Hadoop 速成大法(理论)
Posted JintuZheng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop 速成大法(理论)相关的知识,希望对你有一定的参考价值。
本文笔记仅自用,杠勿cue
编程题:Hadoop 实验MR编程速记
1. 绪论
-
大数据4V特征:
- Volume(容量大)
- Variety(种类多)
- Value(有价值)
- Velocity(追求速度时效)
-
Hadoop 是分布式系统开发的框架,由三部分组成:HDFS(分布式文件系统),MapReduce(分布式运算框架),Yarn(资源分配系统)。
-
Google的论文和Apache开发的框架关系:
BigTable和HBase,MapReduce和MapReduce,GFS和HDFS。 -
特点:
- Hadoop可以存储和处理PB级别的数据(1PB=1024TB)
- 成本低:服务器的集群节点达到上千个节点
- 可靠性:自动维护多份副本
- 高效率:可以并行调度资源处理
-
大数据产生模式的三个阶段:运营式系统阶段,用户原创内容阶段,感知式系统阶段
-
大数据和科学研究:实验,理论,计算,数据密集型
-
大数据和思维方式:全样非采样,效率非准确,相关非因果
-
大数据计算模式:批处理计算(MapReduce),流计算(Storm,Flink,SPark streaming),图计算(Pregel,SPark GraphX),查询分析计算(Hive,Dremel,Impala)
-
运行模式:本地单机,伪分布式,全分布式
真正的分布式,由3个及以上的实体机或者虚拟机组件的机群。
伪分布式,这种模式也是在一台单机上运行,但用不同的Java进程模仿分布式运行中的各类结点(NameNode,DataNode,JobTracker,TaskTracker,SecondaryNameNode)
从分布式存储的角度来说,集群中的结点由一个NameNode和若干个DataNode组成,另有一个
从分布式应用的角度来说,集群中的结点由一个JobTracker和若干个TaskTracker组成,JobTracker负责任务的调度,TaskTracker负责并行执行任务。TaskTracker必须运行在DataNode上,这样便于数据的本地计算。JobTracker和NameNode则无须在同一台机器上。一个机器上,既当namenode,又当datanode,或者说 既 是jobtracker,又是tasktracker。没有所谓的在多台机器上进行真正的分布式计算,故称为"伪分布式"。
NameNode(1)+DataNode(n)
JobTracker调度(1)+TaskTracker执行(n)
TaskTracker一定要在DataNode上,JobTracker则可以在任意机器上
2. HDFS 分布式文件系统
预备知识:
- 什么是元数据?:元数据就是描述数据的数据
