某个服务被访问客户端地域分布的情况
Hadoop可以完成统计,但是需要很长时间才能完成
流式计算:专门针对数据的时效性进行计算,事件出现后马上处理,实时分析,而不是缓存起来批处理
比如气象测控,金融服务,电商的淘宝双十一销售额统计
【Log - Kafka - 处理,结果放内存 - Redis】 -
PageRank问题的解决:
PreGel : 大规模的图处理系统
用来解决大规模的PageRank问题(使用BSP模型)
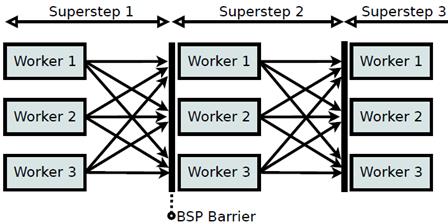
所谓pageRank是一个函数,他为网络中每个网页赋予一个权值,根据这个权值来判断这个网页的重要性
例子:
根据用户之间的关注关系,使用PageRank算法来进行用户影响力的排名
每一个PageRank迭代设计成BSP中的一个超步
每个定点对应一个计算单元(V,Out,Message)
收敛的意思是:所有的PageRank值不再变化或者变化很少的时候,就认为是收敛了
使用MapReduce和PreGel处理PageRank问题的时候不同的是:PreGel将PageRank处理对象看成是连通图,MapReduce是看成KV对,而MapReduce计算批量化处理按照任务进行循环迭代控制
图算法用Mapreduce实现的话从一个阶段到另外一个阶段的时候,需要传递整个图的状态,会产生大量的序列化开销,但是Pregel用超步简化了这个过程。(他不同的地方在于计算单元只管自己的节点状态)
每一个超步,每个定点都会沿着出射边发送他的pageRank值除以出射边的结果值,可以理解为能量辐射影响,然后计算每个顶点的接收到的能量辐射值
每一个超步,对于每一个顶点而言,他既要把自己的能量传递出去,也要接受能量,如果是一个很重要的节点,他必然是:接受到的关注越多远大于他关注别人的数量,这样的人肯定是大v,因此,每一个超步计算之后,他的Pagerank值肯定越大,什么为收敛,就是状态趋于稳定,越是不重要的人,他的关注数量越多,他流失的越多,流入的越少,最后基本变成0
8. 检索模型
- 检索模型:
向量空间模型,所有的信息我们都是可以编码成高维度的向量来表示的,
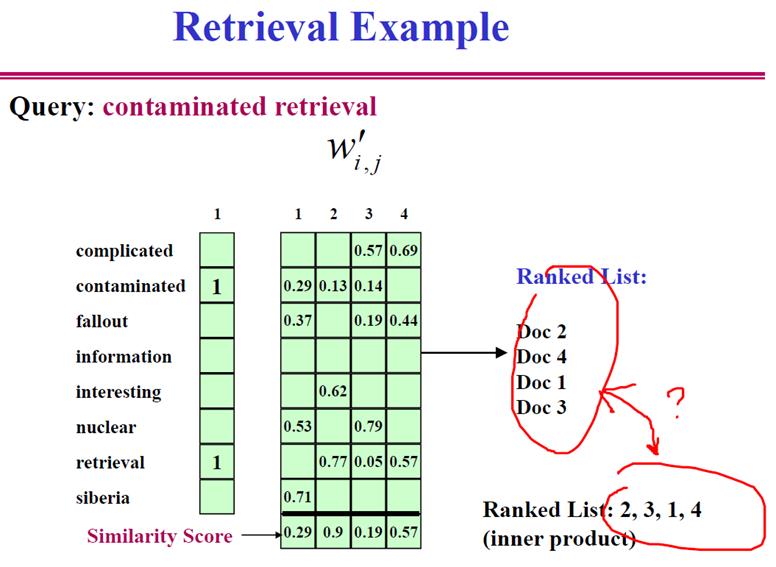
左边是query词语,右边是和四个文档(四个维度)的倒排索引表,矩阵元素表示索引表的权重,使用余弦相似度找出检索的排序结果。
- 如何评价一个IR系统的好坏?
