Apache Flink 在有赞的实践和应用
Posted 过往记忆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Apache Flink 在有赞的实践和应用相关的知识,希望对你有一定的参考价值。
一、Flink 的容器化改造和实践
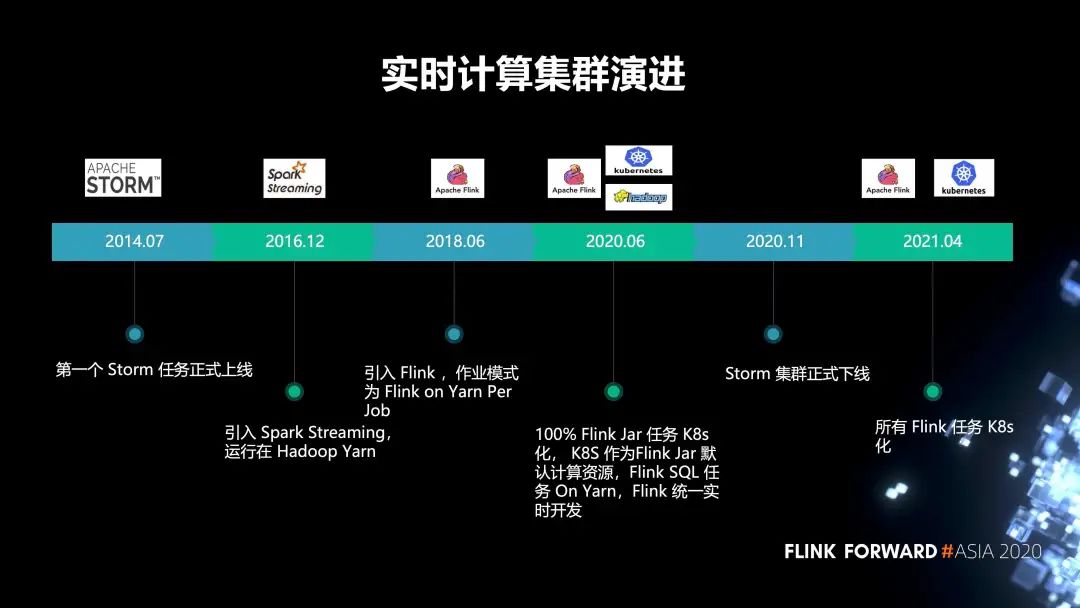
1. 有赞的集群演进历史
2014 年 7 月,第一个 Storm 任务正式上线;
2016 年,引入 Spark Streaming, 运行在 Hadoop Yarn;
2018 年,引入了 Flink,作业模式为 Flink on Yarn Per Job;
2020 年 6 月,实现了 100% Flink Jar 任务 K8s 化, K8s 作为 Flink Jar 默认计算资源,Flink SQL 任务 On Yarn,Flink 统一实时开发;
2020 年 11 月,Storm 集群正式下线。原先的 storm 任务全部都迁移到了 Flink;
2021 年,我们打算把所有的 Flink 任务 K8s 化。
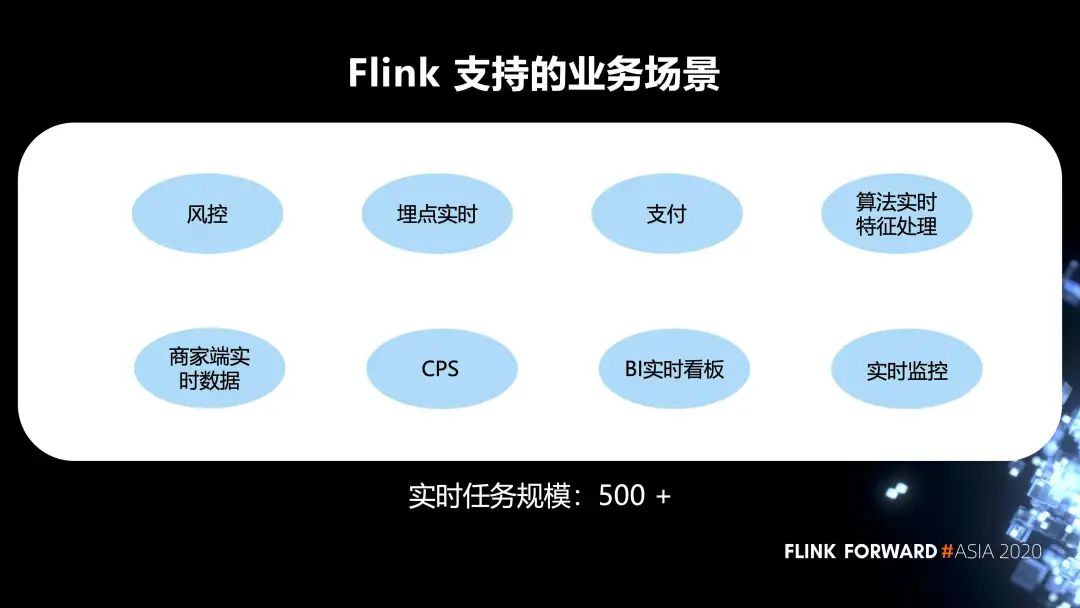
2. Flink 在内部支持的业务场景
Flink 支持的业务场景有风控,埋点的实时任务,支付,算法实时特征处理,BI 的实时看板,以及实时监控等等。目前的实时任务规模有 500+。
3. 有赞在 Flink on Yarn 的痛点
主要有三部分:
第一,CPU 没有隔离。Flink On Yarn 模式,CPU 没有隔离,某个实时任务造成某台机器 CPU 使用过高时, 会对该机器其他实时任务造成影响;
第二,大促扩缩容成本高。Yarn 和 HDFS 服务使用物理机,物理机在大促期间扩缩容不灵活,同时需要投入一定的人力和物力;
第三,需要投入人力运维。公司底层应用资源统一为 K8S,单独再对 Yarn 集群运维,会再多一类集群的人力运维成本。

4. Flink on k8s 相对于 Yarn 的优势
可以归纳为 4 点:
第一,统一运维。公司统一化运维,有专门的部门运维 K8S;
第二,CPU 隔离。K8S Pod 之间 CPU 隔离,实时任务不相互影响,更加稳定;
