HDFS 2.x 升级到 3.x 在车好多的实践
Posted 过往记忆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDFS 2.x 升级到 3.x 在车好多的实践相关的知识,希望对你有一定的参考价值。
背景
HDFS 集群作为大数据最核心的组件,在公司承载了DW、AI、Growth 等重要业务数据的存储重任。随着业务的高速发展,数据的成倍增加,HDFS 集群出现了爆炸式的增长,使用率一直处于很高的水位。同时 HDFS文件数持续增长导致Namenode 压力过大、RPC 过多,整体性能下降。作为集群 admin ,保证集群稳定、提高资源利用率为公司降本增效是我们最主要的责任。面对存储增长带来的挑战,我们做了一些工作:
1、HDFS 账单。
通过统计用户使用的HDFS 资源,形成用户账单。根据账单来push 用户清理自己的数据,下沉HDFS治理压力。
2、HDFS小文件合并工具
为用户提供解决 HDFS 小文件的工具,push 用户对owner 的目录进行合并,下沉HDFS治理压力。
3、数据冷热分析。
根据FSImage分析HDFS目录中数据的冷热程度,为用户提供清理数据的参考依据。
4、建设HDFS 冷集群
前面几个措施虽然缓解了一部分压力,但是有些数据,虽然是冷数据但是需要长周期保存不能删除,该如何降低这部分数据的存储成本?我们想到了 HDFS 3.x 的EC 特性。相比传统的3 副本,在相同的容错能力下,数据存储代价由300% 降低到150% (RS-6-3),可以显著降低HDFS 冷数据的存储成本,达到降本增效的目标。我们内部使用的版本是 HDP-2.6.5 对应 Apache 2.7.3 版本,无法支持这些新特性。我们为此基于HDFS 3.1 EC 建设了HDFS 冷集群, 数据节点采用了存储增强机型,用来存储归档的冷数据。
随着使用的频繁,冷、热集群分离的方案,确实节约了很大一部分存储资源,也暴露出了很多问题,最为明显的有以下几个:
1、冷数据读取代价大
由于冷数据和 热数据分布在两套HDFS 集群,为了避免用户读取两套集群数据增加的使用难度,我们选用了冷数据转热的方案。即,当用户提出要读取冷数据,需要将要读取的数据通过distcp 恢复到热集群。这种方案受限于数据大小、网络宽带(跨机房部署),所以读取冷数据响应时间不能保证。往往用户提出需求后需要admin在配合上需要投入很多精力。
2、计算资源浪费
尽管都是使用了大存储机型,存储利用率提升了,但是冷集群几乎没有计算任务,导致计算资源、网络资源长期利用率低,造成不少的浪费。
基于以上思考,升级HDFS 到3.x 后主要有3个方面的收益:
使用 EC 既可以集群内部转换成EC,又能把计算资源利用起来,能较好的解决我们当前 冷数据 的痛点
使用 HDFS RBF 可以有效缓解文件数增长的压力
集成 Namenode一致性读 后可以较好的解决 Presto 大规模查询 HDFS 造成 RPC 延时的问题,为Namenode 减负
另外 HDFS 3.x 还有 Storage Policy、DataNode Disk Balance等重要特性可以发挥很大的价值,为此我们开始了HDFS的升级调研。
升级目标
此次升级目标主要有四点:
1、解决 冷数据压力 和 小文件压力,降本增效
2、升级需要采用热升级,不影响业务的正常运行
3、有完备的降级方案,升级有异常时可迅速降级(回退)
4、保证HDFS升级后和现有组件兼容,不影响其他组件的正常服务
升级方案
升级组件
HDFS or 升级HDFS + YARN