F
1
=
2
∗
P
R
P
+
R
F1 = \\frac{2*PR}{P+R}
F1=P+R2∗PR
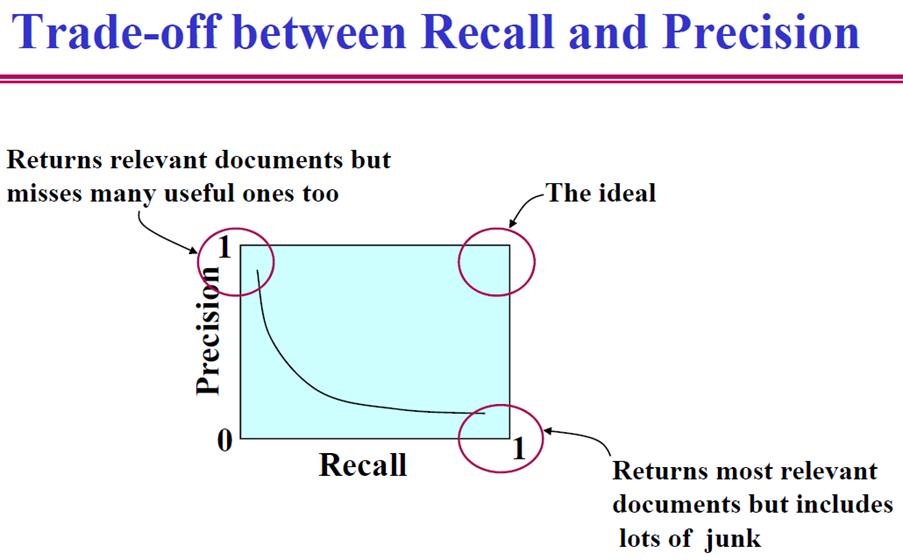
精确率是针对我们预测结果而言的,它表示的是预测为正的样本中有多少是真正的正样本。那么预测为正就有两种可能了,一种就是把正类预测为正类(TP),另一种就是把负类预测为正类(FP)
P = T P T P + F P P=\\frac{TP}{TP+FP} P=TP+FPTP
召回率是针对我们原来的样本而言的,它表示的是样本中的正例有多少被预测正确了。那也有两种可能,一种是把原来的正类预测成正类(TP),另一种就是把原来的正类预测为负类(FN)。
R = T P T P + F N R=\\frac{TP}{TP+FN} R=TP+FNTP
TP: 将正类预测为正类数
FN: 将正类预测为负类数
9. 推荐技术
- 推荐技术分类:
- 基于内容的方法
基于内容推荐的方法特别适用于文本领域,比如新闻的推荐等等。
核心:首先构造商品画像,之后根据此画像来寻找最相似的其他商品。(计算相似度)

-
基于协同过滤的方法
共用其他人的经验,避免了内容分析的不完全或不精确,并且能够基于一些复杂的,难以表述的概念(如信息质量、个人品味)进行过滤。
启发式推荐算法(Memory-based algorithms)
启发式推荐算法易于实现,并且推荐结果的可解释性强。启发式推荐算法又可以分为两类:
基于用户的协同过滤(User-based collaborative filtering):主要考虑的是用户和用户之间的相似度,只要找出相似用户喜欢的物品,并预测目标用户对对应物品的评分,就可以找到评分最高的若干个物品推荐给用户。举个例子,李老师和闫老师拥有相似的电影喜好,当新电影上映后,李老师对其表示喜欢,那么就能将这部电影推荐给闫老师。
基于物品的协同过滤(Item-based collaborative filtering):主要考虑的是物品和物品之间的相似度,只有找到了目标用户对某些物品的评分,那么就可以对相似度高的类似物品进行预测,将评分最高的若干个相似物品推荐给用户。举个例子,如果用户A、B、C给书籍X,Y的评分都是5分,当用户D想要买Y书籍的时候,系统会为他推荐X书籍,因为基于用户A、B、C的评分,系统会认为喜欢Y书籍的人在很大程度上会喜欢X书籍。
