字节跳动异构场景下的高可用建设实践
Posted CSDN资讯
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了字节跳动异构场景下的高可用建设实践相关的知识,希望对你有一定的参考价值。
本文首发于:火山引擎开发者社区;
作者:字节跳动基础架构团队系统治理方向负责人邵育亮
本文主要为大家介绍字节跳动在高可用建设上的一些思考和落地经验。先给大家简单介绍一下系统治理团队是做什么的。系统治理团队在基础架构团队内部,主要负责字节跳动研发的闭环生态:从服务开发,到大规模微服务架构下的联调、开发以及对应的发布,再到上线以后的微服务治理、对应的流量调度、容量分析,以及到最后通过混沌工程的建设帮助业务提升高可用能力。接下来就进入正题。首先介绍一下字节跳动混沌工程建设的背景。大家知道字节跳动有很多 APP,我们有非常多的服务,这些服务大致可以分成三个类型:
- 在线服务:大家可以理解成支持抖音、西瓜视频等的后端服务。这些服务的特点是它们跑在我们自建的大规模 K8s 上的 PaaS 集群上,这是一套非常大的微服务架构。
- 离线服务:包括一些推荐模型的 training,大数据的 report 计算等等,都属于离线服务。它们依赖大规模的存储和计算的能力。
- 基础架构:承载了字节中国的所有业务线,向上提供一套 PaaS 化的能力,包括计算和存储等,支撑各种业务不同的使用场景。
不同的服务体系对高可用的关注度并不一样。我们简单做一下分析:
- 在线服务:本身是无状态服务,运行在 K8s 容器上,其存储都在外部的 mysql、Redis。这些无状态服务很方便做扩容,在发生故障时能尽可能容错,当然也可能会做一些降级。
- 离线服务:有状态服务,很关注计算的状态。大数据的计算服务特点是运行时间很长,Training、model 的时间都特别长。它能容忍一些错误(如果某次 job 挂了,可以进行 retry),其更多状态的一致性、数据的完整性是依赖底层存储系统的支持。所以我们在离线服务的高可用建设,很大规模依赖于整个基础架构提供的高可用能力。
- 基础架构:基础架构本身是有状态的,它是进行大规模存储、计算的平台,可能会遇到一些网络故障、磁盘故障等灰天鹅事件,这其中我们关注较多的是数据一致性。
应对不同的服务类型,系统治理团队负责高可用的同学提出了不同的解决方案。在这里先给大家介绍我们应对在线服务(无状态服务)时混沌工程的演进。
在线服务的混沌工程演进
