深度神经网络识别垃圾邮件
Posted Neil-Yale
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度神经网络识别垃圾邮件相关的知识,希望对你有一定的参考价值。
电子邮件是较常用的网络应用之一,已经成为网络交流沟通的重要途径。但是,垃圾邮件(spam)烦恼着大多数人,调查显示,93%的被调查者都对他们接收到的大量垃圾邮件非常不满。一些简单的垃圾邮件事件也造成了很有影响的安全问题。
垃圾邮件给互联网以及广大的使用者带来了很大的影响,这种影响不仅仅是人们需要花费时间来处理垃圾邮件、占用系统资源等,同时也带来了很多的安全问题。
垃圾邮件占用了大量网络资源,这是显而易见的。一些邮件服务器因为安全性差,被作为垃圾邮件转发站为被警告、封IP等事件时有发生,大量消耗的网络资源使得正常的业务运作变得缓慢。随着国际上反垃圾邮件的发展,组织间黑名单共享,使得无辜服务器被更大范围屏蔽,这无疑会给正常用户的使用造成严重问题。
所以本次实验我们基于这一背景尝试通过DNN来实现垃圾邮件的识别。
关于DNN的介绍,我们从其组成部分、常见DNN模型、DNN处理的硬件着手进行学习。先来学习DNN的组成部分。
卷积神经网络:如下图所示,由多个卷积层组成(CONV),每个卷积层对各自的输入进行高阶抽象,这种高阶抽象被称为特征图(feature map,fmap)。CNN可以通过非常深的层级实现极高的性能。卷积神经网络被广泛应用在图像理解,语音识别,游戏,以及机器人学等。图5(b)介绍了CNN卷积的过程,CNN中的每个卷积层主要由高维卷积构成。输入为一系列二维特征图(input feature map),特征图的个数被称为通道,这里有C个通道。卷积层输出的每个点都是所有通道卷积之和。卷积层输出的通道数取决于滤波器的个数,本例中有M个滤波器,因此输出特征图为M通道。
