Java: 线上故障如何快速排查?来看这套技巧大全(高德地图的总结)
Posted 琦彦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java: 线上故障如何快速排查?来看这套技巧大全(高德地图的总结)相关的知识,希望对你有一定的参考价值。
目录
4.3.1 设置 Redis 的慢命令的时间阈值(单位:微妙)
前言
线上定位问题时,主要靠监控和日志。一旦超出监控的范围,则排查思路很重要,按照流程化的思路来定位问题,能够让我们在定位问题时从容、淡定,快速的定位到线上的问题。
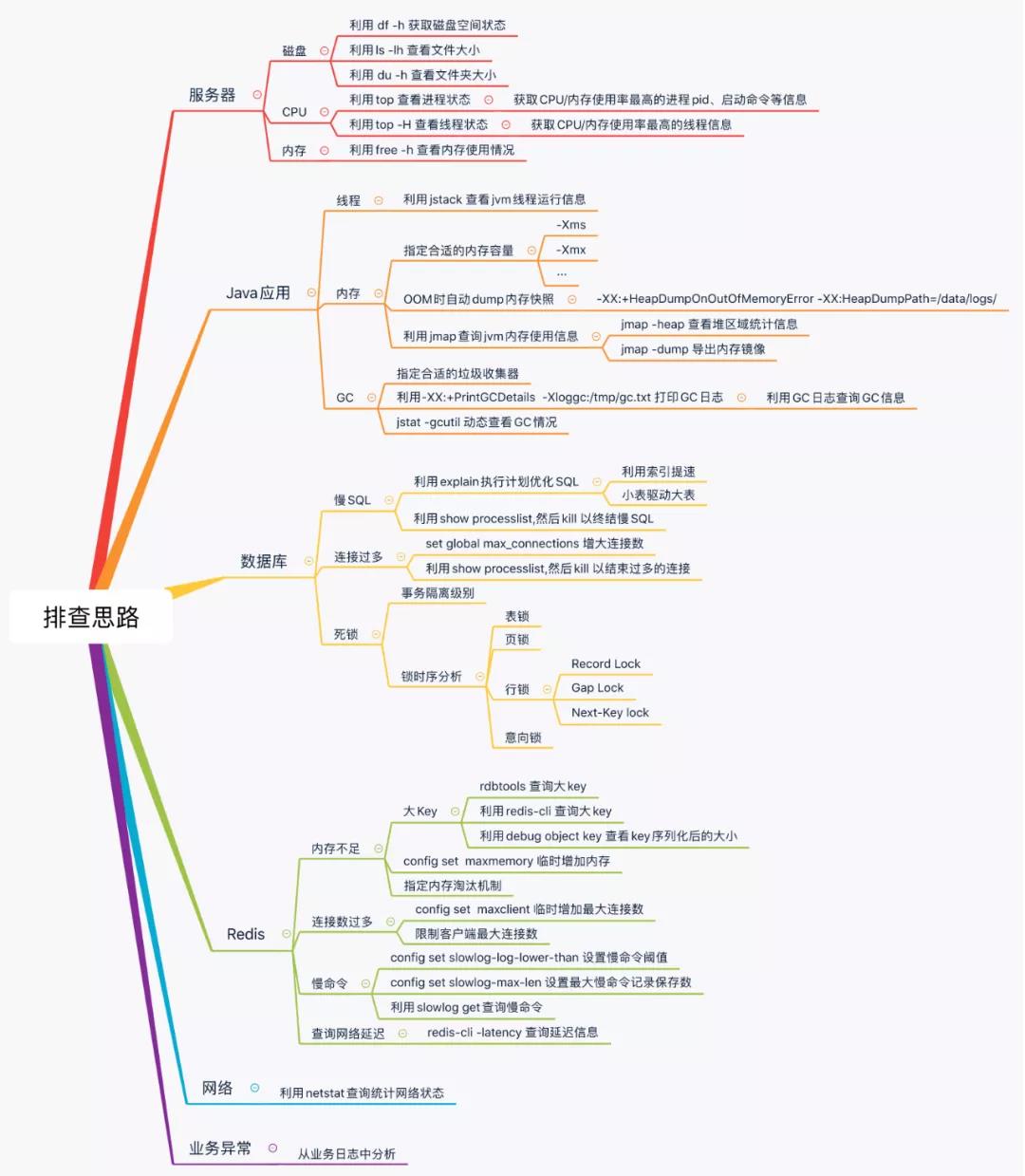
一 服务器层面
1.1 磁盘
1.1.1 问题现象
当磁盘容量不足的时候,应用时常会抛出如下的异常信息:
java.io.IOException: 磁盘空间不足
或是类似如下告警信息:

1.1.2 排查思路
1.1.2.1 利用 df 查询磁盘状态
利用以下指令获取磁盘状态:
df -h
结果是:
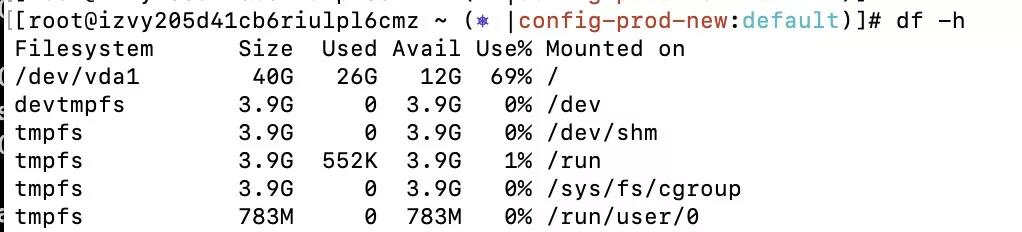
可知 / 路径下占用量最大。
1.1.2.2 利用 du 查看文件夹大小
利用以下指令获取目录下文件夹大小:
du -sh *
结果是:
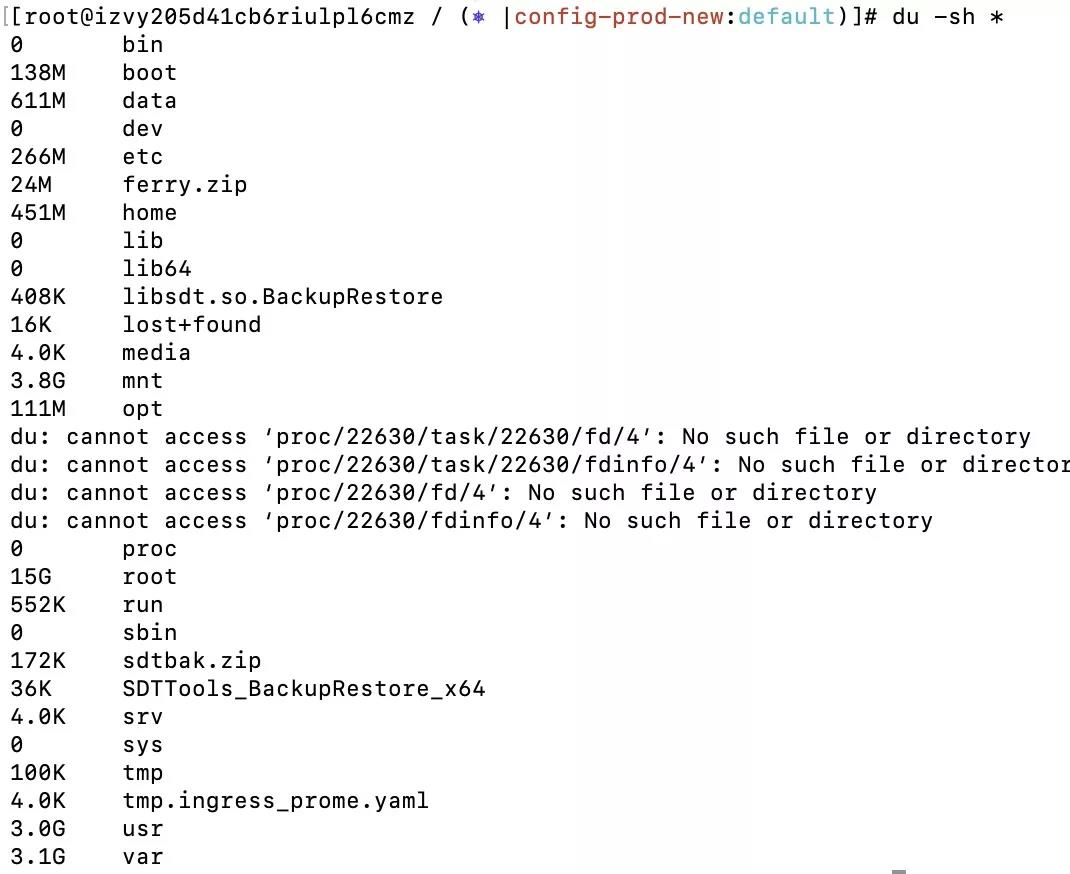
可知 root 文件夹占用空间最大,然后层层递推找到对应的最大的一个或数个文件夹。
1.1.2.3 利用 ls 查看文件大小
利用以下指令获取目录下文件夹大小:
ls -lh
结果是:
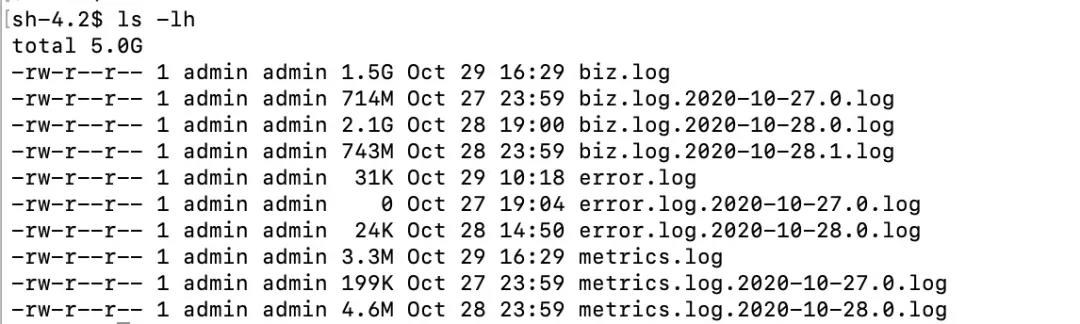
可以找到最大的文件是日志文件,然后使用 rm 指令进行移除以释放磁盘。
1.1.3 相关命令
1.1.3.1 df
主要是用于显示目前在 Linux 系统上的文件系统磁盘使用情况统计。
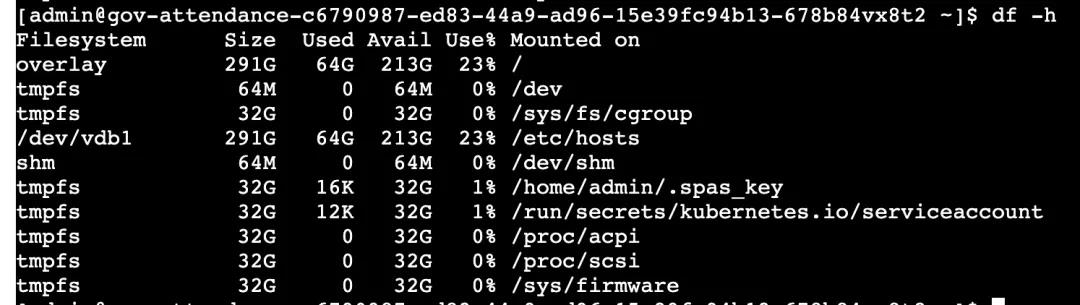
(1)常用参数
启动参数:

(2)结果参数

1.1.3.2 du
主要是为了显示目录或文件的大小。
(1)常用参数
启动参数:

(2)结果参数
1.1.3.3 ls
主要是用于显示指定工作目录下的内容的信息。
(1)常用参数
启动参数:
(2)结果参数

1.2 CPU 过高
1.2.1 问题现象
当 CPU 过高的时候,接口性能会快速下降,同时监控也会开始报警。
1.2.2 排查思路
1.2.2.1 利用 top 查询 CPU 使用率最高的进程
利用以下指令获取系统 CPU 使用率信息:
top
结果是:

从而可以得知 pid 为 14201 的进程使用 CPU 最高。
1.2.3 相关命令
1.2.3.1 top
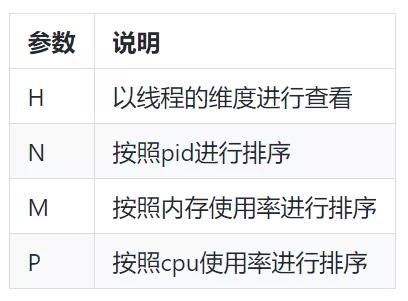
(1)常用参数
启动参数:

top 进程内指令参数:
(2)结果参数

二 应用层面
2.1 Tomcat 假死案例分析
2.1.1 发现问题
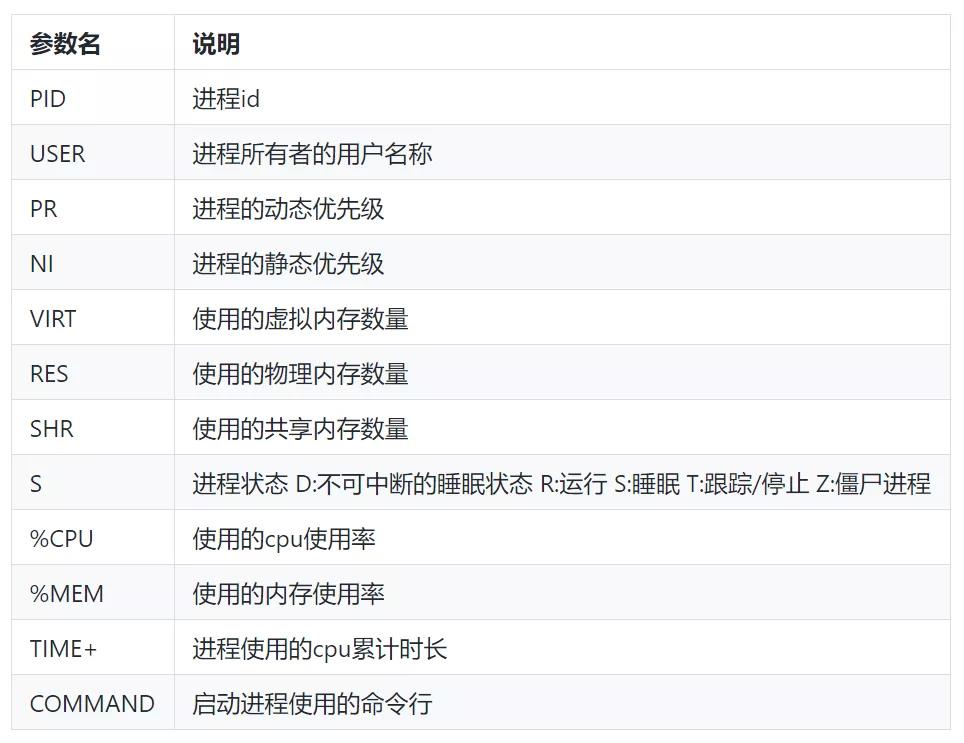
监控平台发现某个 Tomcat 节点已经无法采集到数据,连上服务器查看服务器进程还在,netstat -anop|grep 8001 端口也有监听,查看日志打印时断时续。
2.2.2 查询日志
查看 NG 日志,发现有数据进入到当前服务器(有 8001 和 8002 两个 Tomcat),NG 显示 8002 节点访问正常,8001 节点有 404 错误打印,说明 Tomcat 已经处于假死状态,这个 Tomcat 已经不能正常工作了。
过滤 Tomcat 节点的日志,发现有 OOM 的异常,但是重启后,有时候 Tomcat 挂掉后,又不会打印如下 OOM 的异常:
TopicNewController.getTopicSoftList() error="Java heap space
From class java.lang.OutOfMemoryError"appstore_apitomcat
2.2.3 获取内存快照
在一次 OOM 发生后立刻抓取内存快照,需要执行命令的用户与 JAVA 进程启动用户是同一个,否则会有异常:
/data/program/jdk/bin/jmap -dump:live,format=b,file=/home/www/jmaplogs/jmap-8001-2.bin 18760
ps -ef|grep store.cn.xml|grep -v grep|awk '{print $2}'|xargs /data/program/jdk-1.8.0_11/bin/jmap -dump:live,format=b,file=api.bin内存 dump 文件比较大,有 1.4G,先压缩,然后拉取到本地用 7ZIP 解压。
linux 压缩 dump 为.tgz。
在 windows 下用 7zip 需要经过 2 步解压:
.bin.tgz---.bin.tar--.bin
2.2.4 分析内存快照文件
使用 Memory Analyzer 解析 dump 文件,发现有很明显的内存泄漏提示。
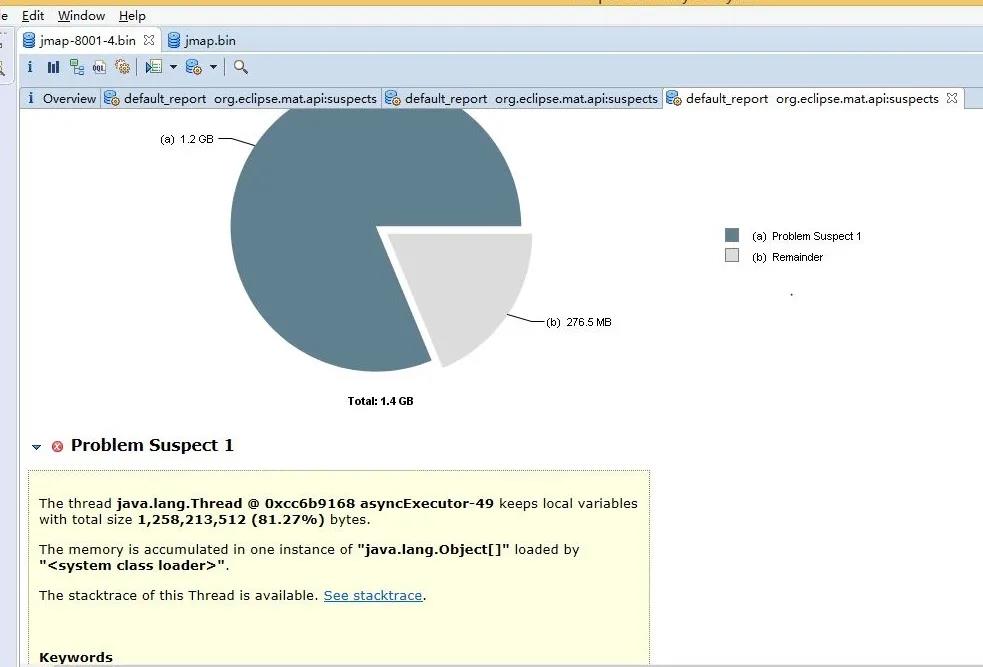
点击查看详情,发现定位到了代码的具体某行,一目了然:

查看 shallow heap 与 retained heap 能发现生成了大量的 Object(810325 个对象),后面分析代码发现是上报 softItem 对象超过 300 多万个对象,在循环的时候,所有的数据全部保存在某个方法中无法释放,导致内存堆积到 1.5G,从而超过了 JVM 分配的最大数,从而出现 OOM。
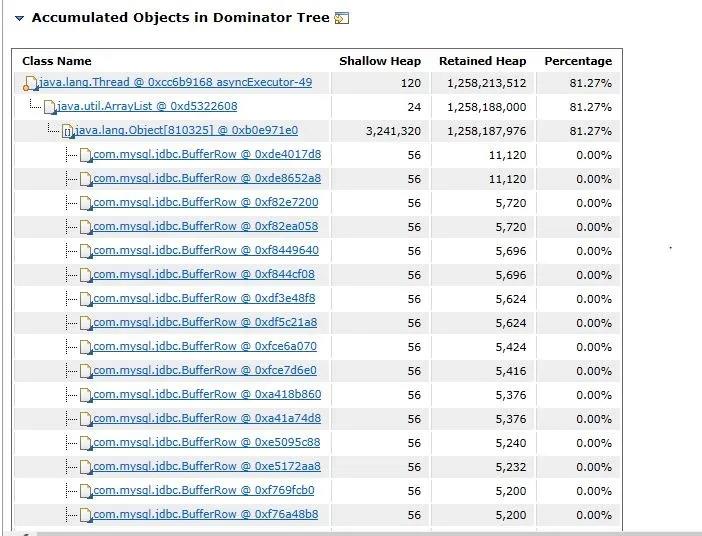
java.lang.Object[810325] @ 0xb0e971e0

2.2.5 相关知识
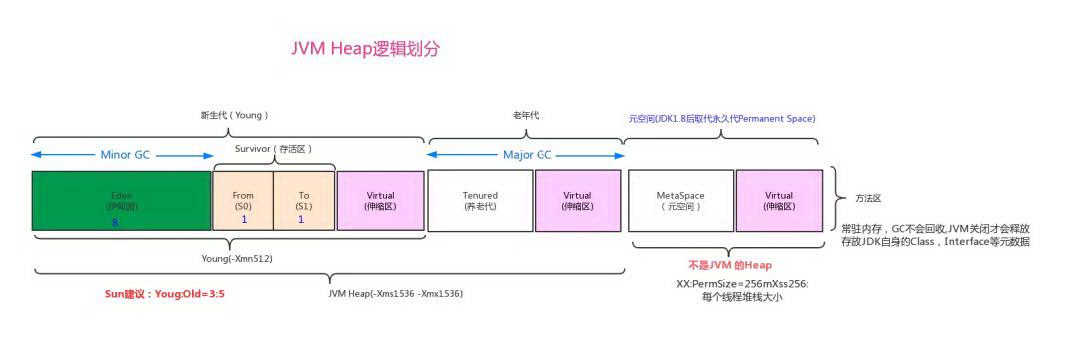
2.2.5.1 JVM 内存
2.2.5.2 内存分配的流程
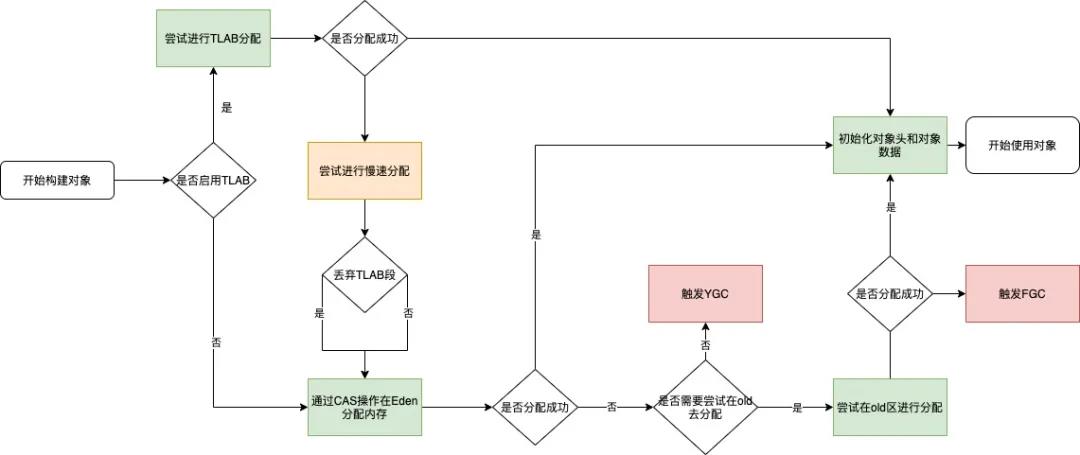
如果通过逃逸分析,则会先在 TLAB 分配,如果不满足条件才在 Eden 上分配。
2.2.4.3 GC
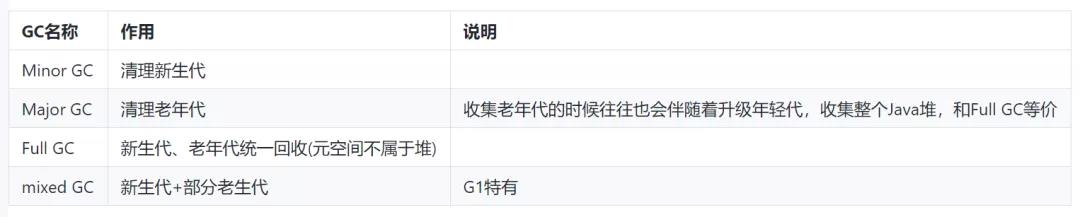
(1)GC 触发的场景
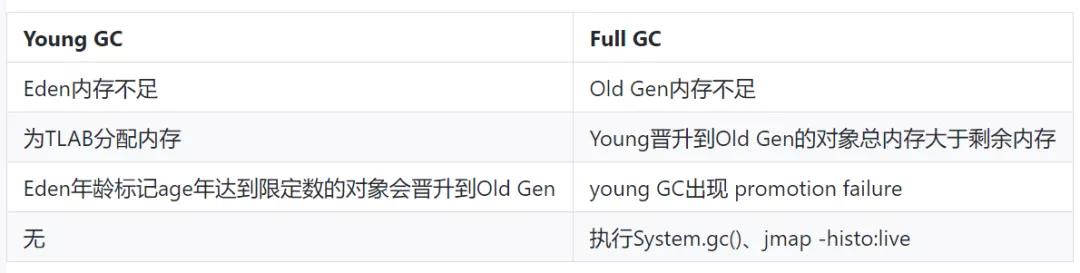
(2)GC Roots
GC Roots 有 4 种对象:
虚拟机栈(栈桢中的本地变量表)中的引用的对象,就是平时所指的 java 对象,存放在堆中。
方法区中的类静态属性引用的对象,一般指被 static 修饰引用的对象,加载类的时候就加载到内存中。
方法区中的常量引用的对象。
本地方法栈中 JNI(native 方法)引用的对象。
(3)GC 算法
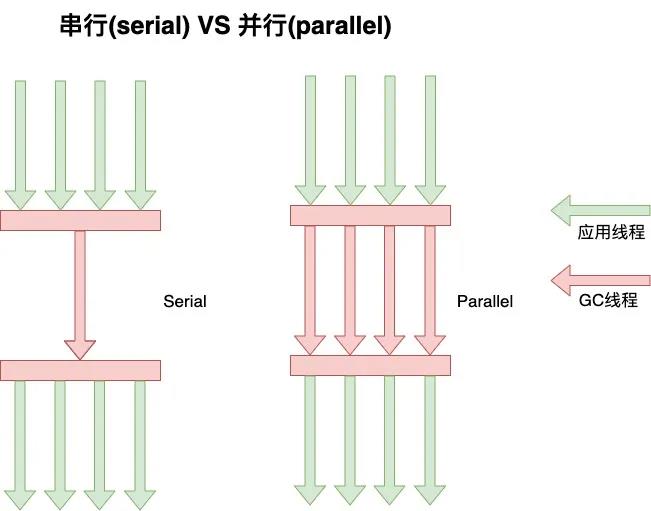
串行只使用单条 GC 线程进行处理,而并行则使用多条。
多核情况下,并行一般更有执行效率,但是单核情况下,并行未必比串行更有效率。
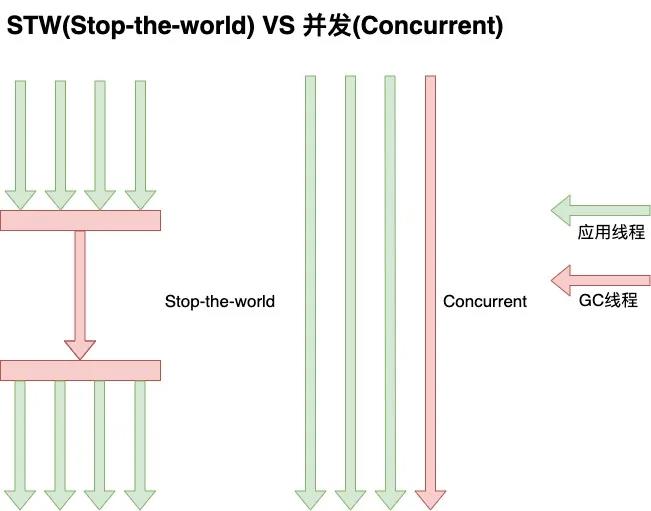
STW 会暂停所有应用线程的执行,等待 GC 线程完成后再继续执行应用线程,从而会导致短时间内应用无响应。
Concurrent 会导致 GC 线程和应用线程并发执行,因此应用线程和 GC 线程互相抢用 CPU,从而会导致出现浮动垃圾,同时 GC 时间不可控。
(4)新生代使用的 GC 算法