混沌工程平台 1.0 架构我们认为我们的混沌工程平台 1.0 版本还不是一个混沌工程系统,更多的是一个故障注入系统。
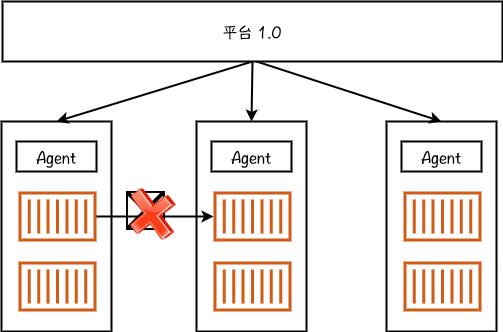
上图是我们这个平台 1.0 版本的架构。这个平台面向用户提供可视化界面,可进行故障注入和一些简单的配置。在底层物理机上我们装了 Agent。Agent 运行在宿主机上,可实现容器间网络相关的故障注入。对于服务稳态,我们在做混沌演练的时候,在平台上可以注入一些 metrics,用户可以写一个 bosun 语句去查询 metrics,我们提供一个阈值,系统就会轮询这个 metrics 来判定服务是否达到稳定的状态。如果超出边界,我们就进行故障恢复。如果没有超出边界,就继续演练,看是否能达到预期。为什么这个系统不能称之为一个混沌工程的系统?Netflix 的 Principle of Chaos 对混沌工程的定义(http://principlesofchaos.org/) 有五大原则:
- 建立一个围绕稳定状态行为的假说
- 多样化真实世界的事件
- 在生产环境中运行实验
- 持续自动化运行实验
- 最小化爆炸半径控制
对比以上五个原则,我们来看一下为什么说这个平台只是个故障注入系统。
- 首先整体的稳态还相对比较简陋。
- 实际的微服务架构中会存在各种故障,这个平台中只做到了比较简单的故障注入,如故障延迟、断网等。
- 在生产环境进行演练是当时能做到的事情。
- 因为稳态比较简陋,所以很难真正评估这个系统是不是稳定,系统也无法自动化运行实验。
- 整个系统声明 scale 的 scope 做的不是特别好。另外当时技术实现的结构是在物理机的宿主机上做故障注入,本身有一定的隐患,爆炸半径控制做得也不是特别好。
混沌工程平台 2.0 架构
在 2019 年的时候,我们开始想把混沌工程平台 1.0 版本演进到下一代,希望能够做一个真正符合混沌工程标准的系统,因此有了平台的 2.0 版本,我们认为它是字节跳动真正意义上的第一个混沌工程系统。
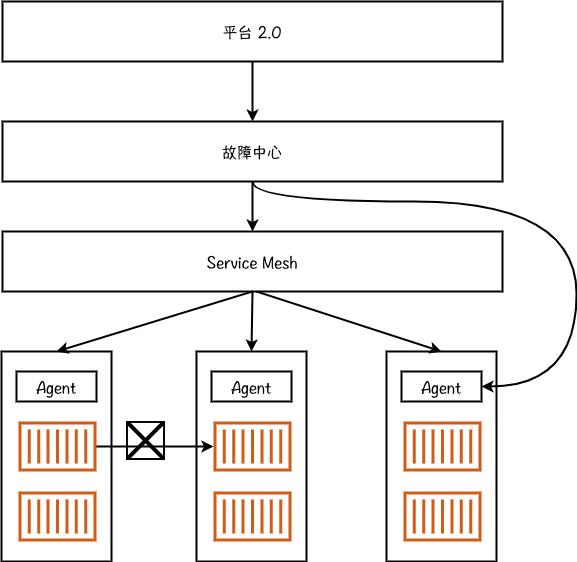
混沌工程平台 2.0 版本的一些升级:
- 架构升级:引入了一个故障中心层,解耦了业务逻辑和底层故障注入。
- 故障注入:随着 Service Mesh 更大规模的应用,网络调用相关的故障更多基于 sidecar 实现。