首先,从需求出发,目前对HDFS升级需求很强烈,升级后有很大收益;对YARN的升级需求很小,当前版本基本满足目前需求。再从升级复杂度考虑,如果在只升级HDFS的情况下,需要考虑HDFS 新旧兼容性及HDFS Server 和 HDFS Client 的兼容性, 上层计算组件通过HDFS Client 和 HDFS 交互,理论上在解决HDFS Client 和 Server 端的兼容性后上层组件都具备兼容能力;如果升级HDFS + YARN ,还需要考虑YARN 和 运行在YARN 上面的众多计算框架的兼容性,当前 Hive,Tez,Spark 等组件版本较低,需要投入很多时间精力去保证组件间兼容,升级的困难程度将大大增加。综合考虑 收益 和 投入,决定YARN 放到在将来成熟的时机升级,这次只升级HDFS来解决当前痛点。
升级方式
官方推荐的升级方式有两种:Express 和 Rolling,Express 升级过程是停止现有服务,然后使用新版本启动服务,会影响业务正常运行;Rolling 升级过程是滚动升级,不停服务,对用户无感知。业务不能接受停服,我们优先选择 RollingUpgrade方案。
对应 RollingUpgrade 中, 有两种回退方式:Rollback 和 RollingDowngrade , Rollback 会把软件版本连同数据状态回退到升级前的那一刻 ,会造成数据丢失;RollingDowngrade 只回退软件版本,数据不受影响。在不容忍数据丢失的前提下,我们优先选择 RollingDowngrade 的回退方案。
最后确定的升级&回退方案如下图:
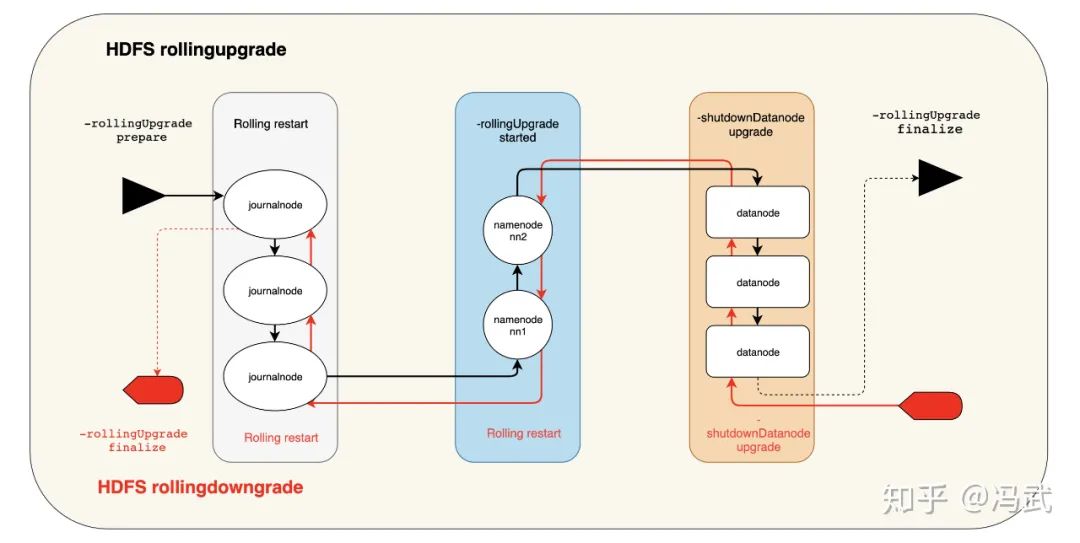
详情参见:Hadoop 官方文档[1]
遇到的问题
版本选择
目前HDFS 最新版本为3.3.x ,但是3.3.x 刚出不具备在生产环境部署的条件。初步调研发现,HDFS 版本小于 3.1.3 和 3.2.1 时,在Namenode滚动升级和滚动降级时存在因为EC导致的兼容性问题(详见HDFS-14396[2],HDFS-13596[3]),所以小于3.1.3 和 3.2.1 的不予考虑。综合考虑需求后,在3.2.1 和 3.1.3 中选用了更稳定的3.1.3 版本。
版本兼容性
我们当前Hadoop版本为HDP-2.6.5,和3.1.3版本之间存在较大的差距,升级存在较多风险。我们在兼容性方面进行了深入研究,主要有以下几个方面需要考虑:
1. 新旧版本Namenode的元数据要兼容,保证服务升级失败后可以降级到旧版本,包括FSImage和EditLog。
2. 新旧版本Datanode 数据格式要兼容,这样Datanode在升级失败时可以滚动降级到旧版本。
3. 新版本Namenode 和 旧版本Datanode 要兼容,升级过程中会存在旧版本Datanode和新版本Namenode 共存的情况
4. 由于HDFS作为Hbase、YARN、Hive、Spark等的依赖组件使用,每个组件的 HDFS Client 都散落在全公司使用方,而且由于历史原因版本、配置繁杂,我们很难做到统一升级。所以我们最终只选择升级HDFS 服务端,包括Namenode/Journalnode/zkfc/Datanode,来降低这次升级的阻力和难度。所以需要保证HDP-2.6.5的 Client 可以正常访问3.1.3的Namenode和Datanode服务。
经调研测试,主要有两处不兼容:
1、 DatanodeProtocol.proto 协议不兼容

我们可以看到两个版本 HeartbeatResponseProto 的第4、5个参数不同。当 Datanode 向 Namenode 发送心跳时,携带了requestBlockReportLease=true 参数, Namenode 根据自身忙碌程度决定是否在心跳中返回 fullBlockReportLeaseId 来接收Datanode 的BlockReport ,从而实现Datanode 的BlockReport 限速(详情参见:HDFS-7923[4])。当新版本 Namenode 返回一个fullBlockReportLeaseId 时,被旧版本Datanode 当成rollingUpgradeStatusV2 来解析,最终导致Datanode BlockReport 无法进行。