第三,存储计算分离。Flink 计算资源和状态存储分离,计算资源能够和其他组件资源进行 混部,提升机器使用率;
第四,弹性扩缩容。大促期间能够弹性扩缩容,更好的节省人力和物力成本。

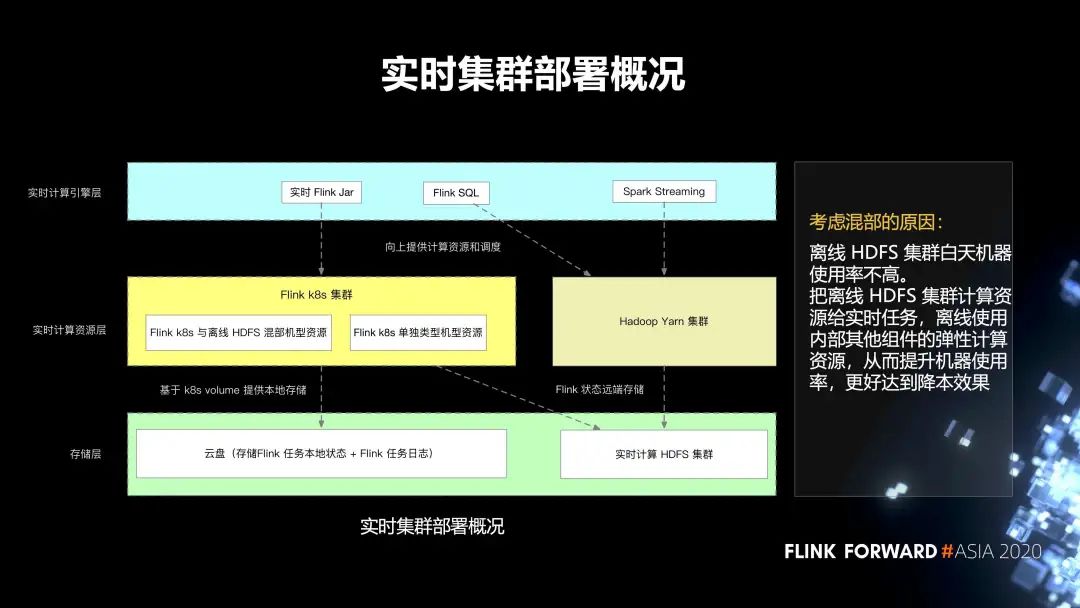
5. 实时集群的部署情况
总体上分为三层。第一层是存储层;第二层是实时计算资源层;第三层是实时计算引擎层。
存储层主要分为两部分:
第一个就是云盘,它主要存储 Flink 任务本地的状态,以及 Flink 任务的日志;
第二部分是实时计算 HDFS 集群,它主要存储 Flink 任务的远端状态。
第二层是实时计算的资源层,分为两部分:
一个是 Hadoop Yarn 集群;
另一个是 Flink k8s 集群,再往下细分,会有 Flink k8s 和离线的 HDFS 混部集群的资源,还有 Flink k8s 单独类型的集群资源。
最上层有一些实时 Flink Jar,spark streaming 任务,以及 Flink SQL 任务。
我们考虑混部的原因是,离线 HDFS 集群白天机器使用率不高。把离线 HDFS 集群计算资源给实时任务,离线使用内部其他组件的弹性计算资源,从而提升机器使用率,更好的达到降本效果。
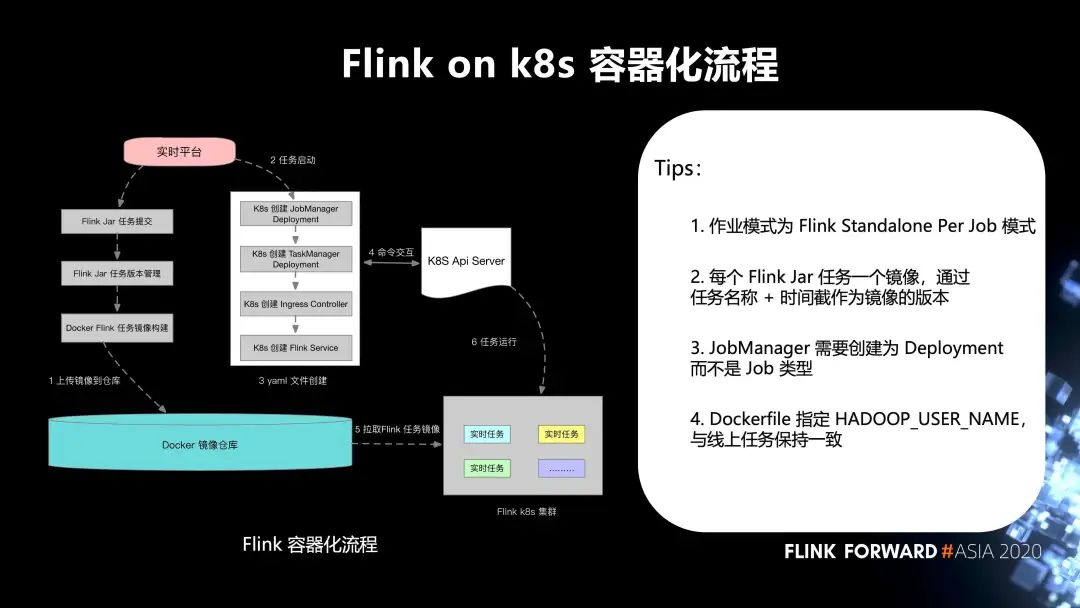
6. Flink on k8s 的容器化流程
如下图所示:
第一步,实时平台的 Flink Jar 任务提交,Flink Jar 任务版本管理,Docker Flink 任务镜像构建,上传镜像到 Docker 镜像仓库;
第二步,任务启动;
第三步,yaml 文件创建;
第四步,和 k8s Api Server 之间进行命令交互;
第五步,从 Docker 镜像仓库拉取 Flink 任务镜像到 Flink k8s 集群;
最后,任务运行。这边有几个 tips:
作业模式为 Flink Standalone Per Job 模式;
每个 Flink Jar 任务一个镜像,通过任务名称 + 时间截作为镜像的版本;
JobManager 需要创建为 Deployment 而不是 Job 类型;
Dockerfile 指定 HADOOP_USER_NAME,与线上任务保持一致。
7. 在 Flink on k8s 的一些实践
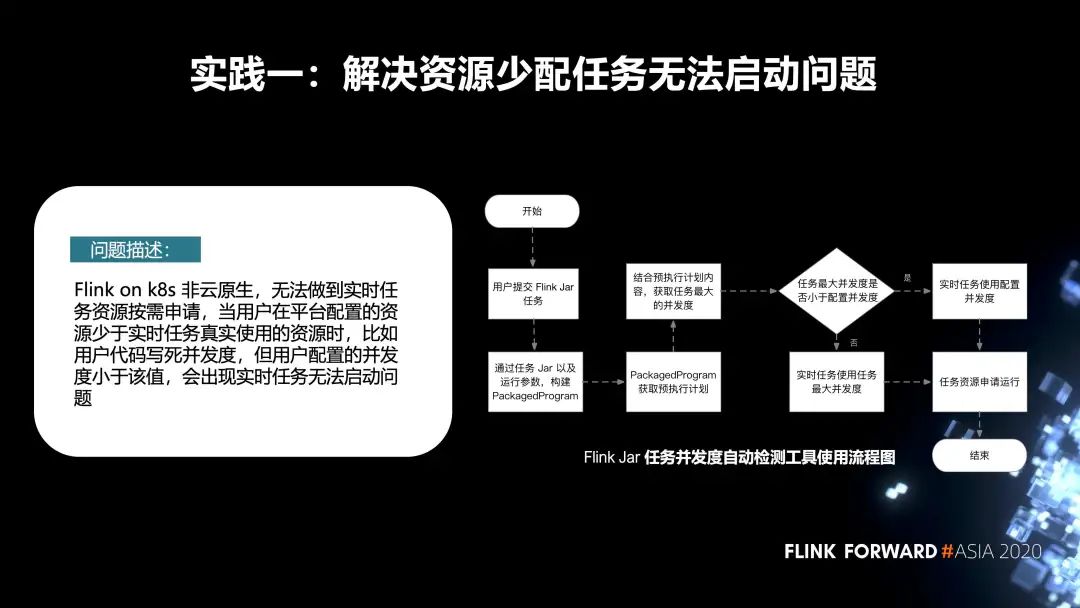