- 稳定性模型:这个阶段我们也构建了一个稳态系统,基于服务的关键指标和机器学习等算法实现稳态计算。我们非常关注稳态系统,认为真正的自动化演练是不需要人工干预的,所以需要一个系统来识别被演练的系统是否稳定。如果系统只看到一堆 metrics,它很难直接去认知系统的稳定性。我们希望通过一些特定算法将这些 metrics 聚合成一个百分位指标,假设这个指标达到 90 分,我们就认为它是稳定的。后文还会再介绍我们怎么在这个稳态系统里面做算法的投入。
故障中心架构
我们的故障中心借鉴了 K8s 的架构。
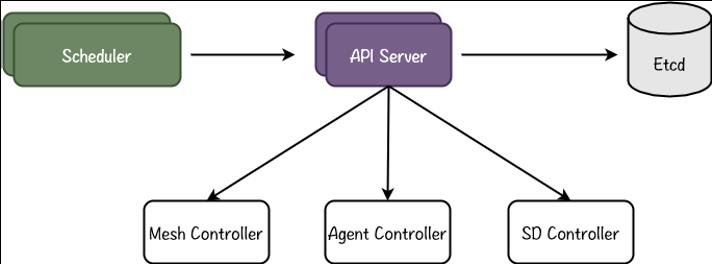
混沌工程平台 1.0 系统有一个问题:假设通过 Agent 在 K8s 里成功注入了一个延迟故障。但 K8s 本身有弹性调度能力,如果很不幸在演练过程中这个服务 crash 了,K8s 会自动在另外一个机器上把这个 Pod 启起来。这种情况下,你以为故障演练是成功的,但其实没有成功,而是重新起了新的服务。故障中心可以在容器发生漂移的时候继续注入故障。所以我们是一套声明式的 API,声明的不是要注入什么故障,而是描述服务器的一种状态,例如 A 跟 B 之间的网络是断开的,那么在任何状态下故障中心要保证 A 和 B 是断开状态。其次,整个系统借鉴 K8s 的架构,有丰富的 controller 支持底层不同的故障注入能力。在对业务的快速需求的支持过程中,我们在 controller 里能很快接入 Chaos Mesh、Chaos Blade 等开源项目。我们自己也原生做了一些 controller,比如 service mesh controller,agent controller,服务发现的 controller 等。
爆炸半径控制
前面提到故障中心是通过声明式 API 注入故障,我们就需要定义故障注入 model。
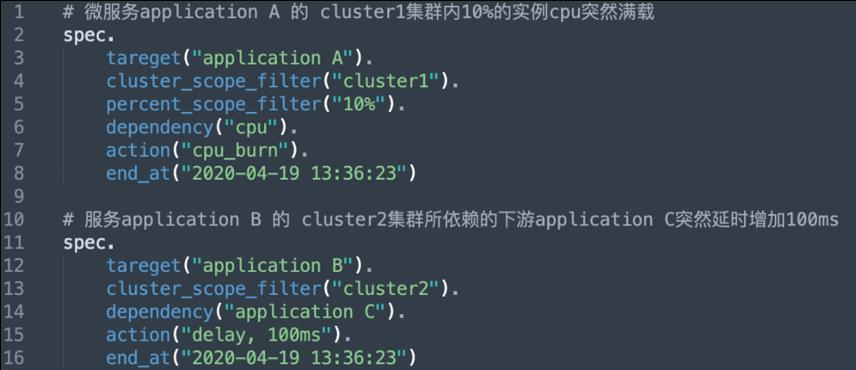
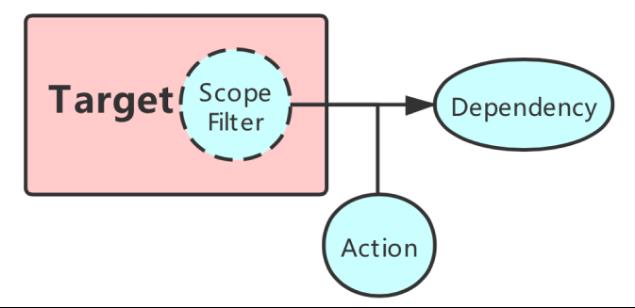
如上图所示:
- Target:表示要注入故障的目标服务。
- Scope Filter:对于爆炸半径控制,很重要的一点是我们希望能够让业务去帮助声明希望演练的 scope,我们称为 Scope Filter。通过 Scope Filter 能定义故障注入的目标,可以是一个机房,一个集群,一个可用区,甚至精确到实例级别乃至流量级别。