- 什么是快照:我们在很多情况下都需要备份文件,但是往往需要备份的那台机器不能即时停止运行,这个时候我们需要对文件系统进行打快照,我们对文件系统锁所进行的所有操作都是有记录的,因此,快照系统的操作就是把元数据保存下来,我们可以根据这份快照对文件系统恢复到某个时间点(用Git的思维思考一下)。
HDFS的相关知识:
- HDFS系统适合处理超大文件,流式访问数据,不适合低延迟的数据访问,不适合大量小文件的存储,不支持多用户写入和任意修改
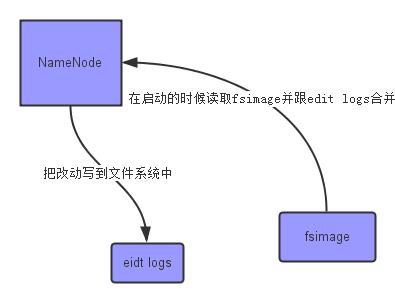
fsimage - 它是在NameNode启动时对整个文件系统的快照
edit logs - 它是在NameNode启动后,对文件系统的改动序列
SecondaryNameNode所完成的工作就是合并fsimage和edit logs
-
一些常用的概念:
- Block:大小默认是256M
- NameNode:管理文件系统的命名空间,维护整个文件系统的目录树和文件的索引目录。有两种信息,一种是命名空间镜像,一种是编辑日志,namenode在每次系统启动的时候动态重建这些信息,当运行任务的时候,客户通过NameNode获取元数据信息,元数据(描述数据的数据)运行保存在NameNode的内存当中。
- 副本策略:副本1存放在上传文件的DN,如果是在集群外提交过来的放在磁盘空闲CPU不忙的节点。副本2放在和副本1 不同Rack(机架)的节点
- 文件操作:NameNode负责文件元数据的操作,DataNode负责处理文件内容的读写请求,数据流不经过NameNode,读取文件的时候NamNode会尽量让用户先读取最近的副本
- SecondaryNamenode不是备份节点,主要工作是阶段性的合并fsimage和edits文件,以此来控制 edits 的文件大小在合理的范围
- HDFS系统启动的时候,NamNode进入安全模式,所谓安全模式就是禁止文件系统修改,NameNode先检查DataNode数据块的副本数量是否达到最小值再考虑退出安全模式。
-
HDFS的读写操作:
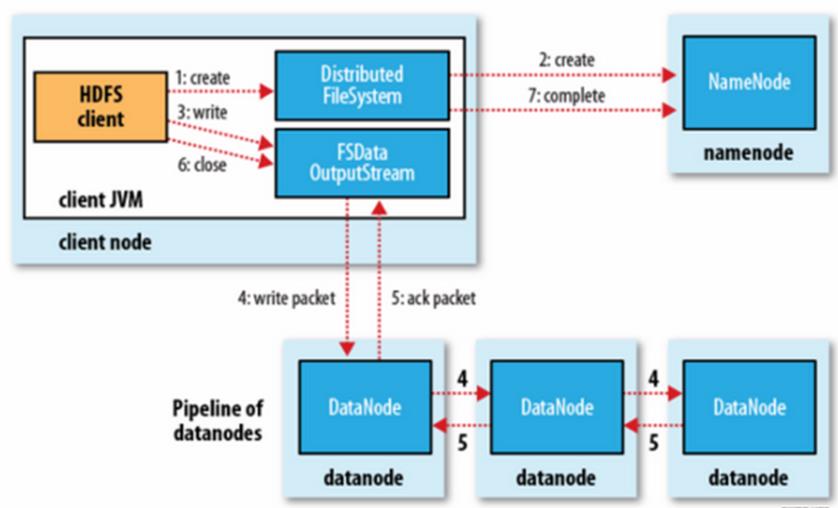
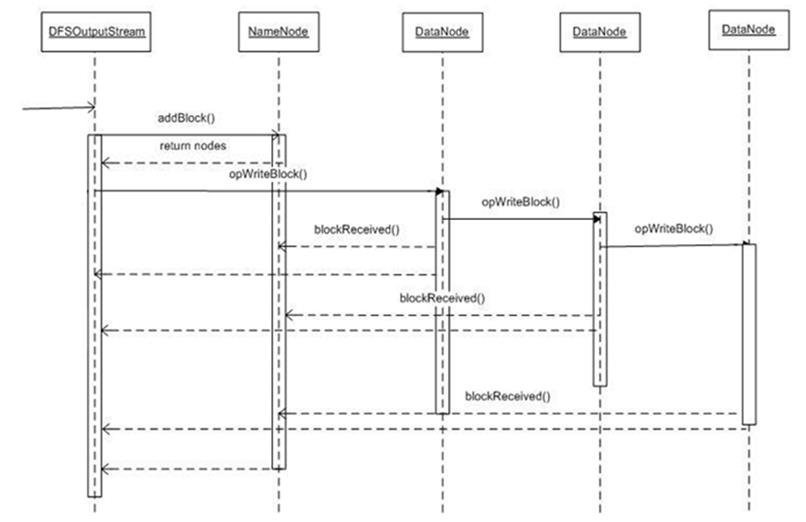
管道式写入(Pipeline),写入遵循这样的步骤:先创建一个任务到NameNode上,然后同时驱使DataOutputStream写入数据,OutputStream(缓冲区)将数据写入某一个DN里面,边写这个DN的时候向其他的DN也写入,并发管道写入,写入的同时不断有ACK报文回复写入的状态,最后关闭缓冲区,OK,完成。如图:
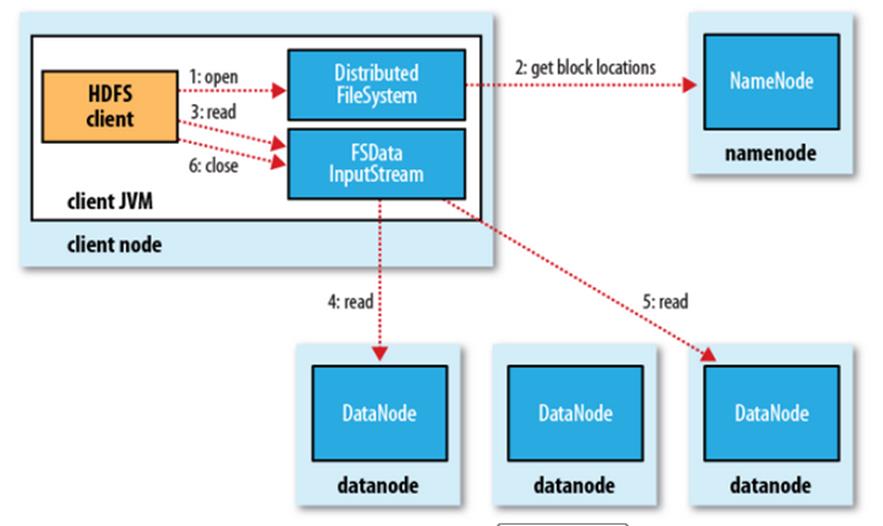
HDFS的读操作:
3. MapReduce 计算框架
MR是一种分布式计算框架,首先传统的并行计算框架是共享内存或者共享存储的,实时的,计算密集型的,但是MR是非共享式的,非实时,适合数据密集型的任务。
开发应用我们遵循这样的:计算-<数据>-写结果。
计算密集型(CPU资源紧张)
