OLAP+星型模型+雪花模型
Posted Data+Science+Insight
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了OLAP+星型模型+雪花模型相关的知识,希望对你有一定的参考价值。
OLAP+星型模型+雪花模型
OLAP:联机分析技术( On-Line Analytical Processing)
OLTP:On-Line Transaction Processing联机事务处理过程
对没有使用过数据仓库的人,对这三个概念确实是有点混淆不清。包括我自己本身不是做数据仓库出身,所以实际上是从实践出发,理论基础是有点匮乏的。
OLAP(on-Line Analysis Processing)是使分析人员、管理人员或执行人员能够从多角度对信息进行快速、一致、交互地存取,从而获得对数据的更深入了解的一类软件技术。OLAP的核心概念是“维”(dimension),维是人们观察客观世界的角度,是一种高层次的类型划分。
OLAP的基本多维分析操作有钻取(roll up和drill down)、切片(slice)和切块(dice)、以及旋转(pivot)、drill acros、drill through等。
改变维的层次,变换分析的粒度。它包括向上钻取和向下钻取。roll up是在某一维上低层次的细节数据概括到高层次的汇总数据,或者减少维数;而drill down则相反,它从汇总数据深入到细节数据进行观察或增加新维。
在一部分维上选定值后,关心度量数据在剩余维上得分布。如果剩余的维只有两个,则是切片;如果有三个,则是切块。
OLAP有多种实现方法,根据存储数据的方式不同可以分为ROLAP、MOLAP、HOLAP

- ROLAP基于关系型数据库,它的OLAP引擎就是将用户的OLAP操作,如上钻下钻过滤合并等,转换成SQL语句提交到数据库中执行,并且提供聚集导航功能,根据用户操作的维度和度量将SQL查询定位到最粗粒度的事实表上去。
- MOLAP事先将汇总数据计算好,存放在自己特定的多维数据库中,用户的OLAP操作可以直接映射到多维数据库的访问,不通过SQL访问。
- HOLAP表示基于混合数据组织的OLAP实现(Hybrid OLAP)。如底层是关系型的,高层是多维矩阵型的。这种方式具有更好的灵活性。特点是将细节数据保留在关系型数据库的事实表中,但是聚合后的数据保存在cube中,聚合时需要比ROLAP更多的时间,查询效率比ROLAP高,但低于MOLAP。
ROLAP表示基于关系数据库的OLAP实现(Relational OLAP)。以关系数据库为核心,以关系型结构进行多维数据的表示和存储。ROLAP将多维数据库的多维结构划分为两类表:
对于层次复杂的维,为避免冗余数据占用过大的存储空间,可以使用多个表来描述,这种星型模式的扩展称为"雪花模式"。特点是将细节数据保留在关系型数据库的事实表中,聚合后的数据也保存在关系型的数据库中。这种方式查询效率最低,不推荐使用。
MOLAP表示基于多维数据组织的OLAP实现(Multidimensional OLAP)。以多维数据组织方式为核心,也就是说,MOLAP使用多维数组存储数据。多维数据在存储中将形成"立方块(Cube)"的结构,在MOLAP 中对"立方块"的"旋转"、"切块"、"切片"是产生多维数据报表的主要技术。特点是将细节数据和聚合后的数据均保存在cube中,所以以空间换效率,查询时效率高,但生成cube时需要大量的时间和空间。
HOLAP表示基于混合数据组织的OLAP实现(Hybrid OLAP)。如底层是关系型的,高层是多维矩阵型的。这种方式具有更好的灵活性。特点是将细节数据保留在关系型数据库的事实表中,但是聚合后的数据保存在cube中,聚合时需要比ROLAP更多的时间,查询效率比ROLAP高,但低于MOLAP。
在多维分析的商业智能解决方案中,根据事实表和维度表的关系,又可将常见的模型分为星型模型和雪花型模型。在设计逻辑型数据的模型的时候,就应考虑数据是按照星型模型还是雪花型模型进行组织。
当所有维表都直接连接到“ 事实表”上时,整个图解就像星星一样,故将该模型称为星型模型,如图 1 。
星型架构是一种非正规化的结构,多维数据集的每一个维度都直接与事实表相连接,不存在渐变维度,所以数据有一定的冗余,如在地域维度表中,存在国家 A 省 B 的城市 C 以及国家 A 省 B 的城市 D 两条记录,那么国家 A 和省 B 的信息分别存储了两次,即存在冗余。
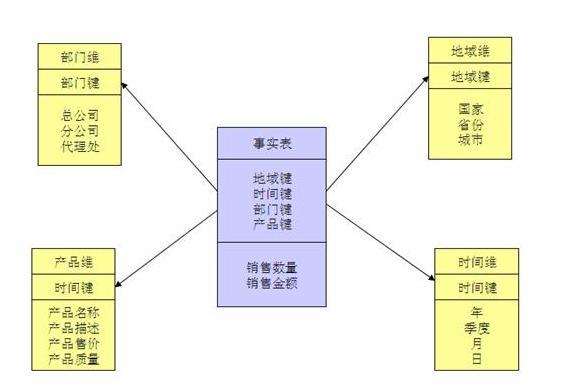
当有一个或多个维表没有直接连接到事实表上,而是通过其他维表连接到事实表上时,其图解就像多个雪花连接在一起,故称雪花模型。雪花模型是对星型模型的扩展。它对星型模型的维表进一步层次化,原有的各维表可能被扩展为小的事实表,形成一些局部的 " 层次 " 区域,这些被分解的表都连接到主维度表而不是事实表。如图 2,将地域维表又分解为国家,省份,城市等维表。它的优点是 : 通过最大限度地减少数据存储量以及联合较小的维表来改善查询性能。雪花型结构去除了数据冗余。