第一个实践是解决资源少配任务无法启动这个问题。
先来描述一下问题,Flink on k8s 非云原生,无法做到实时任务资源按需申请。当用户在平台配置的资源少于实时任务真实使用的资源时(比如用户代码写死并发度,但用户配置的并发度小于该值),会出现实时任务无法启动的问题。针对这个问题,我们内部增加了一种 Flink Jar 任务并发度的自动检测机制。它的主要流程如下图所示。
首先,用户会在我们平台去提交 Flink Jar 作业,当他提交完成之后,在后台会把 Jar 作业以及运行参数,构建 PackagedProgram。通过 PackagedProgram 获取到任务的预执行计划。再通过它获取到任务真实的并发度。
如果用户在代码里配置的并发度小于平台端配置的资源,我们会使用在平台端的配置去申请资源,然后进行启动;
反之,我们会使用它真实的任务并发度去申请资源,启动任务。
第二个实践是 Flink on k8s 任务的资源分析工具。
首先来说一下背景,Flink k8s 任务资源是用户自行配置,当配置的并发度或者内存过大时,存在计算资源浪费的问题,从而会增加底层机器成本。怎么样去解决这个问题,我们做了一个平台管理员的工具。对于管理员来说,他可以从两种视角去看这个任务的资源是否进行了一个超配:
第一个是任务内存的视角。我们根据任务的 GC 日志,通过一个开源工具 GC Viewer,拿到这一个实时任务的内存使用指标;
第二个是消息处理能力的视角。我们在 Flink 源码层增加了数据源输入 record/s 和任务消息处理时间 Metric。根据 metric 找到消息处理最慢的 task 或者 operator,从而判断并发度配置是否合理。
管理员根据内存分析指标以及并发度合理性,结合优化规则,预设置 Flink 资源。然后我们会和业务方沟通与调整。右图是两种分析结果,上面是 Flink on K8S pod 内存分析结果。下面是 Flink K8S 任务处理能力的分析结果。最终,我们根据这些指标就可以对任务进行一个资源的重新调整,降低资源浪费。目前我们打算把它做成一个自动化的分析调整工具。

接下来是 Flink on K8s 其他的相关实践:
第一,基于 Ingress Flink Web UI 和 Rest API 的使用。每个任务有一个 Ingress 域名,始终通过域名访问 Flink Web UI 以及 Resti API 使用;