- Dependency:它是所有可能影响服务本身的异常来源,包括中间件,某下游服务,也包括所依赖的 CPU、磁盘、网络等。
- Action:故障事件,即发生了何种故障,比如下游服务返回拒绝、发生丢包;又比如磁盘写异常、CPU 被抢占等。
所以在故障中心声明故障时,需要描述上述内容,表明业务希望系统中是怎样的故障状态。
稳态系统
稳态系统会涉及一些算法的工作,这里主要介绍三个算法的场景:
- 时序序列的动态分析:我们叫稳态算法,可以尝试分析服务是否稳定。其中使用了阈值检测、3 Sigma 原则、稀疏规则等算法。
- AB 对比稳态分析:借鉴了 Netflix 在用的曼-惠特尼 U 检验,大家可以看一些相关 paper 和文章介绍。
- 检测机制:使用指标波动一致性检测算法,用来分析强弱依赖。
通过以上这些算法(还有其他算法),稳态系统能够去很好地刻画系统稳定性。
自动化演练
我们将自动化演练定义为完全不需要人工干预,由系统进行故障注入,在注入过程、演变过程中分析服务的稳定性,随时止损或拿到结果。我们现在进行自动化演练有这样一些前提:
- 能够明确演练的实际场景的目标;
- 通过稳态系统,对稳态假设具备自动化判断能力;
- 能够通过声明式 API、Scope Filter 控制混沌演练的影响范围,实验过程生产损失极小。
自动化演练目前主要的应用场景是强弱依赖分析,包括:
- 强弱依赖现状与业务标注是否一致;
- 弱依赖超时是否会拖垮整体链路。
总结
现在我们再来回顾一下,为什么我们认为混沌工程平台 2.0 版本是一个混沌工程系统。还是对比前文提到的五个原则:
- 建立一个围绕稳定状态的假说:通过稳态系统已经开启了稳态假说的演进。
多样化真实世界的事件:现在故障分层上更加合理,补充了大量中间件故障和底层故障。 - 在生产环境中运行试验:这一点在 1.0 时期就实现了,2.0 中进行了扩展,可支持生产环境、预发环境、本地测试环境的各种故障演习。
- 持续自动化运行试验:提供 csv、sdk、api 等能力,让业务线在自己希望的服务发布流程中持续跟功能做整合。我们也提供了 API 能力,帮助业务线在需要的环境做故障注入。
- 最小化爆炸半径:提供声明式 API 的能力,其中一个原因就是为了控制爆炸半径。
支撑底层系统演练的基础设施混沌平台
前面提到了离线服务很大程度上依赖底层状态的一致性,所以如果把基础架构中存储、计算做好,就能够很好地支撑业务。我们用一个新的基础设施混沌平台来做一些内部的实验性尝试。对于基础架构的混沌工程,我们要打破一下混沌工程的一些标准原则。