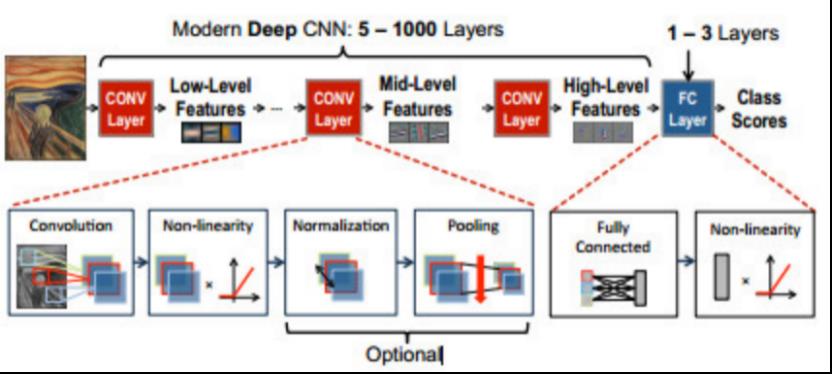
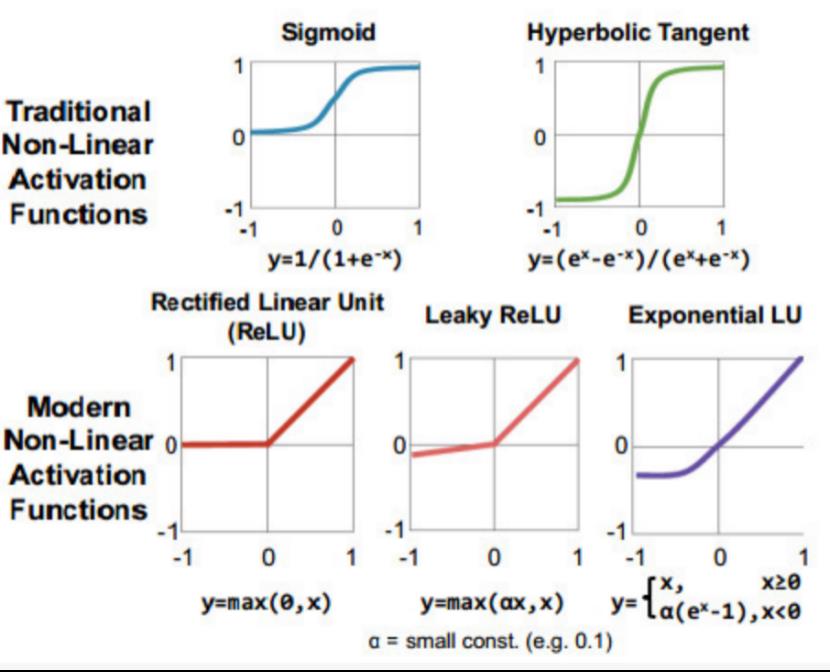
非线性函数:在每个卷积或全连接计算之后,都会使用一个非线性激活函数。如下图所示,不同种类的非线性函数向DNN中引入非线性。起初DNN经常使用Sigmoid或tanh函数,目前ReLU和它的一些变种函数被证明可以更简单,更易训练,同时也能达到更高的准确性,因此变得越来越流行
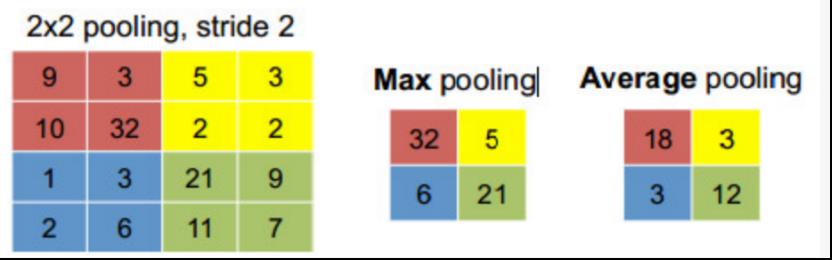
池化(Pooling):池化可以使网络鲁棒性更强。通常池化都是不重叠的,这样能降低表示的维数,减小参数量。
标准化(Normalization):控制各层输入的分布可以极大的加速训练过程并提高准确度。常有的如批标准化(batch normalization)(如下公式),它更进一步的进行缩放和平移,其中γ和β为参数,需要在训练中学习
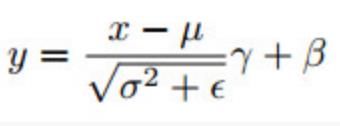
常见的DNN模型有:
常见DNN模型
LeNet:1989年第一个CNN方法,为了解决手写数字识别而设计的。
AlexNet:它在2012年赢得了ImageNet挑战,是第一个使用CNN方法赢得ImageNet的网络。它拥有5个卷积层和3个全连接层。
Overfeat:它与AlexNet结构很相似,同样拥有5个卷积层和3个全连接层,区别是Overfeat的滤波器数量更多,所以准确度略有提升。
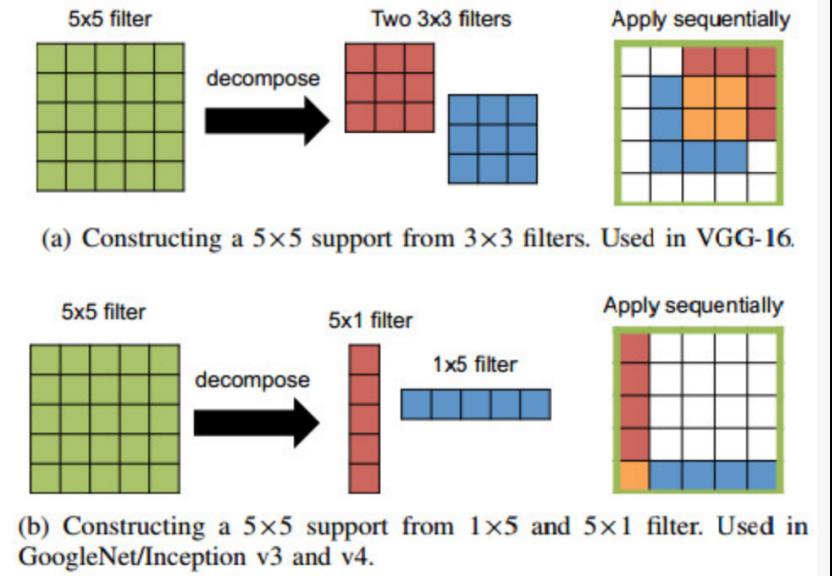