第二,挂载多个 hostpath volume,解决单块云盘 IO 限制。单块云盘的写入带宽以及 IO 能力有瓶颈,使用多块云盘,降低云盘 Checkpoint 状态和本地写入的压力;
第三,Flink 相关通用配置 ConfigMap 化、Flink 镜像上传成功的检测。为 Filebeat、Flink 作业通用配置,创建 configmap,然后挂载到实时任务中,确保每个 Flink 任务镜像都成功上传到镜像仓库;
第四,HDFS 磁盘 SSD 以及基于 Filebeat 日志采集。SSD 磁盘主要是为了降低磁盘的 IO Wait 时 间,调整 dfs.block.invalidate.limit,降低 HDFS Pending delete block 数。任务日志使用 Filebeat 采集,输出到 kafka,后面通过自定义 LogServer 和离线公用 LogServer 查看。

8. Flink on K8s 当前面临的痛点
第一,JobManager HA 问题。JobManager Pod 如果挂掉,借助于 k8s Deployment 能力,JobManager 会根据 yaml 文件重启,状态可能会丢失。而如果 yaml 配置 Savepoint 恢复,则消息可能大量重复。我们希望后续借助于 ZK 或者 etcd 支持 Jobmanager HA;
第二,修改代码,再次上传时间久。一旦代码修改逻辑,Flink Jar 任务上传时间加上打镜像时间可能是分钟级别,对实时性要求比较高的业务或许有影响。我们希望后续可以参考社区的实现方式,从 HDFS 上面拉取任务 Jar 运行;
第三,K8S Node Down 机, JobManager 恢复慢。一旦 K8S Node down 机后, Jobmanager Pod 恢复运行需要 8分钟左右,主要是 k8s 内部异常发现时间以及作业启动时间,对部分业务有影响,比如CPS实时任务。如何解决,平台端定时检测 K8s node 状态,一旦检测到 down 机状态,将 node 上面有 JobManager 所属的任务停止掉,然后从其之前 checkpoint 恢复;