- 首先针对基础架构的混沌工程不太适合在生产环境演练,因为它依赖于底层的故障注入,影响面非常大,爆炸半径不好控制。
- 在自动化演练上,业务方需要更加灵活的能力,进一步跟他们的 CI/CD 打通,也需要更加复杂的编排需求。
- 对于稳态模型,除了稳定性之外,我们更关注一致性。
要支持离线环境的混沌工程,该基础设施混沌平台给了我们一个安全的环境,让我们能够在里面展开手脚做更多的故障注入,比如 CPU、Memory、File system 等系统资源故障;拒绝、丢包等网络故障;以及包括时钟跳变、进程被杀、代码级异常、文件系统级方法 error hook 在内的其他故障。对于自动化演练的自动化编排,我们希望通过这个平台给用户更加灵活的编排能力,例如:
- 串并行任务执行
- 随时暂停 & 断点恢复
- 基础设施主从节点识别
我们也提供了一些插件能力,让一些组件团队能够更灵活地注入故障。有的业务团队可能在自己的系统里已经埋点了一些 hook,他们希望这个系统能够更直接地帮助注入故障,同时也希望复用我们的编排体系和平台体系。我们通过 hook 的方式,业务团队只需实现对应的 hook,就能够注入特定的故障,然后继续使用我们的整套编排体系和平台。
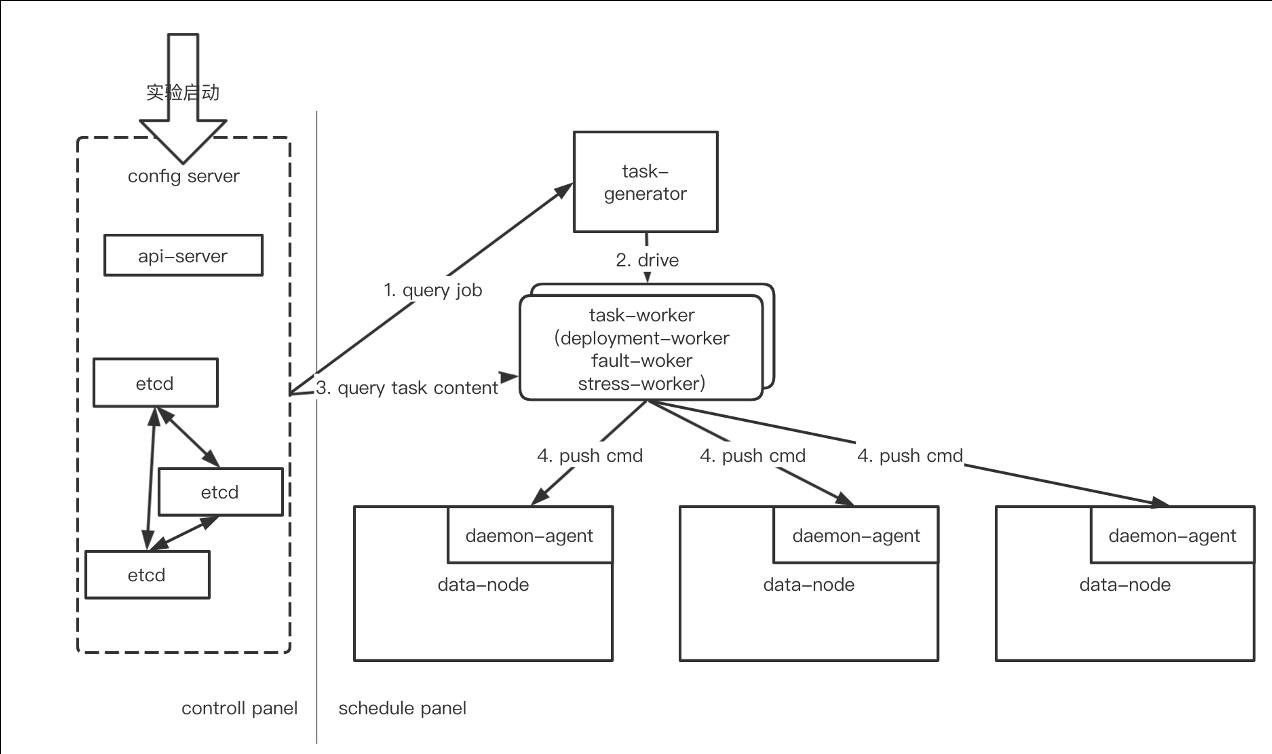
从混沌工程到系统高可用建设
我们最开始做 Chaos Engineering 的时候,对团队的使命定位是在字节跳动落地混沌工程。但是当我们做出一些能力找业务线使用的时候,会发现业务线对此并没有什么需求。后来我们努力思考之后调整了团队的使命:通过混沌工程或者其他一些手段帮助业务推进高可用建设。调整之后我们就从过去研究 Chaos Engineering 的业界发展,变成了要去贴着业务理解业务的高可用。我们如何帮助业务进行高可用建设呢?
什么是高可用
我们用下面这个公式来进行理解高可用。

- MTTR(Mean Time To Repair):平均修复时间
- MTBF(Mean Time Between Failure):平均失效间隔时间
- N:事故发生次数
- S:影响范围
这个公式的值明显小于 1,算出来应该是所谓的三个九、五个九。要让 A 的值足够大,需要:
- MTTRNS 的值足够小。所以需要降低 MTTR,降低事故发生次数,缩小故障范围。
- MTBF 的值变大。即尽可能拉开两次故障之间的间隔。
如何降低 MTTR、N、S 呢?