新生代算法都是基于 Coping 的,速度快。
Parallel Scavenge:吞吐量优先。
吞吐量=运行用户代码时间 /(运行用户代码时间 + 垃圾收集时间)
(5)老年代使用的 GC 算法

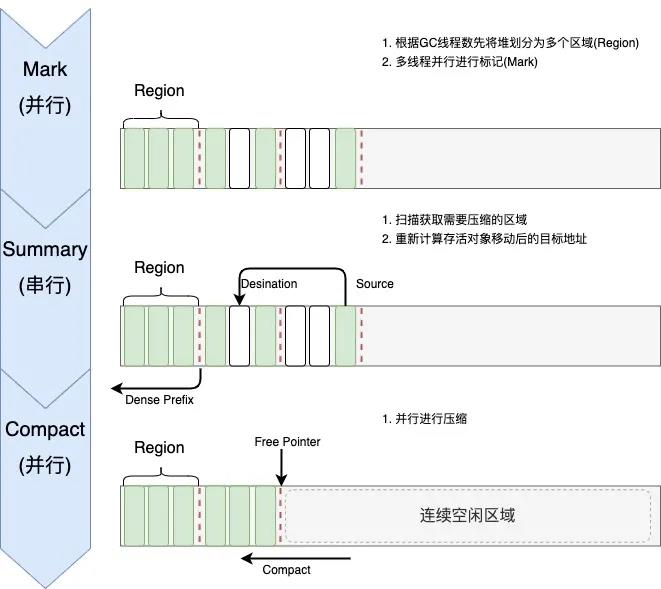
Parallel Compacting

(6)垃圾收集器总结
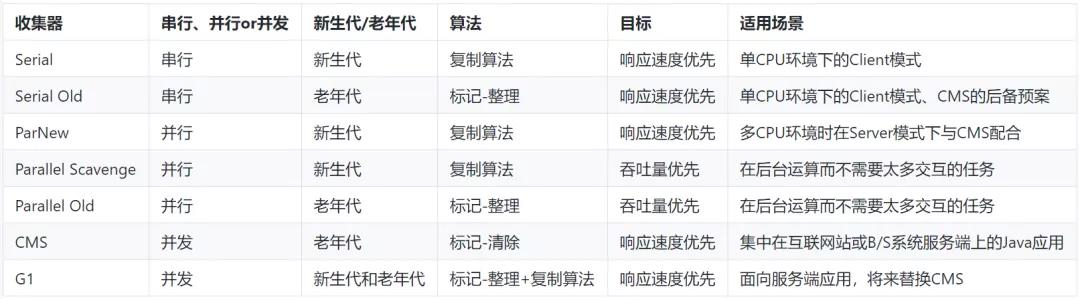
(7)实际场景中算法使用的组合
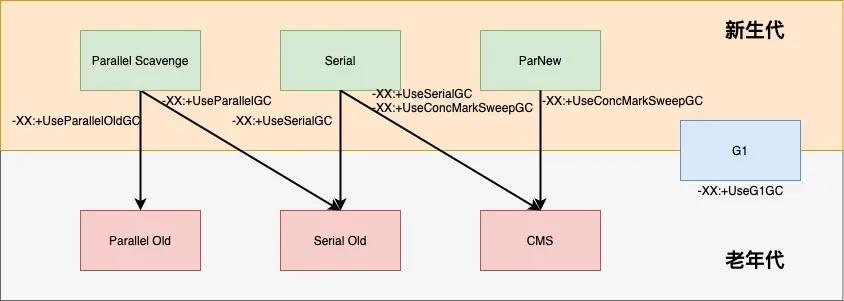
(8)GC 日志格式
(a)监控内存的 OOM 场景
不要在线上使用 jmap 手动抓取内存快照,其一系统 OOM 时手工触发已经来不及,另外在生成 dump 文件时会占用系统内存资源,导致系统崩溃。只需要在 JVM 启动参数中提取设置如下参数,一旦 OOM 触发会自动生成对应的文件,用 MAT 分析即可。
# 内存OOM时,自动生成dump文件-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/data/logs/如果 Young GC 比较频繁,5S 内有打印一条,或者有 Old GC 的打印,代表内存设置过小或者有内存泄漏,此时需要抓取内存快照进行分享。
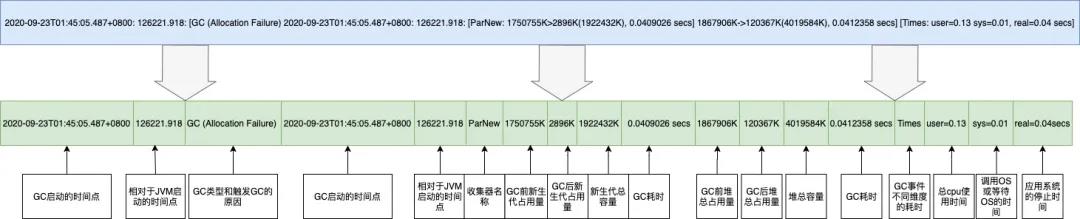
(b)Young Gc 日志
2020-09-23T01:45:05.487+0800: 126221.918: [GC (Allocation Failure)
2020-09-23T01:45:05.487+0800: 126221.918:
[ParNew: 1750755K->2896K(1922432K), 0.0409026 secs]
1867906K->120367K(4019584K), 0.0412358 secs] [Times: user=0.13 sys=0.01, real=0.04 secs]
(c)Old GC 日志
2020-10-27T20:27:57.733+0800: 639877.297: [Full GC (Heap Inspection Initiated GC)
2020-10-27T20:27:57.733+0800: 639877.297: [CMS: 165992K->120406K(524288K), 0.7776748 secs] 329034K->120406K(1004928K),
[Metaspace: 178787K->178787K(1216512K)], 0.7787158 secs] [Times: user=0.71 sys=0.00, real=0.78 secs]

2.2 应用 CPU 过高
2.2.1 发现问题
一般情况下会有监控告警进行提示:
2.2.2 查找问题进程
利用 top 查到占用 cpu 最高的进程 pid 为 14,结果图如下:

2.2.3 查找问题线程
利用 top -H -p 查看进程内占用 cpu 最高线程,从下图可知,问题线程主要是 activeCpu Thread,其 pid 为 417。

2.2.4 查询线程详细信息
首先利用 printf "%x \\n" 将 tid 换为十六进制:xid。
再利用 jstack | grep nid=0x -A 10 查询线程信息(若进程无响应,则使用 jstack -f ),信息如下:

2.2.5 分析代码
由上一步可知该问题是由 CpuThread.java 类引发的,故查询项目代码,获得如下信息:

2.2.6 获得结论
根据代码和日志分析,可知是由于限制值 max 太大,致使线程长时间循环执行,从而导致问题出现。
三 mysql
3.1 死锁
3.1.1 问题出现
最近线上随着流量变大,突然开始报如下异常,即发生了死锁问题:
Deadlock found when trying to get lock; try restarting transaction ;
3.1.2 问题分析
3.1.2.1 查询事务隔离级别
利用
select @@tx_isolation命令获取到数据库隔离级别信息:

3.1.2.2 查询数据库死锁日志
利用
show engine innodb status命令获取到如下死锁信息:

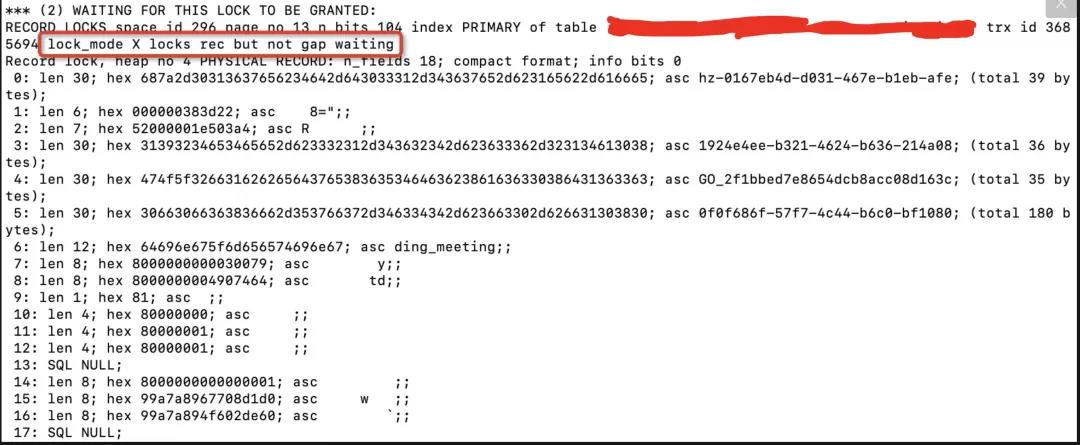
由上可知,是由于两个事物对这条记录同时持有 S 锁(共享锁)的情况下,再次尝试获取该条记录的 X 锁(排它锁),从而导致互相等待引发死锁。
3.1.2.3 分析代码
根据死锁日志的 SQL 语句,定位获取到如下伪代码逻辑:
@Transactional(rollbackFor = Exception.class)
void saveOrUpdate(MeetingInfo info) {
// insert ignore into table values (...)
int result = mapper.insertIgnore(info);
if (result>0) {
return;
}
// update table set xx=xx where id = xx
mapper.update(info);
}3.1.2.4 获得结论
分析获得产生问题的加锁时序如下,然后修改代码实现以解决该问题。
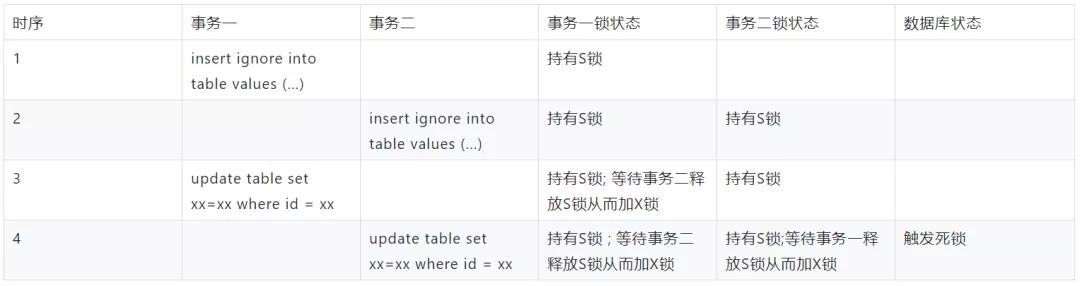
3.2 慢 SQL
3.1.1 问题出现
应用 TPS 下降,并出现 SQL 执行超时异常或者出现了类似如下的告警信息,则常常意味着出现了慢 SQL。
3.1.2 问题分析
分析执行计划:利用 explain 指令获得该 SQL 语句的执行计划,根据该执行计划,可能有两种场景。
SQL 不走索引或扫描行数过多等致使执行时长过长。
SQL 没问题,只是因为事务并发导致等待锁,致使执行时长过长。
3.1.3 场景一
3.1.3.1 优化 SQL
通过增加索引,调整 SQL 语句的方式优化执行时长, 例如下的执行计划:

该 SQL 的执行计划的 type 为 ALL,同时根据以下 type 语义,可知无索引的全表查询,故可为其检索列增加索引进而解决。

3.1.4 场景二
3.1.4.1 查询当前事务情况
可以通过查看如下 3 张表做相应的处理:
-- 当前运行的所有事务
select * from information_schema.innodb_trx;
-- 当前出现的锁
SELECT * FROM information_schema.INNODB_LOCKS;
-- 锁等待的对应关系
select * from information_schema.INNODB_LOCK_WAITS;(1)查看当前的事务有哪些:
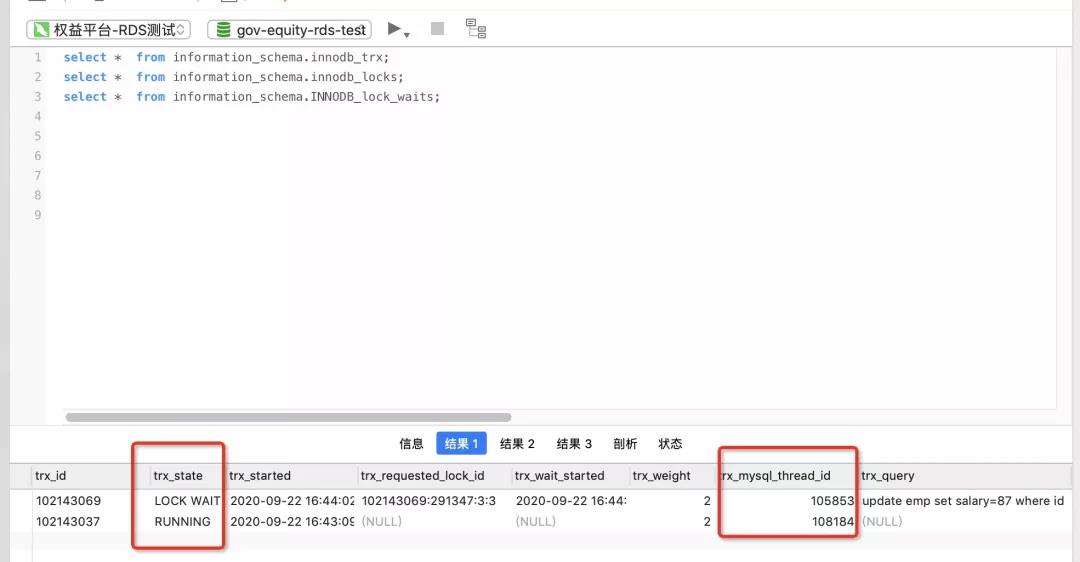
(2)查看事务锁类型索引的详细信息:

lock_table 字段能看到被锁的索引的表名,lock_mode 可以看到锁类型是 X 锁,lock_type 可以看到是行锁 record。
3.1.4.2 分析
根据事务情况,得到表信息,和相关的事务时序信息:
DROP TABLE IF EXISTS `emp`;
CREATE TABLE `emp` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`salary` int(10) DEFAULT NULL,
`name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_name` (`name`(191)) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8mb4;
A 事物锁住一条记录,不提交,B 事物需要更新此条记录,此时会阻塞,如下图是执行顺序:

3.1.4.3 解决方案
(1)修改方案
由前一步的结果,分析事务间加锁时序,例如可以通过 tx_query 字段得知被阻塞的事务 SQL,trx_state 得知事务状态等,找到对应代码逻辑,进行优化修改。
(2)临时修改方案
trx_mysql_thread_id 是对应的事务 sessionId,可以通过以下命令杀死长时间执行的事务,从而避免阻塞其他事务执行。
kill 105853
3.3 连接数过多
3.3.1 问题出现
常出现 too many connections 异常,数据库连接到达最大连接数。
3.3.2 解决方案
解决方案:
通过 set global max_connections=XXX 增大最大连接数。
先利用 show processlist 获取连接信息,然后利用 kill 杀死过多的连。
常用脚本如下:
排序数据库连接的数目
mysql -h127.0.0.0.1 -uabc_test -pXXXXX -P3306 -A -e 'show processlist'| awk '{print $4}'|sort|uniq -c|sort -rn|head -10
3.4 相关知识
3.4.1 索引
3.4.1.1 MySql 不同的存储引擎