第四,Flink on k8s 非云原生。当前通过 Flink Jar 任务并发度自动检测工具解决资源少配无法启动问题,但是如果任务的预执行计划无法获取,就无法获取到代码配置的并发度。我们的思考是:Flink on k8s 云原生功能以及前面的 1、2 问题,如果社区支持的比较快速的话,后面可能会考虑将 Flink 版本与社区版本对齐。

9. Flink on K8s的一些方案推荐
第一种方案,是平台自己去构建和管理任务的镜像。
优点是:平台方对于构建镜像,以及运行实时任务整体流程自我掌控,具体问题能够及时修正。
缺点是:需要对 Docker 以及 K8S 相关技术要有一定了解,门槛使用比较高,同时需要考虑非云原生相关问题。它的适用版本为 Flink 1.6 以上。
第二种方案,Flink k8s Operator。
优点是:对用户整体封装了很多底层细节,使用门槛相对降低一些。
缺点是:整体使用没有第一种方案那么灵活,一旦有问题,由于底层使用的是其封装的功能,底层不好修改。它的适用版本为Flink 1.7 以上。
最后一种方案是,基于社区 Flink K8s 功能。
优点是:云原生,对于资源的申请方面更加友好。同时,用户使用会更加方便,屏蔽很多底层实现。
缺点是:K8s 云原生功能还是实验中的功能,相关功能还在开发中,比如 k8s Per job 模式。它的适用版本为Flink 1.10 以上。

二、Flink SQL 实践和应用
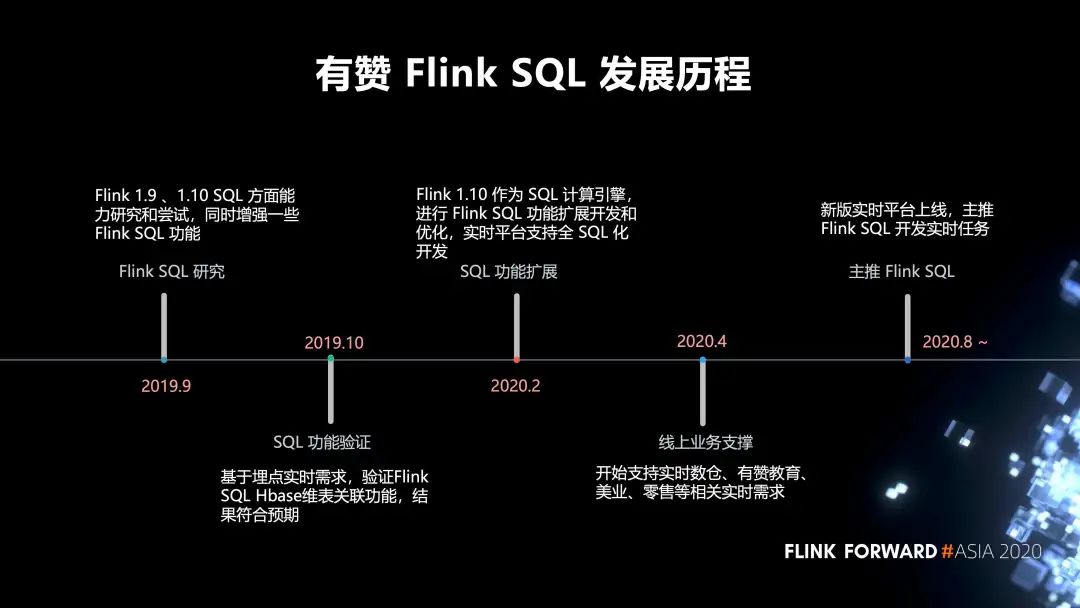
1. 有赞 Flink SQL 的发展历程
2019 年 9 月,我们对 Flink 1.9 、1.10 SQL 方面的能力进行研究和尝试,同时增强了一些 Flink SQL 功能。
2019 年 10 月,我们进行了 SQL 功能验证,基于埋点实时需求,验证 Flink SQL Hbase 维表关联功能,结果符合预期。
2020 年 2 月,我们对 SQL 的功能进行了扩展,以 Flink 1.10 作为 SQL 计算引擎,进行 Flink SQL 功能扩展开发和优化,实时平台支持全 SQL 化开发。
2020 年 4 月,开始支持实时数仓、有赞教育、美业、零售等相关实时需求。
2020 年 8 月,新版的实时平台才开始正式上线,目前主推 Flink SQL 开发我们的实时任务。
2. 在 Flink SQL 方面的一些实践