VGG-16:网络深度大大加深,达到16层,其中包含13个卷积层和3个全连接层。为了平衡网络层数加深而导致的成本增加,一个大的滤波器被分解为多个小的滤波器,来减小参数数量,并具有相同的感知野。VGG有两个模型,还有一个VGG-19的模型,比VGG-16的Top-5错误率低0.1%。如下图所示,为了减少参数,为了使感知野大小不变,使用两个较小的滤波器代替大的滤波器
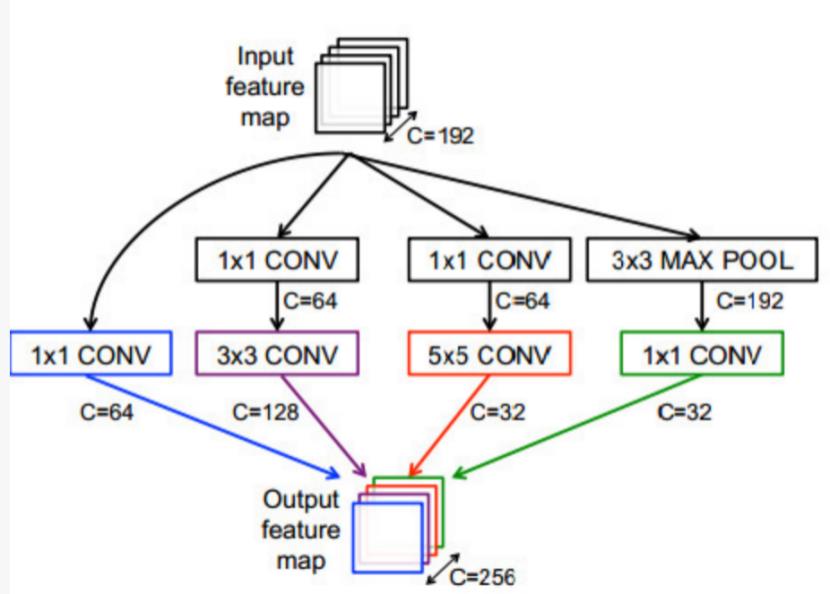
GoogLeNet:网络深度达到22层,同时引入了Inception模型,如下图所示。之前的模型通常是级联的,而Inception模型是并行连接的。可以看到,它使用了多种大小的滤波器对输入进行处理,这是为了能够在不同尺度上处理输入。22层网络包括了三个卷积层,接下来使9个inceptioin层(每层相当于两个卷积层),以及一个全连接层。
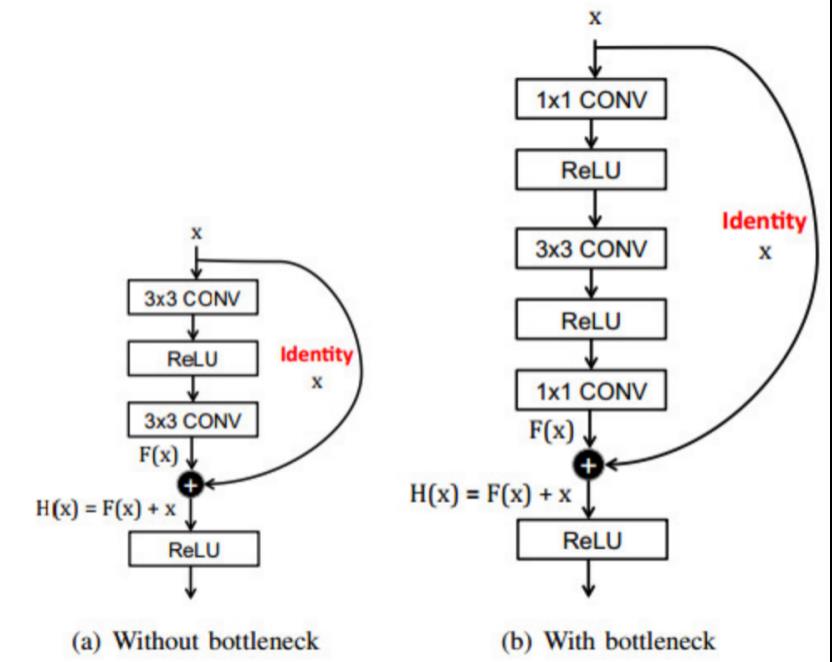
ResNet:也叫做残差网络(Residual Net)。使用了残差连接使得网络变得更深(34层,或更多甚至千层)。它是ImageNet挑战中第一个top-5错误率低于人类的。当网络层次变得更深时,训练时的一个难点就是梯度消失(Vanishing Gradient)。由于沿着网络进行反向传播时,梯度会越来越小,导致对于很深的网络,最初几层网络的权重基本不会更新。残差网络引入了“短接”模型,包含了全等连接,使得梯度传播可以跳过卷积层,即使网络层数达到一千层仍可以训练。残差模型如下所示
再来看看DNN处理的硬件。
由于DNN的流行,许多硬件平台都针对DNN处理的特性进行针对性的开发。无论是服务器级别的还是嵌入式的SoC硬件都在快速发展。因此,了解各种平台如何加速计算,是十分重要的。
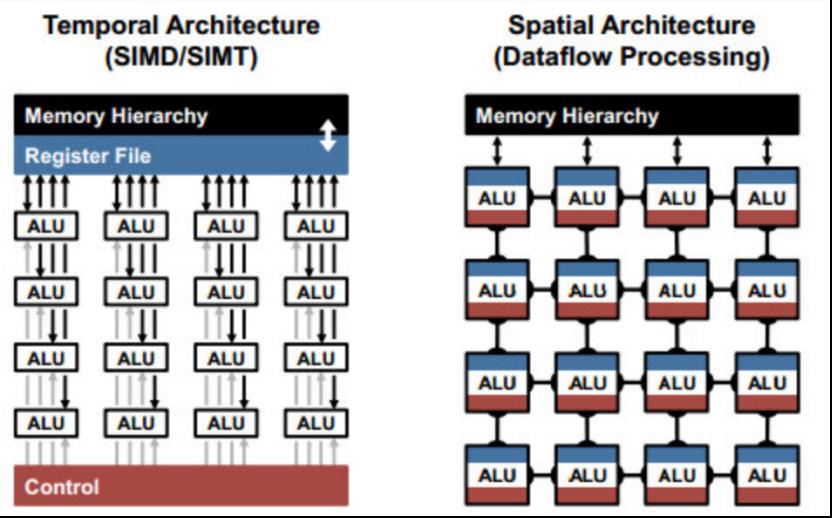