3.4.1.2 InnoDB B+Tree 索引实现
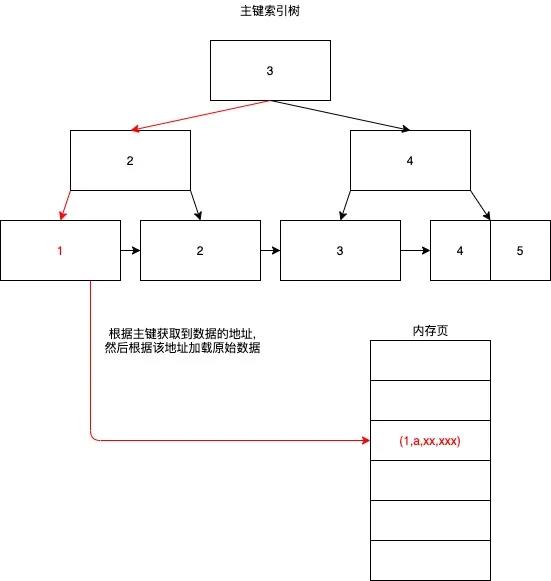
主键索引(聚集索引):
叶子节点 data 域保存了完整的数据的地址。
主键与数据全部存储在一颗树上。
Root 节点常驻内存。
每个非叶子节点一个 innodb_page_size 大小,加速磁盘 IO。
磁盘的 I/O 要比内存慢几百倍,而磁盘慢的原因在于机械设备寻找磁道慢,因此采用磁盘预读,每次读取一个磁盘页(page:计算机管理存储器的逻辑块-通常为 4k)的整倍数。
如果没有主键,MySQL 默认生成隐含字段作为主键,这个字段长度为 6 个字节,类型为长整形。
辅助索引结构与主索引相同,但叶子节点 data 域保存的是主键指针。
InnoDB 以表空间 Tablespace(idb 文件)结构进行组织,每个 Tablespace 包含多个 Segment 段。
每个段(分为 2 种段:叶子节点 Segment&非叶子节点 Segment),一个 Segment 段包含多个 Extent。
一个 Extent 占用 1M 空间包含 64 个 Page(每个 Page 16k),InnoDB B-Tree 一个逻辑节点就分配一个物理 Page,一个节点一次 IO 操作。
一个 Page 里包含很多有序数据 Row 行数据,Row 行数据中包含 Filed 属性数据等信息。
InnoDB 存储引擎中页的大小为 16KB,一般表的主键类型为 INT(占用 4 个字节)或 BIGINT(占用 8 个字节),指针类型也一般为 4 或 8 个字节,也就是说一个页(B+Tree 中的一个节点)中大概存储 16KB/(8B+8B)=1K 个键值(因为是估值,为方便计算,这里的 K 取值为[10]^3)。
也就是说一个深度为 3 的 B+Tree 索引可以维护 10^3 * 10^3 * 10^3 = 10 亿 条记录。
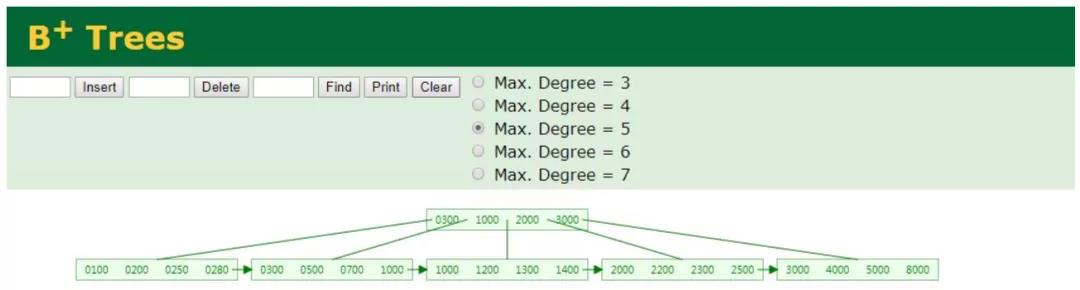
每个索引的左指针都是比自己小的索引/节点,右指针是大于等于自己的索引/节点。
3.4.2 B+ Tree 索引检索
3.4.2.1 主键索引检索
select * from table where id = 1
3.4.2.2 辅助索引检索
select * from table where name = 'a'
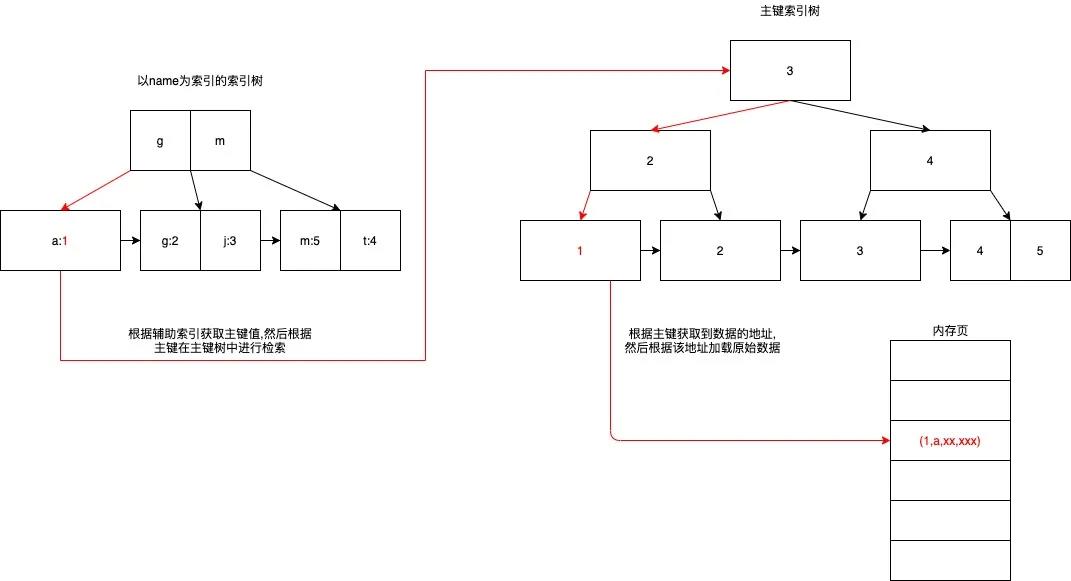
3.4.3 事物的隔离级别
3.4.3.1 如何查看数据库的事务隔离级别
使用如下命令可以查看事务的隔离级别:
show variables like 'tx_isolation';
阿里云上的 rds 的隔离级别是 read committed ,而不是原生 mysql 的“可重复读(repeatable-read)。
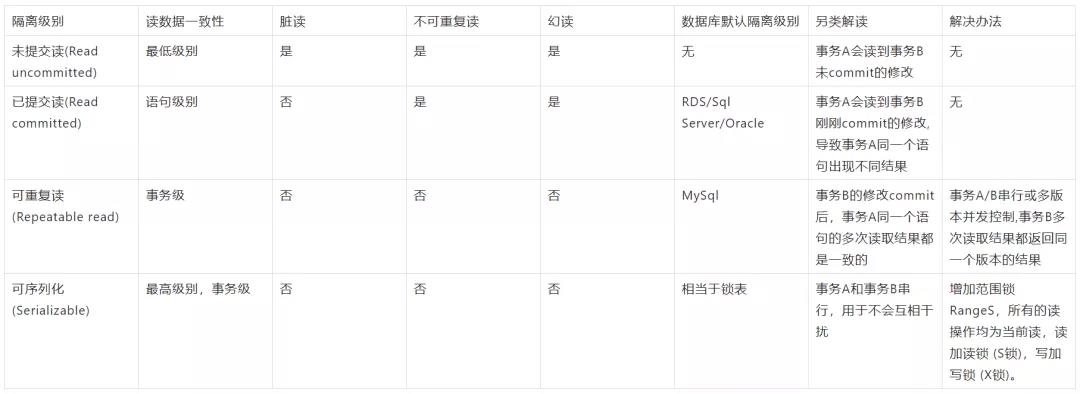
- Repeatable read 不存在幻读的问题,RR 隔离级别保证对读取到的记录加锁 (记录锁),同时保证对读取的范围加锁,新的满足查询条件的记录不能够插入 (间隙锁),不存在幻读现象。
在 MYSQL 的事务引擎中,INNODB 是使用范围最广的。它默认的事务隔离级别是 REPEATABLE READ(可重复读),在标准的事务隔离级别定义下,REPEATABLE READ 是不能防止幻读产生的。INNODB 使用了 next-key locks 实现了防止幻读的发生。
在默认情况下,mysql 的事务隔离级别是可重复读,并且 innodb_locks_unsafe_for_binlog 参数为 OFF,这时默认采用 next-key locks。所谓 Next-Key Locks,就是 Record lock 和 gap lock 的结合,即除了锁住记录本身,还要再锁住索引之间的间隙。可以设置为 ON,则 RR 隔离级别时会出现幻读。
3.4.3.2 多版本并发控制 MVCC
MySQL InnoDB 存储引擎,实现的是基于多版本的并发控制协议——MVCC (Multi-Version Concurrency Control) (注:与 MVCC 相对的,是基于锁的并发控制,Lock-Based Concurrency Control)。
- MVCC 最大的好处,相信也是耳熟能详:读不加锁,读写不冲突。在读多写少的 OLTP 应用中,读写不冲突是非常重要的,极大的增加了系统的并发性能。
在 MVCC 并发控制中,读操作可以分成两类:快照读 (snapshot read)与当前读 (current read)。
- 快照读:简单的 select 操作,属于快照读,不加锁。(当然,也有例外,下面会分析)。
select * from table where ?;
当前读:特殊的读操作,插入/更新/删除操作,属于当前读,需要加锁。
select * from table where ? lock in share mode; 加S锁 (共享锁)
-- 下面的都是X锁 (排它锁)
select * from table where ? for update;
insert into table values (…);
update table set ? where ?;
delete from table where ?;3.4.4.3 场景模拟
修改事务隔离级别的语句:
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;
-- READ UNCOMMITTED/READ COMMITTED/REPEATABLE READ/SERIALIZABLE(1)脏读场景模拟
DROP TABLE IF EXISTS `employee`;
CREATE TABLE `employee` (
`id` int(11) NOT NULL,
`name` varchar(50) NOT NULL,
`salary` int(11) DEFAULT NULL,
KEY `IDX_ID` (`id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of employee
-- ----------------------------
INSERT INTO `employee` VALUES ('10', '1s', '10');
INSERT INTO `employee` VALUES ('20', '2s', '20');
INSERT INTO `employee` VALUES ('30', '3s', '30');
(2)不可重复读模拟
DROP TABLE IF EXISTS `employee`;
CREATE TABLE `employee` (
`id` int(11) NOT NULL,
`name` varchar(50) NOT NULL,
`salary` int(11) DEFAULT NULL,
KEY `IDX_ID` (`id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of employee
-- ----------------------------
INSERT INTO `employee` VALUES ('10', '1s', '10');
INSERT INTO `employee` VALUES ('20', '2s', '20');
INSERT INTO `employee` VALUES ('30', '3s', '30');不可重复读的重点是修改: 同样的条件, 你读取过的数据, 再次读取出来发现值不一样了。

(3)幻读场景模拟
表结构与数据如下:id 不是主键,也不是唯一索引,只是一个普通索引,事务隔离级别设置的是 RR,可以模拟到 GAP 锁产生的场景。
DROP TABLE IF EXISTS `emp`;
CREATE TABLE `emp` (
`id` int(11) NOT NULL,
`salary` int(11) DEFAULT NULL,
KEY `IDX_ID` (`id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of emp
-- ----------------------------
INSERT INTO `emp` VALUES ('10', '10');
INSERT INTO `emp` VALUES ('20', '20');
INSERT INTO `emp` VALUES ('30', '30');
修改 id=20 的数据后,会在加多个锁:20 会被加 X 锁,[10-20],[20-30]之间会被加 GAP 锁。
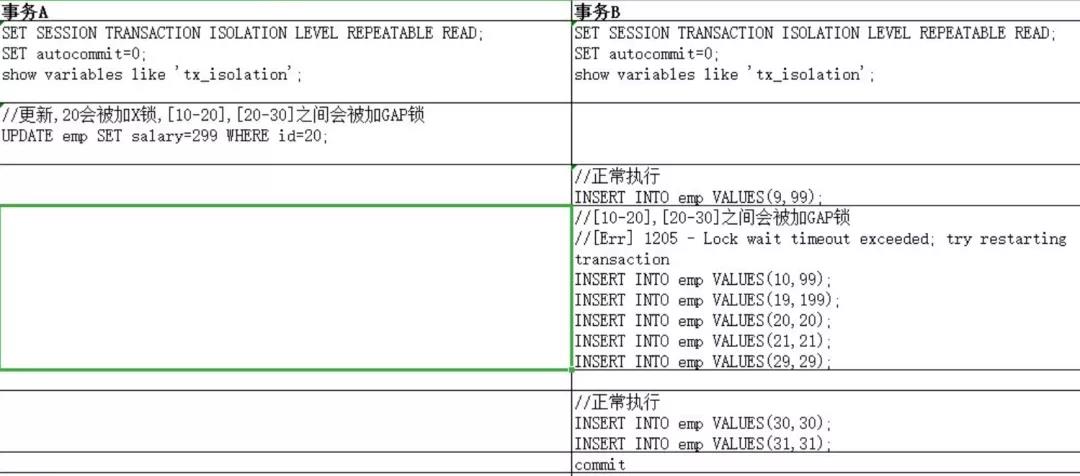
幻读的重点在于新增或者删除 (数据条数变化)。同样的条件, 第 1 次和第 2 次读出来的记录数不一样。
在标准的事务隔离级别定义下,REPEATABLE READ 是不能防止幻读产生的。INNODB 使用了 2 种技术手段(MVCC AND GAP LOCK)实现了防止幻读的发生。
3.4.4 Innodb 的多种锁
3.4.4.1 锁类型