主要分为三个方面:
第一,Flink Connector 的实践包括:Flink SQL 支持 Flink NSQ Connector、Flink SQL 支持 Flink HA Hbase Sink 和维表、Flink SQL 支持无密 mysql Connector、Flink SQL 支持标准输出(社区已经支持)、Flink SQL 支持 Clickhouse Sink;
第二,平台层的实践包括:Flink SQL 支持 UDF 以及 UDF 管理、支持任务从 Checkpoint 恢复、支持幂等函数、支持 Json 相关函数等、支持 Flink 运行相关参数配置,比如状态时间设置,聚合优化参数等等、Flink 实时任务血缘数据自动化采集、Flink 语法正确性检测功能;
第三,Flink Runtime的实践包括:Flink 源码增加单个Task 以及 Operator 单条记录处理时间指标;修复 Flink SQL 可撤回流 TOP N 的BUG。

3. 业务实践
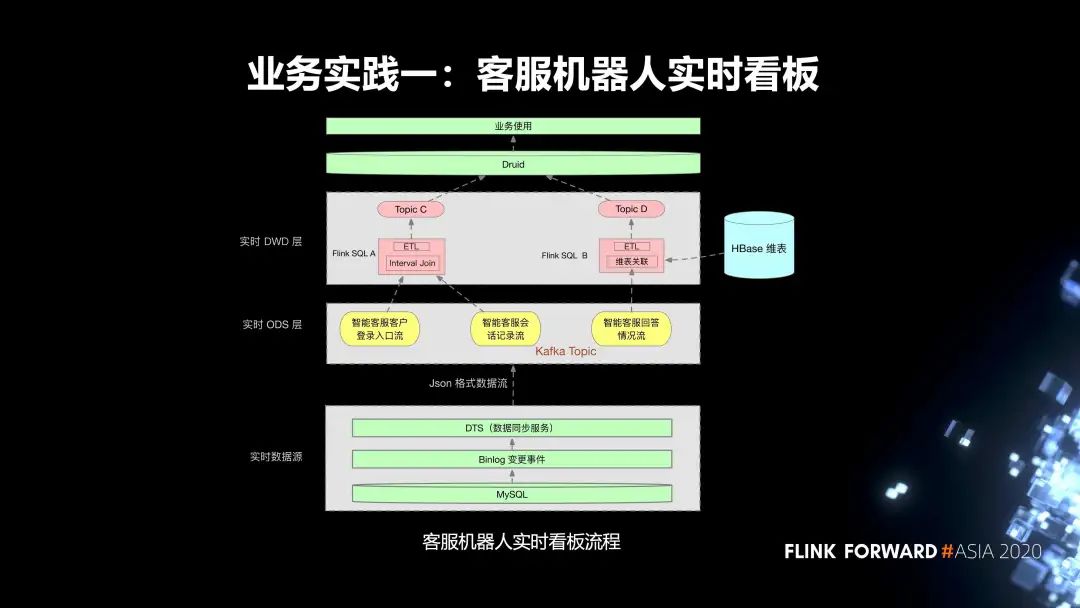
第一个实践是我们内部的客服机器人实时看板。流程分为三层:
第一层是实时数据源,首先是线上的 MySQL 业务表,我们会把它的 Binlog 通过 DTS 服务同步到相应的 Kafka Topic;
实时任务的 ODS 层有三个 Kafka Topic;
在实时 DWD 层,有两个 Flink SQL 任务:
Flink SQL A 消费两个 topic,然后把这两个 topic 里面的数据去通过 Interval Join,根据一些窗口的作用关联到对应的数据。同时,会对这个实时任务设置状态的保留时间。Join 之后,会去进行一些 ETL 的加工处理,最终会把它的数据输入到一个 topic C。
另外一个实时任务 Flink SQL B 消费一个 topic,然后会对 topic 里面的数据进行清洗,然后到 HBase 里面去进行一个维表的关联,去关联它所需要的一些额外的数据,关联的数据最终会输入到 topic D。
在上游,Druid 会消费这两个 topic 的数据,去进行一些指标的查询,最终提供给业务方使用。
