秒级去重:ClickHouse在腾讯海量游戏营销活动分析中的应用
Posted 过往记忆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了秒级去重:ClickHouse在腾讯海量游戏营销活动分析中的应用相关的知识,希望对你有一定的参考价值。
腾讯内部每日都需要对海量的游戏营销活动数据做效果分析,而活动参与人数的去重一直是一项难点。本文将为大家介绍腾讯游戏营销活动分析系统——奕星,在去重服务上的技术思路和迭代方案,希望与大家一同交流探讨。文章作者:王方晓,腾讯运营开发工程师。
一、背景
奕星 (EAS) 是腾讯内部专注于游戏营销活动分析的系统,在营销活动效果分析中,奕星遇到一个最大的问题就是对活动参与人数的去重,并给出对应的活动号码包。单个营销活动的周期是固定的,但活动与活动之间时间很少会有完全相同的情况。
比如A活动时间是1-10号,B活动是5-15号,那么如果想分别得到 A 和 B 的去重参与人数,则必须分别开启任务对 A 和 B 在他们所属的时间区间内进行计算去重。在海量日志中每天对数千个营销活动进行类似计算,对资源消耗是一个不小的挑战。
而实际情况下,需要计算的任务量还远远不止于此,奕星同时还提供游戏官网非活动链接的去重数据,甚至每个链接在每个推广渠道的去重数据,这个任务量级目前高达每天 50W+ 以上。
总结来看,面临的主要问题就是如何在海量数据的情况下,处理数量巨大的而且周期各不相同的去重计算任务。
二、原有解决方案
对于这个问题,奕星之前尝试了不少方案,这里简单介绍一下。
1. 基于TDW临时表的方案
TDW 是腾讯内部通用的一站式大数据平台,服务稳定,功能强大。对于这些任务的计算,奕星最早是想借助于 TDW 的计算能力来完成。
思路很简单,就是在 pysql 中循环对每个活动执行对应的 hiveSQL 来完成 T+1 时效的计算。
但这个方案最大的缺点就是:任务基本都是顺序执行,重复扫描大量日志,导致效率非常低下,而且从HDFS中拉取最终的去重文件也非常耗时。
虽然后面采用多种思路优化,比如将原始日志先每天统一批量去重一次入到临时表里,所有计算基于临时表来完成等,但最终还是效率无法进一步提高而放弃。
2. 基于实时计算+文件增量去重的方案
在奕星的数据统计中,基于 Storm 的实时计算任务,主要是提供各个活动的实时 PV 和参与次数等计数类数据。
由于内存资源有限,业界也有基于近似去重算法(如 hyperloglog )直接在 Storm 中算出近似去重结果的,但无法给出精确的结果和最终的号码包文件,所以不符合选型要求。
而内存资源有限,更不可能容纳下这么大量的号码包数据,所以通过内存完全得出最终精确去重结果的方案基本不现实。
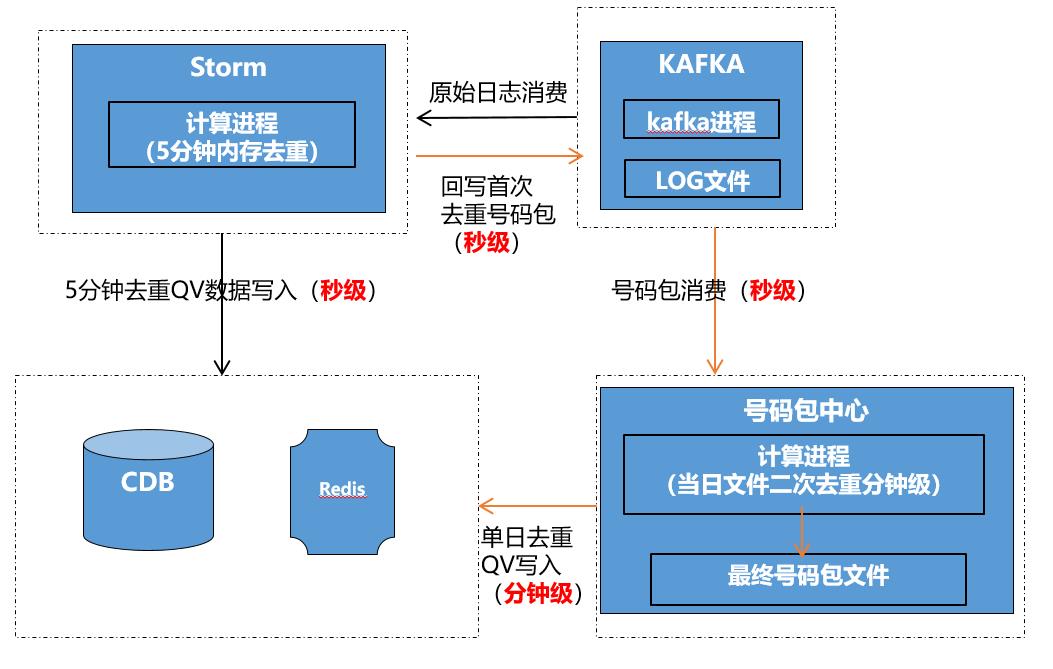
但内存虽然不能容纳整个活动期间的号码数据或者一天之内的号码数据,但是否可以容纳 1 分钟,5 分钟的号码数据?