比如视频高清解码,严重依赖CPU资源,对代码的运行效率重要。因此用C语言比像Python的脚本语言要好。
IO密集型:(CPU消耗少,对网络和磁盘IO依赖严重的)
大部分的WEB1.0应用都是IO密集型,我们优先使用脚本语言。(WEB1指的是简单的门户)
数据密集型:(需要处理的数据量非常多)
我们面临的数据是海量的,我们的Web2应用(提供即时服务的)
MapReduce采用分而治之的思想,一个非常大的数据集分布地存储在不同的机器上,这样的数据集被切分成多个独立的分片(逻辑上的),这些分片被多个Map任务并行处理,我们遵循计算向数据靠拢,因此节省了移动数据的开销。
在Hadoop中所有的MR程序按照Job的形式提交给集群运行。
MR的核心思想:
Split → \\rightarrow →RecordReader → \\rightarrow →Map → \\rightarrow →Partitioner → \\rightarrow →Sort → \\rightarrow →Reduce
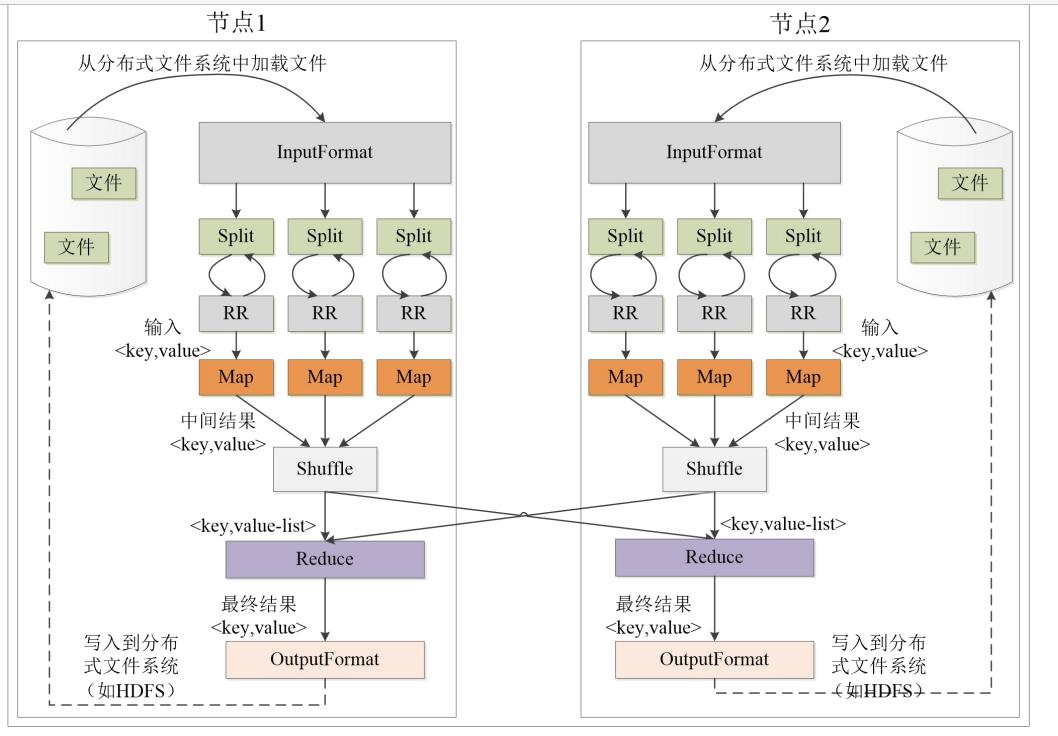
Map任务:
我们对每一个分片进行进一步的切分,变成多个的<K1,V1>,一般来说,一个<K1,V1>就是一行数据,一个<K1,V1>会被映射成一个或多个<K2,V2>
合并:
我们会将同样的K2进行整合,在逻辑上变成了:<K2,List[V2]>
Reduce任务:
输入是:<K2,List[V2]>,根据每个K2,映射成<K3,V3>
每个(k1、v1)键值对调用一次 map 函数,一个 Reduce 任务处理一个分区数据
不同的Map任务不会通信,不同的Reduce不会发生任何信息交换,记住:用户是不允许干预MR框架的信息交换过程的
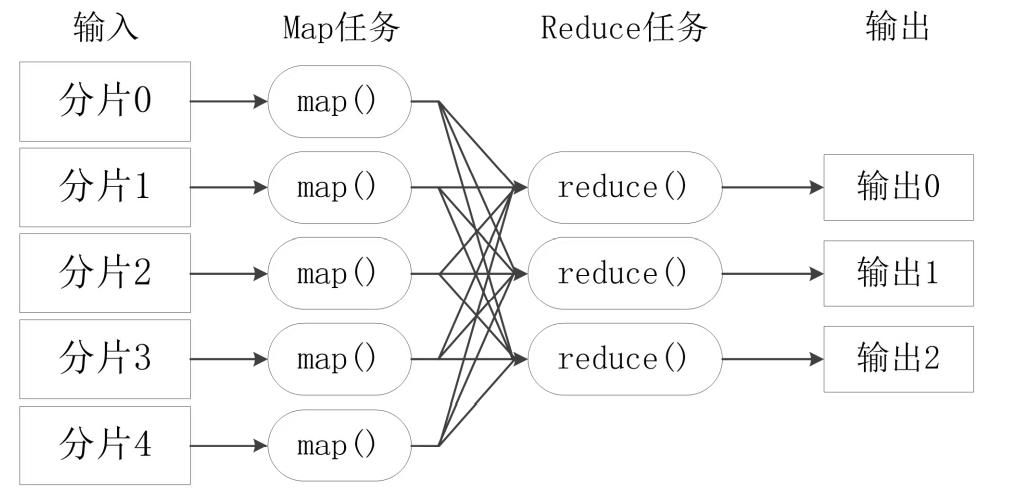
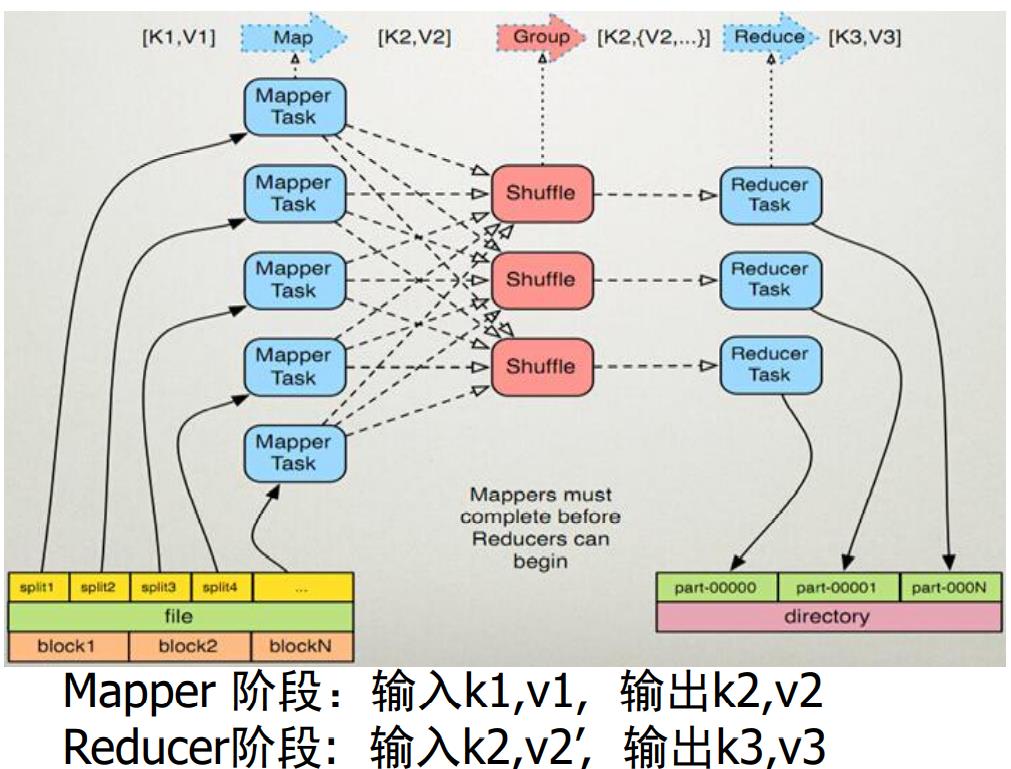
Map任务的阶段:
【1】读取该分片的数据,解析成KV对,一般来说针对每一行解析成一个K1V1,然后对K1V1的V1进程处理,然后映射成多个或者一个K2V2
【2】对输出的K2V2进行分区,一个分区将形成:K2,{V2,V2,V2},默认是一个分区
【3】此时可进行合并Combiner(可选)
【4】将Map的结果写入本地磁盘
Reduce任务的阶段:
【1】根据多个map任务的输出,按照不同的分区复制到不同的Reduce节点,一个Map可以产生多个分区的结果,但是一个Reduce只能处理一个分区的任务。(这样的重新分配过程称为shuffle,中文意思是洗牌)
【2】对map任务K2的V2s们进行合并Combiner操作
【3】将Reduce的结果写入本地磁盘
分片splits是一个逻辑概念,我们真实存储数据是分桶Blocks,最理想的情况是一个Block对应一个Map一个分片。
例子:一个文件800MB,集群的Block大小是256MB,Split分片的大小是150MB,启动的Map数量是800MB / 150MB = 7splits。我们分片的时候直接无视Blocks