CONV和FC层的基本组成都是乘加操作(Multiply-and-Accumulate,MAC),可以很容易的并行化。为了实现高性能,如图12所示,包括时间和空间的架构的经典模型经常被使用。时间架构(也称作SIMD或SIMT)主要出现在CPU或GPU中。它对大量ALU使用集中控制。这些ALU智能从存储器层次结构中获取数据,并且彼此不能通信数据。相比之下,空间架构使用数据流处理,即ALU形成处理链,使得它们能直接将数据从一个传递到另一个。每个ALU有自己的控制逻辑和本地内存,称为暂存器或注册文件。空间架构主要使用在为DNN专门设计的ASIC中。
对于时间架构,可以使用核心中的计算转换(Computational Transform)来减少乘法的数量,以增加吞吐量(Throughput)。
对于加速硬件中使用的空间架构,使用存储器层次结构中的低成本内存,来增加数据重利用率,以降低能耗。
接下来了解本次实验用到的数据集。
本次实验用到的数据集来自spambase.Spambase Dataset 是一个垃圾邮件数据集,其包含 57 个属性和 4601 个实例,其中1813个实例为垃圾邮件。该数据集主要用于垃圾邮件的识别分类,其中垃圾邮件的资源均来自于邮件管理员和提交垃圾邮件的个人,其可被用于构建垃圾邮件过滤器。
训练数据在spambase.data,文件很大,有700多k,我们在终端中使用head命令打印前几条看看

可以看到spambase的数据不是原始的邮件内容,而是已经经过特征化的数据,对应的特征是统计的关键字以及特殊符号的词频。最后一个是垃圾邮件的标记位,1表示为垃圾邮件,0表示不是垃圾邮件
具体的格式说明可以打开syambase.name进行查看
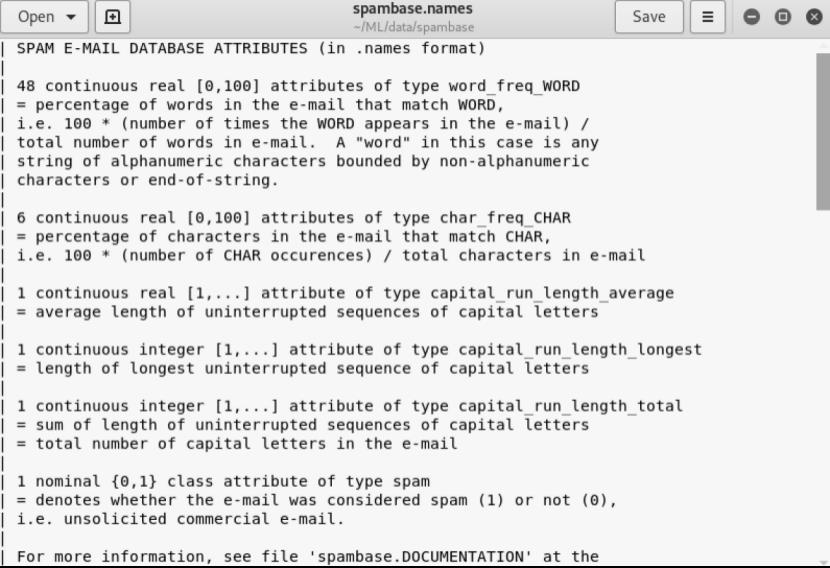
可以看到会统计单词频率、字符频率等特征

可见这是一个入门级的垃圾邮件分类训练集。