基于模型的推荐算法(Model-based algorithms)
基于模型的推荐算法利用矩阵分解,有效的缓解了数据稀疏性的问题。矩阵分解是一种降低维度的方法,对特征进行提取,提高推荐准确度。基于模型的方法包括决策树、基于规则的模型、贝叶斯方法和潜在因素模型。
-
混合推荐方法
加权或者切换各种推荐算法组合使用
基于内容的推荐:能推荐出用户独有的小众偏好,可以一定程度解决数据稀疏问题,可解释性强
但是很难带给用户惊喜性不强,
协同过滤:就好像生活中朋友之间相互推荐自己喜欢的东西一样
userbased CF
先计算出相似用户(Pearson,Jaccard,cosine)
然后找相似用户喜欢的物品,预测目标用户对于这些物品的评分(聚类,KNN等)
过滤掉目标用户已经消费过的物品
将剩下的物品按照预测评分排序,返回前N个物品
item based
计算多个目标用户对于item的评分,选取用户预测评分最高的前N个商品进行推荐
实时计算的复杂性减少了,解决用户冷启动问题(用户冷启动主要解决如何给新用户做个性化推荐的问题)
基于内容推荐的需要大量的领域知识,但是协同过滤需要很少来比喻知识,因此通用性强,但是冷启动问题,数据稀疏问题,热门倾向性,很难推荐出小众爱好。
我的看法:为什么协同过滤很难推荐出小众爱好的问题,因为他在计算的时候使用了聚类算法,这样的算法一旦出现就注定了稀疏数据的灾难性。
例题:
这里的相似度计算:
s
i
m
=
C
交
集
C
全
集
sim = \\frac{C_{交集}}{C_{全集}}
sim=C全集C交集
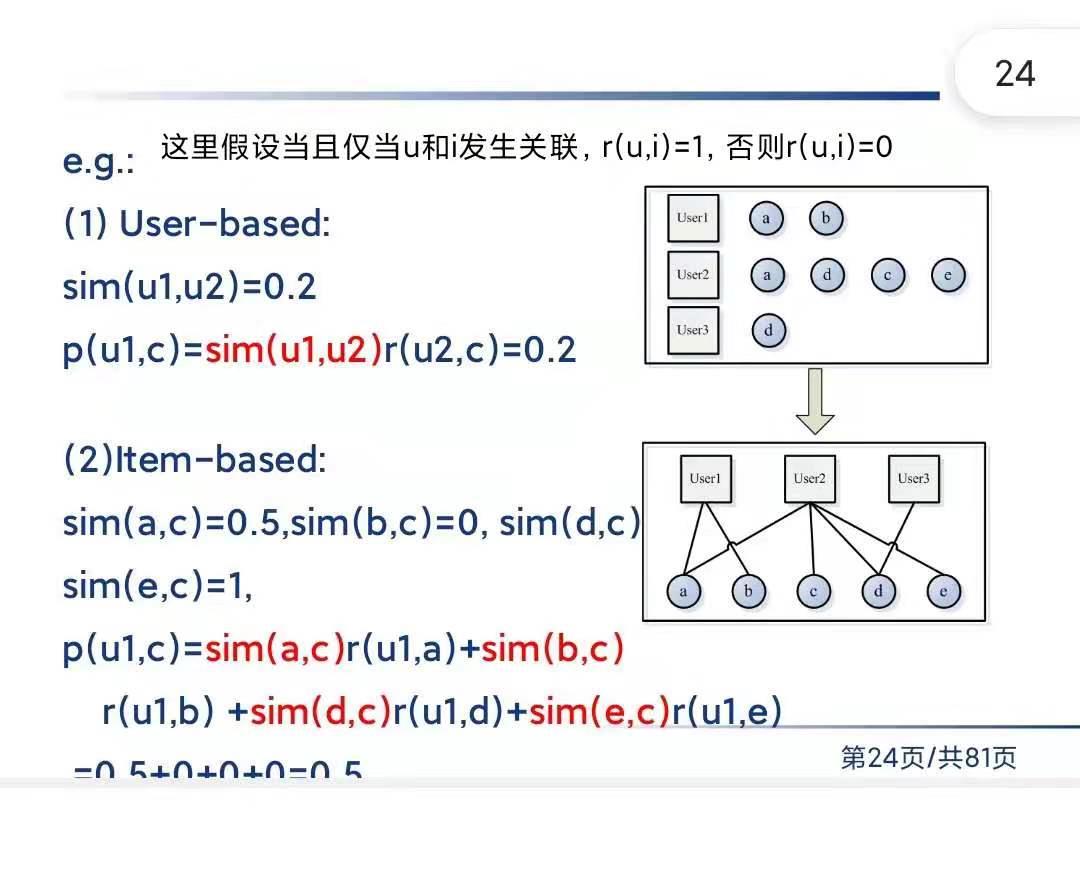
例题:设有如下的用户购买商品的关联二分图:
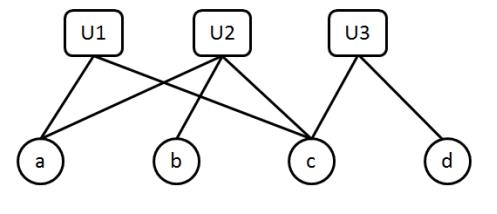
上图表示三个用户U1,U2和U3对4个商品a,b,c和d的购买情况,请计算U1用户对商品b和商品d的喜好度及排序,要求写出解题过程。
假设关联度是:有=1,无=0
Userbased思路解决
U1[a,c],U2[a,b,c],U3[c,d]
先计算
s
i
m
(
U
1
,
U
2
)
=
2
3
sim(U1,U2) = \\frac{2}{3}
sim(U1,