这个问题的原因在于, 3.1.3 版本 commit 了 HDFS-9788[5] ,用来解决低版本升级时兼容问题,而 HDP-2.6.5 没有commit 。
解决这个问题主要有两个办法:
1、在当前版本HDP-2.6.5 上回退 HDFS-7923[4] 的修改来达到协议兼容;
2、在3.1.3 上回退 HDFS-9788[5] 的修改来保持和HDP-2.6.5 兼容。
综合考虑,HDFS-9788[5] 只是为了解决hdfs升级时兼容低版本的问题,我们当前目标是升级到HDFS 3.x , 至于兼容低版本的功能我们不需要。所以我们选择了第二种方法。
2、 Datanode 数据存储格式不兼容
社区自 HDFS-2.8.0 commit HDFS-8791[6] 后,基于blockid的Block Pool数据块目录存储结构从256x256个目录变成了32x32个目录,数据存储格式发生了变化。这个特性导致了HDP-2.6.5 可以滚动升级到 HDFS-3.1.3 但是不能滚动降级。HDFS-8791[6]主要解决Datanode在ext4文件系统中用256x256个目录存储数据块的性能问题。考虑这个问题在我们集群并不明显,决定暂时回退HDFS-8791[6]的修改,保持Datanode 数据格式的兼容,保证我们在升级Datanode异常时还能降级。至于后续有需要时,可单独升级Datanode。
其他问题
1、升级过程中,DataNode 在删除 Block 时,是不会真的将 Block 删除的,而是先将Block 文件放到磁盘BlockPool 目录下一个 Trash 目录中,为了能够使用原来的 rollback_fsimage 恢复升级过程中删除的数据。我们集群磁盘的水位一直在80%,本来就很紧张,升级期间Trash 中的大量Block文件会对集群稳定造成很大威胁。考虑到我们的方案是的回退方式是滚动降级而非Rollback,并不会用到Trash 中的Block。所以我们使用脚本定时对 Trash 中的 Block 文件进行删除,这样可以大大减少 Datanode 上磁盘的存储压力。
2、升级观察过程中发现旧版本HDFS 在 Kerberos 认证后去连接 3.1.3 建立连接失败,导致一条数据链路故障。因为在3.1.3 版本中增加了 hadoop.security.auth_to_local.mechanism 默认值为hadoop , 不接受带有 ‘@’ 或者 o'/' 的用户名 ,而旧版本Client 在kinit 之后会携带 ‘test@HADOOP.COM’ 这样的用户名去建立连接,所以连接失败。在修改 hadoop.security.auth_to_local.mechanism = MIT 后解决,详见:HADOOP-15996[7] 。反思:考虑集群本身没有开启 Kerberos 认证,在升级测试过程并未把 Kerberos 相关内容划到测试范围内,导致一个故障。以后在测试时要 Involve 更多的依赖方,做更全面的Testing。
3、升级后手动 Failover Namenode 失败,引发Standby Namenode 挂掉。Namenode Failover 时,Standby Namenode 转变成 Active 过程中初始化 Quota 的时间超过了zkfc超时时间,所以Standby Namenode 挂掉。初始化 Quota 线程数默认值为4 ,增加dfs.namenode.quota.init-threads 后解决。详见 :HDFS-8865[8]
测试 & 上线
1、分析升级原理 & 版本差异