第二个实践是实时用户行为中间层。用户在我们平台上面会去搜索、浏览、加入购物车等等,都会产生相应的事件。原先的方案是基于离线来做的。我们会把数据落库到 Hive 表,然后算法那边的同学会结合用户特征、机器学习的模型、离线的数据去生成一些用户评分预估,再把它输入到 HBase。
在这样的背景下面,会有如下诉求:当前的用户评分主要是基于离线任务,而算法同学希望结合实时的用户特征,更加及时、准确的提高推荐精准度。这其实就需要构建一个实时的用户行为中间层,把用户产生的事件输入到 Kafka 里面,通过 Flink SQL 作业对这些数据进行处理,然后把相应的结果输出到 HBase 里面。算法的同学再结合算法模型,实时的更新模型里面的一些参数,最终实时的进行用户的评分预估,也会落库到 HBase,然后到线上使用。
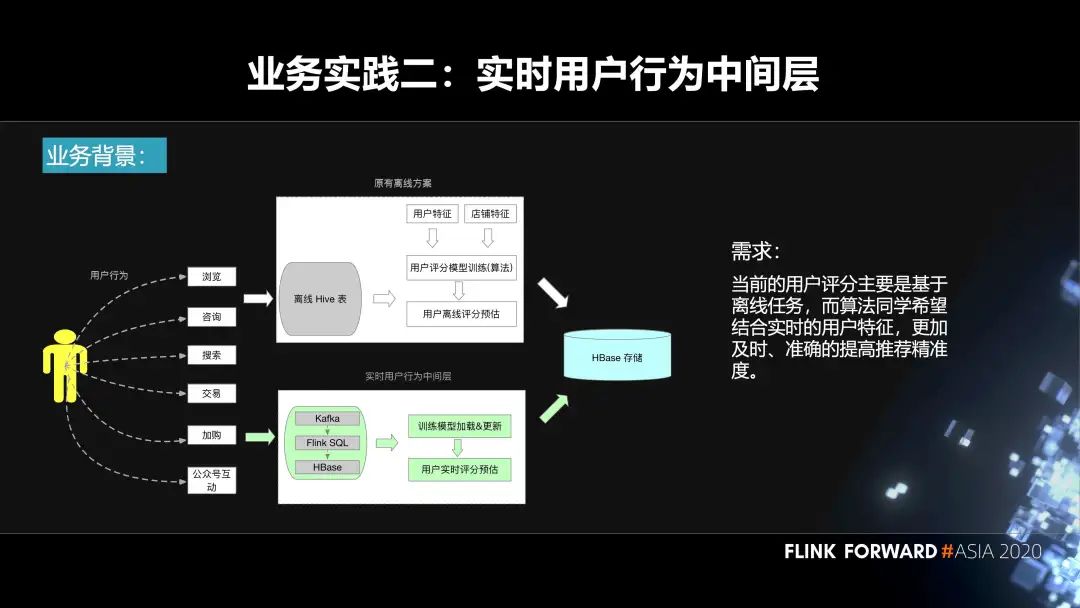
用户行为中间层的构建流程分为三个步骤:
第一层,我们的数据源在 Kafka 里面;
第二层是 ODS 层,在 Flink SQL 作业里面会有一些流表的定义,一些 ETL 逻辑的处理。然后去定义相关的 sink 表、维表等等。这里面也会有一些聚合的操作,然后输入到 Kafka;
在 DWS 层,同样有用户的 Flink SQL 作业,会涉及到用户自己的 UDF Jar,多流 Join,UDF 的使用。然后去读取 ODS 层的一些数据,落库到 HBase 里面,最终给算法团队使用。
这里有几个实践经验:
第一,Kafka Topic、Flink 任务名称,Flink SQL Table 名称,按照数仓命名规范。
第二,指标聚合类计算,Flink SQL 任务要设置空闲状态保留时间,防止任务状态无限增大。
第三,如果存在数据倾斜或者读状态压力较大等情况,需要配置 Flink SQL 优化参数。

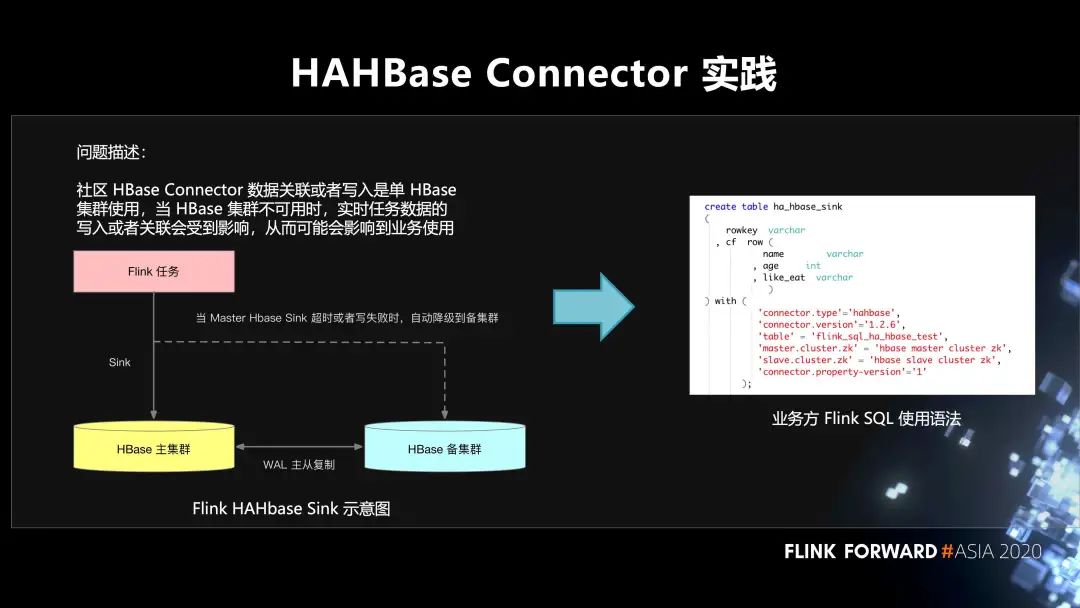
4. 在 HAHBase Connector 的实践
社区 HBase Connector 数据关联或者写入是单 HBase 集群使用,当 HBase 集群不可用时,实时任务数据的写入或者关联会受到影响,从而可能会影响到业务使用。至于怎么样去解决这个问题。首先,在 HBase 方面有两个集群,主集群和备集群。它们之间通过 WAL 进行主从的复制。Flink SQL 作业先写入主集群,当主集群不可用的时候,自动降级到备集群,不会影响到线上业务的使用。