我们都知道Reduce任务的数量是根据我们的Map分区数量得到的,因此最优的Reduce任务个数取决于集群中可用的reduce任务槽slots。我们通常设置比reduce任务槽署目稍微小一些的reduce任务个数,目的是预留系统资源处理可能发生的错误。
Shuffle 洗牌
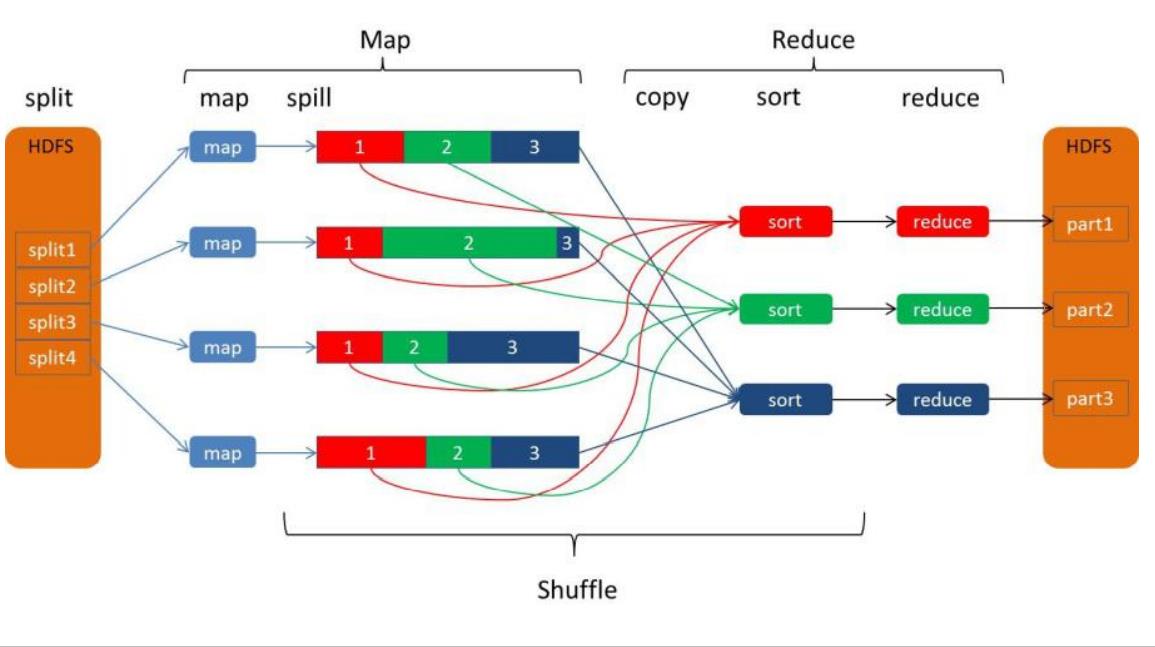
需要注意的是分区是针对全局分区而言的。
Shuffle 是从map到reduce之间的过程,也是hadoop最核心的部分,原理:
先看基本概念:
Combiner是对相同key的多个values进行某种操作得到一个新的value的操作,Merge是对相同Key的多个values进行cat操作
- 合并:Combine:例如:
<"a",1>,<"a",1>=<"a",2> - 归并:Merge:例如:
<"a",1>,<"a",1>=<"a",[1,1]> - 排序:会根据指定Key的compare方法进行排序
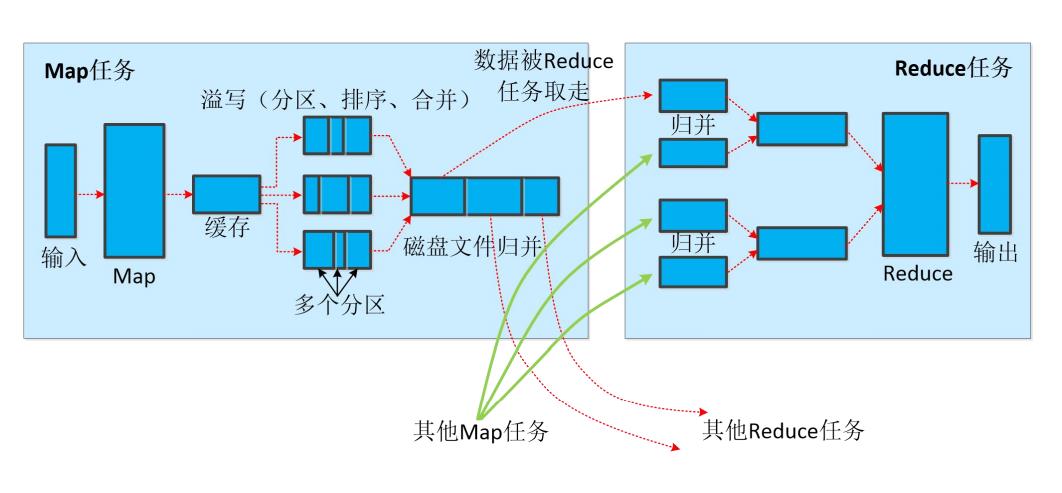
我们来这个图的一些细节:
首先一个Map任务有一个缓存,这个缓存区域在内存里面,默认是100MB,默认的溢写Spill比例是0.8,也就是说当我们的数据占了缓存的80%的时候就需要进行溢写(排序 → \\rightarrow →合并Combiner → \\rightarrow →归并Merge)到指定分区,写入对应的分区磁盘文件。
对于Reduce任务而言,一个分区一个Reduce任务,针对来自不同的map任务的数据再做一次归并Merge。需要注意的是:Reduce是主动拉取Map处理之后的数据。我们的JobTracker角色会监视map任务的执行,并且通知Reduce任务来领取。
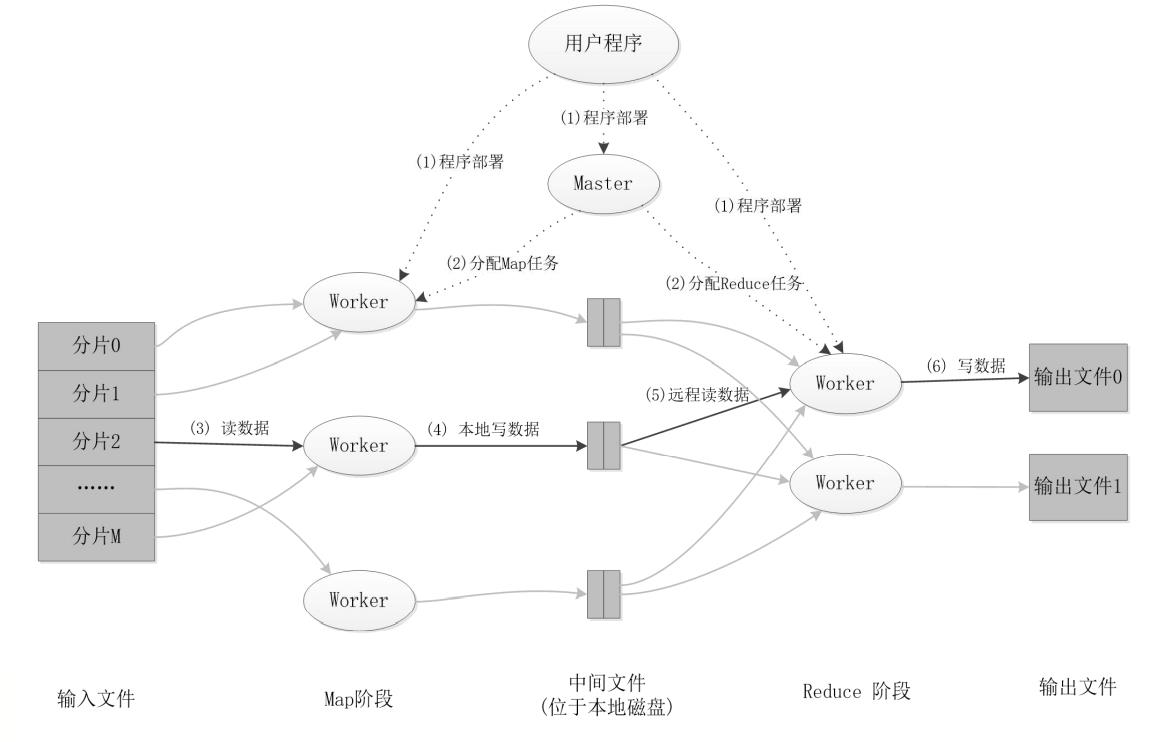
任务调度的原理:
在MR1.0的时候,我们的JobTracker完成的任务如下:
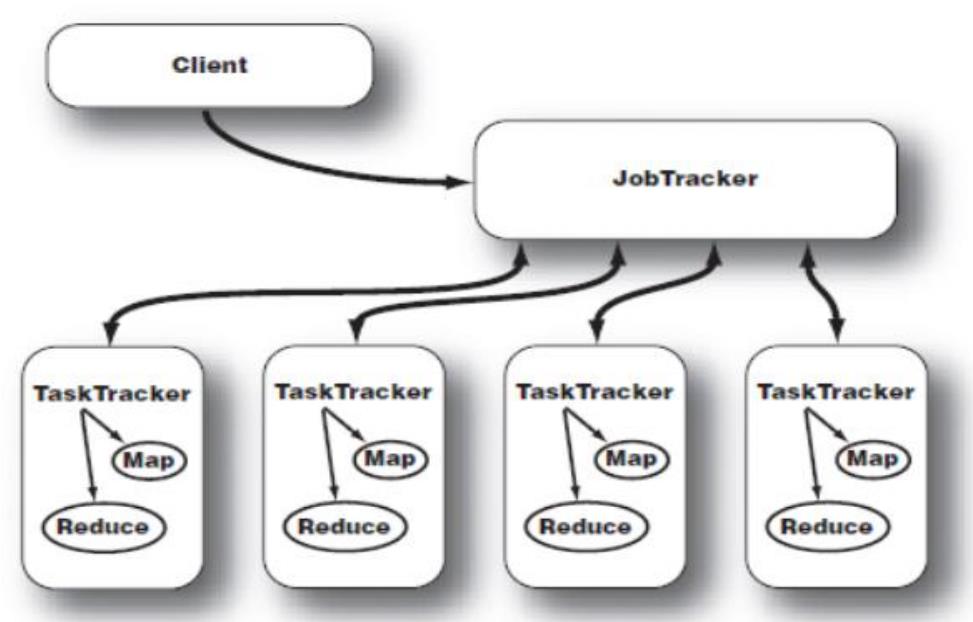
到MR2.0的时候,我们有了更加系统化的任务调度系统YARN。Yarn分为NodeManager,ResourceManager。(其中,最大的改进是把Applicationmanager应用管理和ResurceScheduler资源调度分开了)。RM相当于MR1.0里面的JobTracker,Nodemanager相当于MR1.0里面的TaskTracker负责管理节点的运行,当接收到任务的时候启动Container(容器)完成(Map或者Reduce任务)
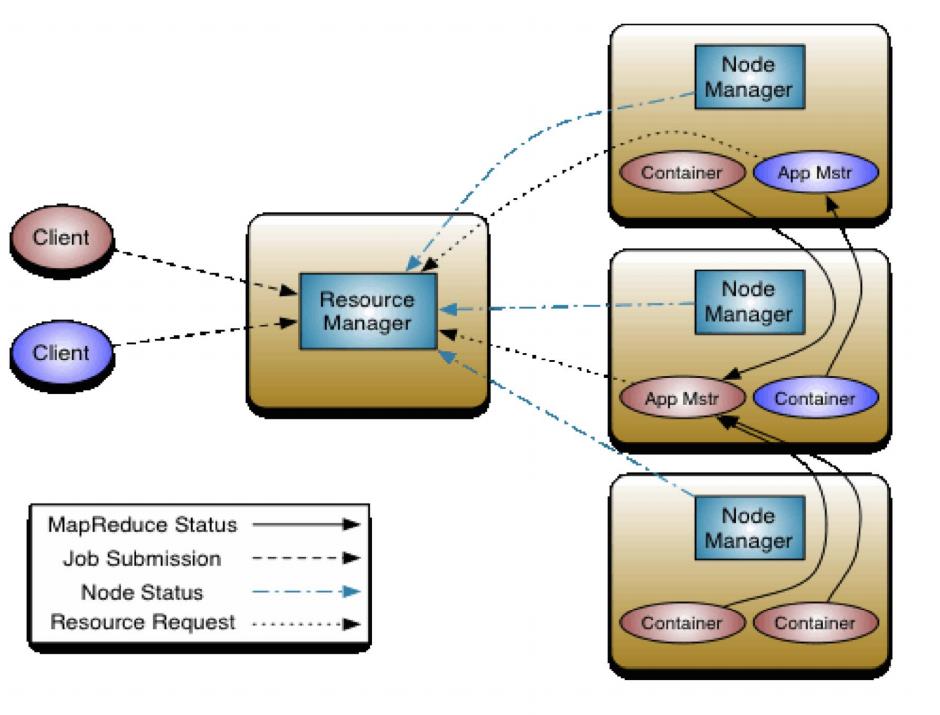
4. Yarn 资源任务分配系统
容器:Container 资源容器,集群节点将自身内存CPU磁盘等资源封装在一起的抽象概念
Yarn组件:
- ResourceManager:处理Client的请求,启动和监控AppMaster(简称AM),监控NM,资源分配和调度
- NodeManager:单个节点上的资源调度,处理来自RM上的命令,处理来自AM的命令
- ApplicationMaster:动态生成,任务完成之后注销,数据切分,为应用程序申请资源分配给内部任务,负责任务监控和容错
Yarn的作用流程
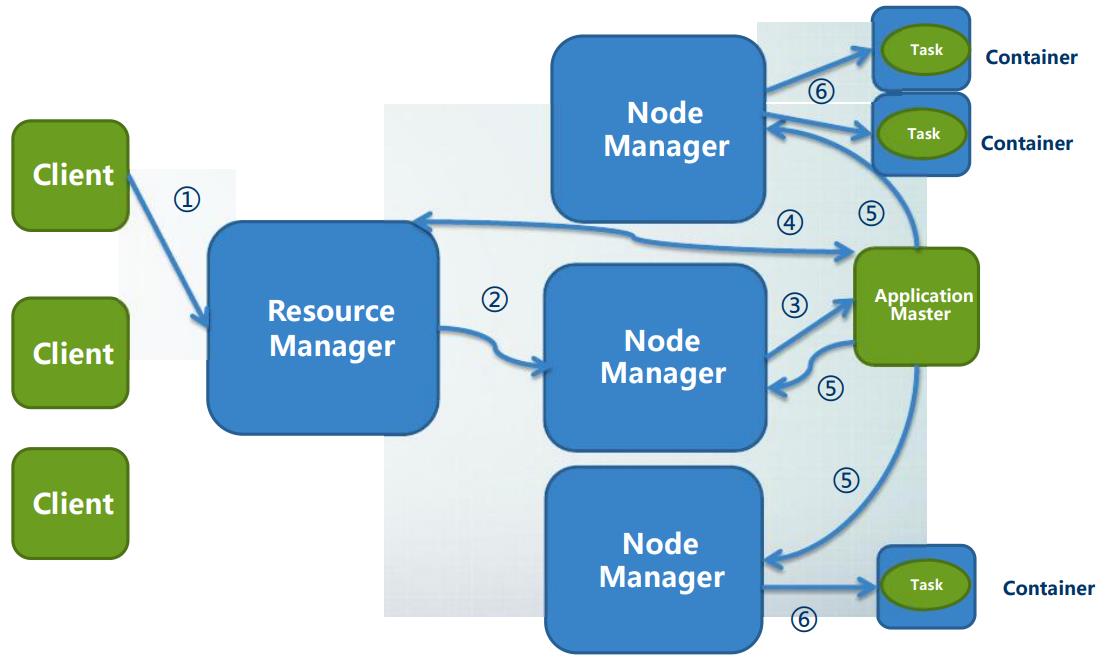
【1】Client 向RM提交APP(Job)
【2】RM为APP分配第一个Container,并与这个节点的NM进行通信,要求这个Contatiner启动Appmaster,然后开始执行自己的任务
【3】之后AppMaster保持和RM之间的监控报告
【4】然后AppMaster采用轮询的方式向RM申请和领取资源
【5】一旦AppMaster领取到了资源就会和对应的NM通信,要求他启动任务
【6】NM负责为任务设置好运行环境包括环境变量JAR包,等二进制程序,然后启动任务
【7】每一个任务通过轮询的方式向AppMaster汇报自己的运行状态,如果发生任务失败AppMaster可以重新启动任务
【8】APP(Job)完成之后,AppMaster向RM注销并且关闭自己
具体记忆下面的:
- 客户端向ResourceManager(简称RM)提交任务;
- RM选择一台节点,安排其启动该任务的AppMaster(以下简称AM);
- 被选择的节点,启动AM;
- AM向RM申请执行该任务需要的资源(节点,CPU,内存等),RM分配节点给AM;AM与RM保持通信;
- AM要求RM分配的节点上执行任务;
- 节点按照要求启动容器,执行MAP或者REDUCE操作;节点定期向AM汇报进展情况;
- 最后,节点执行任务完毕后,释放所占用的容器资源;AM在任务结束后关闭;
JOB的执行流程:
- 提交作业
- 初始化作业
- 分配任务
- 执行任务
- 更新任务执行进度和状态
如果某个节点的任务执行过慢,会启动备份任务(替代它)
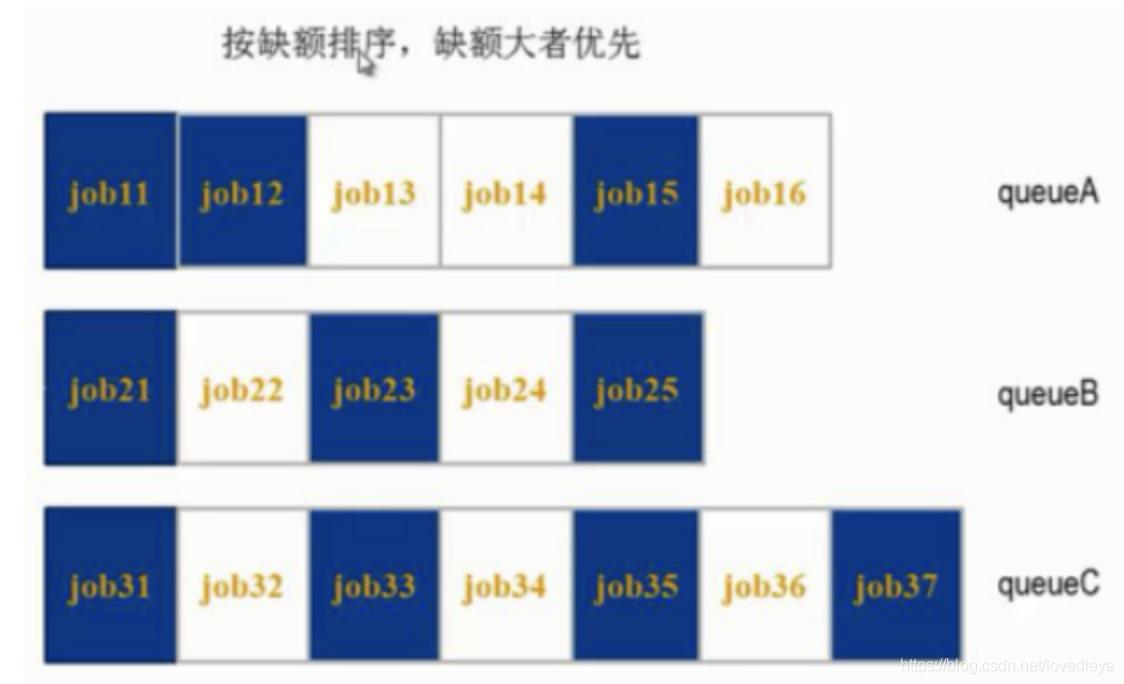
作业调度机制
- FIFO,先来先服务
- Fair Scheduler,公平调度器
- Capacity Scheduler,容量调度器
FIFO只有一个队列
容量调度器支持多个队列,每个队列可配置一定的资源量,每个队列采用FIFO调度策略
公平调度器:同队列的作业公平共享队列所有的资源

5. HBase
HBase 是分布式,面向列的数据库,可伸缩,实时读写,可靠,高性能,
介于NoSQL和RDBMS之间,仅能通过主键RowKey和主键的range来检索数据,仅支持单行事务
Hbase的表:
【1】大:上亿,上百万列
【2】面向列:面向列族的存储和权限控制,列族的独立检索
【3】稀疏:null的列不占用存储空间
HBase的概念:
【1】RowKey:主键行键
【2】Column family:列族,列中的数据按照二进制存储,没有数据类型