降低故障影响范围(S)
当面向生产架构的故障发生的时候,要降低故障影响范围,从架构侧可以采用一些设计手段:
- 单元化设计:用户请求隔离
- 多机房部署:系统资源隔离
- 核心业务独立部署:业务功能隔离
- 异步化处理
在这里,混沌工程可以做的事情是帮助 SRE 团队验证这些架构设计是否符合预期。
减少故障发生次数(N)
这里要重新定义一下故障。Failure 是不可避免的,我们要尽可能在软件系统的架构层避免 Failure 转换成 Error。如何降低从 Failure 到 Error 的转换率?最重要的是加强系统的容错性,包括:
- 部署:异地多活,流量灵活调度,服务兜底,预案管理;
- 服务治理:超时配置,熔断 fail fast。
这其中混沌工程起到的作用帮助验证系统容错能力。
降低平均修复时间(MTTR)
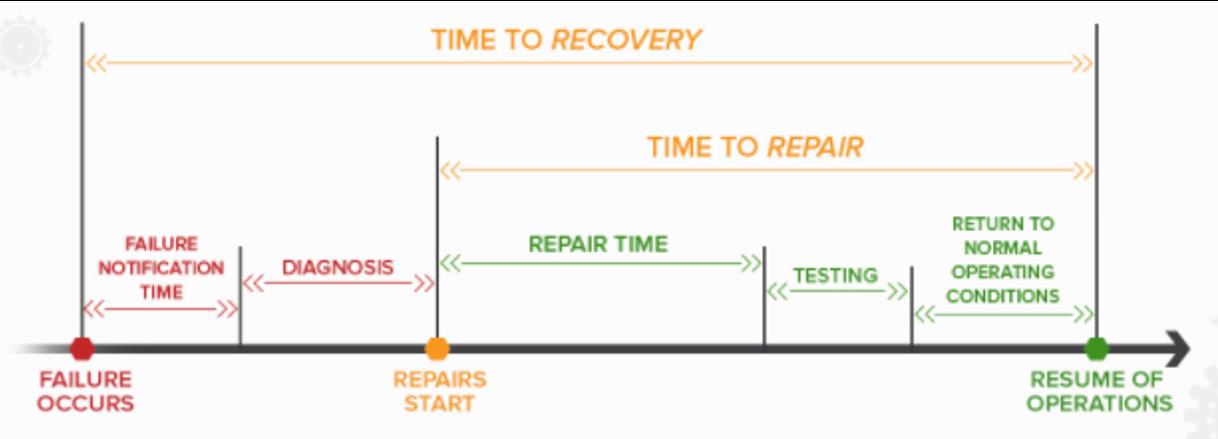
上图展示了 MTTR 涉及的一些因素:Fail Notification、诊断、修复、测试、最终上线等所需的时间。要降低 MTTR 可以对每个涉及的因素加入一些设计手段:
- 充分的监控告警覆盖。需要推动业务进行告警的治理。
- 在告警充分覆盖的同时保证告警的准确性。
- 高效定位,加强排障能力。目前我们跟内部的 AIOps 团队合作,做进一步的智能化障碍分析,降低诊断时间。
- 快速止损预案。从修复到测试再到最终上线,需要有一个预案系统,根据诊断的故障特征备有预案库,做到点击按钮即可选择准确的预案做恢复。
- 这其中混沌工程可做的是进行应急响应演练。其实演练不只是针对系统,也是演练- 组织里每个人的应急能力。当面临事故时,团队可以有一套标准的 workflow 去发现问题、定位问题、解决问题,这也混沌工程系统希望演练达到的效果。
后续规划
最后介绍一下我们在高可用、混沌工程方面的后续规划,主要有三个方面:
- 故障精细化能力建设
- 面向不同体系故障分层建设
- 丰富各层故障能力
- 丰富混沌工程的使用场景
- 继续探索自动化场景
- 降低用户接入和使用成本,打造轻量级平台
- 扩展混沌工程内涵
- 回归可用性视角,持续探索混沌工程与高可用的关系
- 建立故障预算机制,通过量化故障损失进行预测和分析,从而协助决策在混沌工程的投入
以上是关于字节跳动异构场景下的高可用建设实践的主要内容,如果未能解决你的问题,请参考以下文章