通过测试计算发现,在内存中缓存 5 分钟内的去重号码数据是完全可行的,并且最高可以将原始日志降低 90% 以上的量级。缓存 1 分钟的话,最高也可以将原始日志降低 70% 以上的量级。
主要的原因是玩家参与活动的时候是即时参与行为,比如一个玩家来到一个活动页面后,一般是连续将活动中能参与的功能都参与下,不会参与完一个等很久再参与下一个,所以导致同一个玩家的日志时间连续性较高,单位时间窗口内去重后量级会降低很多。
基于此,目前奕星主要是基于 Storm 在单位时间窗口内进行初次去重,以达到降低原始数据量级的目的。
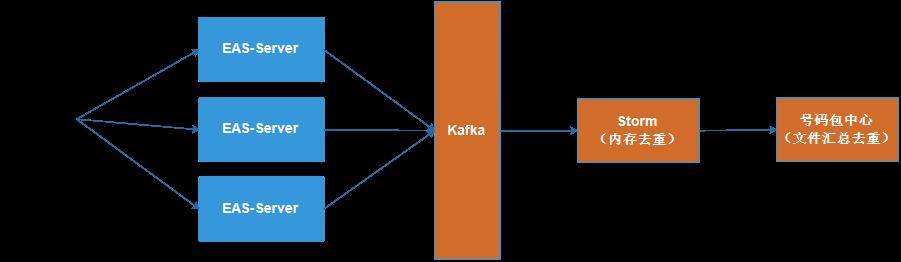
最初的基于 TDW 的去重方案,除了重复扫描等问题外,还有一个问题就是:同一个活动不同日期之间的计算无法前后衔接,比如 A 活动在活动期间(1-10号),每天的计算逻辑基本一致,都是要全量扫描 1-10 号之间的日志(或中间结果)来完成计算。
所以团队将目光投向如何在活动前期去重的基础上来增量去重的问题上来。最终选定的方案是基于文件的计算方案,如下图所示,活动每天都滚动生成最新的去重号码包文件,而次日同一个活动的日号码包再与这个总包交叉后得到更新的号码包文件,如此重复,直到活动结束得到最终的活动号码包文件。
3. 基于实时计算+LevelDB增量去重方案
文件增量去重的方案,运行了一段时间后,就出现了一个很大的问题:就是每日新增的文件量巨大,日均几十万。
虽然没有达到把单台机器 inode 占满的情况,但在增量去重时,大量的小文件 IO 操作,导致增量去重效率非常低,最后被迫只支持高优先级业务的活动和单个活动参与量大于一定阀值的大活动。
经过团队小伙伴的调研,最终将目光锁定在 Google 的 LevelDB 上,LevelDB 是 Google 开源的持久化 KV 单机数据库,具有很高的随机写,顺序读/写性能,但是随机读的性能很一般。
也就是说,LevelDB 很适合应用在查询较少,而写入很多的场景,这正好符合我们号码包去重服务的应用场景。
另外号码包的存储本身也是一个K-V的存储,文件名为 key,文件内容为 value,正好跟 LevelDB 支持的 K-V 结构类似。
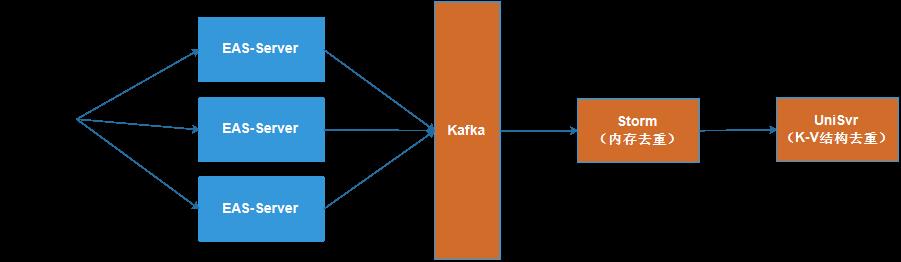
使用 LevelDB 后,可以毫秒级得到某个活动的准确去重人数,并且可以在 10 秒内导出千万量级的号码包文件,相比传统的文件操作,大大提高了号码包去重服务的整体效率。
三、基于CLickHouse的解决方案
虽然基于 LevelDB 的去重服务可以很好的满足大部分营销活动的人数去重需求。但扩展性较差,数据回溯困难等问题比较突出,类似于基于预计算模式的 OLAP 系统。比如系统只支持活动整个期间内的去重人数计算,如果想知道活动期间内某一段时间内的去重就无法实现。
另外如果某个活动引入了脏数据后,只能将整个活动的 K-V 结构删除后重跑,非常耗时。团队经过调研后,将目光锁定到基于 MPP 的 OLAP 方案上。