【3】Timestamp:时间戳,64bit,版本信息
【4】Cell:[rowkey] [column+qualifer] [version] 决定一个唯一数据
Hbase的管理架构:
数据存放按照Region来存,每个Region按照startKey和endKey来决定,Region里面的一个列族存成一个Store
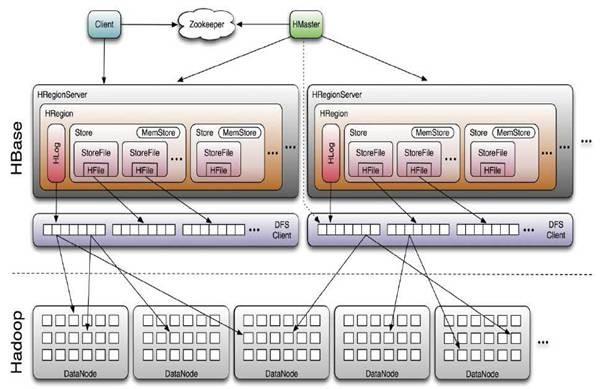
HMaster:负责Table的Schema(增删改),HRegion的拆分和迁移
HRegionServer:管理一系列的HRegion。每一个HRegion对应Table的一个Region。HRegion由多个HStore组成,每一个HStore对应Table的一个Column Family的存储,Client可以通过HMaster快速定位RowKey在哪个HRegion里面
HStore:是HBase的存储核心,由MemSore和StoreFiles组成,当StoreFiles的数量达到一定阈值的时候,就会触发紧缩操作(Compaction)
Hbase 物理上只会增加数据,所有的更新和删除操作都是在Compaction进行的
数据紧缩(Compaction):
Minor Compaction 小紧缩,对一些小的,相邻的StoreFiel将他们合并成更大的StoreFile。这个过程不会处理已经Deleted和Expired的Cell。
Major Compaction 大紧缩,将所有的StoreFile合并一个StoreFile,这个过程里面Deleted的Cell就会被删除,Expired的Cell就会被丢弃,超过版本数量的Cell也会被丢弃,一个Major Compaction操作下来,每个HStore就只剩下一个StoreFile了,Major Compaction 会引起非常多的IO操作因此会触发性能问题,因此他发生在集群比较空闲的时间。
HBase和RDBMS的对比:
- 数据只有字符串
- 数据操作简单,没有复杂的关联和连接操作
- 存储模式是列存储
- 数据维护是用插入替代修改和删除操作
- 可伸缩行性可以轻松增加和减少硬件数量
- HBase适合大量插入和大量读的情况
- Hbase的瓶颈是传输速度,Oracle的平均是磁盘寻道时间
- Hbase适合寻找按照时间排序的 top n的场景
- Oracle可以做OLTP(联机事务处理,比如银行交易)又可以做OLAP(联机数据分析,数据仓库,复杂的分析,提供直观的查询结果)
HBase的局限:
- 只能做简单的KV查询,不能做复杂的SQL统计
- 只能在row Key上做快速查询(索引)
HBase的读写:
- 写:先向RegionServer提交请求找到对应的region,获取系统的时间戳,更新Wallog,将更新写入Memstore,然后判断MemStore是否需要flush为Store
- 读:依次扫描BlockCache,MemStore,StoreFile,然后将结果合并
HBase的模式设计:
- 尽量使用一个列族,列族的数据多少称为”势“
- 行键的设计:加盐(分配随机数),哈希,反转(比如手机号,前面是有规律的,后面的随机的。我们反转过来,没有意义的放前面,有意义的放后面)
- 尽量最小化行键和列的大小,列族名最好一个字符
- 版本数量合适
HBase Shell操作:
create,put,get,scan,delete,drop,disable
- create ‘表名’, ‘列族名’ #创建一个新表
- alter ‘表名’, {NAME=> ‘列族名’, METHOD=> ‘delete’} #删除一个列族
- alter ‘表名’, NAME => ‘列族名’, VERSIONS => 5 # 修改某个列族的版本数量
- describe ‘表名’ # 获取一个表的描述
- put ‘表名’, ‘行键’, ‘列’, ‘数据’
- get ‘表名’, ‘行键’, {COLUMN => ‘列名’, VERSIONS => 3}
- scan ‘表名’, ROWPREFIXFILTER => ‘行键’
- delete ‘表名’, ‘行键’, ‘列名’
- disable ‘表名’
- drop ‘表名’
- a=get_table ‘表名’
- a.scan
- a.get ‘行键’
6. ZooKeeper 协调分布式应用的服务
ZooKeeper提供通用的分布式锁服务,用以协调分布式应用
- Hadoop,使用Zookeeper的事件处理确保整个集群只有一个**(active)NameNode**,存储配置信息等。实现NameNode自动切换;
- HBase,使用Zookeeper的事件处理确保整个集群只有一个**(active)HMaster**,察觉HRegionServer联机和宕机,存储访问控制列表等。
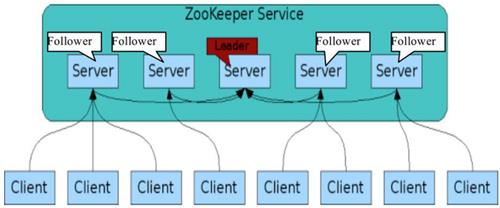
通信端口:2181
主要功能:统一命名服务、配置管理、集群管理、共享锁、队列管理;
ZK 服务器的数量,奇数(3、5、7 等);
最大允许当机的个数,一半以下,即一半以上可以工作时,ZK 集群才算正常。
zkServer.sh start/stop //启动/停止
zkServer.sh status //查看状态
High Availability 高可用性:
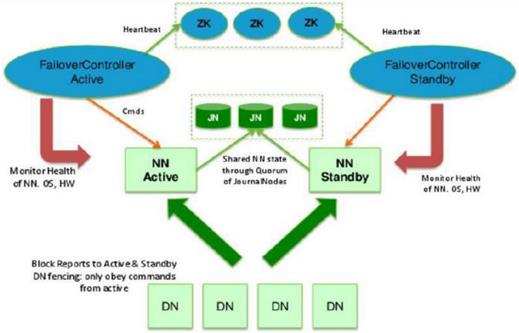
HA 集群的规划和启动进程:

7. Hive
Hive是一种数据仓库技术,用于查询和管理存储在分布式环境下的大数据集
数据仓库是一个过程而不是一个项目;数据仓库是一个环境,而不是一件产品。
数据仓库提供用户用于决策支持的当前和历史数据,这些数据在传统的操作型数据库中很难或不能得到。
构建于Hadoop的HDFS和MapReduce上,用于管理和查询分析结构化/非结构化数据的数据仓库;
使用 HQL(类 SQL 语句)作为查询接口;
使用 HDFS 作为底层存储;
使用 MapReduce 作为执行层,即将HQL语句转译成M/R Job后在Hadoop执行;
