Spark2.4.7源码解读RDD依赖关系
Posted <一蓑烟雨任平生>
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark2.4.7源码解读RDD依赖关系相关的知识,希望对你有一定的参考价值。
(1)概述
Spark中RDD的高效与DAG(有向无环图)有很大的关系,在DAG调度中需要对计算的过程划分Stage,划分的依据就是RDD之间的依赖关系。RDD之间的依赖关系分为两种,宽依赖(ShuffleDependency)和窄依赖(NarrowDependency)
依赖在 Apache Spark 源码中的对应实现是 Dependency 抽象类。
/**
* :: DeveloperApi ::
* Base class for dependencies.
*/
@DeveloperApi
abstract class Dependency[T] extends Serializable {
def rdd: RDD[T]
}
每个 Dependency 子类内部都会存储一个 RDD 对象,对应一个父 RDD,如果一次转换转换操作有多个父 RDD,就会对应产生多个 Dependency 对象,所有的 Dependency 对象存储在子 RDD 内部,通过遍历 RDD 内部的 Dependency 对象,就能获取该 RDD 所有依赖的父 RDD。
Dependency 有两个实现类:抽象类NarrowDependency(窄依赖)和 ShuffleDependency(宽依赖)。
(2)窄依赖
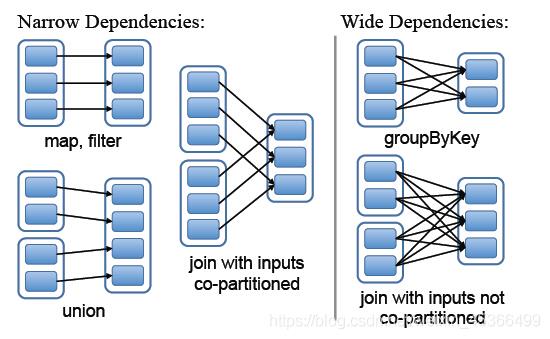
窄依赖:父RDD的分区最多只会被子RDD的一个分区使用。 如图左面部分
窄依赖的实现在 NarrowDependency 抽象类中:
/**
* :: DeveloperApi ::
* Base class for dependencies where each partition of the child RDD depends on a small number
* of partitions of the parent RDD. Narrow dependencies allow for pipelined execution.
*/
@DeveloperApi
abstract class NarrowDependency[T](_rdd: RDD[T]) extends Dependency[T] {
/**
* Get the parent partitions for a child partition.
* @param partitionId a partition of the child RDD
* @return the partitions of the parent RDD that the child partition depends upon
*/
def getParents(partitionId: Int): Seq[Int]
override def rdd: RDD[T] = _rdd
}
NarrowDependency 要求子类实现 getParent 方法,用于获取一个分区数据来源于父 RDD 中的哪些分区(虽然要求返回 Seq[Int],实际上却只有一个元素),其输入参数是子RDD 的 分区Id,输出是子RDD 分区依赖的父RDD 的 partition 的 id 序列。。
窄依赖有分为两种:
- 一对一依赖OneToOneDependency,比如map、filter等
- 范围依赖RangeDependency,比如union
(2.1)一对一依赖
OneToOneDependency源码如下:
/**
* :: DeveloperApi ::
* Represents a one-to-one dependency between partitions of the parent and child RDDs.
*/
@DeveloperApi
class OneToOneDependency[T](rdd: RDD[T]) extends NarrowDependency[T](rdd) {
override def getParents(partitionId: Int): List[Int] = List(partitionId)
}
一对一依赖表示子 RDD 分区的编号与父 RDD 分区的编号完全一致的情况,若两个 RDD 之间存在着一对一依赖,则子 RDD 的分区个数、分区内记录的个数都将继承自父 RDD。
(2.2)范围依赖
RangeDependency源码如下:
/**
* :: DeveloperApi ::
* Represents a one-to-one dependency between ranges of partitions in the parent and child RDDs.
* @param rdd the parent RDD
* @param inStart the start of the range in the parent RDD
* @param outStart the start of the range in the child RDD
* @param length the length of the range
*/
@DeveloperApi
class RangeDependency[T](rdd: RDD[T], inStart: Int, outStart: Int, length: Int)
extends NarrowDependency[T](rdd) {
override def getParents(partitionId: Int): List[Int] = {
if (partitionId >= outStart && partitionId < outStart + length) {
List(partitionId - outStart + inStart)
} else {
Nil
}
}
}
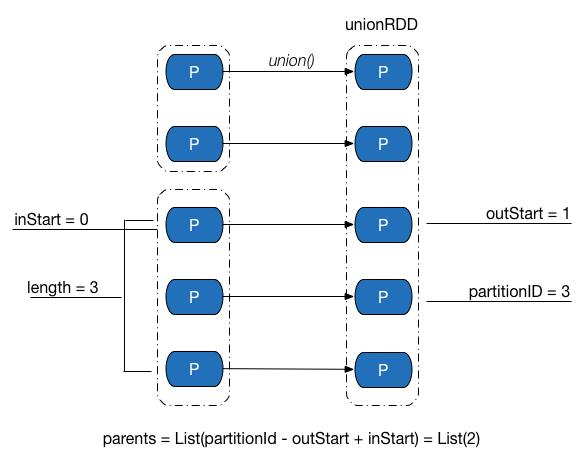
首先解释三个变量:inStart:父RDD range 的起始位置;outStart:子RDD range 的起始位置;length:range 的长度。
获取 父RDD 的partition index 的规则是:如果子RDD 的 partition index 在父RDD 的range 内,则返回的 父RDD partition是 子RDD partition index - 父 RDD 分区range 起始 + 子RDD 分区range 起始。其中,(- 父 RDD 分区range 起始 + 子RDD 分区range 起始)即 子RDD 的分区的 range 起始位置和 父RDD 的分区的 range 的起始位置 的相对距离。子RDD 的 parttion index 加上这个相对距离就是 对应父的RDD partition。否则是无依赖的父 RDD 的partition index。父子RDD的分区关系是一对一的。RDD 的关系可能是一对一(length 是1 ,就是特殊的 OneToOneDependency),也可能是多对一,也可能是一对多。
(3)宽依赖
宽依赖:父RDD的一个分区会被子RDD的多个分区使用
例如reduceByKey、reparttition、sortByKey等算子
Shuffle 依赖的对应实现为 ShuffleDependency 类,其源码如下:
/**
* :: DeveloperApi ::
* Represents a dependency on the output of a shuffle stage. Note that in the case of shuffle,
* the RDD is transient since we don't need it on the executor side.