那么接下来我们就来看看代码实现。
首先是加载数据集的函数
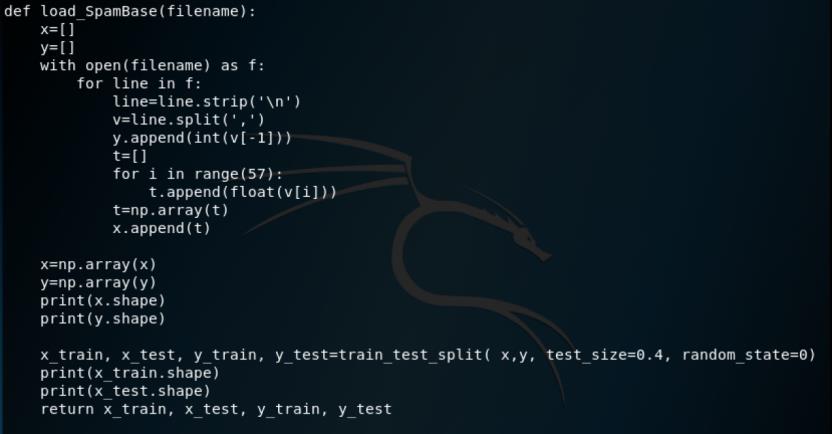
在加载完成后,我们通过train_test_split将矩阵随机划分为训练子集和测试子集,并返回划分好的训练集测试集样本和训练集测试集标签,这里指定测试集占0.4
加载完成后,指定分类器为DNN

上面的代码中,hidden_units=[30,15]表示具有两个隐藏层,每层节点数分别为30,15.n_classes=2表示2分类,对应我们的实验,即分类为垃圾邮件与非垃圾邮件。
接着进行训练

Steps=1000表示训练1000批次,batch_size=50表示每个批次有50个训练数据
使用训练数据集进行分类,得到分类结果y_predict,将其与正确标记的y_test进行比对,计算出准确率

测试
Python3 dnn.py
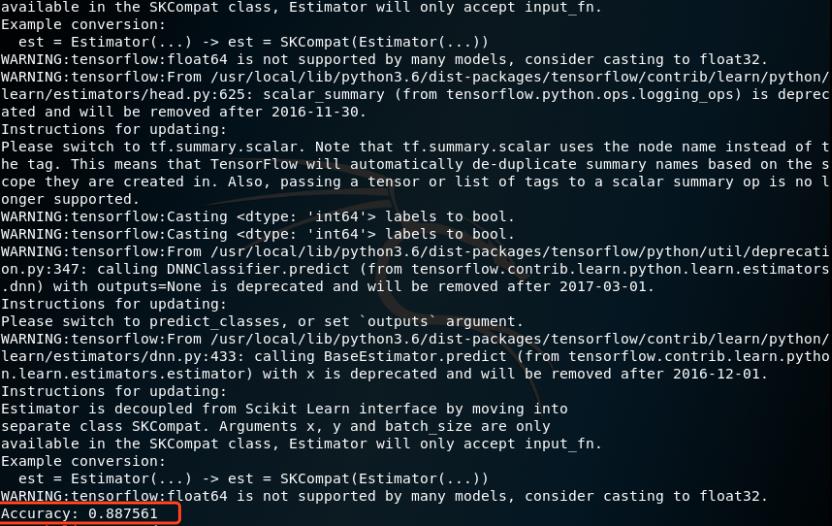
这里会打印出TensorFlow的很多warning信息,不需要去关注。上图红色标注的就是准确率,可以看到高达88.7%
参考:
1.《机器学习之web安全》
2.http://archive.ics.uci.edu/ml/datasets/Spambase/
3.https://baike.baidu.com/item/%E5%8F%8D%E5%9E%83%E5%9C%BE%E9%82%AE%E4%BB%B6
4.https://www.leiphone.com/news/201703/qSPav6WbksGmW3Vh.html
5.https://github.com/duoergun0729/1book/
以上是关于深度神经网络识别垃圾邮件的主要内容,如果未能解决你的问题,请参考以下文章