表锁的优势:开销小;加锁快;无死锁。
表锁的劣势:锁粒度大,发生锁冲突的概率高,并发处理能力低。
加锁的方式:自动加锁。查询操作(SELECT),会自动给涉及的所有表加读锁,更新操作(UPDATE、DELETE、INSERT),会自动给涉及的表加写锁。也可以显示加锁。
共享读锁:lock table tableName read
独占写锁:lock table tableName write
批量解锁:unlock tables
3.4.4.2 行锁

只在 Repeatable read 和 Serializable 两种事务隔离级别下才会取得上面的锁。
3.4.4.3 意向锁
(1)场景
- 在 mysql 中有表锁,LOCK TABLE my_tabl_name READ; 用读锁锁表,会阻塞其他事务修改表数据。LOCK TABLE my_table_name WRITe; 用写锁锁表,会阻塞其他事务读和写。
- Innodb 引擎又支持行锁,行锁分为共享锁,一个事务对一行的共享只读锁。排它锁,一个事务对一行的排他读写锁。
- 这两中类型的锁共存的问题考虑这个例子:
- 事务 A 锁住了表中的一行,让这一行只能读,不能写。之后,事务 B 申请整个表的写锁。如果事务 B 申请成功,那么理论上它就能修改表中的任意一行,这与 A 持有的行锁是冲突的。
- 数据库需要避免这种冲突,就是说要让 B 的申请被阻塞,直到 A 释放了行锁。
(2)问题
数据库要怎么判断这个冲突呢?
(3)答案
无意向锁的情况下:
step1:判断表是否已被其他事务用表锁锁表
step2:判断表中的每一行是否已被行锁锁住。
有意向锁的情况下:
step1:不变
step2:发现表上有意向共享锁,说明表中有些行被共享行锁锁住了,因此,事务 B 申请表的写锁会被阻塞。
(4)总结
在无意向锁的情况下,step2 需要遍历整个表,才能确认是否能拿到表锁。而在意向锁存在的情况下,事务 A 必须先申请表的意向共享锁,成功后再申请一行的行锁,不需要再遍历整个表,提升了效率。因此意向锁主要是为了实现多粒度锁机制(白话:为了表锁和行锁都能用)。
3.4.4.4 X/S 锁
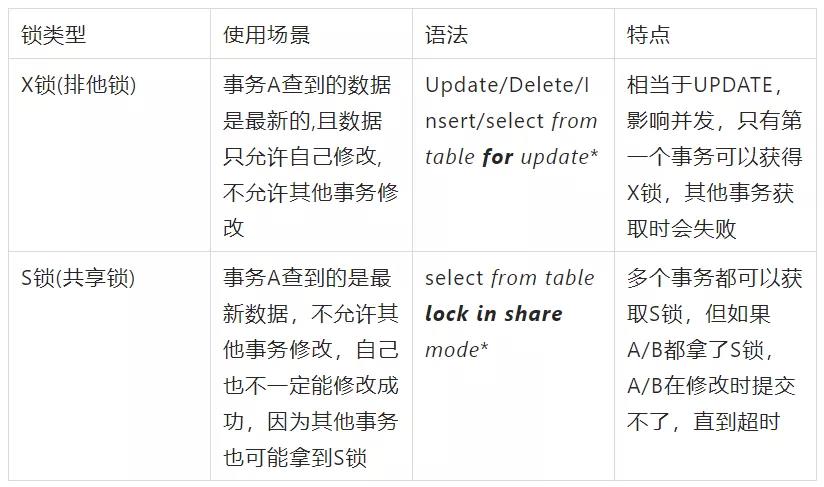
3.4.4.5 一条 SQL 的加锁分析
-- select操作均不加锁,采用的是快照读,因此在下面的讨论中就忽略了
SQL1:select * from t1 where id = 10;
SQL2:delete from t1 where id = 10;组合分为如下几种场景:

(1)组合 7 的 GAP 锁详解读
Insert 操作,如 insert [10,aa],首先会定位到[6,c]与[10,b]间,然后在插入前,会检查这个 GAP 是否已经被锁上,如果被锁上,则 Insert 不能插入记录。因此,通过第一遍的当前读,不仅将满足条件的记录锁上 (X 锁),与组合三类似。同时还是增加 3 把 GAP 锁,将可能插入满足条件记录的 3 个 GAP 给锁上,保证后续的 Insert 不能插入新的 id=10 的记录,也就杜绝了同一事务的第二次当前读,出现幻象的情况。
既然防止幻读,需要靠 GAP 锁的保护,为什么组合五、组合六,也是 RR 隔离级别,却不需要加 GAP 锁呢?
GAP 锁的目的,是为了防止同一事务的两次当前读,出现幻读的情况。而组合五,id 是主键;组合六,id 是 unique 键,都能够保证唯一性。
一个等值查询,最多只能返回一条记录,而且新的相同取值的记录,一定不会在新插入进来,因此也就避免了 GAP 锁的使用。
(2)结论
Repeatable Read 隔离级别下,id 列上有一个非唯一索引,对应 SQL:delete from t1 where id = 10; 首先,通过 id 索引定位到第一条满足查询条件的记录,加记录上的 X 锁,加 GAP 上的 GAP 锁,然后加主键聚簇索引上的记录 X 锁,然后返回;然后读取下一条,重复进行。直至进行到第一条不满足条件的记录[11,f],此时,不需要加记录 X 锁,但是仍旧需要加 GAP 锁,最后返回结束。
什么时候会取得 gap lock 或 nextkey lock 这和隔离级别有关,只在 REPEATABLE READ 或以上的隔离级别下的特定操作才会取得 gap lock 或 nextkey lock。
3.4.5 线上问题处理
3.4.5.1 观察问题的几个常见库表
首先可以通过下属两个命令来查看 mysql 的相应的系统变量和状态变量。
# status代表当前系统的运行状态,只能查看,不能修改
show status like '%abc%';
show variables like '%abc%';MySQL 5.7.6 开始后改成了从如下表获取:
performance_schema.global_variables
performance_schema.session_variables
performance_schema.variables_by_thread
performance_schema.global_status
performance_schema.session_status
performance_schema.status_by_thread
performance_schema.status_by_account
performance_schema.status_by_host
performance_schema.status_by_user之前是从如下表获取:
INFORMATION_SCHEMA.GLOBAL_VARIABLES
INFORMATION_SCHEMA.SESSION_VARIABLES
INFORMATION_SCHEMA.GLOBAL_STATUS
INFORMATION_SCHEMA.SESSION_STATUS比较常用的系统变量和状态变量有:
# 查询慢SQL查询是否开启
show variables like 'slow_query_log';
# 查询慢SQL的时间
show variables like 'long_query_time';
# 查看慢SQL存放路径,一般:/home/mysql/data3016/mysql/slow_query.log
show variables like 'slow_query_log_file';
# 查看数据库的事务隔离级别,RDS:READ-COMMITTED Mysql:Repeatable read
show variables like 'tx_isolation';
# innodb数据页大小 16384
show variables like 'innodb_page_size';
show status like 'innodb_row_%';
# 查看慢SQL
SHOW SLOW limit 10;
show full slow limit 10;
# 查看autocommit配置
select @@autocommit;
# 同上
show variables like 'autocommit';
#设置SQL自动提交模式 1:默认,自动提交 0:需要手动触发commit,否则不会生效
set autocommit=1;
# 查看默认的搜索引擎
show variables like '%storage_engine%';
# 设置事务隔离级别
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;
3.5 一些建议
3.5.1 小表驱动大表
nb_soft_nature:小表
nb_soft:大表
package_name:都是索引
MySQL 表关联的算法是 Nest Loop Join(嵌套循环连接),是通过驱动表的结果集作为循环基础数据,然后一条一条地通过该结果集中的数据作为过滤条件到下一个表中查询数据,然后合并结果。
(1)小表驱动大表
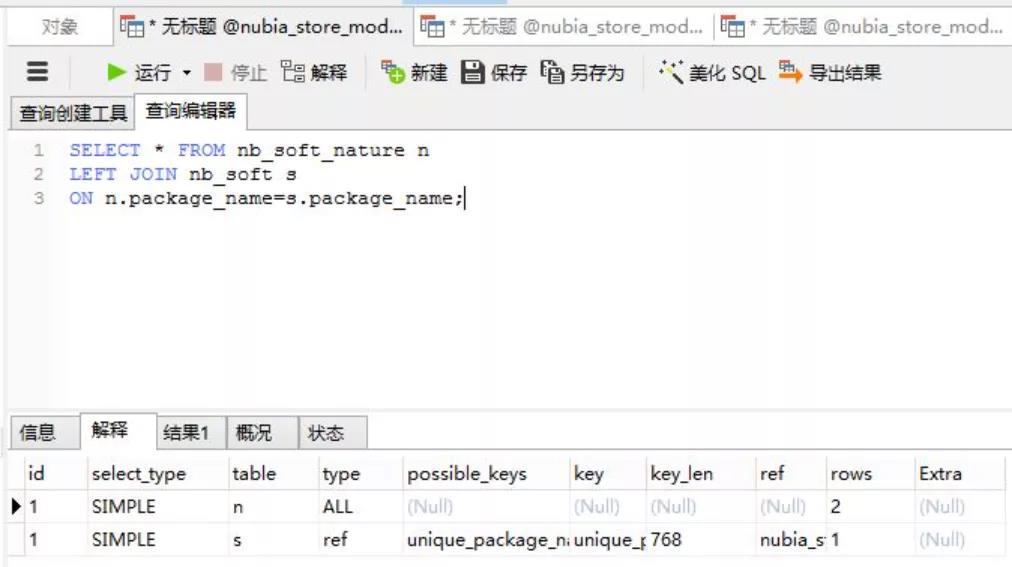
nb_soft_nature 中只有 24 条数据,每条数据的 package_name 连接到 nb_soft 表中做查询,由于 package_name 在 nb_soft 表中有索引,因此一共只需要 24 次扫描即可。
(2)大表驱动小表
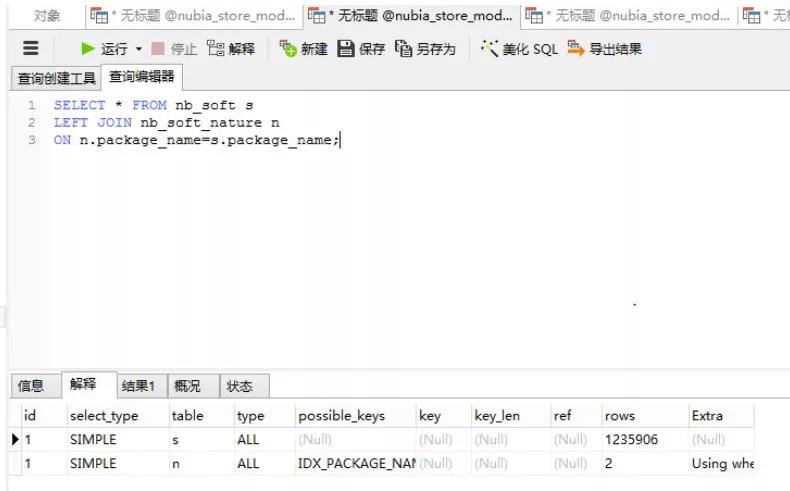
同上,需要 100 多万次扫描才能返回结果
3.5.2 使用自增长主键
结合 B+Tree 的特点,自增主键是连续的,在插入过程中尽量减少页分裂,即使要进行页分裂,也只会分裂很少一部分。并且能减少数据的移动,每次插入都是插入到最后。总之就是减少分裂和移动的频率。
四 Redis
4.1 问题处理思路
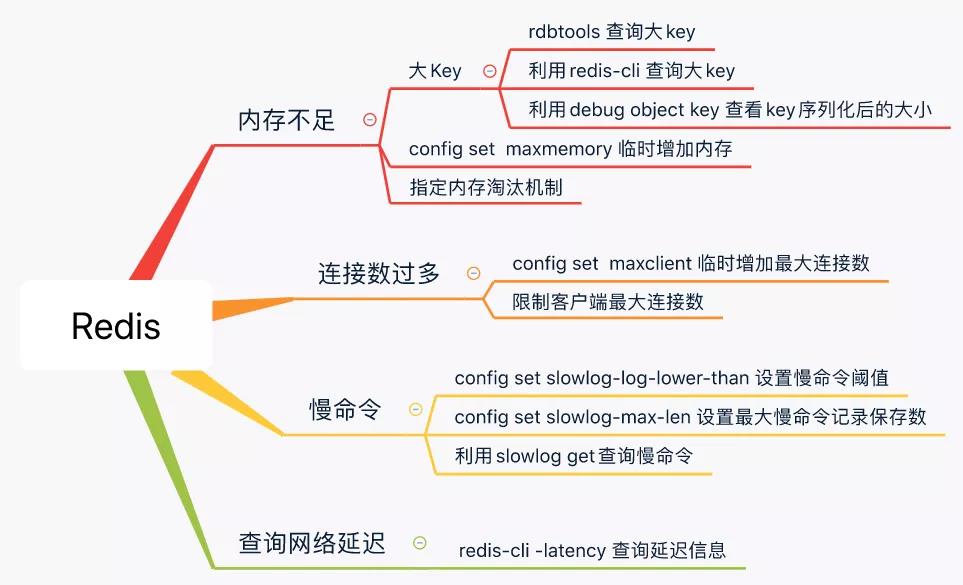
4.2 内存告警
时常会出现下述异常提示信息:
OOM command not allowed when used memory
4.2.1 设置合理的内存大小
设置 maxmemory 和相对应的回收策略算法,设置最好为物理内存的 3/4,或者比例更小,因为 redis 复制数据等其他服务时,也是需要缓存的。以防缓存数据过大致使 redis 崩溃,造成系统出错不可用。
(1)通过 redis.conf 配置文件指定
maxmemory xxxxxx
(2)通过命令修改
config set maxmemory xxxxx
4.2.2 设置合理的内存淘汰策略
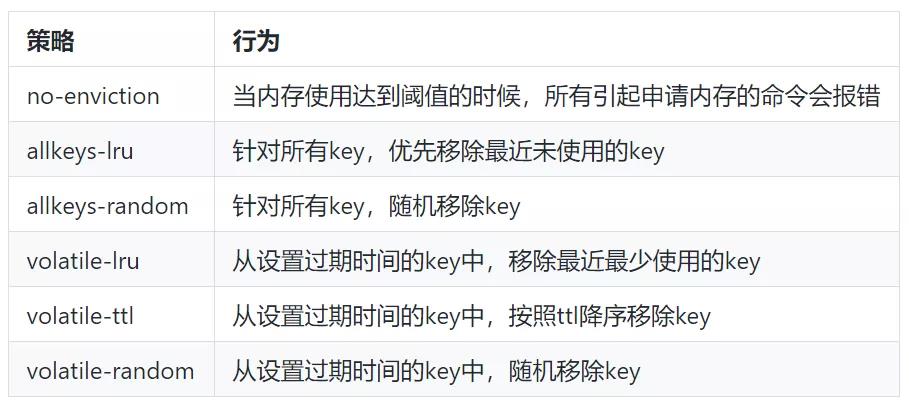
(1)通过 redis.conf 配置文件指定
maxmemory-policy allkeys-lru
4.2.3 查看大 key
(1)有工具的情况下:
安装工具 dbatools redisTools,列出最大的前 N 个 key
/data/program/dbatools-master/redisTools/redis-cli-new -h <ip> -p <port> --bigkeys --bigkey-numb 3
得到如下结果:
Sampled 122114 keys in the keyspace!
Total key length in bytes is 3923725 (avg len 32.13)
Biggest string Key Top 1 found 'xx1' has 36316 bytes
Biggest string Key Top 2 found 'xx2' has 1191 bytes
Biggest string Key Top 3 found 'xx3' has 234 bytes
Biggest list Key Top 1 found 'x4' has 204480 items
Biggest list Key Top 2 found 'x5' has 119999 items
Biggest list Key Top 3 found 'x6' has 60000 items
Biggest set Key Top 1 found 'x7' has 14205 members
Biggest set Key Top 2 found 'x8' has 292 members
Biggest set Key Top 3 found 'x,7' has 21 members
Biggest hash Key Top 1 found 'x' has 302939 fields
Biggest hash Key Top 2 found 'xc' has 92029 fields
Biggest hash Key Top 3 found 'xd' has 39634 fields原生命令为:
/usr/local/redis-3.0.5/src/redis-cli -c -h <ip> -p <port> --bigkeys
分析 rdb 文件中的全部 key/某种类型的占用量:
rdb -c memory dump.rdb -t list -f dump-formal-list.csv
查看某个 key 的内存占用量:
[root@iZbp16umm14vm5kssepfdpZ redisTools]# redis-memory-for-key -s <ip> -p <port> x
Key x
Bytes 4274388.0
Type hash
Encoding hashtable
Number of Elements 39634
Length of Largest Element 29(2)无工具的情况下可利用以下指令评估 key 大小:
debug object key
4.3 Redis 的慢命令
4.3.1 设置 Redis 的慢命令的时间阈值(单位:微妙)
(1)通过 redis.conf 配置文件方式
# 执行时间大于多少微秒(microsecond,1秒 = 1,000,000 微秒)的查询进行记录。
slowlog-log-lower-than 1000
# 最多能保存多少条日志
slowlog-max-len 200(2)通过命令方式
# 配置查询时间超过1毫秒的, 第一个参数单位是微秒
config set slowlog-log-lower-than 1000
# 保存200条慢查记录
config set slowlog-max-len 2004.3.2 查看 Redis 的慢命令
slowlog get