在这个过程中,我们详细阅读分析了滚动升级的源码,确定升级中 NameNode,DataNode 会做哪些动作,以明确风险点。由于 HDP-2.6.5 基于Apache-2.7.3 增加了近 2000个Patch ,HDFS-3.1.3 相比 2.7.3 增加了近4000 个 Patch ,我们需要找出可能存在兼容性问题的点进行分析,以确保对升级没有影响。
2、对比新旧版本配置
新旧版本在配置方面有很大不同,尤其是3.1.3 新增了很多配置,都可能成为升级失败的关键点。这里需要我们过滤出新旧版本的不同配置进行研究,确保配置参数兼容。
3、模拟线上环境全量组件测试
HDFS 是众多组件的依赖,HDFS的运行状况随时影响着其他各种链路的稳定。为了尽可能的避免升级风险,保证集群升级的顺利我们模拟线上集群节点压力搭建了一套全量组件测试环境。组织所有相关组件admin 模拟线上场景搭建任务链路,在任务正常运行情况下,开始按步骤进行升级,并每个步骤进行Check ,直升级完成后所有任务都无异常。
4、多次的演练
升级方案验证完成形成Checklist 后,逐步在Dev环境、Test环境、Stage 环境进行演练,在增加操作的熟练度同时通过不同环境的大量测试任务检验升级方案健壮性。
5、正式升级
商定一个升级时间窗口,并通知用户注意升级期间任务运行情况。升级完成观察一周没问题后执行 Finalize 操作。
总结
HDFS 在 3.1.3 版本运行稳定,我们计划在今年完成集群冷数据的转EC操作,降低HDFS存储成本,并在计算组件支持EC文件读写上投入精力调研。后续逐步开启3.1.3版本新特性,包括RBF、Namenode 一致性读、DN的维护状态等功能,来提升HDFS的读写性能,继续为降本增效努力。
引用链接
[1] Hadoop 官方文档: https://hadoop.apache.org/docs/r3.1.3/hadoop-project-dist/hadoop-hdfs/HdfsRollingUpgrade.html[2] HDFS-14396: https://issues.apache.org/jira/browse/HDFS-14396[3] HDFS-13596: https://issues.apache.org/jira/browse/HDFS-13596[4] HDFS-7923: https://issues.apache.org/jira/browse/HDFS-7923[5] HDFS-9788: https://issues.apache.org/jira/browse/HDFS-9788[6] HDFS-8791: https://issues.apache.org/jira/browse/HDFS-8791[7] HADOOP-15996: https://issues.apache.org/jira/browse/HADOOP-15996[8] HDFS-8865: https://issues.apache.org/jira/browse/HDFS-8865
参考资料:
[1]https://blog.csdn.net/DiDi_Tech/article/details/103849694
[2]https://issues.apache.org/jira/browse/HDFS-14831
[3]https://issues.apache.org/jira/browse/HDFS-14509
[4]https://issues.apache.org/jira/browse/HDFS-11096
[5] https://issues.apache.org/jira/browse/HDFS-14753
本文作者:
车好多大数据离线存储团队:冯武、王安迪
以上是关于HDFS 2.x 升级到 3.x 在车好多的实践的主要内容,如果未能解决你的问题,请参考以下文章