5. 无密 Mysql Connector 和指标扩展实践
左图是 Flink 无密 Mysql Sink 语法,解决的问题包括三点:
第一,Mysql 数据库用户名和密码不以明文方式向外进行暴露和存储;
第二,支持 Mysql 用户名和密码周期性更新;
第三,内部自动根据用户名鉴定表权限使用。这样做最主要的目的还是保证实时任务数据库使用更安全。
然后是左下图,我们在 Flink 源码层面增加 Task 和 Operator 单条消息处理时间 Metric。目的是帮助业务方,根据消息处理时间的监控指标,排查和优化 Flink 实时任务。

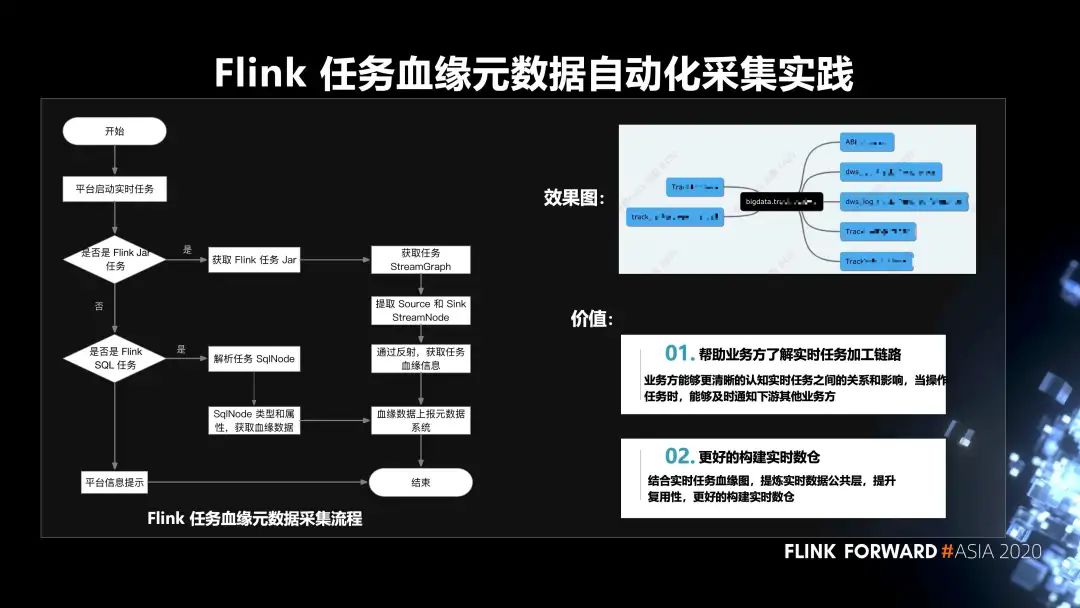
6. Flink 任务血缘元数据自动化采集的实践
Flink 任务血缘元数据采集的流程如下图所示,平台启动实时任务后,根据当前任务是 Flink Jar 任务,还是 Flink SQL 任务,分别走两条不同的路径,来获取任务的血缘数据,再把血缘数据上报元数据系统。这样做的价值有两点:
第一,帮助业务方了解实时任务加工链路。业务方能够更清晰的认知实时任务之间的关系和影响,当操作任务时,能够及时通知下游其他业务方;
第二,更好的构建实时数仓。结合实时任务血缘图,提炼实时数据公共层,提升复用性,更好的构建实时数仓。
三、未来规划
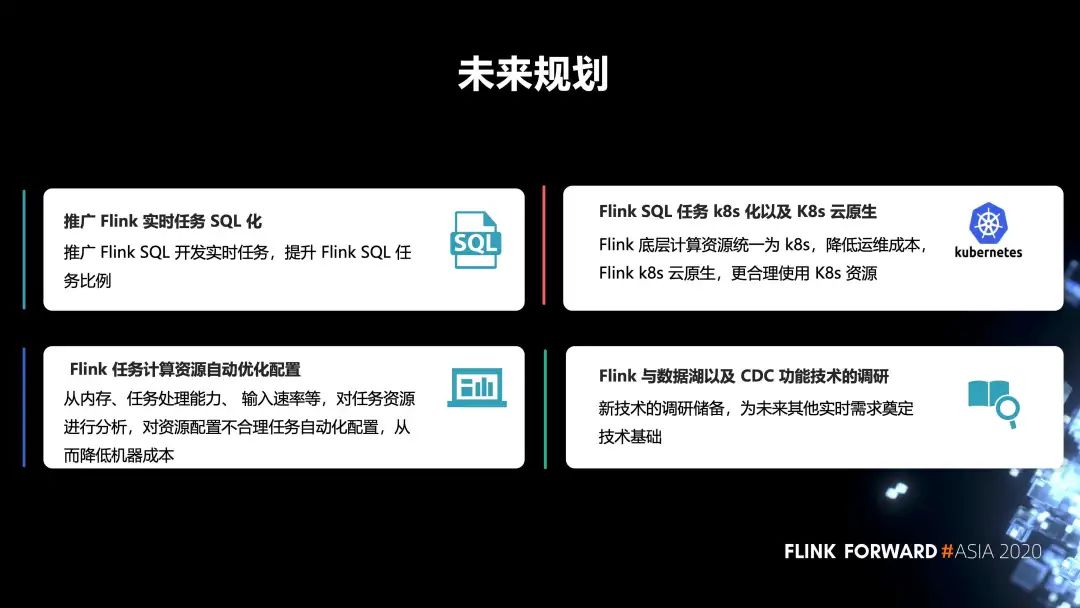
最后是未来的规划,包括四点:
第一,推广 Flink 实时任务 SQL 化。推广 Flink SQL 开发实时任务,提升 Flink SQL 任务比例。
第二,Flink 任务计算资源自动优化配置。从内存、任务处理能力、输入速率等,对任务资源进行分析,对资源配置不合理任务自动化配置,从而降低机器成本。
第三,Flink SQL 任务 k8s 化以及 K8s 云原生。Flink 底层计算资源统一为 k8s,降低运维成本,Flink k8s 云原生,更合理使用 K8s 资源。
第四,Flink 与数据湖以及 CDC 功能技术的调研。新技术的调研储备,为未来其他实时需求奠定技术基础。
 戳我,回顾作者分享视频!
戳我,回顾作者分享视频!
以上是关于Apache Flink 在有赞的实践和应用的主要内容,如果未能解决你的问题,请参考以下文章