基于 MPP 的 OLAP 系统,在数据库非共享集群中,每个节点都有独立的磁盘存储系统和内存系统,业务数据根据数据库模型和应用特点划分到各个节点上,每台数据节点通过专用网络或者商业通用网络互相连接,彼此协同计算,作为整体提供数据库服务。
相对于基于预计算模式的 OLAP 系统来说,它最大的优点就是灵活,扩展性强,而最大的缺点是响应时间不及时,甚至需要较长的时间等待。
而在营销活动效果分析中,往往灵活性比效率要更加重要,或者说效率是可以稍微妥协的一面,所以我们选择基于 MPP 的 OLAP 系统。
目前市面上有很多优秀的 OLAP 系统,但要么是收费的(Vertica),要么是基于 hadoop 生态的(presto,Impala),整体架构比较重。
而作为战斗民族开源神器的 ClickHouse 不但拥有自己的文件系统和极高的压缩比,在集群部署上甚至可以不用 zk 来独立部署,甚至在性能上“吊打”商业的 OLAP 系统(详见官方测评数据:https://clickhouse.tech/benchmark/dbms/)。
综合以上考虑,最终选择了 ClickHouse,去重服务就变成了 SQL 查询,例如下面这条 SQL 就是查询 LOL 官网某个页面在 9 月 6 日这 1 天的 UV:
select uniqExact(uvid) from tbUv where date='2020-09-06' and url='http://lol.qq.com/main.shtml';
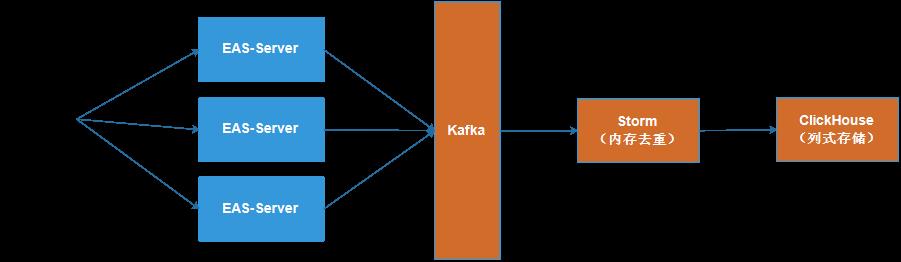
在 24 核 96G 内存的机器上,实际测试下来在 1 亿条记录中,精确去重一个参与量为100W 的活动,仅需 0.1 s 不到,而导出这个号码包文件只需要 0.2 s 不到。
虽然查询效率上比 LevelDB 有一点差距,但灵活性却大大提高,可以任意指定时间区间和条件来做去重查询,符合当前业务场景关注灵活度的需求场景,而且性能上从毫秒到秒级的延迟基本也可以接受。
四、结语
去重服务的的问题伴随奕星系统整个开发和运营周期,期间经历过很多尝试,部分临时的尝试方案尚未在本文列出,但一直的出发点就是业务需求本身,并且结合当时的运维环境来选取对应的技术方案。
不追求绝对的高性能(意味成本也高),而关注最合适,易于扩容,搬迁,故障替换等有利于服务长期稳定运营的特性。当然,随着更多利器的出现,也会去不断的尝试使用,毕竟科学技术才是第一生产力。
目前 ClickHouse 在奕星等多个数据系统和诸多个性化营销分析的场景中落地使用,数据总规模超过 5 千亿,还在不断增长中。
本文只是通过对去重问题的历史回顾顺带简单介绍了一下 ClickHouse,更多关于ClickHouse 的详细介绍和实操,可以自行搜索官方文档和其他分享内容,最后欢迎大家来评论区探讨 ClickHouse 有关的更详细的问题和应用场景。
以上是关于秒级去重:ClickHouse在腾讯海量游戏营销活动分析中的应用的主要内容,如果未能解决你的问题,请参考以下文章
阿里为啥把MySQL晾一边,抢用ClickHouse+Doris,秒级实现有多爽?