HIVE 的元数据存储(MetaStore): 可以是内置的dearby数据库;也可以是通用关系型数据库(如mysql)
内部表与外部表:
- 相同点:需要指定元数据,都支持分区;
- 不同点:实际数据的存储方式不同;
- 内部表。实际数据存储在数据仓库目录(默认/user/hive/warehouse下)。删除表时,表中的数据和元数据将会被同时删除。
- 外部表。需要 external 关键字;实际数据存储在创建语句 location 指定的 HDFS 路径中,不会移动到数据库目录中。如果删除一个外部表,仅会删除元数据,表中的数据不会被删除。
Hive的分区,分桶:
分区:是指按照数据表的某列或某些列分为多个区,区从形式上可以理解为文件夹,比如我们要收集某个大型网站的日志数据,一个网站每天的日志数据存在同一张表上,由于每天会生成大量的日志,导致数据表的内容巨大,在查询时进行全表扫描耗费的资源非常多。那其实这个情况下,我们可以按照日期对数据表进行分区,不同日期的数据存放在不同的分区,在查询时只要指定分区字段的值就可以直接从该分区查找。
Hive表中的一个分区对应表下的一个目录,所有分区的数据都存储在对应的子目录中。
例如:htable 包含ds、city两个分区,则相同日期、不同城市的hdfs目录分别为:
/datawarehouse/htable/ds=20100301/city=GZ
/datawarehouse/htable/ds=20100301/city=BJ
分桶:相对分区进行更细粒度的划分。桶对指定列进行哈希(hash)计算时,根据哈希值切分数据,每个桶对应一个文件
数据上传命令:
LOAD DATA LOCAL INPATH '/path/to/local/files'
OVERWRITE INTO TABLE test
PARTITION (country='CHINA')
有LOCAL表示从本地文件系统加载(文件会被拷贝到HDFS中)
无LOCAL表示从HDFS中加载数据(注意:文件直接被移动!!!而不是拷贝!!! 并且。。文件名都不带改的。。)
OVERWRITE 表示是否覆盖表中数据(或指定分区的数据)(没有OVERWRITE 会直接APPEND,而不会滤重!)
8. 其他Hadoop 生态系统
Lambda 架构整合离线计算和实时计算,融合不可变性(Immutability),读写分离和复杂性隔离等一系列架构原则,可集成 Hadoop,Kafka,Storm,Spark,HBase 等各类大数据组件。
Lambda 三层架构:批处理层、实时处理层、服务层
- 数据采集工具:Flume、Kafka
- 工作流:OOzie;
- 数据分析工具:Pig(基于数据流)
- RDBMS 与 Hadoop 数据迁移工具:Sqoop
- 数据挖掘分析工具:Mahout
- Spark:基于内存的大型的、低延迟的数据分析应用程序;
以上是关于Hadoop 速成大法(理论)的主要内容,如果未能解决你的问题,请参考以下文章