星型模型因为数据的冗余所以很多统计查询不需要做外部的连接,因此一般情况下效率比雪花型模型要高。星型结构不用考虑很多正规化的因素,设计与实现都比较简单。雪花型模型由于去除了冗余,有些统计就需要通过表的联接才能产生,所以效率不一定有星型模型高。正规化也是一种比较复杂的过程,相应的数据库结构设计、数据的 ETL、以及后期的维护都要复杂一些。因此在冗余可以接受的前提下,实际运用中星型模型使用更多,也更有效率。
星形模型(Star Schema)和雪花模型(Snowflake Schema)是数据仓库中常用到的两种方式,而它们之间的对比要从四个角度来进行讨论。
雪花模型使用的是规范化数据,也就是说数据在数据库内部是组织好的,以便消除冗余,因此它能够有效地减少数据量。通过引用完整性,其业务层级和维度都将存储在数据模型之中。

相比较而言,星形模型使用的是反规范化数据。在星形模型中,维度直接指的是事实表,业务层级不会通过维度之间的参照完整性来部署。
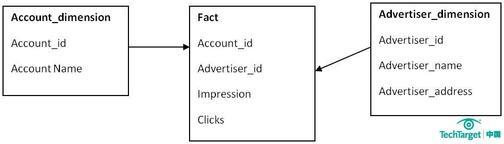
主键是一个单独的唯一键(数据属性),为特殊数据所选择。在上面的例子中,Advertiser_ID就将是一个主键。外键(参考属性)仅仅是一个表中的字段,用来匹配其他维度表中的主键。在我们所引用的例子中,Advertiser_ID将是Account_dimension的一个外键。
在雪花模型中,数据模型的业务层级是由一个不同维度表主键-外键的关系来代表的。而在星形模型中,所有必要的维度表在事实表中都只拥有外键。
第三个区别在于性能的不同。雪花模型在维度表、事实表之间的连接很多,因此性能方面会比较低。举个例子,如果你想要知道Advertiser 的详细信息,雪花模型就会请求许多信息,比如Advertiser Name、ID以及那些广告主和客户表的地址需要连接起来,然后再与事实表连接。
而星形模型的连接就少的多,在这个模型中,如果你需要上述信息,你只要将Advertiser的维度表和事实表连接即可。
雪花模型加载数据集市,因此ETL操作在设计上更加复杂,而且由于附属模型的限制,不能并行化。
星形模型加载维度表,不需要再维度之间添加附属模型,因此ETL就相对简单,而且可以实现高度的并行化。
雪花模型使得维度分析更加容易,比如“针对特定的广告主,有哪些客户或者公司是在线的?”星形模型用来做指标分析更适合,比如“给定的一个客户他们的收入是多少?”
参考:浅谈ROLAP、MOLAP和HOLAP区别
以上是关于OLAP+星型模型+雪花模型的主要内容,如果未能解决你的问题,请参考以下文章