*
* @param _rdd the parent RDD
* @param partitioner partitioner used to partition the shuffle output
* @param serializer [[org.apache.spark.serializer.Serializer Serializer]] to use. If not set
* explicitly then the default serializer, as specified by `spark.serializer`
* config option, will be used.
* @param keyOrdering key ordering for RDD's shuffles
* @param aggregator map/reduce-side aggregator for RDD's shuffle
* @param mapSideCombine whether to perform partial aggregation (also known as map-side combine)
*/
@DeveloperApi
class ShuffleDependency[K: ClassTag, V: ClassTag, C: ClassTag](
@transient private val _rdd: RDD[_ <: Product2[K, V]],
val partitioner: Partitioner,
val serializer: Serializer = SparkEnv.get.serializer,
val keyOrdering: Option[Ordering[K]] = None,
val aggregator: Option[Aggregator[K, V, C]] = None,
val mapSideCombine: Boolean = false)
extends Dependency[Product2[K, V]] {
if (mapSideCombine) {
require(aggregator.isDefined, "Map-side combine without Aggregator specified!")
}
override def rdd: RDD[Product2[K, V]] = _rdd.asInstanceOf[RDD[Product2[K, V]]]
private[spark] val keyClassName: String = reflect.classTag[K].runtimeClass.getName
private[spark] val valueClassName: String = reflect.classTag[V].runtimeClass.getName
// Note: It's possible that the combiner class tag is null, if the combineByKey
// methods in PairRDDFunctions are used instead of combineByKeyWithClassTag.
private[spark] val combinerClassName: Option[String] =
Option(reflect.classTag[C]).map(_.runtimeClass.getName)
val shuffleId: Int = _rdd.context.newShuffleId()
val shuffleHandle: ShuffleHandle = _rdd.context.env.shuffleManager.registerShuffle(
shuffleId, _rdd.partitions.length, this)
_rdd.sparkContext.cleaner.foreach(_.registerShuffleForCleanup(this))
}
ShuffleDependency 类中几个成员的作用如下:
- rdd:用于表示 Shuffle 依赖中,子 RDD 所依赖的父 RDD。
- shuffleId:Shuffle 的 ID 编号,在一个 Spark 应用程序中,每个 Shuffle 的编号都是唯一的。
- shuffleHandle:Shuffle 句柄,ShuffleHandle 内部一般包含 Shuffle ID、Mapper 的个数以及对应的 Shuffle 依赖,在执行 ShuffleMapTask 时候,任务可以通过 ShuffleManager 获取得到该句柄,并进一步得到 Shuffle 相关信息。
- partitioner:分区器,用于决定 Shuffle 过程中 Reducer 的个数(实际上是子 RDD 的分区个数)以及 Map 端的一条数据记录应该分配给哪一个 Reducer,也可以被用在 CoGroupedRDD 中,确定父 RDD 与子 RDD 之间的依赖关系类型。
- serializer:序列化器。用于 Shuffle 过程中 Map 端数据的序列化和 Reduce 端数据的反序列化。
- KeyOrdering:键值排序策略,用于决定子 RDD 的一个分区内,如何根据键值对 类型数据记录进行排序。
- Aggregator:聚合器,内部包含了多个聚合函数,比较重要的函数有 createCombiner:V => C,mergeValue: (C, V) => C 以及 mergeCombiners: (C, C) => C。例如,对于 groupByKey 操作,createCombiner 表示把第一个元素放入到集合中,mergeValue 表示一个元素添加到集合中,mergeCombiners 表示把两个集合进行合并。这些函数被用于 Shuffle 过程中数据的聚合。
- mapSideCombine:用于指定 Shuffle 过程中是否需要在 map 端进行 combine 操作。如果指定该值为 true,由于 combine 操作需要用到聚合器中的相关聚合函数,因此 Aggregator 不能为空,否则 Apache Spark 会抛出异常。例如:groupByKey 转换操作对应的ShuffleDependency 中,mapSideCombine = false,而 reduceByKey 转换操作中,mapSideCombine = true。
以上内容仅供参考学习,如有侵权请联系我删除!
如果这篇文章对您有帮助,左下角的大拇指就是对博主最大的鼓励。
您的鼓励就是博主最大的动力!
以上是关于Spark2.4.7源码解读RDD依赖关系的主要内容,如果未能解决你的问题,请参考以下文章